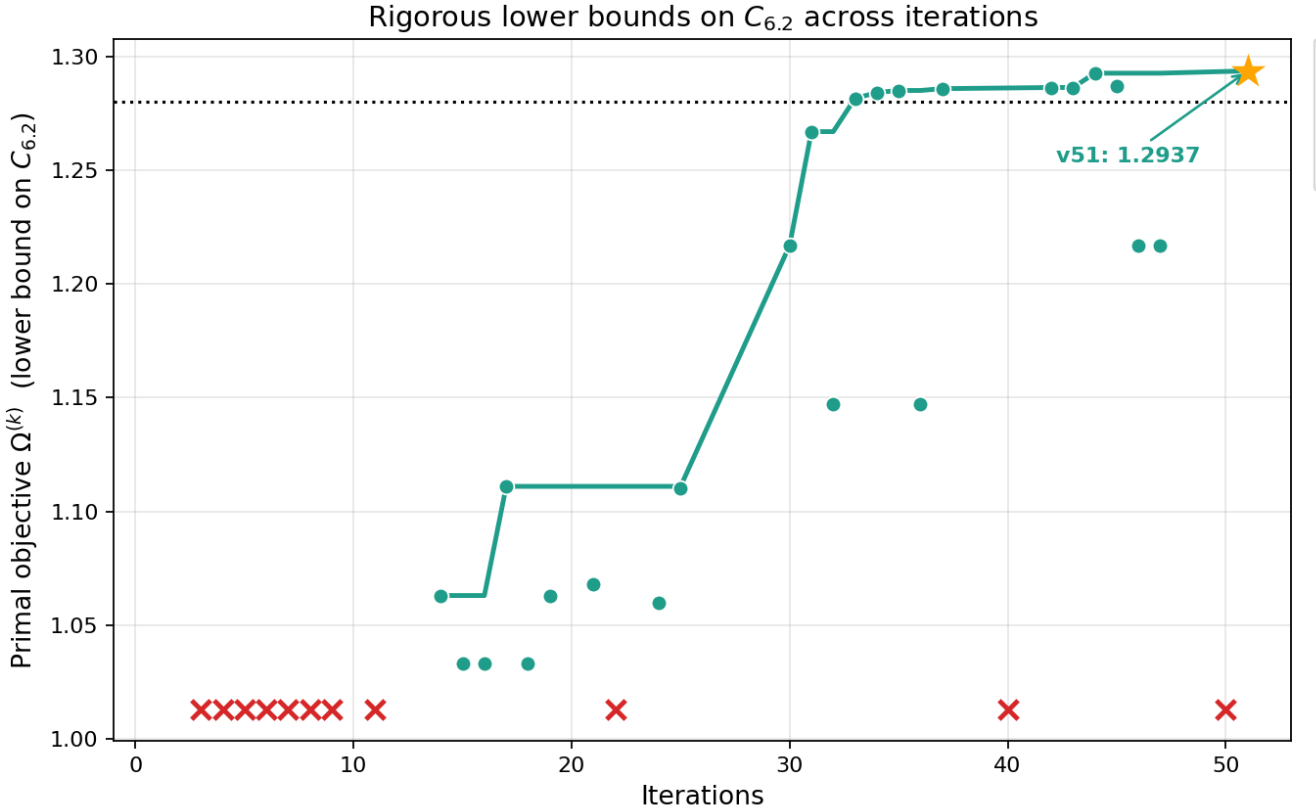
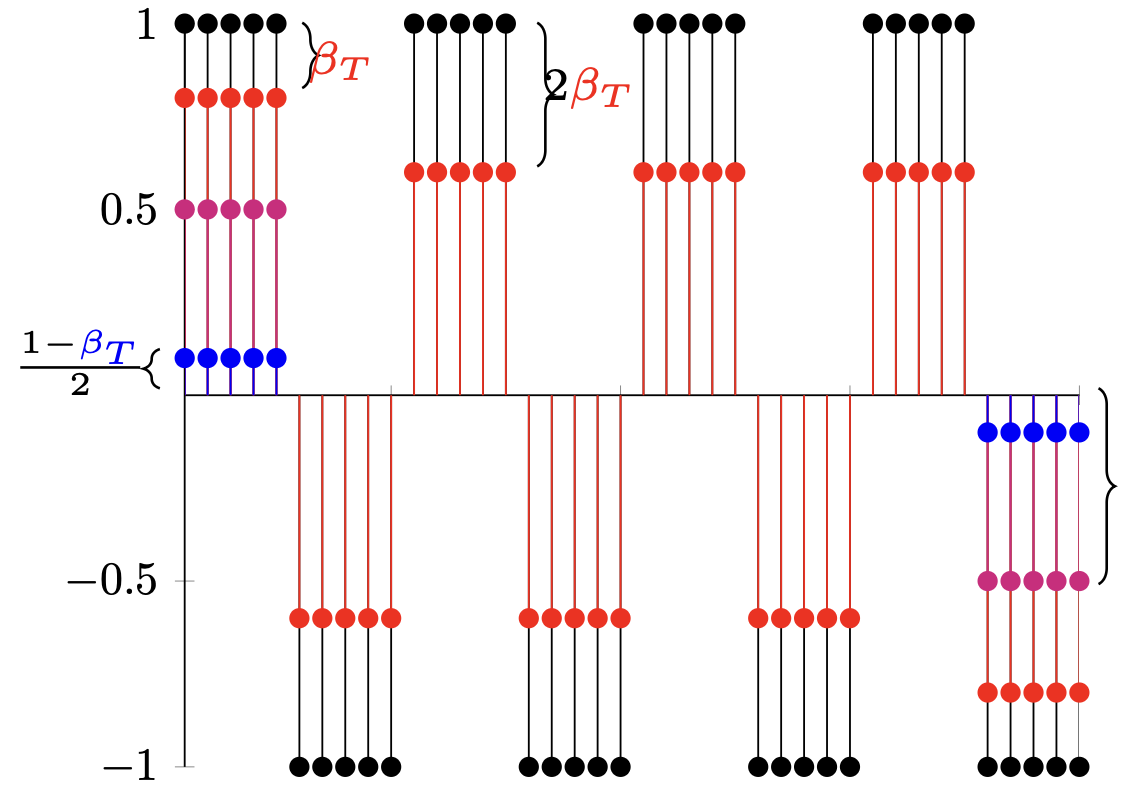
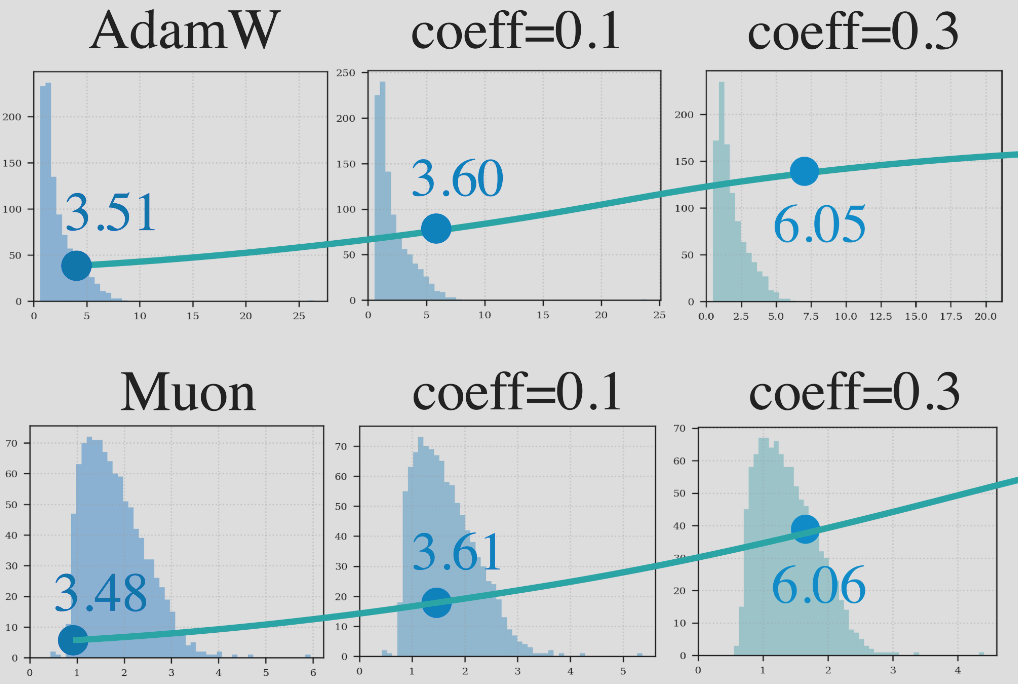
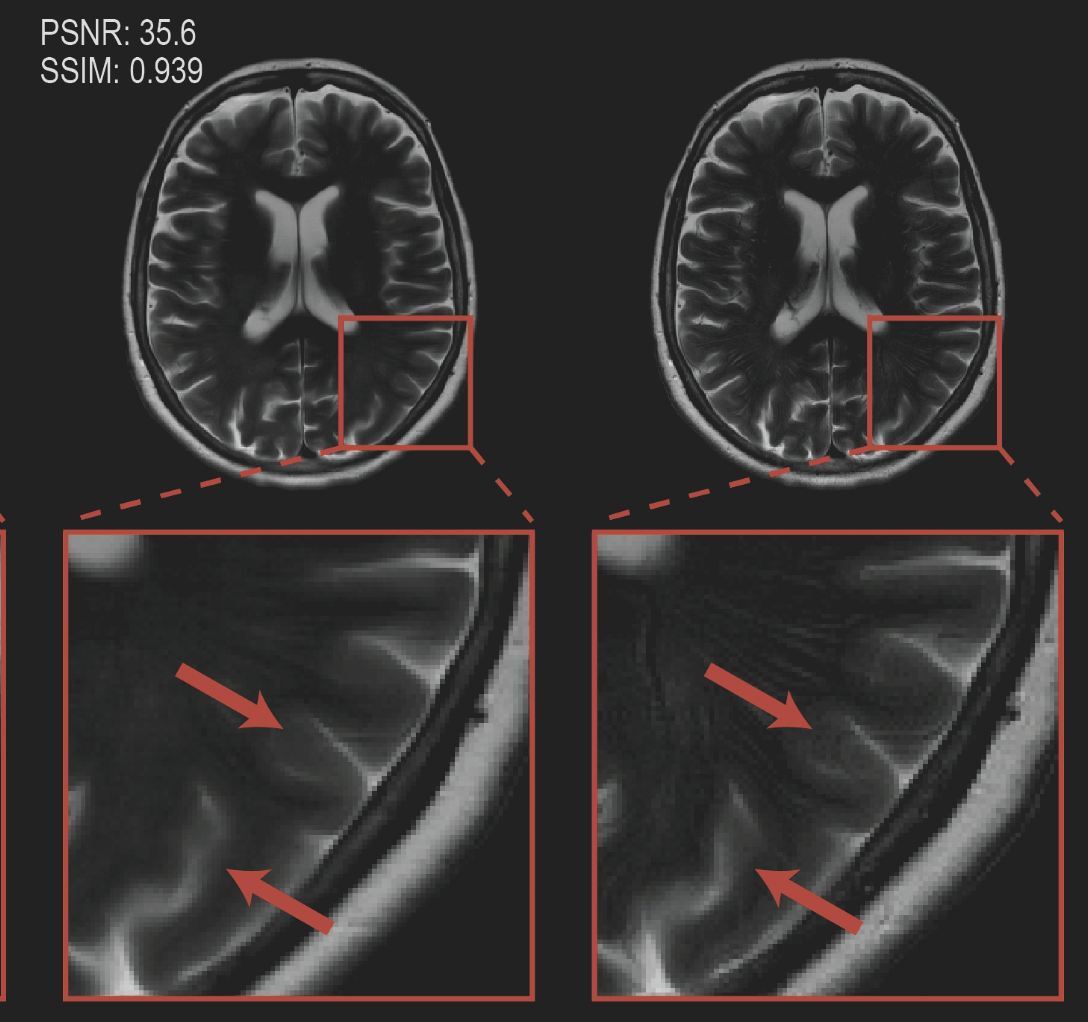
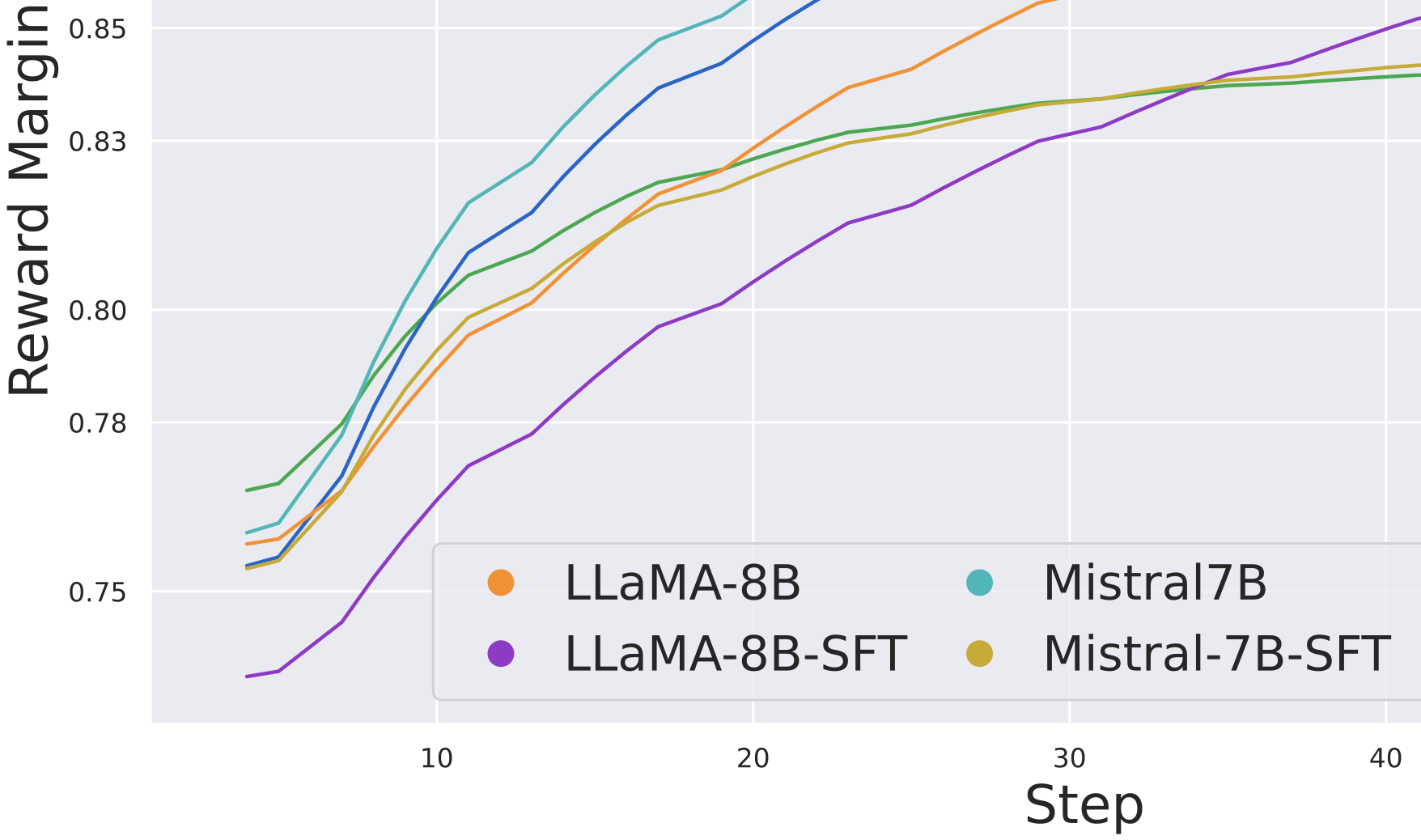
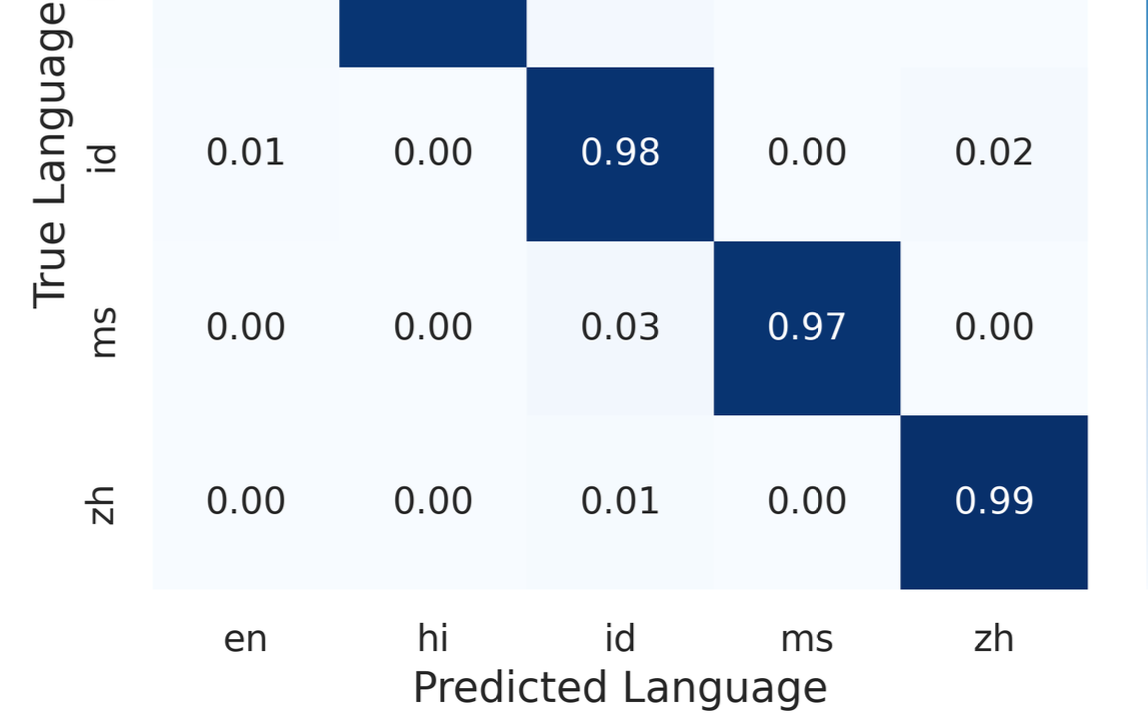
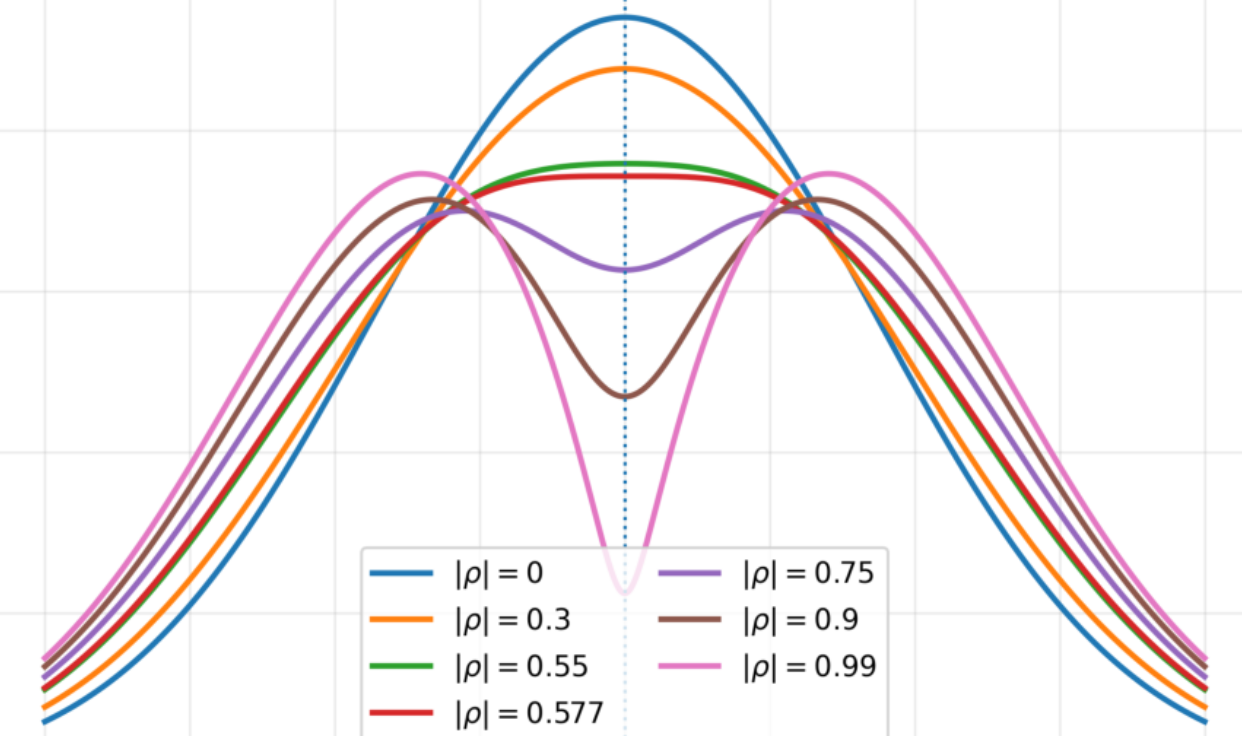
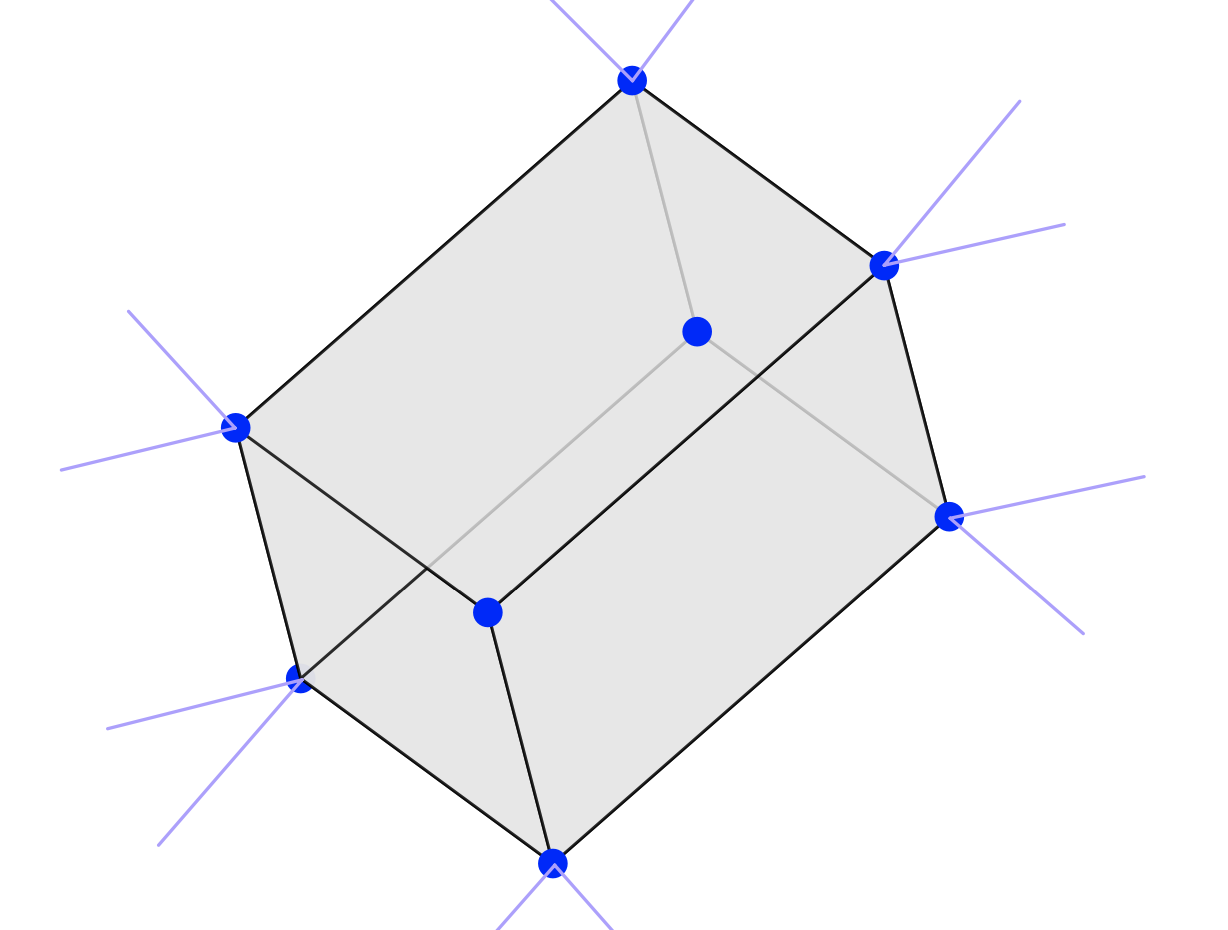
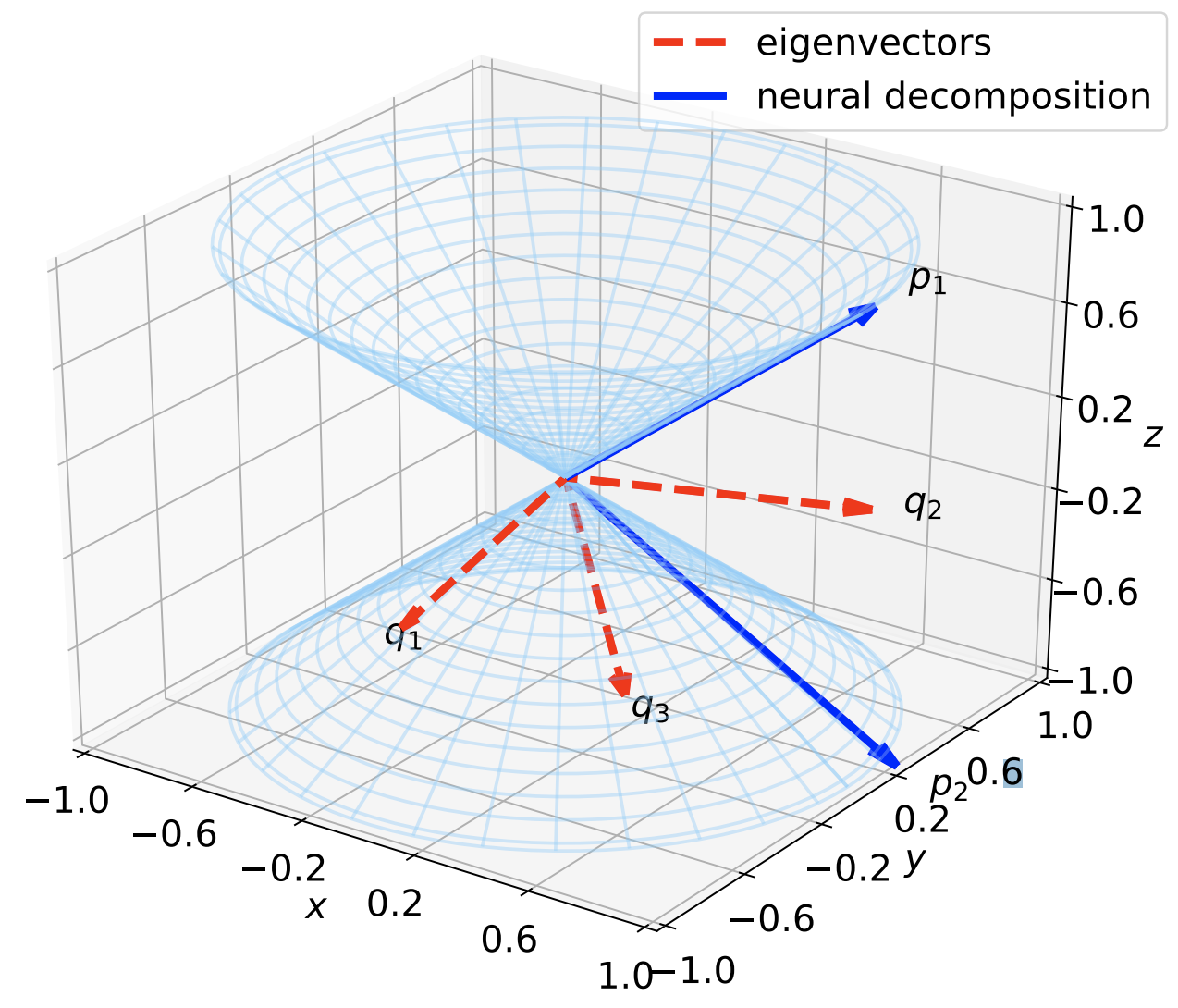
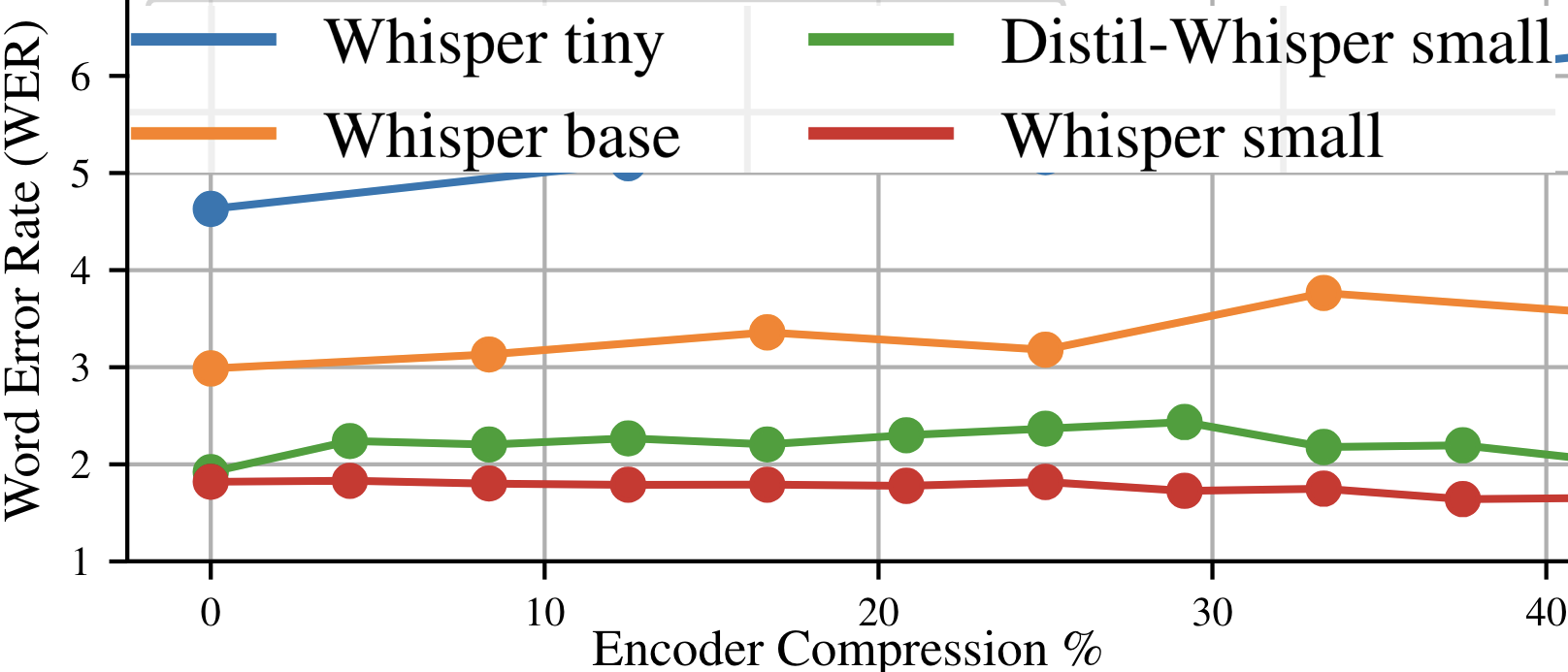
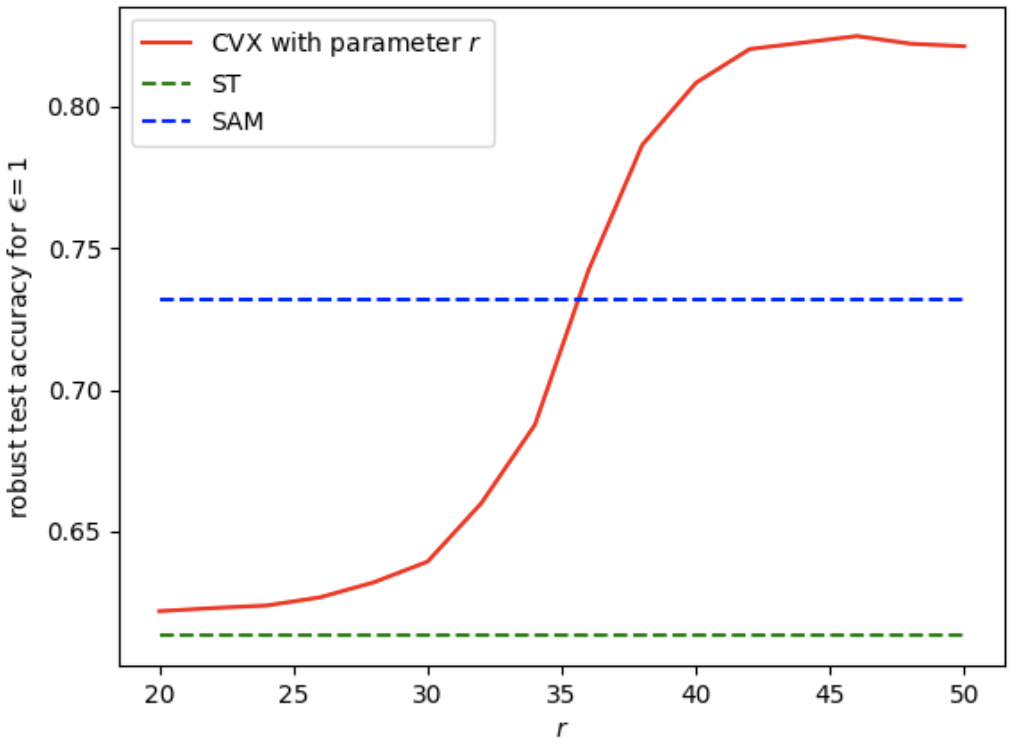
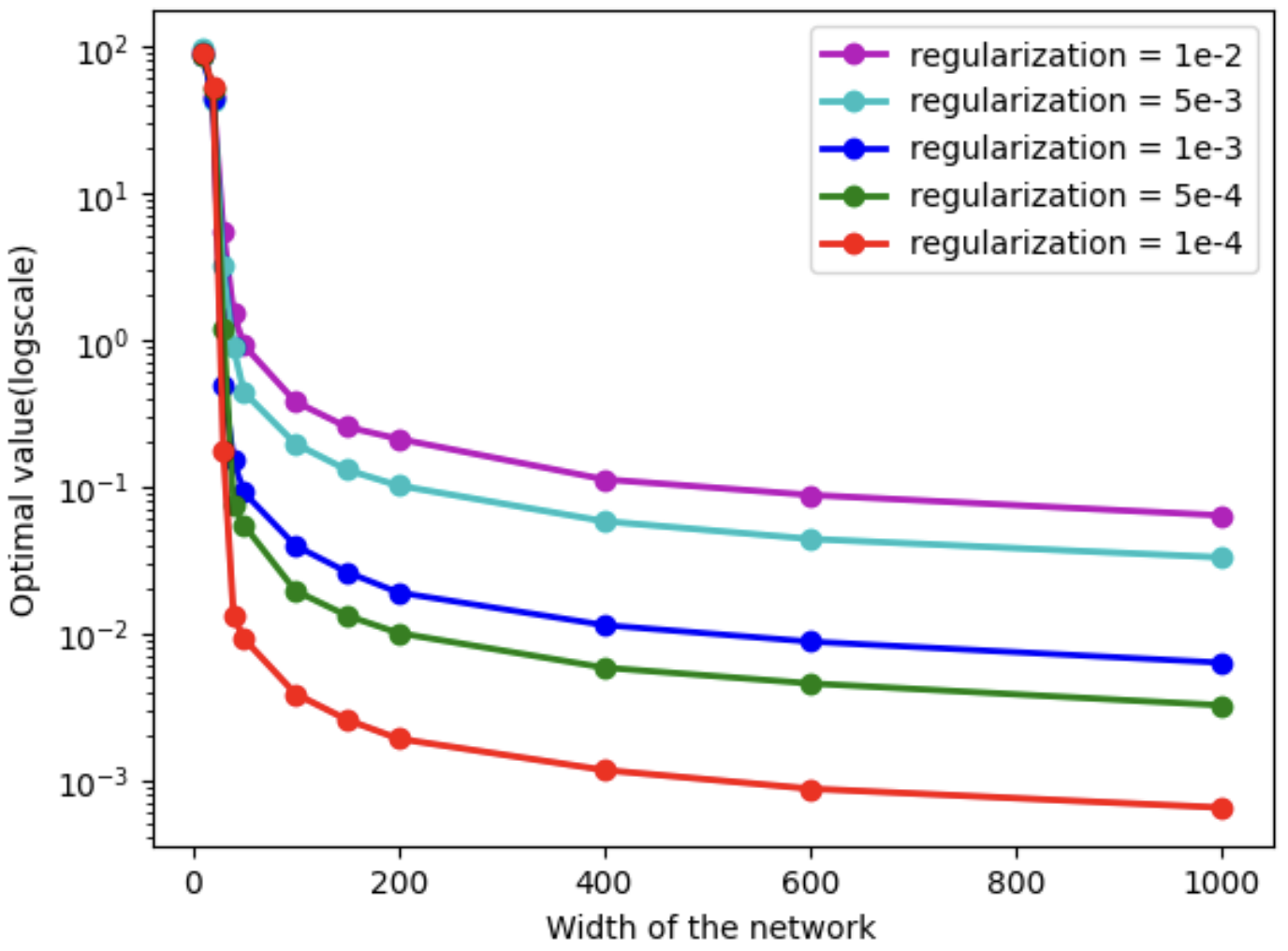
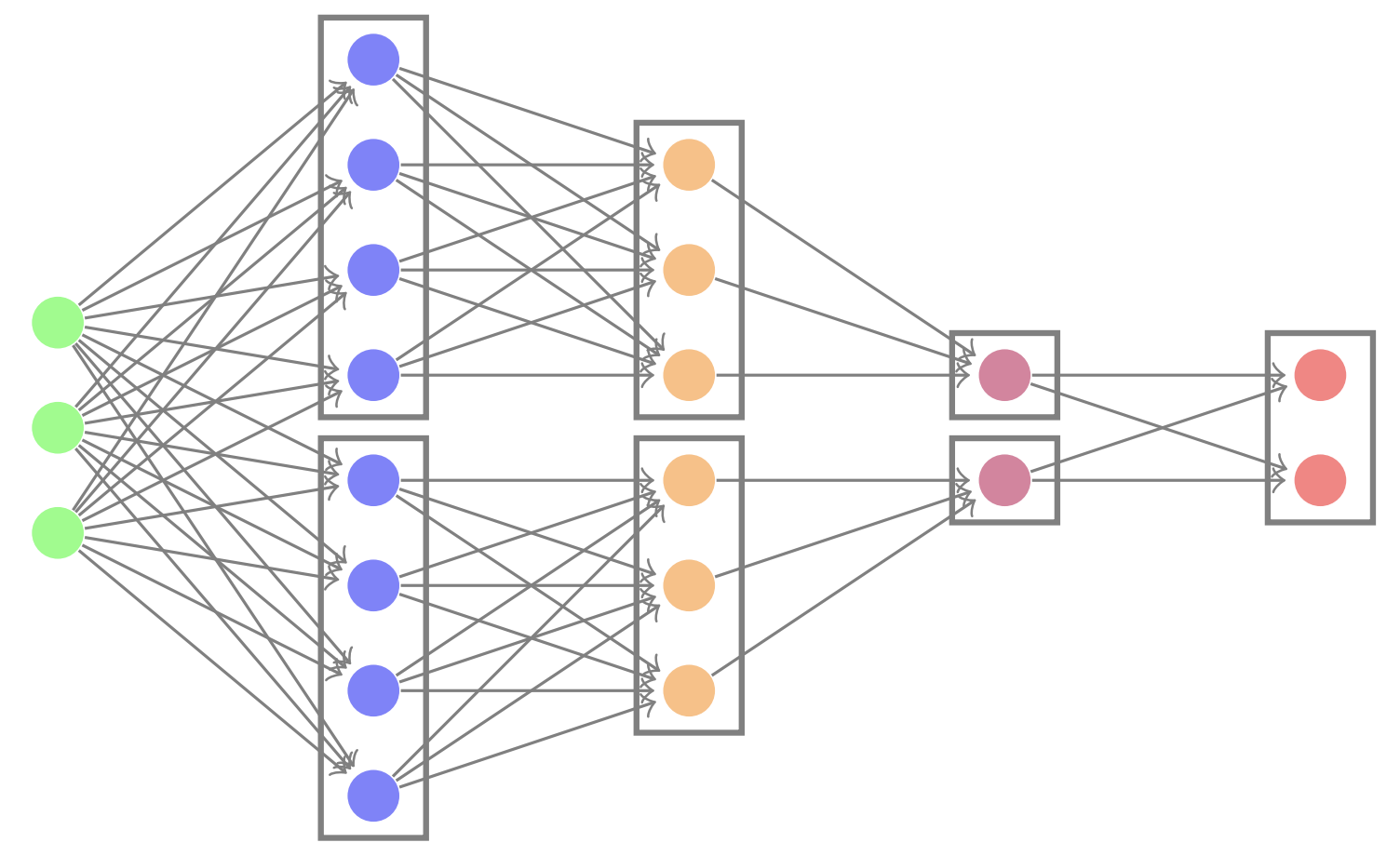
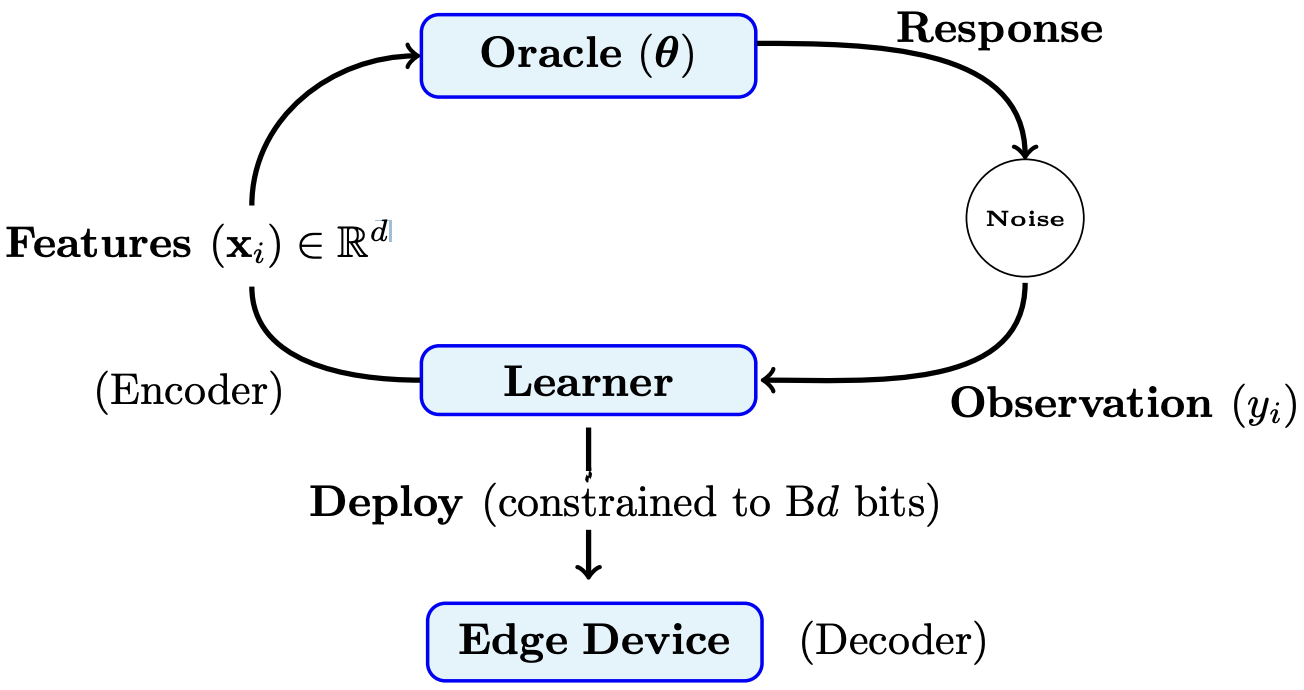
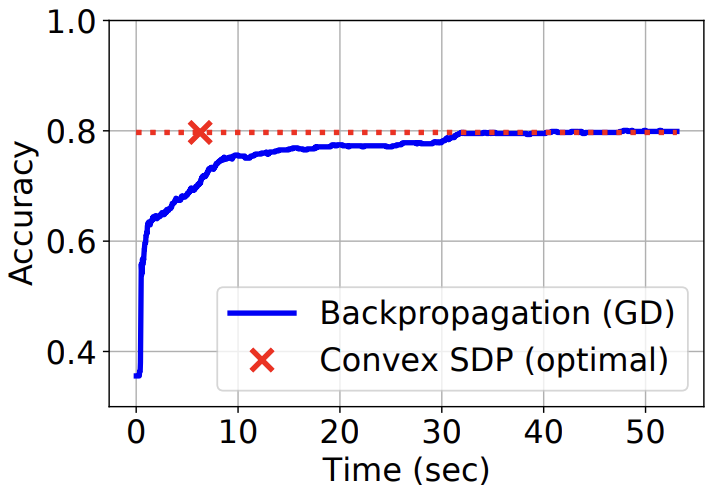
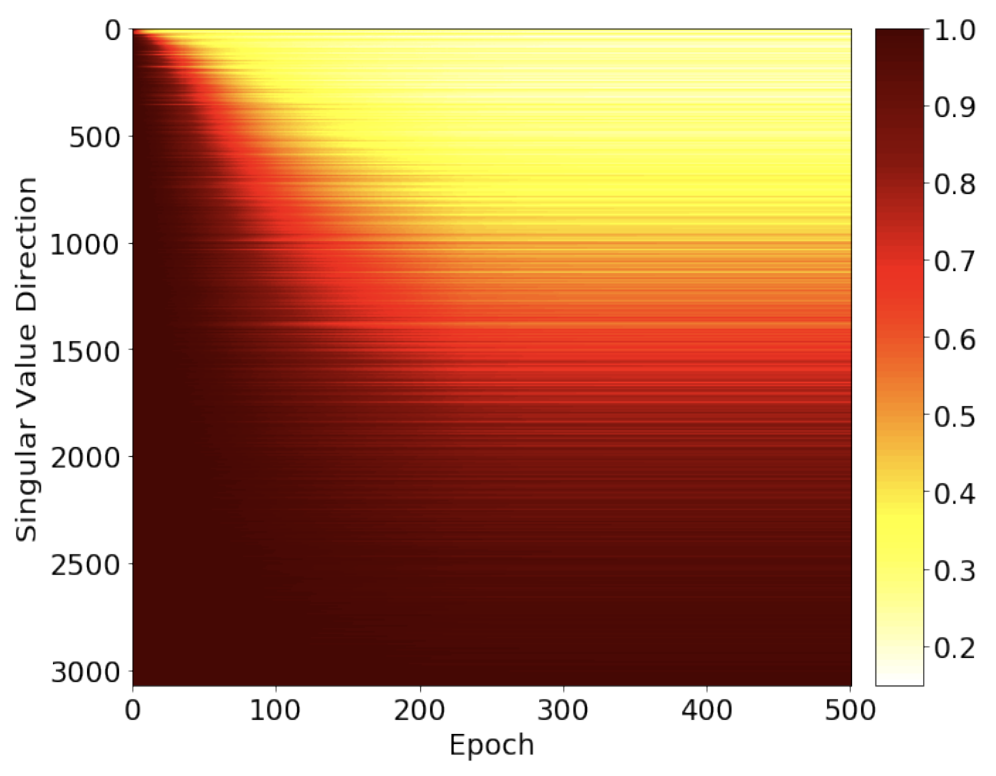
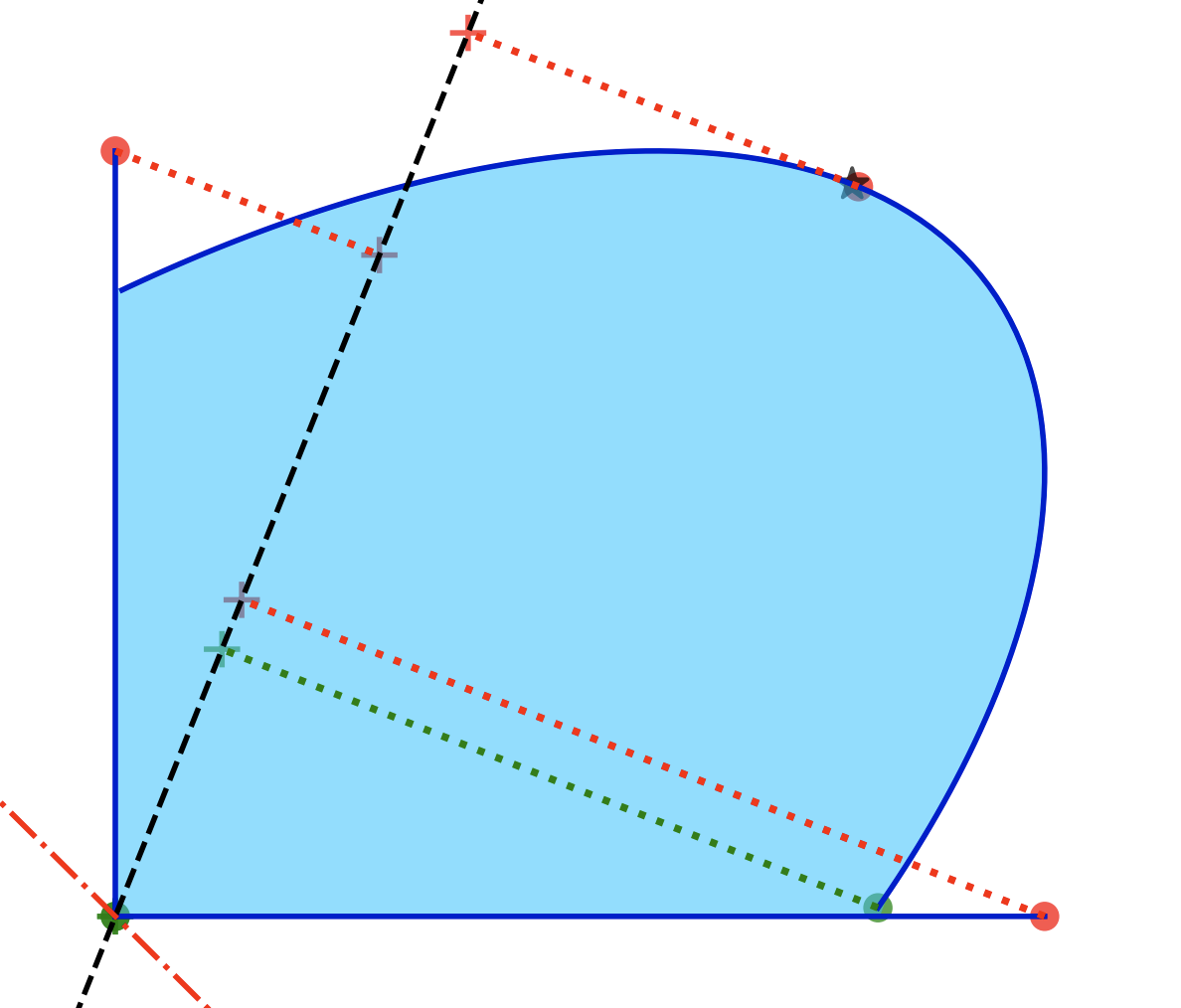
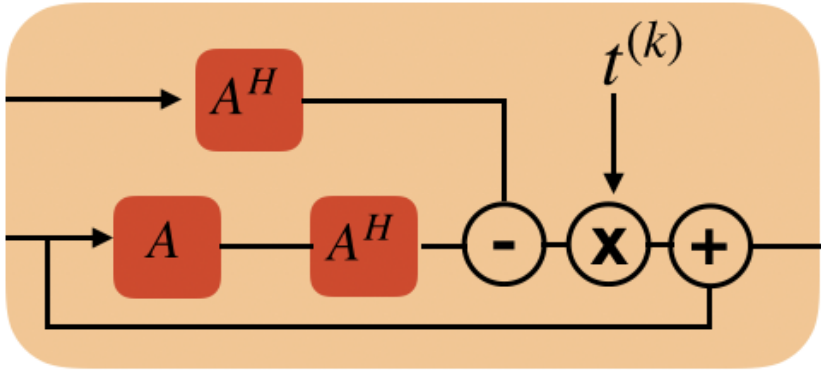
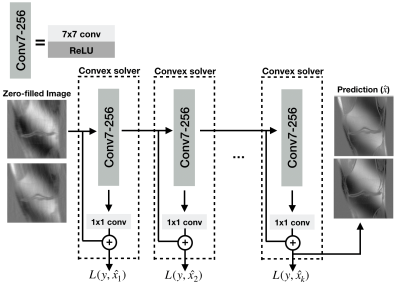
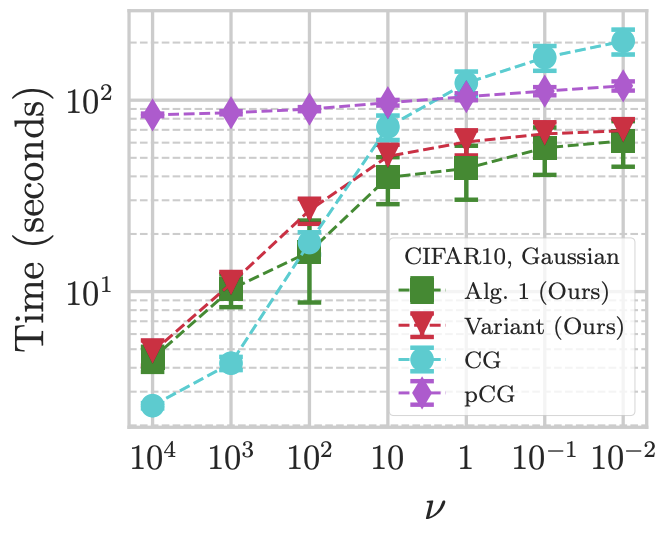
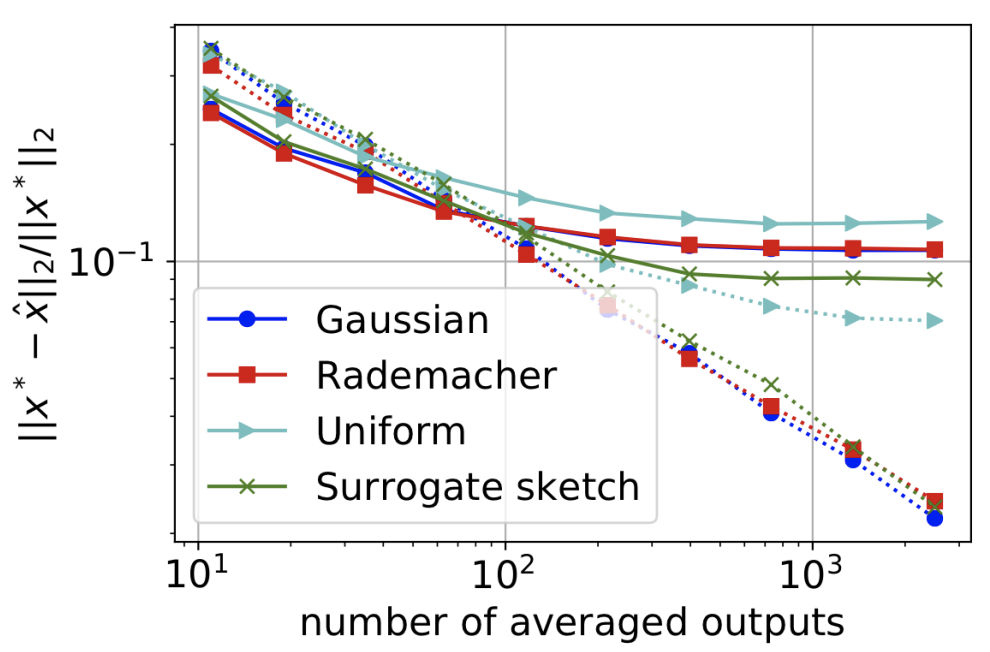
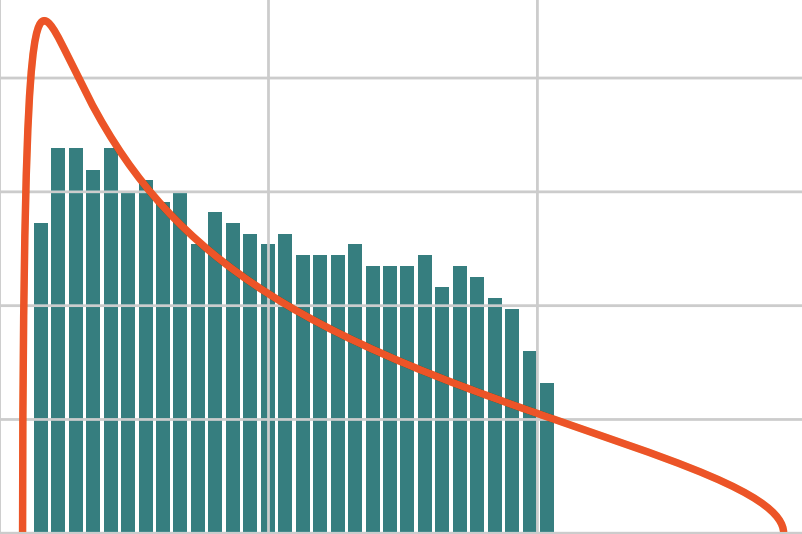
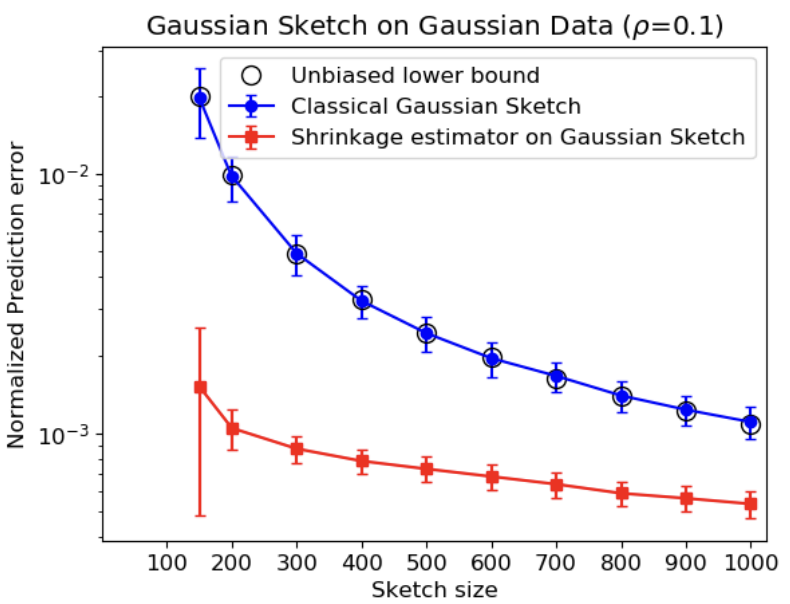
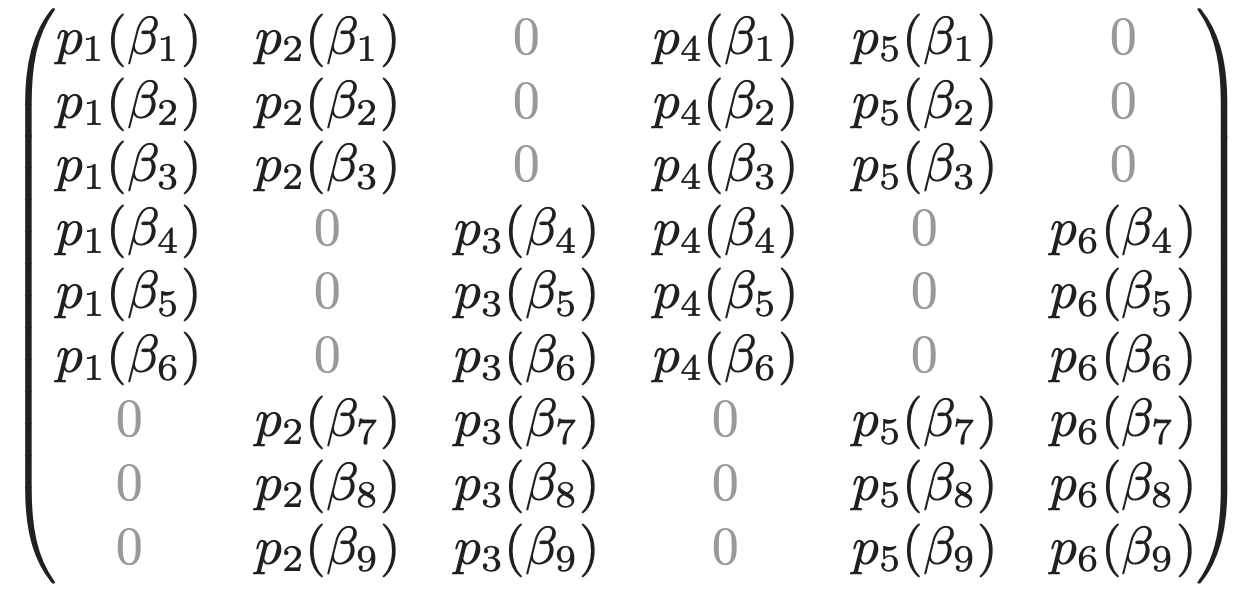I'm an assistant professor in the department of
Electrical Engineering at Stanford University.
Prior to joining Stanford, I was an assistant professor of Electrical Engineering and Computer Science at the
University of Michigan . In 2017, I was a
Math+X
postdoctoral fellow working with
Emmanuel Candès at Stanford University. I received my Ph.D. in Electrical Engineering and Computer Science from UC Berkeley in 2016. My Ph.D.
advisors were Laurent El Ghaoui and Martin Wainwright, and my studies were supported partially by a Microsoft Research PhD Fellowship. I obtained my B.S. and M.S. degrees in Electrical Engineering from Bilkent University,
where I worked with Orhan Arikan and Erdal Arikan.
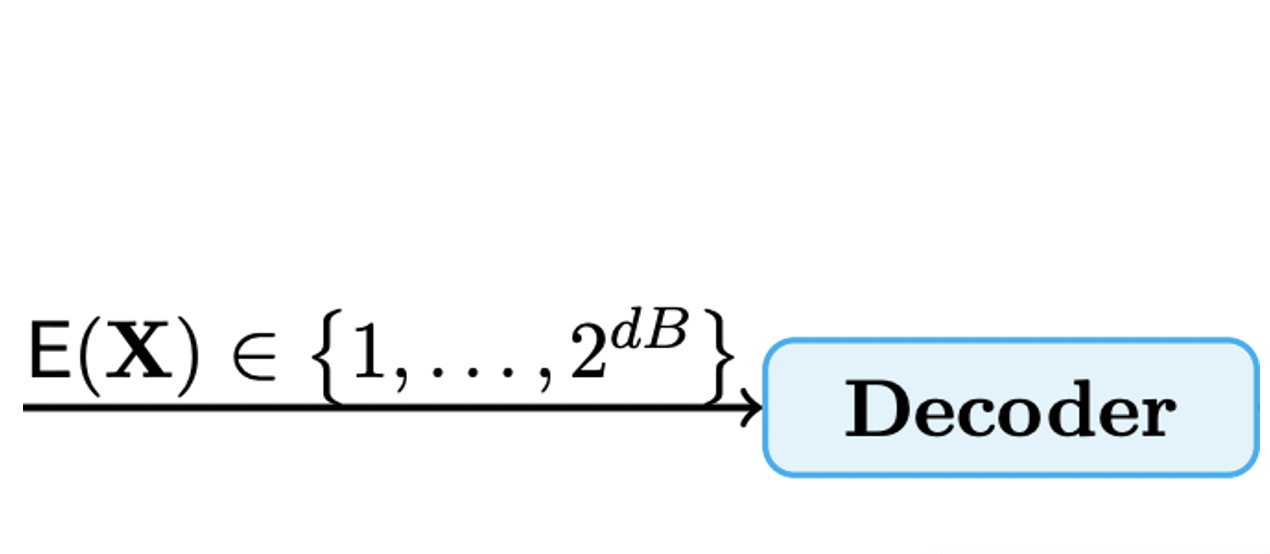
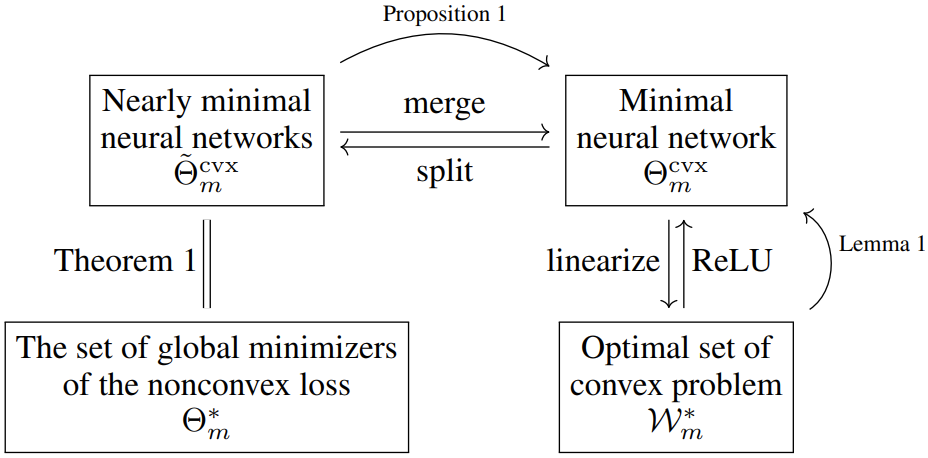
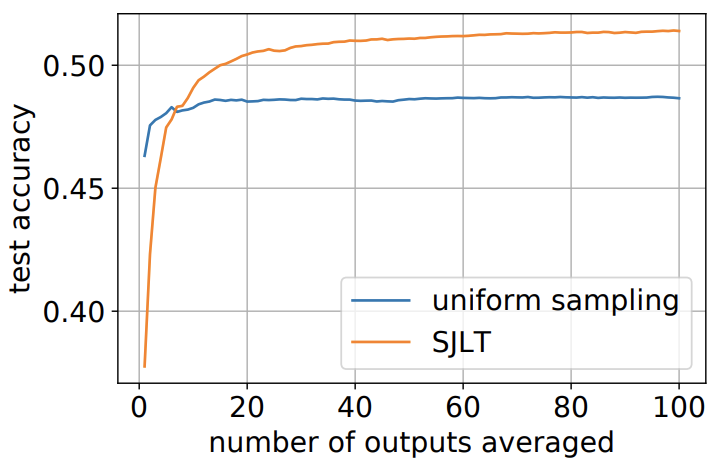
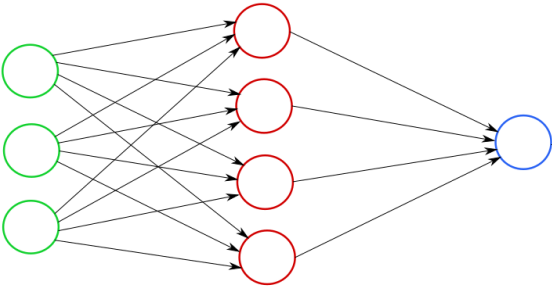
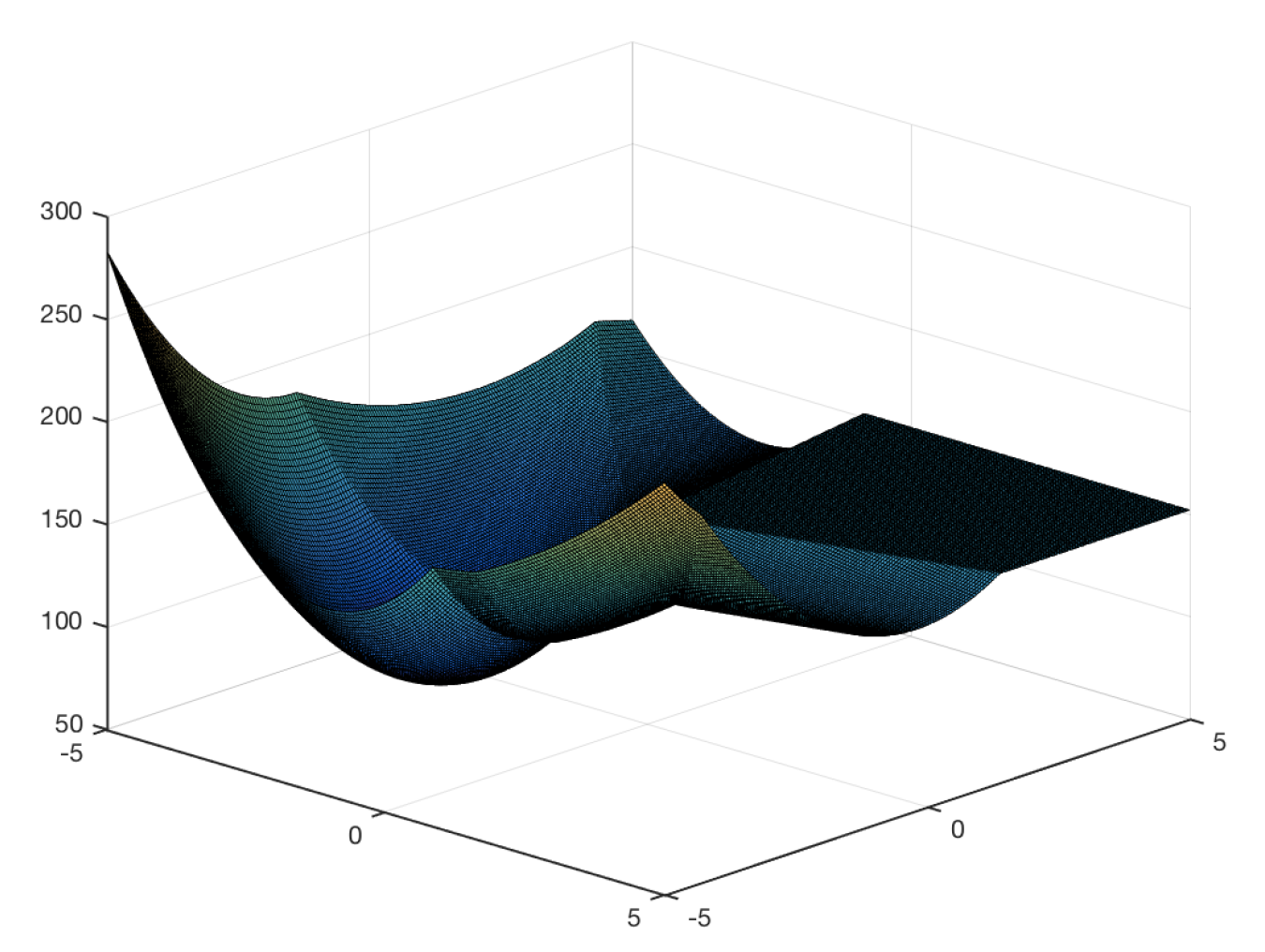
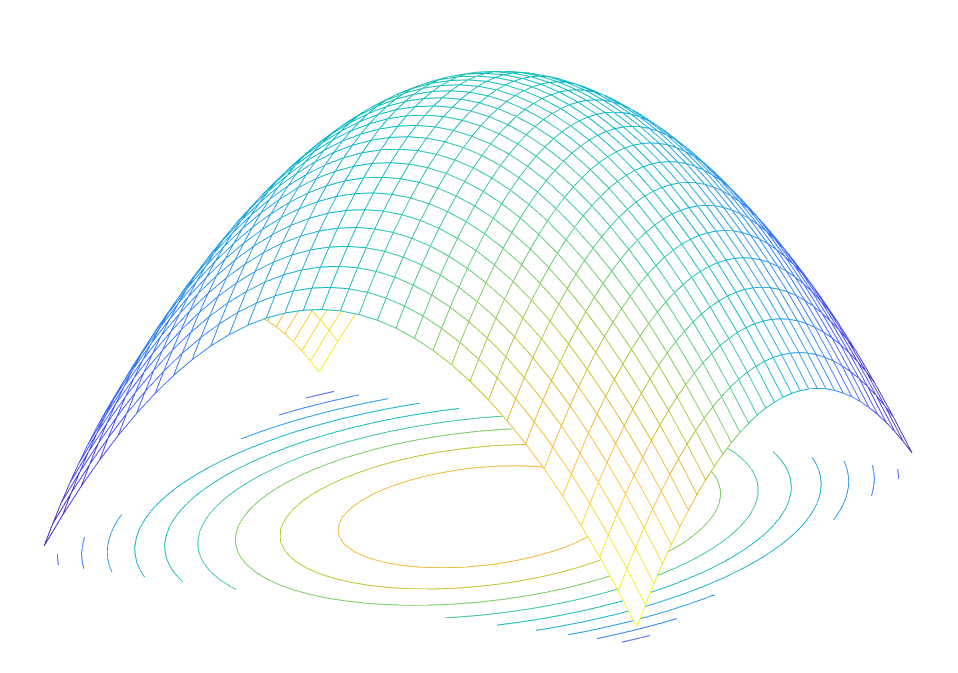
Research Interests: Optimization, Machine Learning, Neural Networks, Generative AI, Signal Processing, Information Theory