Due Aug 5th, 11:59pm.
Written by Chris Piech, Sarah Xing.
Instructions
This problem set has three problems that you should submit an answer for (Brain, Tomatoes and Autism). Write your solutions to each of the three problems in separate documents and save them to files named p1.pdf, p2.pdf and p3.pdf.
Submission will work just like pset 1. See submitting for more details.
1. Brain Computer Interface
A brain-computer interface is a pathway between a brain and an external device. Research in this area aims to assist, improve, or repair cognitive and sensorimotor functions and one of the research objectives is to predict whether someone is trying to move a computer mouse with his or her brain. You decide to build an SVM to classifier.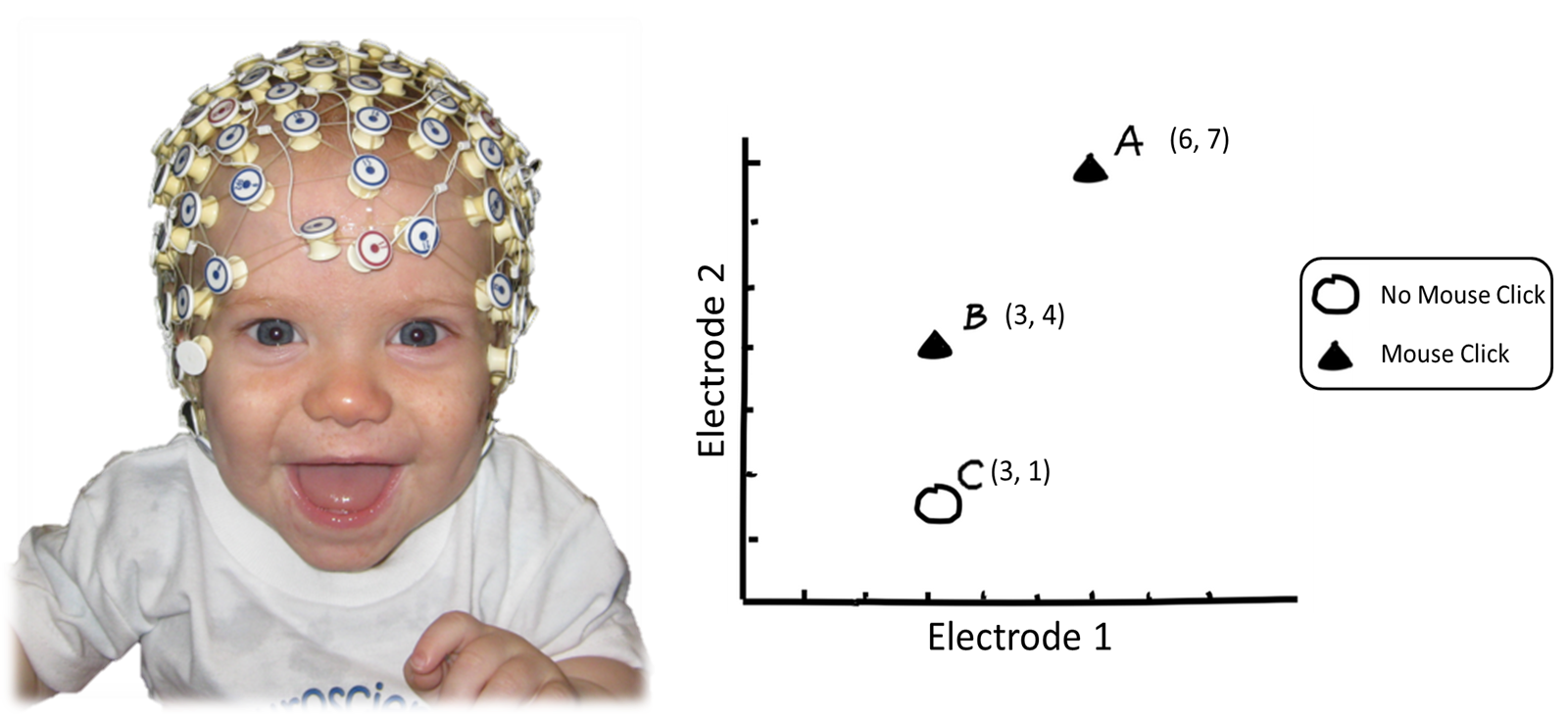
Figure 1: (left) This baby is set up with many sensors to record her brain activity. In our example training data was only collected with two sensors. (right) The three hardest to classify points.
| a | Our classifier has two input features (one for each electrode), measuring brain waves from different areas of the brain.
Consider a subset of data samples as shown in figure 1 and their coordinates:
|
||||||||
| b | Consider two scenarios: (1) You observe very high training error and very high testing error. Adding more data doesn't seem to be helping. (2) You observe very low training error but very high testing error. Adding data seems to improve your testing error slightly. Which of the two scenareos represents overfitting? | ||||||||
| c | If you notice your model overfitting your data, which of the following techniques can you utilize to address the problem? Add more features, remove/combine features, add training data, remove training data, use a more complicated kernel. Which techniques would you use to address underfitting? |
2. Rotten Tomatoes
We have a movie rating site with two critics who have different, structured, well respected tastes. The critics both watch movies and then rate them out of 10. We want to explore the ratings to see if there is any patterns which might shine light on good ways to categorize movies. The critics have rated 5 movies and given the ratings: (1, 4), (5, 6), (7, 5), (7, 8), (2, 4) such that the first critics rating is the first element in the tuple and the second critics rating is the second.

Figure 2: Our competitor website.
Walk through the k-means algorithm starting with your centroids at (6, 7) and (7, 8). Stop when your centroids no longer change. What are the final two centroids? What are the final assignments of points to clusters? I found it very useful to use a python interpreter and define a euclidean distance function. Show your work for partial credit.
3. Autism and Neuroscience
Autism is a disease which is complex, hard to diagnose and has a wide range of different symptoms. In fact, some researchers have proposed that what we call Autism might actually be a few different diseases.
A lab at Stanford has collected f-MRI brain scans of 300 Autistic children. The brain scans are represented as a numeric value for each of the $M$ voxels (like a 3D pixel) in the brain. For each subject the lab also has a set of $N$ behavior tests. You may assume the behavior tests are all pass / fail. You have been given this data to analyze. The brain voxels have been normalized and reshapped so that all brains are the same size. For privacy reasons you are not allowed to know any more information about the subjects.

Figure 3: A single brain scan. Voxels with high density of brain matter are shown in light blue. Voxels with low density of brain matter are shown in dark blue.
Come up with an initial research plan. Your plan should be brief: each section could be as short as a few sentences and should be no longer than two paragraphs. Your research plan should include the three following things: A hypothesis, A methodology (be precise about what algorithms you would use) and you should explain how you would evaluate your results.