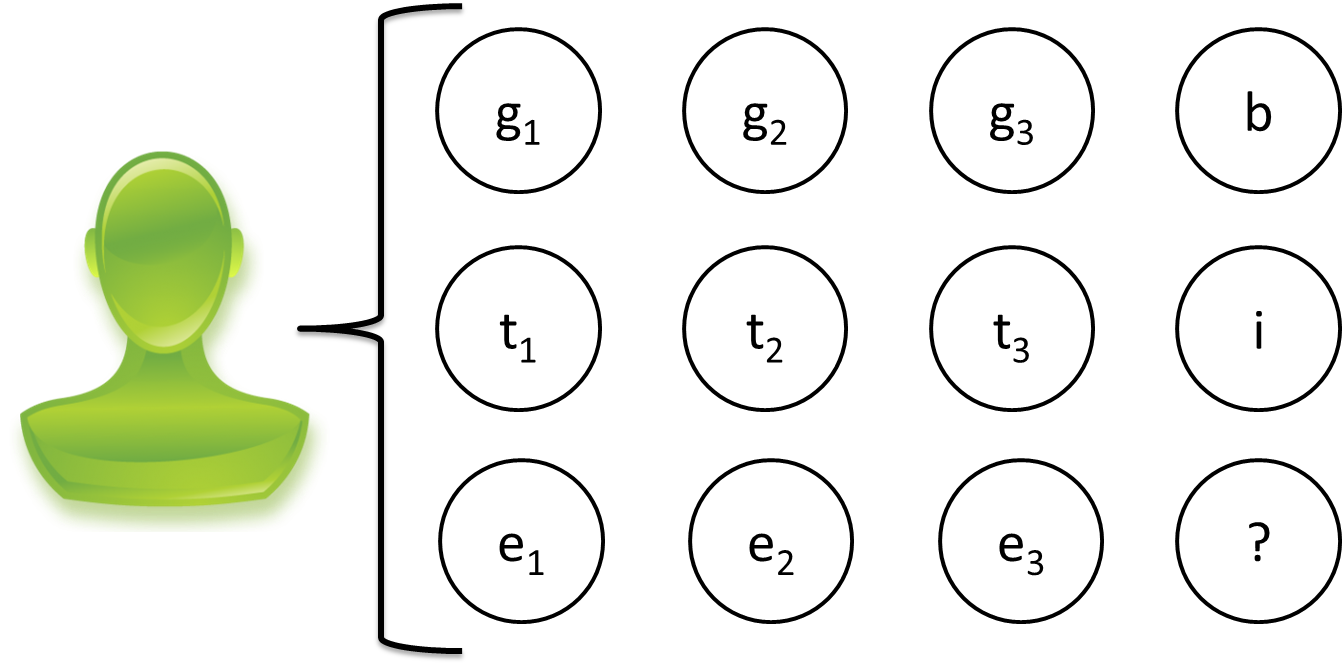
For each student we have a large set of observed variables. The three grades the student received on the first pset $g_1, g_2, g_3$, how much they enjoyed each problem $e_1, e_2, e_3$ and how much time it took them $t_1, t_2, t_3$. We also know the student's background $b \in \left\{ {bs, ms, phd, scpd}\right\}.$
Getting accurate feedback for an assignment is a cornerstone of the educational process. But it can be obscured by the presence of grading errors. To maximize our grading accuracy we can use related variables to notice which assignments have suprisingly high or suprisingly low grades and warent a deeper inspection. This handout describes the problem of predicting which homeworks have been misgraded (an unsolved problem) using bayesian nets (a beautiful formalization).
The Basic Idea
Submit a model by Monday at 11:59pm and stand a chance to win extra credit and make a novel contribution to education research.
Modeling
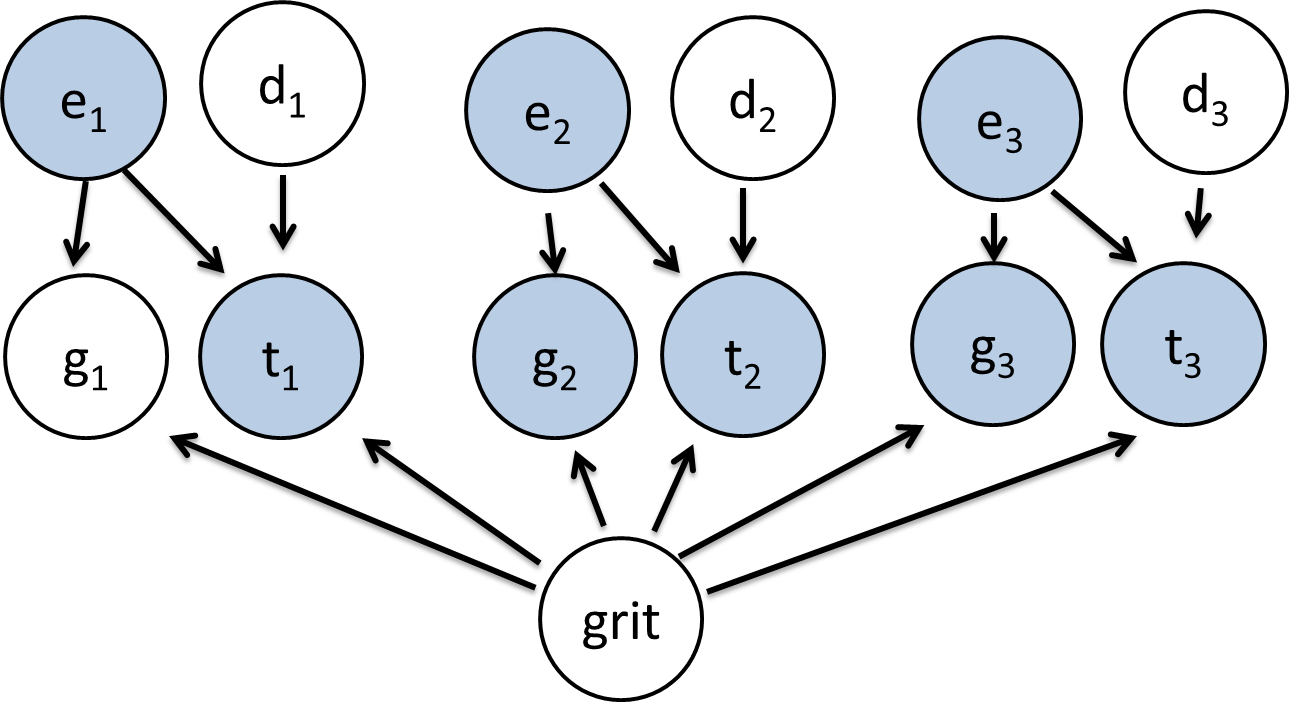
Model A: The variables and their relationships. Depicts a single student.
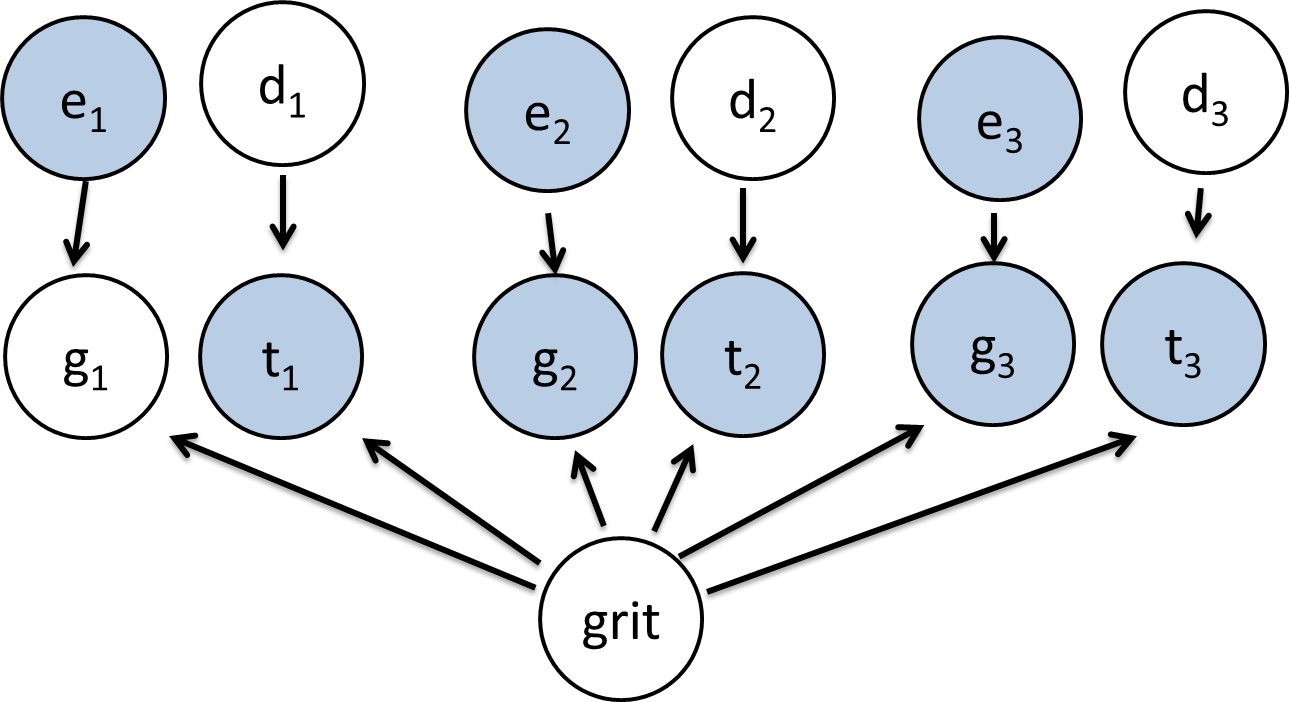
Model B: Also only depicts one student.