Due August 5th, 11:59pm.
Written by Awni Hannun and Chris Piech.
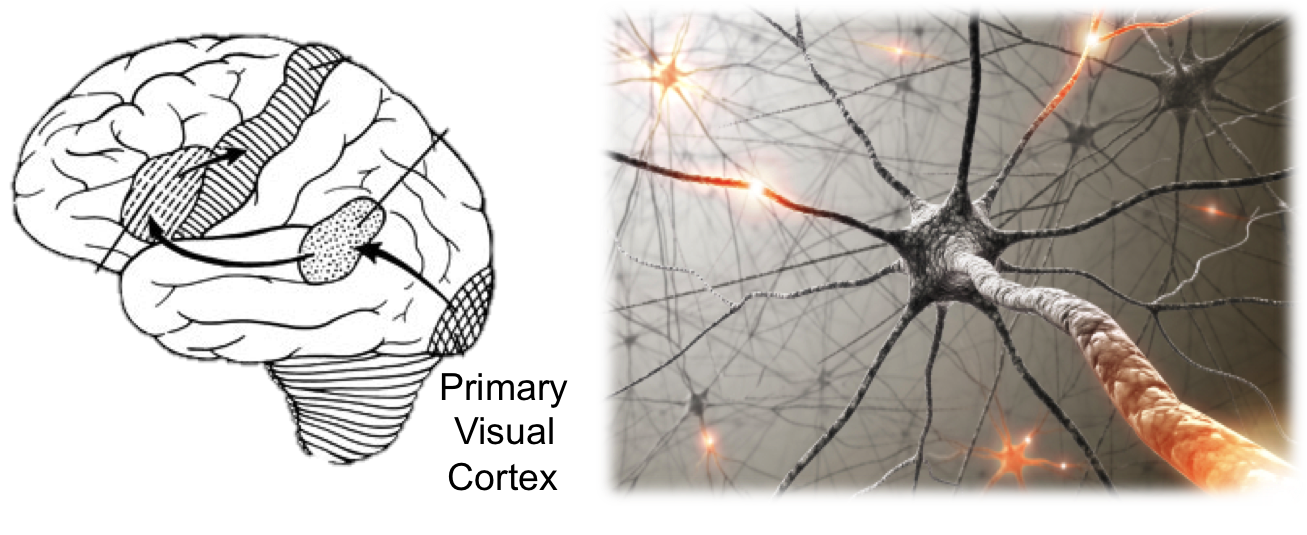
Figure 1: When human's view the world, raw retina signals are processed by the visual cortex (left). The first neurons (right) are hypothesied to each represent whether a particular edge is seen by a particular part of the eye. Unsupervised Feature Learning and Supervised Classification.
Introduction
One of the most exciting recent developments in machine learning is the ability of agents to learn how to represent the world without supervision. It is particularly interesting when the learned representations are similar to the way our brains process information as it seems like a step in the direction of strong AI.
In this assignment you are going to implement a cutting edge algorithm that will learn a feature representation of images analogous to the human visual cortex. Using these "features" your program will then classify the content of images in the CIFAR-10 dataset.

Figure 2: Various images of airplanes (top) and birds (bottom) from the CIFAR-10 dataset. When finished your visual cortex should be able to recognize the content of these images.
The code for this project contains the following files, available as a zip archive.
Key files to read:
featureLearner.py |
This file defines an object that has methods to both run K-means unsupervised learning and feature extraction. You will modify this file in the assignment. Do not change existing function names, however feel free to define helper functions as needed. |
classifier.py | This file defines an object for training and testing the logistic regression classifier. You will modify this file. Do not change existing function names, however feel free to define helper functions as needed. |
evaluator.py |
This file contains code to evaluate how your classifier performs on the test set. You should not need to modify this file but may want to read through the comments to understand how it works. |
util.py |
This file contains the
Image
class which will create objects that represent data for each image. Also contained in this file are several helper methods for viewing features and images. You should not need to modify this file although you should read through it to understand how it works. |
Submission: Submission is the same as with the Pacman and Driverless Car assignments. You will submit the files
featureLearner.py
and
classifier.py. See submitting for more details.
Evaluation: Your code will be autograded for technical correctness. Please do not change the names of any provided functions or classes within the code, or you will wreak havoc on the autograder. However, the correctness of your implementation -- not the autograder's judgements -- will be the final judge of your score. If necessary, we will review and grade assignments individually to ensure that you receive due credit for your work.
Academic Dishonesty: We will be checking your code against other submissions in the class for logical redundancy (as usual). If you copy someone else's code and submit it with minor changes, we will know. These cheat detectors are quite hard to fool, so please don't try. We trust you all to submit your own work only; please don't let us down. If you do, we will pursue the strongest consequences available to us, as outlined by the honor code.
Getting Help: You are not alone! If you find yourself stuck on something, contact the course staff for help. Office hours and piazza are there for your support; please use them. We want these projects to be rewarding and instructional, not frustrating and demoralizing. But, we don't know when or how to help unless you ask.
Tasks
This project, like most python machine learning projects, uses numpy and matplot lib. We wrote an install script that makes it one command to install the packages. If you don't have numpy and matplotlib (or you are not sure) run the install script that came with the project:
python install.pyIf for some reason you have trouble installing the packages, let us know and we can help you work through any problems. In the mean time you could develop your solutions on the corn machines.
Good to go? Next lets, get you familiar with the dataset! Open the python interpreter (type
python
in the command-line) and run:
import util trainImages = util.loadTrainImages() firstImage = trainImages[0] firstImage.view() trainImages[106].view()

Figure 4: An example from each image class. Left: A bird, Right: A plane.
You should see the two images in Fig 3. In the training set planes are given the label 0 and birds the label 1. To see the label of an image type:
trainImages[0].label trainImages[106].label
Now lets see how images are stored. Each image is a 32 by 32 square (yes, they are small). Images are broken down into sixteen "patches" each of which is 8 by 8.
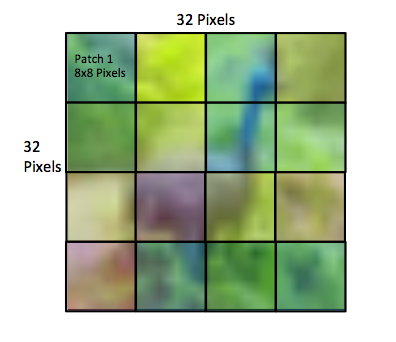
Figure 3: The sixteen patches of size 8x8 pixels corresponding to an image of size 32x32 pixels.
You can get the patches of an image by calling getPatches on your image.
patches = firstImage.getPatches()
Patches in our data set are simple! They are lists of 64 positive or negative floating point numbers (one entry for each of the 64 pixels in the patch). Lets print one out:
len(patches) firstPatch = patches[0] len(firstPatch) firstPatch
We got these numbers by transforming pixels in a similar way to how the human eye sees light. Negative numbers are for when the eye sees a dark pixel and positive numbers are for when the eye sees a light pixel. A computer trying to learn airplanes vs birds using these raw "features" will not be able to accurately recognize the difference between birds and planes. The patch representation is too low level.
1. Unsupervised Learning
A simple yet powerful insight in 2012 was that an unsupervised agent can learn feature representations based on centroids
of structured subsections of the training data. In this part of the assignment you will implement K-means clustering to learn
centroids for image patches. Specifically you should fill out the method
runKmeans in the file
featureLearner.py.

Figure 4: 20 centroids learned from K-means on patches from the first 1000 training images. Notice that the centroids look like edges!
Since each of our image patches are 64 floating point numbers, the centroids that K-means finds will also be 64 floating point numbers. We start you off by initializing K-means with random centroids where each floating point number is chosen from a normal distribution with mean 0 and standard devation 1.
In order to determine if K-means has converged, calculate and print the error after each iteration. The error for k-means is defined as the sum of squared euclidean distances of each training patch to its closest centroid.
Where $m$ is the number of patches, $x^{(i)}$ is the $i$th patch and $\text{Centroid}(x^{(i)})$ is the centroid that the $i$th patch is assigned to after the most recent iteration.
Test the K-means code with the provided test utility in
evaluator.py
by running:
python evaluator.py -k -t
If you've passed the test above, try running your K-means method with a bigger dataset. After 50 iterations of K-means with the first 1000 training images and 25 centroids, our error is 807,189.
You should be able to get the same results by running the
evaluator
and seeding the random number generator with the
-f
flag. Even if you do not run k-means with a fixed seed, you should get similar error.
python evaluator.py -k -f
Another way to determine if your K-means algorithm is learning sensible features is to view the learned centroids using our provided utility function. To view the first 20 learned centroids, run
python evaluator.py -k -f -vYour centroids should look similar to Fig 4. Notice how the centroids resemble edges. Thats particularly interesting because the first layer of neurons in our visual cortex also detects edges.
Numpy: Some Numpy functions that may come in handy:
2. Feature Extraction
How can we our patch centroids to generate features that will be more useful for the classification task then the raw pixel intensities we started out with? The answer is to represent each patch by the distance to the centroids that it most resembles.
In this portion of the assignment you will implement the
extractFeatures
method in the
featureLearner.py
file. This method takes one image object, and returns features for that image using the learned centroids.
There will be one feature for each patch, centroid combination which will be a representation of how similar the patch is to the centroid (see the exact definition below). Therefore, each image will have $16$x$K$ features where $16$ is the number of patches per image and $K$ is the number of centroids learned in part 1.
The relative activation of centroid $j$ by patch $i$ ($a_{ij}$) is defined to be the average distance from patch $i$ to all centroids minus the distance from $i$ to $j$.
The format of the features should be a 1D array. Test your feature extraction code by running
python evaluator.py -e
If the test passes, the first layer of your visual cortex is working!
3. Supervised Learning
Our final task is to use our better feature representation to classify images as birds or planes. You will implement both parts of the supervised learning pipeline: training (learning a hypothesis function) and testing (using your hypothesis function to make predictions)
For this assignmnet you should write a logistic regression classifier using batch gradient descent. First fill out the method train in the file classifier.py
to learn all the parameters you will need to make predictions. The images passed in to you will be in their original "raw" form. Make
sure to use your FeatureLearner from the previous parts so that you can turn images into a higher level representation.
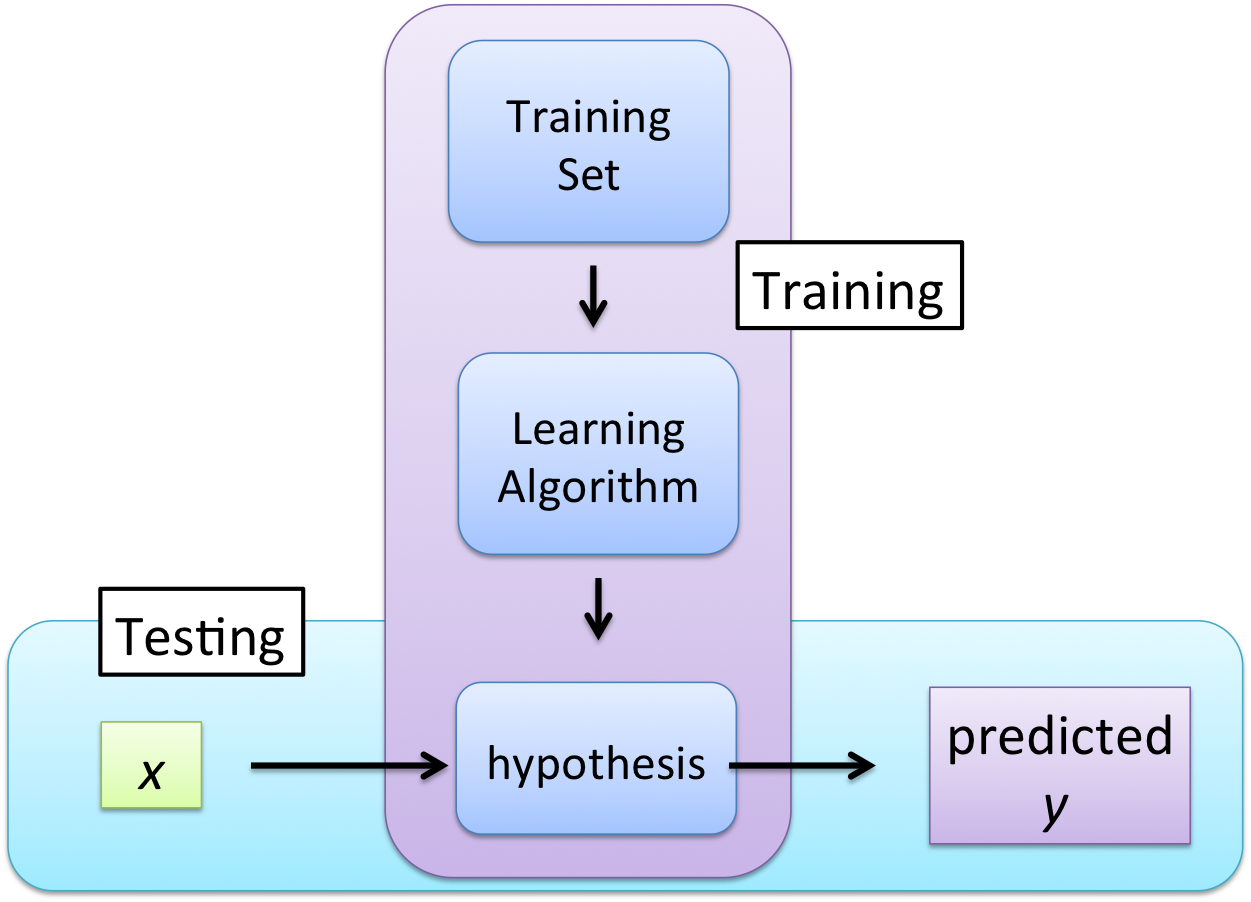
Figure 5: The supervised learning pipeline.
Specifically, write a logistic regression classifier that does not use an intercept variable. Solve for the weights using a batch (standard) gradient descent update that minimizes the likelihood objective. You should not use a regularization term.
In our solution, we initialize the weight vector from a zero-mean gaussian with 0.01 standard deviation.
You can test your logistic regression classifier by running
python evaluator.py -s
To save time in computation you can run a toy version of the full pipeline by passing
evaluator
the
-d
flag.
python evaluator.py -d
Run gradient descent for
self.maxIter = 5000
iterations before stopping. After running gradient descent for 5000 iterations using only the first 1000 training images and a learning rate $\alpha=1e-5$, our negative log-likelihood evaluated to $400.8$.
Next implement the
test
method in the
classifier.py
file. This method takes as input a list of test
Image
objects and makes a prediction as to whether each image is a plane or a bird (0 or 1 respectively).
Now you are ready to run the entire pipeline and evaluate performance! Run the full pipeline with (include the
-f
flag to recreate our results):
python evaluator.py
The output of this should be two scores, the training and the testing accuracy. Following the steps above our classifier achieves 85.5% accuracy on the training set and 72.8% accuracy on the test set.
4. What does this mean?
One commonly held hypothesis is that humans process natural stimuli such as images in multiple layers of representation, starting with the raw sensory stimulus and slowly building higher and higher levels of representation. For example in human vision the raw sensory stimulus received in the retina is passed to a first layer of neurons in the visual cortex. This first layer is hypothesized to have many neurons known as simple cells all of which code for different features in the input. In particular, much evidence points to these simple cells as being edge detectors, i.e. they each code for a specific edge of different orientation and translation within the image. The new representation of what the eye sees becomes the activations of these simple cells which the next part of the brain can turn into higher level understanding like: "I'm looking at a bird."
The unsupervised algorithm you implemented was able to learn a feature representation of images similar to the first layer of processing in the visual cortex. In other words, the algorithm wasn't told via supervision or hard coded in any other way to learn to represent an image as it's component edges. Amazingly, that's what the agent found to be the most important features in an image on its own! Unsuprisingly, since our features were similar to the human brain we were quite good at telling the difference between birds and planes. This result suggests the AI community may be approaching an understanding of the learning algorithm used by the human brain.
5. Extensions (Optional)
README
file in your submission that documents everything you did. Some suggestions for extensions include:
-
Get classification accuracy high! We will give bonus points to student with best classification accuracy. Note all extra work should be done outside of existing functions in order to not mess up the autograder. Report your best accuracy in your
README. We will run your code to verify this. - Try out using a different linear classifier, such as a linear SVM, and report how it performs.
- Overfit the training data with many centroids and add a regularizer to your cost function to see if you can improve generalization error
- Anything else you can dream up!
References
- Learning Feature Representations with K-means, Adam Coates and Andrew Y. Ng. In Neural Networks: Tricks of the Trade, Reloaded, Springer LNCS, 2012.(pdf)
- An Analysis of Single-Layer Networks in Unsupervised Feature Learning, Adam Coates, Honglak Lee, and Andrew Y. Ng. In AISTATS 14, 2011.(pdf)
- Learning Multiple Layers of Features from Tiny Images, Alex Krizhevsky, 2009. (pdf)
Project 3 is done!