Comprehending Bechdel Data
Written by Elyse Cornwall, based on a section by Erin McCoy, Katie Creel, Diana Navas, and Juliette Woodrow.
List Comprehensions
Temps, Revisited
Let's revisit a problem from last section: we have a list of temperatures temps_f in Fahrenheit,
and we want to produce a list temps_c of those temperatures in Celsius.
temps_f = [45.7, 55.3, 62.1, 75.4, 32.0, 0.0, 100.0]
Last section, we saw how to
do this with map. Now, write a list comprehension to create the list temps_c.
Movie Tuples
Suppose we have a list of tuples representing movies, for example:
movies = [('alien', 8, 1), ('titanic', 6, 9), ('parasite', 10, 6), ('caddyshack', 4, 5)]
The first element of each movie tuple is the movie name, the second element is the overall score, and the
third element is the "date score" (how appropriate the movie is for a date). Write list comprehensions to
do the following, given some list movies like the one above.
- Produce a list of the second elements (overall scores) of each tuple.
- Produce a list of the sum of the second and third elements (overall score plus date score) of each tuple.
- Produce a list of the first elements (movie name) of each tuple, except that the first character of each name is made uppercase. You can assume that each movie name has at least one character, and don't worry about movie names that are multiple words.
Bechdel Test Data
A Short History
Named for Alison Bechdel, the Bechdel Test seeks to analyze the representation of women in fictional media. To pass the Bechdel Test, a film must fulfill three requirements:
- Feature two women
- Who have a conversation
- About something other than a man
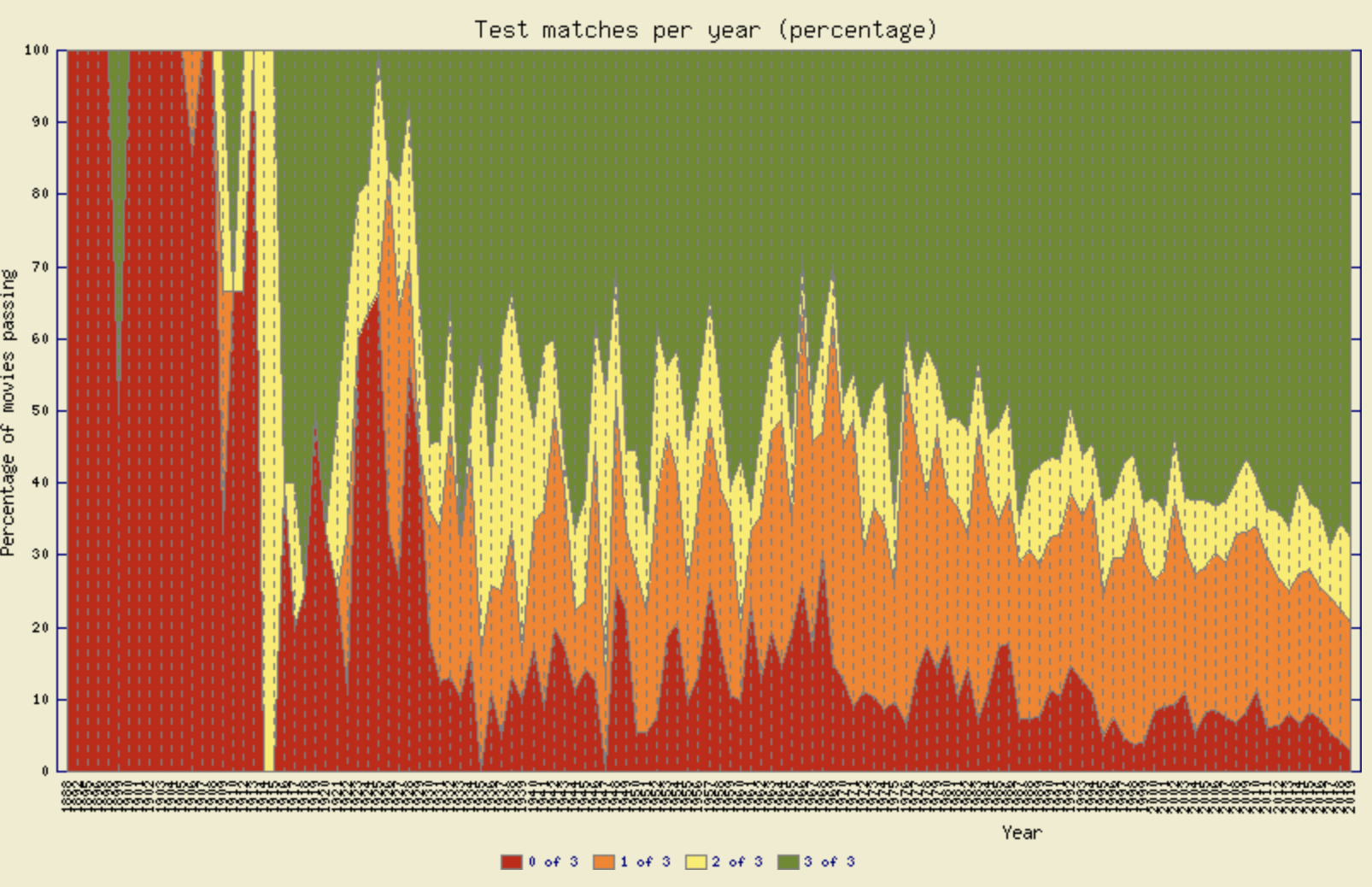
Our Data
In this problem, we are going to use over a century of data to plot what percentage of movies pass the Bechdel Test over time. This data comes from a database of over 9000 movies. We've got a data file in the following format:
Sherlock Holmes Baffled,0,1900
Pinocchio,1,1940
Anna Karenina,2,1948
Encanto,3,2021
Cruella,3,2021
Each line has a movie title, score between 0-3, and year. The score represents the number of Bechdel
requirements the movie passes, so 0 is none, and 3 is fully passing the Bechdel Test. We've turned this data
into a years dictionary where the key is a decade, and the value is a nested list of length 2.
The first value (index 0) in the list represents how many movies from this decade pass the Bechdel Test, and
the
second value (index 1) in the list represents how many do not.
years = {
1900: [0, 1],
1940: [0, 2],
2020: [2, 0]
}
We can read this dictionary as: in the 1900s, 0 movies passed the Bechdel Test and 1 failed; in the 1940s, 0 movies passed the Bechdel Test and 2 failed; finally, in 2020, 2 movies passed the Bechdel Test and 0 failed.
We've provided the code to read the file data into a years dictionary in a function called
read_file in the starter code, but implementing read_file yourself would be
great practice for the final exam.
Plotting Total Passed
We want to create a line plot to see how many movies pass the Bechdel Test over time, kind of like the graph
we
see above. We will do this using the matplotlib library. To make sure you have everything installed properly,
download the starter code at the top of this handout and open it in PyCharm as usual. If you haven't
installed matplotlib already, open the terminal in PyCharm and run the following command (if you have a
Windows
computer, substitute py for python3): python3 -m pip install matplotlib
Recall that you can use matplotlib to make a line graph by providing a list of x and y values, and a color like this:
x_vals = # some list of x values
y_vals = # some list of y values
plt.plot(x_vals, y_vals, color="green")
In the starter code, we have provided the call to plt.plot, and your job will be to create the
x_vals and y_vals lists. Think: what are plotting along the x-axis? What about the
y-axis? Use a list comprehension to create y_vals. Note that because the movies in our
input file were ordered chronologically, our dictionary's keys are already sorted in increasing order, so that
for our sample dict years above, we have:
>>> years
{1900: [0, 1], 1940: [0, 2], 2020: [2, 0]}
>>> years.keys()
dict_keys([1900, 1940, 2020])
>>> years.values()
dict_values([[0, 1], [0, 2], [2, 0]])
To test your function, type: python3 bechdel-graphs.py data-full.txt. Here's what you should
see:
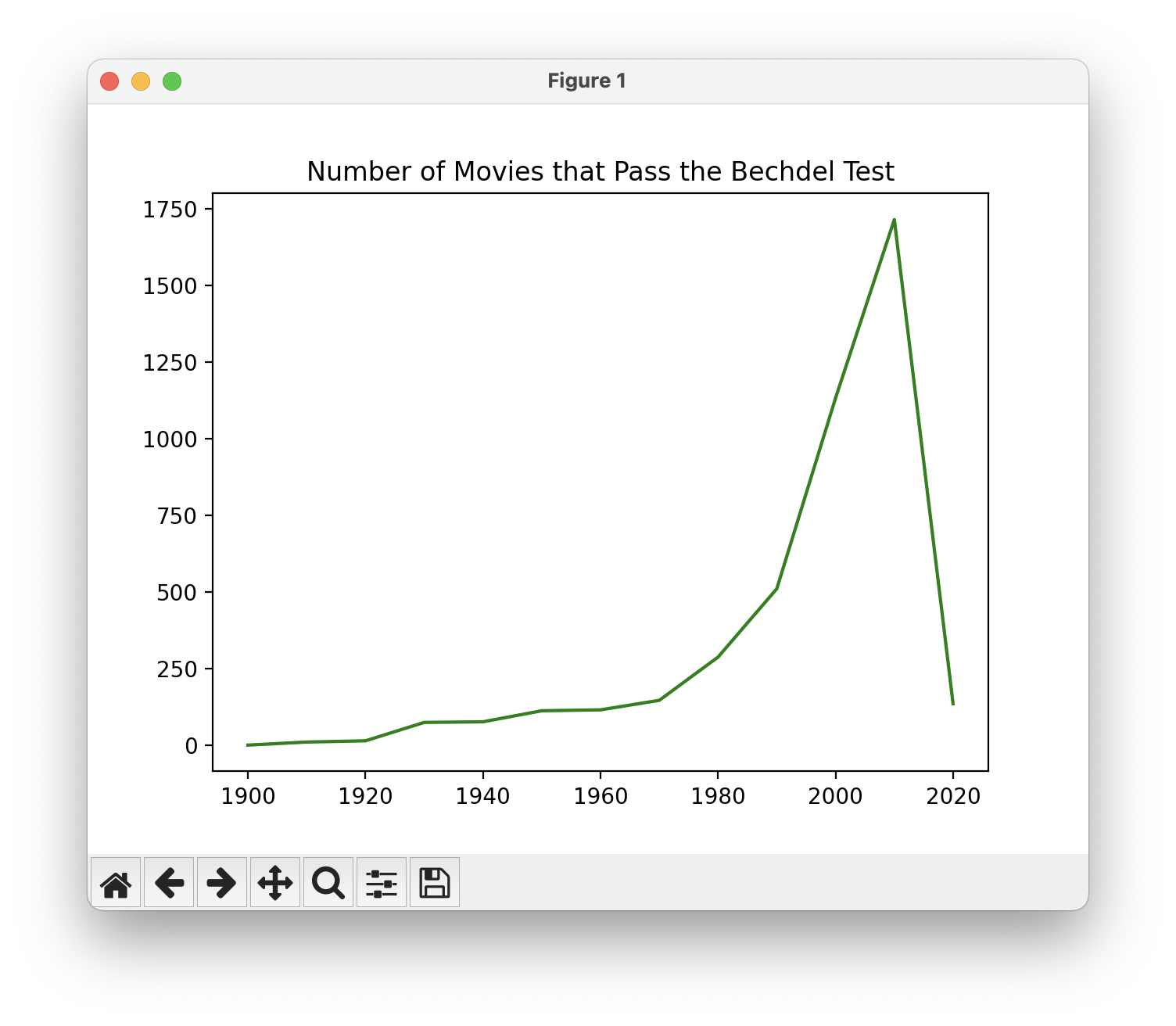
Hmm... the number of movies that pass the Bechdel Test increases expontentially from 0 in the 1900s to 1750 the 2010s, but then completely plumments back to 200 in the 2020s. What's going on here? Well, let's take a look at the number of movies in our dataset by decade (you guessed it, we used matplotlib to graph this).
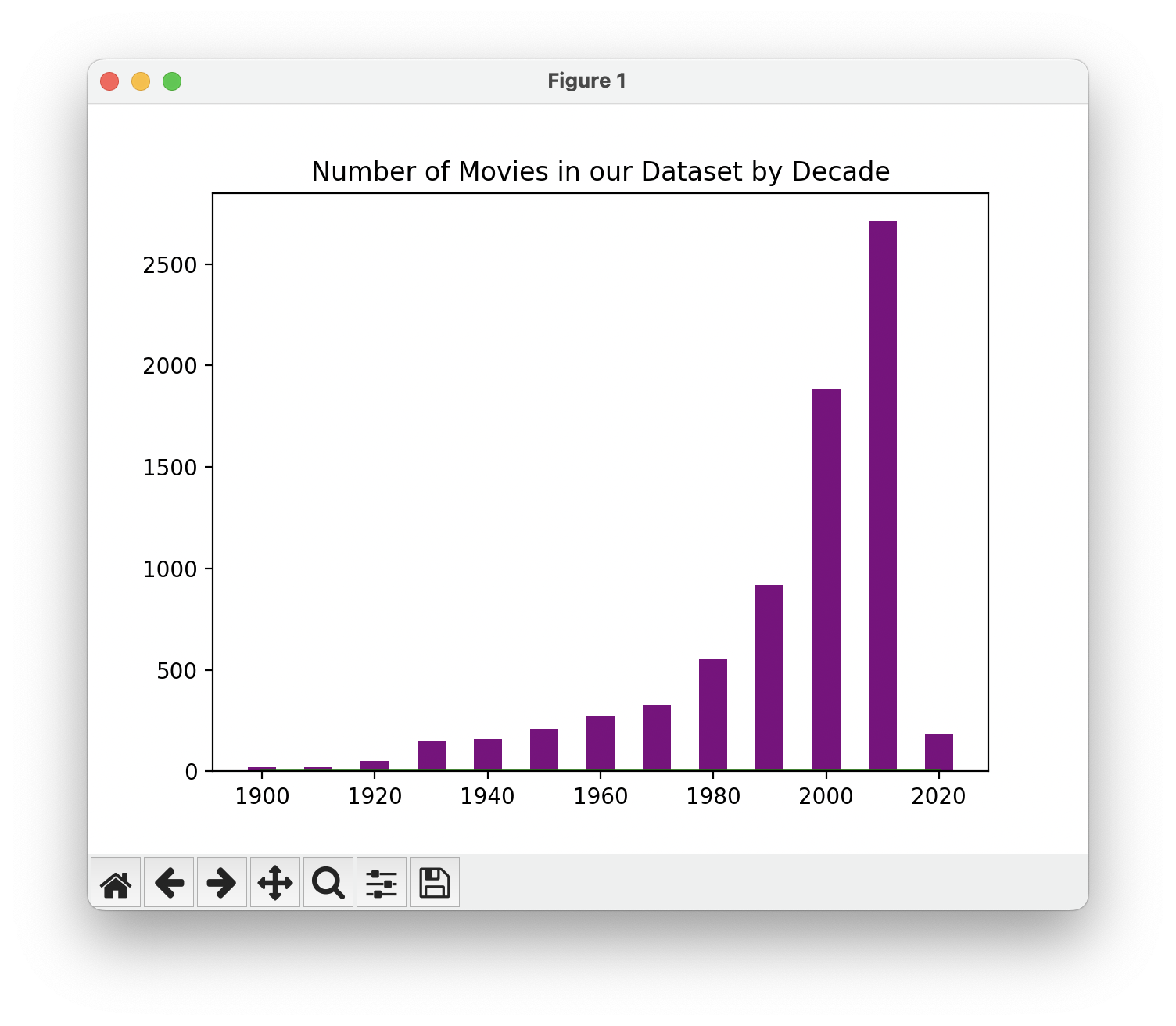
Because we're only a few years into the 2020s, we don't have nearly as many movies in our dataset for this decade as we do for the 2010s. We can also see that the number of movies in our dataset steadily increases by decade, and so how do we know whether more movies are passing the Bechdel Test as time goes on, or if there are just more movies overall? To answer this question, we can plot the fraction of movies that pass the Bechdel Test. That way, our results won't be swayed by the total count of movies in our dataset for a given decade.
Plotting Fraction Passed
Adjust your list comprehension for calculating y_vals so that rather than calculating the
numbers of movies that pass the Bechdel Test for a decade, you instead plot the fraction of all movies from
that
decade that pass. You might also change the title to say "Fraction of Movies that Pass the Bechdel Test".
Hint: We want the numerator to be the number of movies that pass, and the denominator
should be the total number of movies from that decade.
You can run the same command as before to test your implementation:
python3 bechdel-graphs.py data-full.txt. Here's what you should see:
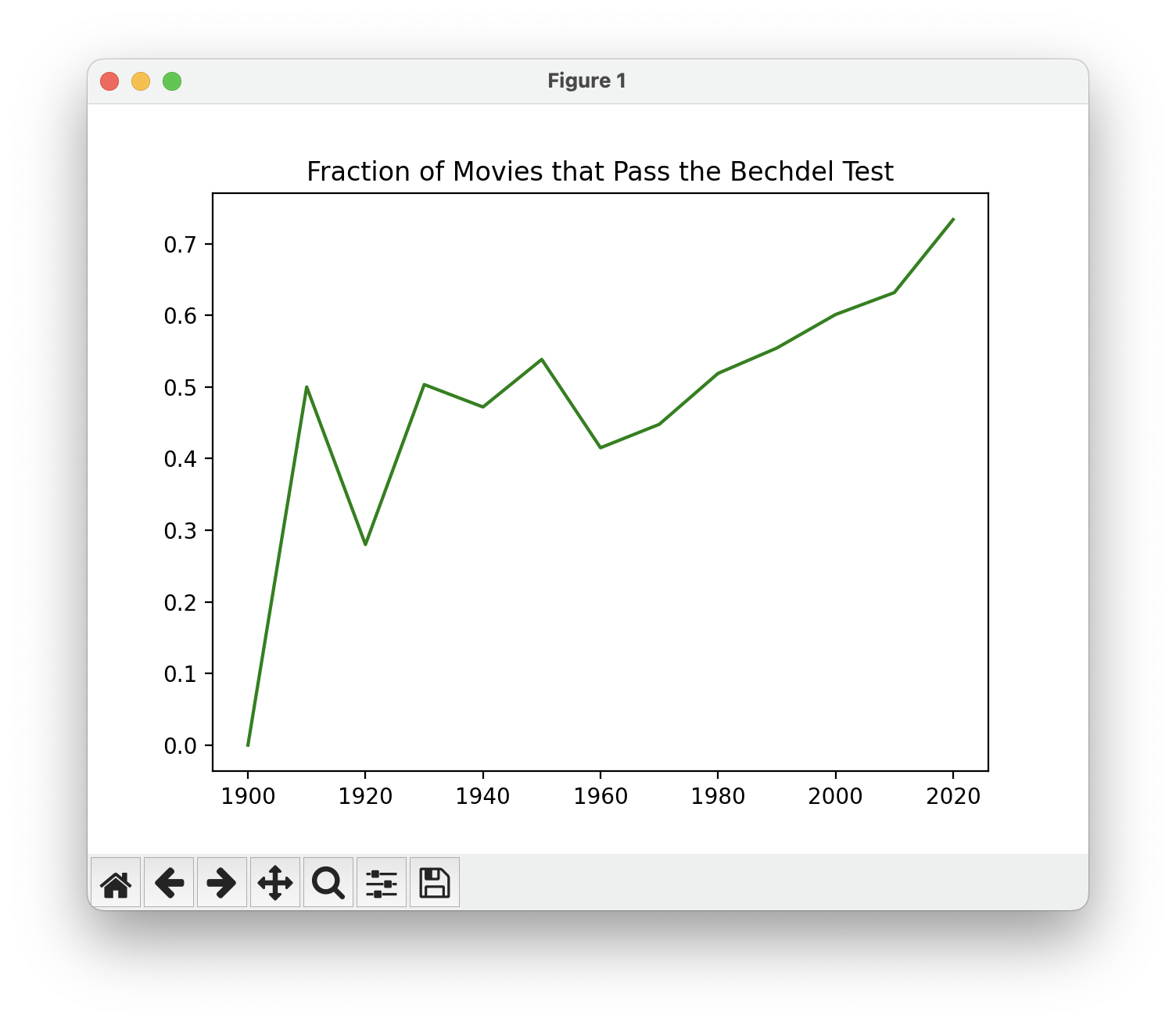
That's pretty cool! We no longer see that dropoff for the decade 2020. Instead, it looks like the number of movies that pass the Bechdel Test have been steadily increasing over time. Next time you watch a new movie, you might ask, is this movie contributing to this trend?