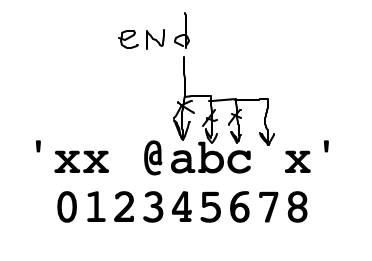
end = 4. Advance to space char with end += 1 in loop
Today: parsing, complex while loops, parse words out of string patterns
Here's some fun looking data...
$GPGGA,005328.000,3726.1389,N,12210.2515,W,2,07,1.3,22.5,M,-25.7,M,2.0,0000*70 $GPGSA,M,3,09,23,07,16,30,03,27,,,,,,2.3,1.3,1.9*38 $GPRMC,005328.000,A,3726.1389,N,12210.2515,W,0.00,256.18,221217,,,D*78 $GPGGA,005329.000,3726.1389,N,12210.2515,W,2,07,1.3,22.5,M,-25.7,M,2.0,0000*71 $GPGSA,M,3,09,23,07,16,30,03,27,,,,,,2.3,1.3,1.9*38 $GPRMC,005329.000,A,3726.1389,N,12210.2515,W,0.00,256.18,221217,,,D*79 $GPGGA,005330.000,3726.1389,N,12210.2515,W,2,07,1.3,22.5,M,-25.7,M,3.0,0000*78 $GPGSA,M,3,09,23,07,16,30,03,27,,,,,,2.3,1.3,1.9*38 ...
Or a less dry example, try to extract the hashtag from the text.
So I'm like, no way! #yolo, and they're like yazzo!
for/i/rangeThe for/i/range form is great for going through numbers which you know ahead of time - a common pattern in real programs. If you need to go through 0..n-1 - use for/i/range, that's exactly what it's for.
for i in range(n):
# i is 0, 1, 2, .. n-1
while - More FlexibleBut we also have the while loop. The "for" is suited for the case where you know the numbers ahead of time. The while is more flexible. The while tests on each iteration, stoping at the right spot. Ultimately you need both forms, but here we will switch to using while.
while Equivalent of for/i/rangeIt's possible to write the equivalent of for/i/range as a while loop instead. This is not the easieset way to go through 0..n-1, but it shows a useful while structure.
Aside: down in the CPU chip, there is a facility that resembles the while. Through layers of abstraction, your for/i/range in Python is constructed using the while down in the chip. You don't need to worry about this as a Python programmer. The for/i/range loop is an abstraction that Python reliably constructs for you, using what the chip has.
Here is the while-equivalent to for i in range(n)
i = 0 # 1. init while i < n: # 2. test # ... # use i in loop # ... i += 1 # 3. increment loop-bottom # (easy to forget this line)
double_char() written as a while. The for-loop is the correct approach here, so we are just showing how a "for" can written with "while".
1. Init i = 0
2. Test i < n
3. Increment i += 1 (loop bottom)
def while_double(s):
result = ''
i = 0
while i < len(s):
result += s[i] + s[i]
i += 1
return result
var += 1Start with end = 4. Advance to space char with end += 1 in loop
i In Bounds?Suppose the int i is indexing into a string, and I am changing it with i += 1 or i -= 1. What are the bounds for i remaining a valid index into the string?

In-bounds for increasing i:
i < length
In-bounds for decreasing i:
i >= 0
Python detail: surprisingly s[-1] does not give an error in Python, it accesses the last char, although this may not be what you want. For our algorithms, we treat i >= 0 as the boundary.
> at_word() (in parse1 section)
'xx @abcd xyz' -> 'abcd' 'x@ab^xyz' -> 'ab'
at_word(s): We'll say an at-word is an '@' followed by zero or more alphabetic chars. Find and return the alphabetic part of the first at-word in s, or the empty string if there is none. So 'xx @abc xyz' returns 'abc'.
First use s.find() to locate the '@'. Then start end pointing to the right of the '@'.
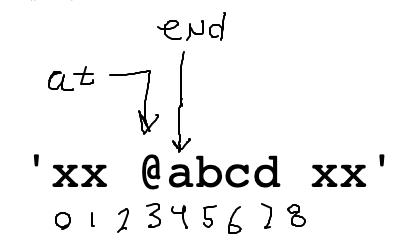
Code to set this up:
at = s.find('@')
if at == -1:
return ''
end = at + 1
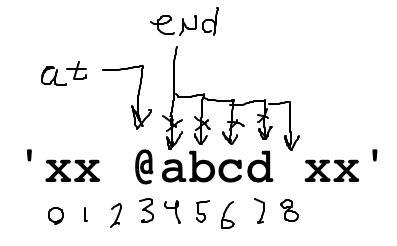
Use a while loop to advance end over the alphabetic chars. What is the test for this loop? Work it out on the drawing.
while ????
end += 1
Think about what while test is True while end is pointing at an alphabetic char. Draw T/F under each char for the test we want.
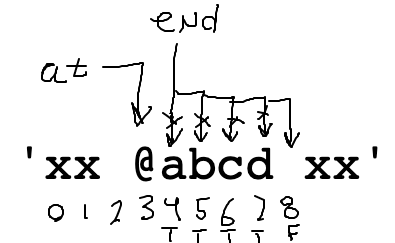
This loop is 90% correct to advance end:
# Advance end over alpha chars
while s[end].isalpha():
end += 1
Once we have at/end computed, pulling out the result word is just a slice.
word = s[at + 1:end]
return word
Put those phrases together and it's an excellent first try, and it 90% works. Run it.
def at_word(s):
at = s.find('@')
if at == -1:
return ''
end = at + 1
# Advance end over alpha chars
while s[end].isalpha():
end += 1
word = s[at + 1:end]
return word
That code is pretty good, but there is actually a bug in the while-loop. It has to do with particular form of input case below, where the alphabetic chars go right up to the end of the string. Think about how the loop works when advancing "end" for the case below.
at = s.find('@')
end = at + 1
while s[end].isalpha():
end += 1
'xx@woot' 01234567
Problem: keep advancing "end" .. past the end of the string, eventually end is 7. Then the while-test s[end].isalpha() throws an error since index 7 is past the end of the string.
The loop above translates to: "advance end so long as s[end] is alphabetic"
To fix the bug, we modify the test to: "advance end so long as end is valid and s[end] alphabetic".
In other words, stop advancing if end reaches the end of the string.
Loop end bug:
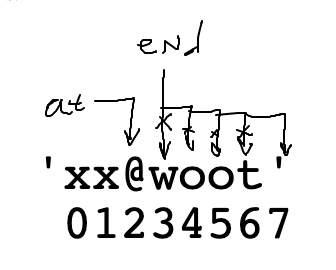
end < len(s) Guard TestThis "guard" pattern will be a standard part of looping over something.
We cannot access s[end] when end is too big. Add a "guard" test end < len(s) before the s[end]. This stops the loop when end gets to 7. The slice then works as before. This code is correct.
def at_word(s):
at = s.find('@')
if at == -1:
return ''
# Advance end over alpha chars
end = at + 1
while end < len(s) and s[end].isalpha():
end += 1
word = s[at + 1:end]
return word
The "and" evaluates left to right. As soon as it sees a False it stops, known as "short circuiting". In this way the < len(s) guard checks that end is a valid number, before s[end] tries to use it. This a standard pattern: the index-is-valid guard is first, then "and", then s[end] that uses the index. The guard stops the loop from running off the end of the string. We'll see more examples of this guard pattern.
while i < len(s) and .... s[i] ...:
i += 1
'woot' Bug - Very Specific InputWe say that having a few reasonable test cases will find the great majority of bugs, and this is true. This is how modern software is built and tested. However, we see a slightly unsettling pattern with the 'woot' bug — the bug is triggered only by a very specific pattern in the input data. After the '@', there must be a run of alphabetic chars going right up to the end of the string. If we did not have an test case with that pattern, the tests would pass code, even if the code has this bug in it.
Software is put out for use in the world, and then, out of millions of users, a user happens to make an input case which exposes a bug in the software. The user may file a bug report, or a crash-reporter system in the software may prompt the user to please submit it. The bug-report makes its way back to the engineers, and they may well react like "oh wow, look at this, we never thought of this case." There's so many users out there doing so many things, they will come up with cases you never thought of. With the user-submitted bug in hand, a new test case can be added, a so called "regression" test, that tests against this bug the software had one time, and should avoid having in the future.
s[at + 1:end]The slice s[at + 1:end] works fine, even though end is not a valid index, going 1 past the last char. How does this work?
>>> s = 'Python' >>> len(s) 6 >>> s[2:5] 'tho' >>> s[2:6] 'thon' >>> s[2:46789] 'thon'
What about
'xx @ xx'
at = 3 --^
end = 4 --^
s[at + 1:end] -> s[4:4]
exclamation(s): We'll say an exclamation is zero or more alphabetic chars ending with a '!'. Find and return the first exclamation in s, or the empty string if there is none. So 'xx hi! xx' returns 'hi!'. (Like at_word, but right-to-left).
Suggestions:
'xx hi! xx' -> 'hi!'
exclaim---^
start ---^
start --^
start -^ (loop end)
1. Set variable exclaim to point to the exclamation mark. (in starter code)
2. Set a variable start to the left of the exclamation mark. Write a loop to move start towards the start of the string, over the alphabetic chars. Slice out the answer - off-by-one details to think about here. Run this version, it 90% works.
3. Then add a guard to prevent start from running past the beginning of the string. As the loop goes right-to-left. The leftmost valid index is 0, so that will figure in the guard test.
Starter code
def exclamation(s):
exclaim = s.find('!')
if exclaim == -1:
return ''
# Your code here
start = ???
def exclamation(s):
exclaim = s.find('!')
if exclaim == -1:
return ''
# Your code here
# Move start left over alpha chars
# guard: start >= 0
start = exclaim - 1
while start >= 0 and s[start].isalpha():
start -= 1
# start is on the first non alpha
word = s[start + 1:exclaim + 1]
return word
See the guide for details Boolean Expression
The code below looks reasonable, but doesn't quite work right
def good_day(age, is_weekend, is_raining):
if not is_raining and age < 30 or is_weekend:
print('good day')
Because and is higher precedence than or as written above, the code above acts like the following (and evaluates before or):
if (not is_raining and age < 30) or is_weekend:
You can tell the above does not work right, because any time is_weekend is True, the whole thing is True, regardless of age or rain. This does not match the good-day definition above, which requires that it not be raining.
The solution we will spell out is not difficult.
Solution
def good_day(age, is_weekend, is_raining):
if not is_raining and (age < 30 or is_weekend):
print('good day')
> oh_no()
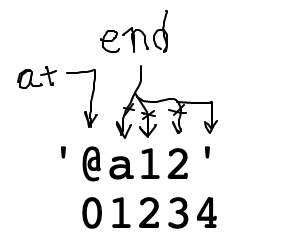
'xx @ab12 xyz' -> 'ab12'
at_word99(): Like at-word, but with digits added. We'll say an at-word is an '@' followed by zero or more alphabetic or digit chars. Find and return the alpha-digit part of the first at-word in s, or the empty string if there is none. So 'xx @ab12 xyz' returns 'ab12'.
We've reached a very realistic level of complexity for solving real problems.
Like before, but now a word is made of alpha or digit - many real problems will need this sort of code. This may be our most complicated line of code thus far in the quarter! Fortunately, it's a re-usable pattern for any of these "find end of xxx chars" problems.
The most difficult part is the "end" loop to locate where the word ends. What is the while test here? (Bring up at_word99() in other window to work it out). We want to use "or" to allow alpha or digit.
at = s.find('@')
end = at + 1
while ??????????:
end += 1
# 1. Still have the < guard
# 2. Use "or" to allow isalpha() or isdigit()
# 3. Need to add parens, since this has and+or
# combination
while end < len(s) and (s[end].isalpha() or s[end].isdigit()):
end += 1
def at_word99(s):
at = s.find('@')
if at == -1:
return ''
# Advance end over alpha or digit chars
# use "or" + parens
end = at + 1
while end < len(s) and (s[end].isalpha() or s[end].isdigit()):
end += 1
word = s[at + 1:end]
return word
Normally each Python line of code is un-broken. BUT if you add parenthesis, Python allows the code to span multiple lines until the closing parenthesis. Indent the later lines an extra 4 spaces - in this way, they have a different indentation than the body of the while. There's also a preference to end each line with an operator like or .. to suggest that there's more on the later lines.
while (end < len(s) and
(s[end].isalpha() or
s[end].isdigit())):
end += 1
More practice.
'xx www.foo.com xx' -> 'www.foo.com'
dotcomt2(s): We are looking for the name of an internet host within a string. Find the '.com' in s. Find the series of alphabetic chars or periods before the '.com' with a while loop and return the whole hostname, so 'xx www.foo.com xx' returns 'www.foo.com'. Return the empty string if there is no '.com'. This version has the added complexity of the periods.
Ideas: find the '.com', loop left-right to find the chars before it. Loop over both alphabetic and '.'
def dotcom2(s):
com = s.find('.com')
if com == -1:
return ''
# "or" logic - move leftwards over
# alphabetic or '.'
start = com - 1
while start >= 0 and (s[start].isalpha() or s[start] == '.'):
start -= 1
return s[start + 1:com + 4]