Research Discussions
The following log contains entries starting several months prior to the first day of class, involving colleagues at Brown, Google and Stanford, invited speakers, collaborators, and technical consultants. Each entry contains a mix of technical notes, references and short tutorials on background topics that students may find useful during the course. Entries after the start of class include notes on class discussions, technical supplements and additional references. The entries are listed in reverse chronological order with a bibliography and footnotes at the end.
Class Discussions
Welcome to the 2021 class discussion list. Preparatory notes posted prior to the first day of classes are available here. Introductory lecture material for the first day of classes is available here, a sample of final project suggestions here and the calendars of invited talks and discussion lists from previous years are available in the CS379C archives. Since the class content for this year builds on that of last year, you may find it useful to search the material from the 2020 class discussions available here.
Following the 2020 class, the course instructor and teaching assistant met with several interested students on a regular basis to discuss more advanced topics and projects than those covered in 2020 with the aim of integrating these into the 2021 version of course. The field is progressing at an incredible rate and there have been several advances in the intervening months that warrant more than a passing mention. We chronicled our weekly discussions and related project ideas in an appendix to the 2020 class discussion list that you are welcome to take a look at here if you are interested.
July 15, 2021
%%% Thu Jul 15 05:45:29 PDT 2021
Channeling Your Inner Turing Machine
Following up on ideas introduced in the July 11 entry, I reverted to traditional concepts from computer science in an effort to explain how human beings become so adept at handling hierarchies and recursion. The main insight is that humans and conventional computers simply flatten hierarchies and serialize recursive structures.
The primate brain is Turing complete, but it is difficult to master for much of anything besides running and writing motor programs. During development, we create a virtual machine on top of our innate computational substrate that enables us to read, write and run programs in the form of stories communicated by natural language.
In acquiring a natural language, you learn how to serialize your thoughts and express complicated narratives with many twists and turns. You become adept at keeping track of multiple threads in a story involving different characters, remembering who said what, identifying the referent of pronouns, and handling recurrent structure.
Children learn to attribute goals to the agents in stories. They learn that agents construct plans to achieve goals, often have multiple, possibly conflicting goals and multiple plans for achieving them, and that goals have a natural hierarchy and dependency structure in which one goal's postconditions satisfy another goal's preconditions.
By the age of five, most children have the prerequisites for learning a programming language. Their first decade is dedicated to developing their latent von Neumann machine and learning a series of domain-specific languages (DSL) culminating in a language facility capable of interpreting any program expressed in natural language.
The maturation of your biological computing machinery is mirrored by the requirements of the DSLs that you learn as a part of development, starting with simple motor plans, graduating to more complicated recipes for everything from climbing the stairs in your home to preparing a peanut butter sandwich for your lunch.
The earliest DSL's correspond to the machine language for your body and learning to write programs in that language amounts to experimenting with sequences of primitive actions guided by an exploratory instinct and reward of novel experience. Subsequent learning benefits from human tutors following simple training protocols.
The neural substrate is highly plastic allowing training to proceed in sync with the complexity of the concepts to be learned. The first priority is to learn what essentially constitutes the firmware of your brain. Once established, you never install a full update of that firmware, only patches intended to fix bugs introduced during development.
During early development, a good tutor points out problems and corrects mistakes. This supervision is relaxed over time, with the burden of identifying and correcting problems shifting from tutor to student. It is because of this early advantage that learning occurs so quickly, but the child must learn the logical-thinking skills required for identifying and repairing bugs largely on its own.
| |
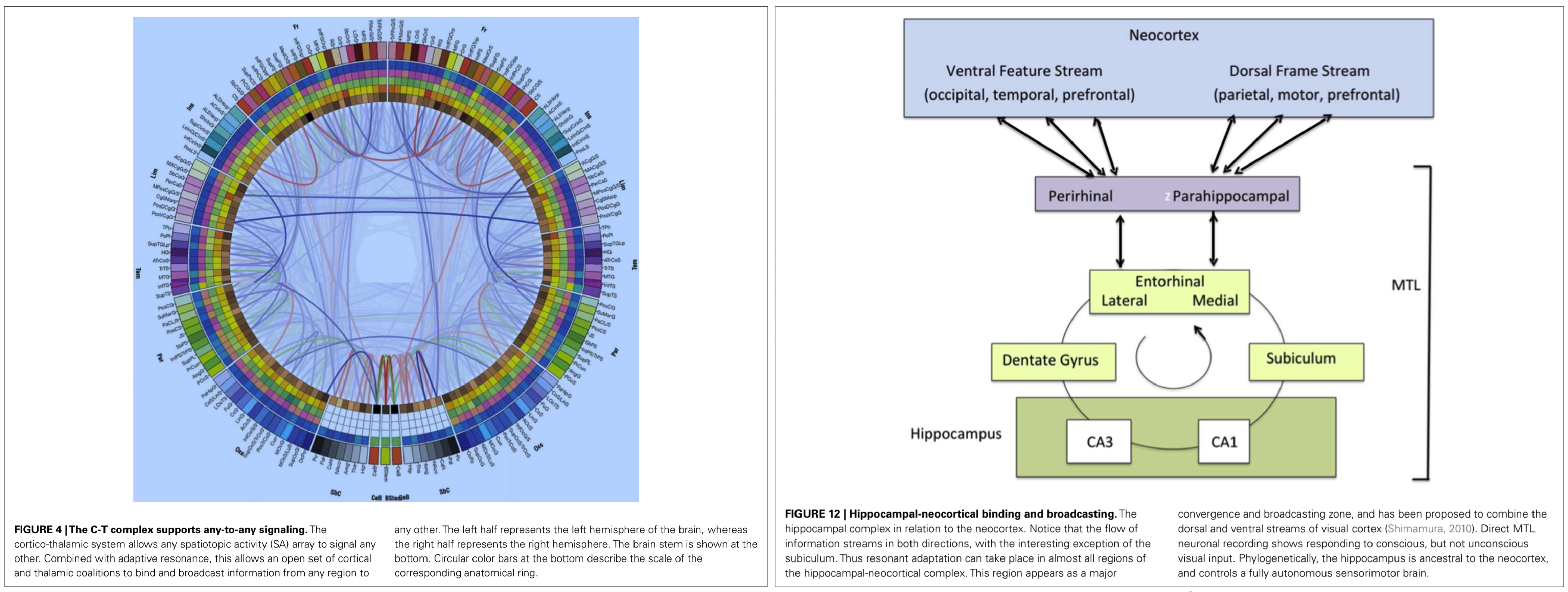
| Figure 1: Two figures from Baars et al [14] are reproduced here for the reader's convenience in understanding the discussion in the main text. The paper is published in Frontiers in Psychology an open-access journal and available here for download. | |
|
|
Cell Assemblies & Prediction Machines
You can think of the time between infancy and early adulthood as primarily dedicated to acquiring a general-purpose vocabulary grounded in the physical environment that we directly experience throughout our extended development along with a set of skills for using that vocabulary to express useful knowledge about how best to exploit the affordances that the environment offer. There is no mystery how we learn novel skills including skills that involve abstract reasoning. The mammalian brain and the human brain, in particular, is a predictive machine; our brains approach every problem as a problem of prediction [102, 45, 207].
As we learn and explore the environment, we constantly encounter new situations that are similar enough to previously encountered ones that we can describe and take advantage of them by adapting existing skills. Rather than allocate scarce neural resources, we simply reuse our existing knowledge and skills where possible and supply patches to handle the differences. For the most part, all of the learning from now is essentially one-shot or zero-shot imitation learning. To facilitate such learning, new information is layered on existing cortical tissue by learning to create, combine, and alter (reprogram) cell assemblies that are associated with abstract concepts and defined by the enabling of inhibitory and excitatory neurons controlled by circuits in the hippocampus and prefrontal cortex.
This implies that no new axons, dendrites, or synapses are formed and that the activation of neurons in semantic memory in the inferior parietal and temporal lobes is determined by altering the programming of inhibitory neurons in layer-five and excitatory neurons in layers two through six using some variant of Hebbian learning. It is hypothesized the hippocampus and prefrontal cortex play a central role in the processes by which cell assemblies are created, activated, altered, and maintained. Elsewhere in this log, we've discussed the role of the hippocampus and the notion of a global neuronal workspace spanning the neocortex that facilitates both conscious and unconscious attention.
Figure 1 shows two figures from Baars et al [14] illustrating, on the left, the pathways between neocortical regions comprising the global workspace and, on the right, the role of the hippocampus and prefrontal cortex in supporting the transfer of information between regions to facilitate neural computations. See Modha and Singh [183] on the graph structure of the network shown on the left, and Mashour et al [175] for details regarding how cell assemblies are activated and give rise to cascades of activation.
For additional background on the organization of the underlying neural structure shown graphic on the left in Figure 1, Binder and Desai [39] summarize progress in understanding the structural-functional relationships at the level of cortical areas building on the work of Korbinian Brodmann [44], and Amunts and Zilles [11] review what is known about the structural-functional relationships underlying the cytoarchitectural divisions in the brain at the level of cortical areas. See relevant class notes here and here.
Computational Modeling Technologies
Papadimitriou et al [193] describe a mathematical model of neural computation based on creating, activating, and performing computations on cell assemblies. They define a simple abstraction for representing assemblies and provide a repertoire of operations that can be performed on them. Using a formal model of the brain intended to capture cognitive phenomena in the association cortex, the authors describe a set of experiments demonstrating the operations performing computations and prove that under appropriate assumptions that their model can perform arbitrary computations.
Rolls et al [215, 153] present a quantitative computational theory of the operation of the hippocampus as an episodic memory system. "The CA3 system operates as a single attractor or auto-association network (1) to enable rapid one-trial associations between any spatial location (place in rodents or spatial view in primates) and an object or reward and (2) to provide for completion of the whole memory during recall from any part. The theory is extended to associations between time and object or reward to implement temporal order memory, which is also important in episodic memory."
Ramsauer et al [206] show that the attention mechanism in the transformer model [235] is the update rule of a modern Hopfield network [159] with continuous states. This new Hopfield network can store exponentially (with the dimension) many patterns, converges with one update and has exponentially small retrieval errors [88]. Seidl et al [222] demonstrate that modern Hopfield networks are capable of few- and zero-shot prediction on a challenging prediction problem related to drug discovery that has interesting analogs in other application areas.
Miscellaneous Loose Ends: The three modeling technologies in the previous subsection represent a sample of potential algorithmic solutions to the computational problems involved in implementing a complementary learning system that roughly models the hippocampus and supports a scalable approach to rapid learning based on Hebbian cell-assemblies. We plan to resurrect this theme in designing the syllabus for CS379C in the Spring of 2022. The rest of the discussion listing for this year includes many entries exploring alternative solutions some of which we'll return to next year. You can find the BibTeX references including abstracts for several of the papers that were useful in compiling the previous subsection here1.
July 11, 2021
%%% Sun Jul 11 04:36:58 PDT 2021
Complementary Learning Models
This poster summarizes and illustrates the component conceptual and architectural parts of the hierarchical complementary learning system [160] (CLS) model I've been working on over the last three months. By way of introduction, the following list briefly summarizes the six subcomponents / talking points labeled A through F in the poster:
A provides two views of the hippocampal formation (HPC): a simplified anatomical rendering on the left and a schematic block diagram on the right illustrating the primary information processing networks in the hippocampus along with their interconnecting pathways – see Figure 7 in [77] for more detail. C is the analogous description for the basal ganglia (BG) – see Figure 6 in [77] for more detail.
B is a rendering of the PBWM model – prefrontal-cortex (PFC) + basal-ganglia (BG) + working memory (WM) – extended to include the hippocampus (HPC) as the basis for complementary learning. The diagram illustrates the role of the HPC in influencing action selection by supplementing information the BG obtains from posterior cortex and assisting the PFC by suggesting episodic memory – see O'Reilly and Jilk [189] and Huang et al [142].
D is a modification of Box 2 in Merel et al [177] highlighting in forest green the three structures that roughly align with levels L1, L2, and L3 in the current hierarchical model that Yash has been working on and Juliette is using as the basis for designing the curriculum training protocol – see Figure 2 below. I've also made changes to incorporate the hippocampal formation in accord with the PBWM + HPC model in B.
E shows a recent model of the hippocampus that includes pathways by which the HPC can alter the activity of circuits in frontal and posterior cortex – see Kleinfeld et al [154] for details. This model is one of several attempting to understand how the four subregions – CA1, CA2, CA3, and CA4 – combine to support capabilities beyond the traditional spatial reasoning tasks that are the subject of most mouse studies.
| |
| Figure 2: A modification of Box 2 in Merel et al [177] highlighting in forest green the three cortical and subcortical structures that roughly align with levels L1, L2, and L3 in the hierarchical model described in Figure 11, and adding the hippocampal formation as providing a basis for complementary learning. | |
|
|
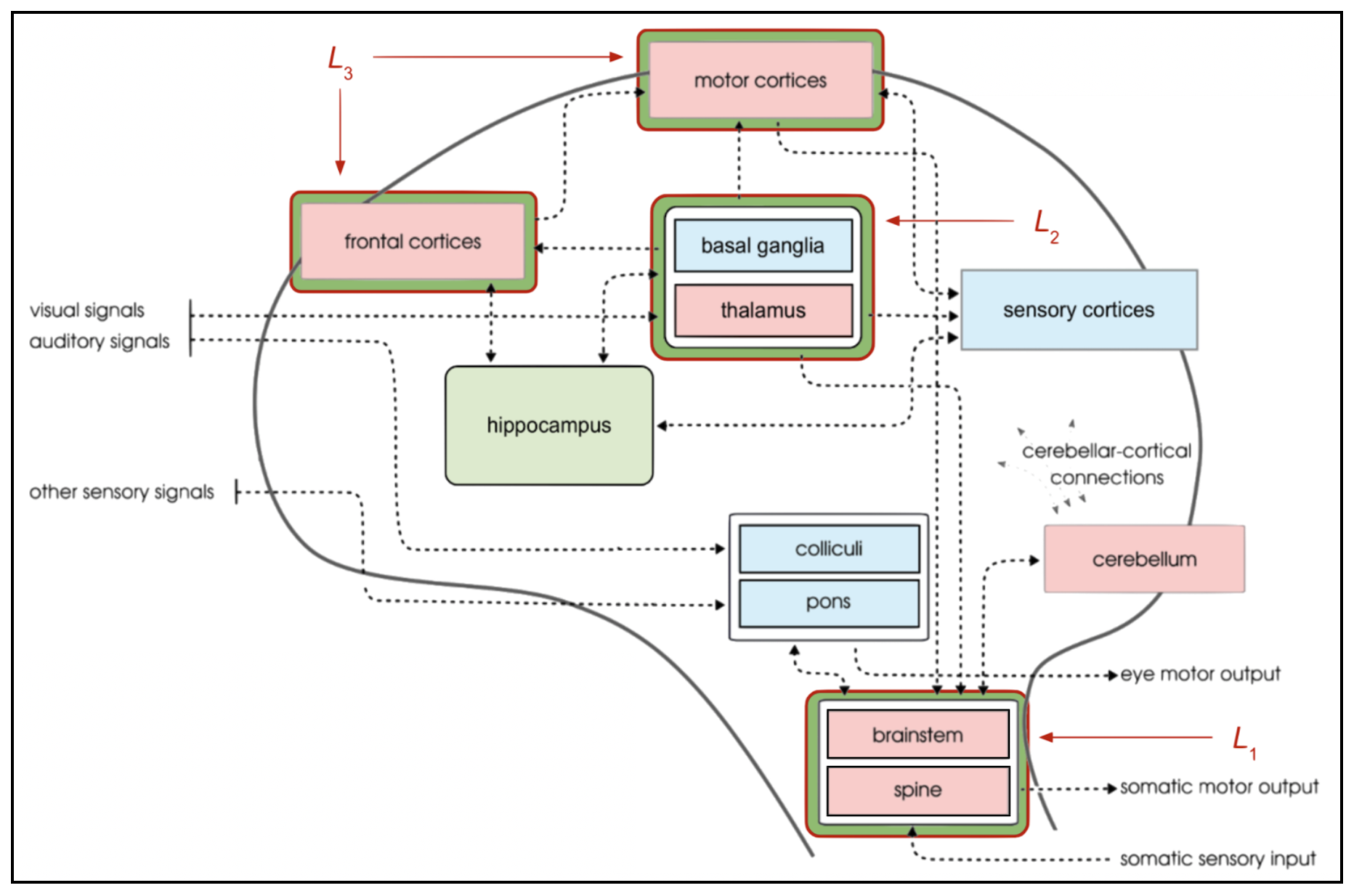
I revised the original cognitive version of Box 2 in Merel et al [177] to include the hippocampal formation and the reciprocal connections predicted in the O'Reilly et al CLS extension of PBWM [142, 189] (B) and Figure 1 in Kleinfeld et al [154] (E). We might want to feature the revised version (D) as an inset in the paper highlighting the differences between our model and that of Merel et al. Much of the inspiration for the design of this model derives from the papers reviewed in the June 22 entry in this discussion log.
Hippocampal Representations
Jessica Robin and Morris Moscovitch [214] argue that the hippocampus is responsible for transforming detail-rich representations into gist-like and schematic representations based on functional differentiation observed in the circuits along the longitudinal-axis of the hippocampus, and its functional connectivity to related posterior and anterior neocortical structures, especially the ventromedial prefrontal cortex (vmPFC) – see Ghosh and Gilboa [111] for detail regarding the use of the term "schema" in cognitive neuroscience and the June 22 entry in the class discussions for more detail regarding "gist-like" representations.
Vanessa Ghosh and Asaf Gilboa [111] argue that the necessary features of schema are (1) an associative network structure, (2) basis on multiple episodes, (3) lack of unit detail, and (4) adaptability, and optional features include (5) chronological relationships, (6) hierarchical organization, (7) cross-connectivity, and (8) embedded response options. In Table 2 (Page 111) they attempt to identify the neural correlates of different schema-related functions. Unfortunately, the material is highly speculative and provides little insight one might used to design artificial neural correlates.
CA1 and CA3 are at the poles of this longitudinal-axis, with the latter often characterized as an associative network and Hopfield networks suggested as a potential artificial network architectures. The traditional functional account [153] suggests the dentate gyrus as performing pattern separation followed by CA3 performing pattern completion – operations that could ostensibly be be of use in creating and adapting schematic representations of the sort envisioned above. This narrow perspective completely ignores the roles of CA2 and CA4 which are of increasing interest due to improved recording technology [93, 62].
Architectural Considerations
The challenge here is to explain how the apprentice might exploit its episodic memory to efficiently "program" the prefrontal cortex and the basal ganglia to learn new tasks from a single demonstration, generalizing on the single exposure while not inflicting collateral damage – catastrophic interference – on previously learned tasks.
The prefrontal cortex and the basal ganglia have access to the same structured sensory, somatosensory, and motor state information gathered from throughout the cortex and made available in the thalamus. The prefrontal cortex and the basal ganglia share responsibility in selecting and orchestrating behavior – both cognitive and physical activity – by shaping the context for performing such activity.
In addition, the prefrontal cortex retains selected information in working memory thereby providing an advantage in performing its executive functions. In principle, both the prefrontal cortex and the hippocampus could potentially control the behavior of the basal ganglia by altering the patterns of activity available in the thalamus and that the basal ganglia rely upon for action selection.
If we assume that the current summary of activity throughout the neocortex is sufficient to reconstruct the cognitive and physical action taken in response to that summary, then all we have to store is a representation that provides a suitably compressed account of that activity, and we know that the input to the hippocampus provides the information necessary to construct such a representation.
It seems reasonable to suggest that the representations stored in the activity patterns of CA1 neurons are sufficient to recover aspects of those patterns sufficient to recreate the originally elicited cognitive and physical behavior even if the current state at the time of their recreation differs in nonessential ways from the original state at the time of their encoding in the hippocampus.
This also assumes that the hippocampus is able to infer the essential features of the state that enable the application of a specified activity as well as nonessential features that when present are also relevant to the elicitation and execution of the specified activity. There is certainly a good deal of well-situated hippocampal circuitry, e.g., in CA2 and CA4 that could be utilized to identify such features.
The above observations suggest that the ability to identify the essential and optional features prerequisite for exploiting a given state supports the encoding of gist-like representations that might be implemented as relational models [246, 216, 27], and that these representations, together with the auto-associative properties of CA3 neurons [153], are capable of encoding schema-based representations suitable to meet the challenge mentioned earlier.
The earlier model from Dean et al [77] – labeled F in the poster – captures some, but not all, of the intuitions discussed above. It would be more plausible to model the LTM DNC as a single network composed of dynamically separated cell assemblies [193] rather than as a collection key / value pairs – keys = contexts and values = programs – as in Reed and DeFreitas [212]. We pursue the idea somewhat further in the July 15 entry in this log.
Miscellaneous Loose Ends: Kesner and Rolls [153, 215] provide a summary of current computational models of hippocampal function – including detail concerning CA1 and CA3, along with a review of the evidence supporting their adoption. The three inset text boxes in [77] – written by Chaofei Fan and Meg Sano – are relevant to the discussion in this log entry: Box A: Pattern Separation, Completion, Integration, Box B: Replaying Experience, Consolidating Memory, and Box C: Hierarchy, Abstraction and Executive Control.
June 22, 2021
%%% Tue Jun 22 14:04:51 PDT 2021
This entry follows up on the abbreviated discussion concerning the function of the hippocampal formation in the previous entry. Additional research revealed a gap in my understanding of hippocampal function. In particular, I overlooked research on human hippocampal function based on evidence gleaned from behavioral, lesion and fMRI studies of human subjects as well as non-human animal studies specifically relating to observed functional variation expressed along the longitudinal axis of the adult human hippocampus. I've compiled a collection of relevant papers available here2 , and a sample of representitive excerpts are included below:
Robin and Moscovitch [214] – argue that memory transformation from detail-rich representations to gist-like and schematic representation is accompanied by corresponding changes in their neural representations. These changes can be captured by a model based on functional differentiation along the long-axis of the hippocampus, and its functional connectivity to related posterior and anterior neocortical structures, especially the ventromedial prefrontal cortex (vmPFC). In particular, we propose that perceptually detailed, highly specific representations are mediated by the posterior hippocampus and neocortex, gist-like representations by the anterior hippocampus, and schematic representations by vmPFC. These representations can co-exist and the degree to which each is utilized is determined by its availability and by task demands.
Sekeres et al [223] – The posterior hippocampus, connected to perceptual and spatial representational systems in posterior neocortex, supports fine, perceptually rich, local details of memories; the anterior hippocampus, connected to conceptual systems in anterior neocortex, supports coarse, global representations that constitute the gist of a memory. Notable among the anterior neocortical structures is the medial prefrontal cortex (mPFC) which supports representation of schemas that code for common aspects of memories across different episodes. Linking the aHPC with mPFC is the entorhinal cortex (EC) which conveys information needed for the interaction/translation between gist and schemas. Thus, the long axis of the hippocampus, mPFC and EC provide the representational gradient, from fine to coarse and from perceptual to conceptual, that can implement processes implicated in memory transformation.
Schacter et al [220] – Recent work has revealed striking similarities between remembering the past and imagining or simulating the future, including the finding that a common brain network underlies both memory and imagination. Here, we discuss a number of key points that have emerged during recent years, focusing in particular on the importance of distinguishing between temporal and nontemporal factors in analyses of memory and imagination, the nature of differences between remembering the past and imagining the future, the identification of component processes that comprise the default network supporting memory-based simulations, and the finding that this network can couple flexibly with other networks to support complex goal-directed simulations.
Grady [114] – These three approaches provided converging evidence that not only are cognitive processes differently distributed along the hippocampal axis, but there also are distinct areas coactivated and functionally connected with the anterior and posterior segments. This anterior/posterior distinction involving multiple cognitive domains is consistent with the animal literature and provides strong support from fMRI for the idea of functional dissociations across the long axis of the hippocampus.
Vogel et al [236] – We find frontal and anterior temporal regions involved in social and motivational behaviors, and more functionally connected to the anterior hippocampus, to be clearly differentiated from posterior parieto-occipital regions involved in visuospatial cognition and more functionally connected to the posterior hippocampus. These findings place the human hippocampus at the interface of two major brain systems defined by a single molecular gradient.
Hassabis and Maguire [125] – Demis Hassabis and Eleanore Maguire suggest two possilble roles for hippocampal memory: First, the hippocampus may be the initial location for the memory index [173] which reinstantiates the active set of contextual details and later might be consolidated out of the hippocampus. Second, the hippocampus may have another role as an online integrator supporting the binding of these reactivated components into a coherent whole to facilitate the rich recollection of a past episodic memory, regardless of its age. From latter, they hypothesize that such a function would be of great use also for predicting the future, imagination and navigation.
Cer and O'Reilly [60] – [p]ostulate that different regions of neural the brain are specialized to provide solutions to particular computational problems. The posterior cortex employs coarse-coded distributed representations of low-order conjunctions to resolve binding ambiguities, while also supporting systematic generalization to novel stimuli and situations. [T]his cognitive architecture represents a more plausible framework for understanding binding than temporal synchrony approaches.
Eichenbaum [95] – The prefrontal cortex (PFC) and hippocampus support complementary functions in episodic memory. Considerable evidence indicates that the PFC and hippocampus become coupled via oscillatory synchrony that reflects bidirectional flow of information. Furthermore, newer studies have revealed specific mechanisms whereby neural representations in the PFC and hippocampus are mediated through direct connections or through intermediary regions. – a claim that if true need not undermine the explanatory value of Cer and O'Reilly's computational model.
Miscellaneous Loose Ends: I added several papers to the related work mentioned earlier. The newly added papers were authored by – different subsets of – Demis Hassabis, Dharshan Kumaran, Eleanor Maguire, and Daniel Schacter for their constructive model [124, 125, 220] of hippocampal episodic memory that inspired the papers from DeepMind on imagination-based planning and optimization [122, 194]. There is a lot of overlap between these papers and the work of Morris Moscovitch.
In terms of implementing a flexible memory system to support one- and zero-shot learning of the sort we envision for the programmer's apprentice I suggest you start by reading the 2017 paper by Jessica Robin and Moscovitch [214]. It is worth reviewing the Nature paper by Graves et al [115] on the functions supported by Differentiable Neural Computers to contrast with our requirements in the programmer's apprentice – a synopsis is provided here3.
Given an observed state-action summary, ⟨st, at, rt, st1⟩, the apprentice has to both generalize the context for acting by adjusting the observed (posterior/perceptual) state st as sketched in an earlier entry in this log and modify the program to be executed in that context by altering the control (anterior/prefrontal) circuits at as discussed in the previous entry. Interaction and translation between gist and schema representations along the gradient described in Sekeres et al [223] may provide implementation insight.
June 17, 2021
%%% Thu Jun 17 10:43:50 PDT 2021
I spent the last two weeks looking into the literature in an attempt to better understand the design choices made in the implementation described in Huang et al [142]. It appears to provide a practical foundation for building agents like the programmer's apprentice, and, where it falls short, it can be adapted without deviating too far from the basic skeleton outlined in Huang et al.
As a check on my thinking, I asked Randy O'Reilly for feedback concerning the following design principles that I believe roughly account for our current understanding of the relevant biology as laid out in O'Reilly et al [191] and in our discussions with Randy over the last two years concerning his Prefrontal cortex Basal ganglia Working Memory (PBWM) model of executive control.
If you're not familiar with PBWM, check out the transcript of the discussion we had with Randy in 2020 during which we talked about adapting the model for the programmer's apprentice, and the followup with Randy and Michael Frank in which we discussed the sharing of responsibility for action selection and executive control between basal ganglia and prefrontal cortex.
Human brains are functionally organized along the anterior-posterior axis with the back of the brain largely responsible for sensory processing and the front responsible for action selection and execution including actions that perform abstract reasoning tasks.
There appear to be rostrocaudal distinctions in frontal cortex activity that reflect a hierarchical organization, whereby anterior frontal regions influence processing by posterior frontal regions during the realization of abstract action goals as motor acts.
The basal ganglia take as input a compressed summary of activity collected from throughout both the motor and sensory cortex and produce an annotated version that serves as a context for action selection – both concrete and abstract – in the frontal cortex.
This basal-ganglia-generated context is modified by feedback from the executive regions of the frontal cortex in which the rostrocaudal axis of the PFC supports a control hierarchy so posterior-to-anterior regions of PFC exert progressively more abstract, higher-order control.
The hippocampal formation and the circuits in the prefrontal cortex work together in order to exploit prior experience in current circumstances as well as assimilate new memories into pre-existing networks of knowledge in anticipation of their use in future circumstances.
Relevant design choices that follow from the above include the assumption that the frontal cortex is responsible for performing both concrete motor and abstract cognitive processing and control. Performing sequences of actions is facilitated by PFC access to both the input and output of such actions whether through the perception of the consequences of acting in the external environment or by way of the extensive reciprocal white matter tracts connecting circuits in the frontal cortex with circuits scattered throughout the rest of the cortex.
The idea that the posterior cortex is representational / perception-oriented and the anterior cortex is computational / action-oriented is obviously misleading given that the hallmark of biological computing is that representation and computation are collocated. Perhaps it might be more useful to say that the posterior cortex is primarily responsible for precipitating computations that are dictated by circumstances/signals that are external to the posterior cortex whereas the anterior cortex is primarily responsible for precipitating computations that are self-initiated including computations precipitated by previous self-initiated computations, i.e., recursively.
June 16, 2021
%%% Wed Jun 16 05:29:34 PDT 2021
This entry extends the discussion on the scope of cognitive functions in the human neocortex begun in the previous entry. Brodmann area 10 (BA10), also referred to as the frontopolar prefrontal cortex or rostrolateral prefrontal cortex, is often described as "one of the least well understood regions of the human brain". Katerina Semendeferi et al [225] argue, from examination of the skulls of early homonids, that during human evolution, the functions in this area resulted in its expansion relative to the rest of the brain. They suggest that "the neural substrates supporting cognitive functions associated with this part of the cortex enlarged and became specialized during hominid evolution."
Koechlin and Hyafil [157] claim that frontopolar prefrontal cortex (FPC) function "enables contingent interposition of two concurrent behavioral plans or mental tasks according to respective reward expectations, overcoming the serial constraint that bears upon the control of task execution in the prefrontal cortex. This function is explained by interactions between FPC and neighboring prefrontal regions. However, its capacity appears highly limited, suggesting that the FPC is efficient for protecting the execution of long-term mental plans from immediate environmental demands and for generating new, possibly more rewarding, behavioral or cognitive sequences, rather than for complex decision-making and reasoning."
Dehaene et al [87] offer a model of a global workspace engaged in effortful cognitive tasks for which perceptual, motor and related specialized processors do not suffice. "In the course of task performance, workspace neurons become spontaneously coactivated, forming discrete though variable spatio-temporal patterns subject to modulation by reward signals. A computer simulation of the Stroop task shows workspace activation to increase during acquisition of a novel task, effortful execution, and after errors. We outline predictions for spatio-temporal activation patterns during brain imaging, particularly about the contribution of dorsolateral prefrontal cortex and anterior cingulate to the workspace."
June 14, 2021
%%% Mon Jun 14 14:19:27 PDT 2021
I've been studying papers on the structure and supported cognitive functions of the human neocortex, primarily authored by Etienne Koechlin, David Badre and their colleagues, relating to cognitive control and in particular hierarchical planning, internal goals, task management, and action selection in the dorsolateral prefrontal cortex. Rather than my summarizing them here, I suggest that you read Badre's 2018 Trends in Cognitive Sciences paper [21] that provides the best recent review and attempt at reconciling the differences between the competing theories that were featured in Figure 2 in the 2008 paper [20] in the same journal4.
Two widely-cited journal articles and a 2012 special issue of the Journal of Experimental Psychology dedicated to research on identifying the neural substrates of analogical reasoning describe an emerging consensus that the rostrolateral prefrontal cortex, known for its increased connectivity with higher-order association areas in humans, plays an important role in supporting analogical reasoning as well as other executive functions including cognitive flexibility, planning, and abstract reasoning. This and support from Koechlin et al [158] and others for the cascade model argues for the sort of neural network architecture that Yash and I discussed on Sunday5.
June 12, 2021
%%% Sat Jun 12 05:32:08 PDT 2021
I spent much of the last week attempting to justify the hypothesis that the prefrontal cortex (PFC) and hippocampus (HPC) work together to construct and execute high-level programs involving the serial activation of cell assemblies in the neocortex, in much the same way as the basal ganglia (BG) and the cerebellum (CB) work together to construct and execute low-level motor programs involving the serial activation of motor control circuits in the motor cortex. In the following, I justify the reasons for my abandoning this hypothesis and provide an alternative.
Despite their sharing cell types not found elsewhere in the brain and some superficial local cytoarchitectural characteristics, the CB and HPC differ substantially in terms of both their functional network architecture and number of neurons, with the CB at ≈ 70B CB having approximately 1000 × more neurons than the HPC at ≈ 40M neurons. Moreover, there is a good deal of evidence that the HPC, with its substantially increased white matter tracts, reciprocally connecting the PFC and HPC in humans, plays a key role in supporting cognitive behaviors in a manner analogous the way in which it supports motor control actions.
The focus on cell assemblies in the original proposal was predicated on three assumptions, (a) it is necessary to activate arbitrary ensembles of neurons to perform computations, (b) it is necessary to route arbitrary patterns of activity to serve as input to those computations, and (c) changes in the strength of connections between neurons must be restricted to the neurons in the activated ensembles in order to avoid the negative impact of catastrophic interference. Of the three, only (c) remains a concern and the potentially negative consequences of such interference apply to any proposal for lifelong-learning and can probably be mitigated by some variant of Hebbian learning or finessed using memory-augmented neural networks.
The presumed necessity to deal with arbitrary ensembles was partly based on believing that the information provided by the thalamocortical radiations and the manner in which it is represented in the striatum and subsequently projected onto working memory in the frontal cortex are limited in such a way as to preclude more complicated cognitive and abstract reasoning. I no longer believe this to be the case, and am now predisposed to assume that most motor-related functions that involve the PFC, HPC, BG and CB are likely to have cognitive counterparts that depend on the same neural components and related pathways.
In particular, I had to stumble over the early work by Redgrave, Prescott, and Gurney [211] on the generality of action selection in the basal ganglia extending to cognitive activities before finally circling back to O'Reilly's Chapter 7 on the basal ganglia, action selection and reinforcement learning in Computational Cognitive Neuroscience in which Randy and his co-authors explore these issues in detail [191]. The paper by Huang et al [142] (PDF) describes a Leabra model that implements an instructive simplfied instantiation of their theory6.
Supporting Research Papers
Redgrave et al [211] – A selection problem arises whenever two or more competing systems seek simultaneous access to a restricted resource. Consideration of several selection architectures suggests there are significant advantages for systems which incorporate a central switching mechanism. We propose that the vertebrate basal ganglia have evolved as a centralized selection device, specialized to resolve conflicts over access to limited motor and cognitive resources. Analysis of basal ganglia functional architecture and its position within a wider anatomical framework suggests it can satisfy many of the requirements expected of an efficient selection mechanism.
Buzsàki [47] – Review of the normally occurring neuronal patterns of the hippocampus suggests that the two principal cell types of the hippocampus, the pyramidal neurons and granule cells, are maximally active during different behaviors. Granule cells reach their highest discharge rates during theta-concurrent exploratory activities, while population synchrony of pyramidal cells is maximum during immobility, consummatory behaviors, and slow wave sleep associated with field sharp waves. [...] Sharp waves reflect the summed post-synaptic depolarization of large numbers of pyramidal cells in the CA1 and subiculum as a consequence of synchronous discharge of bursting CA3 pyramidal neurons. The trigger for the population burst in the CA3 region is the temporary release from subcortical tonic inhibition.
Buzsàki [48] – Theta oscillations represent the "on-line" state of the hippocampus. The extracellular currents underlying theta waves are generated mainly by the entorhinal input, CA3 (Schaffer) collaterals, and voltage-dependent CA2 currents in pyramidal cell dendrites. The rhythm is believed to be critical for temporal coding/ decoding of active neuronal ensembles and the modification of synaptic weights. [...] Key issues therefore are to understand how theta oscillation can group and segregate neuronal assemblies and to assign various computational tasks to them. An equally important task is to reveal the relationship between synaptic activity (as reflected globally by field theta) and the output of the active single cells (as reflected by action potentials).
One of the most interesting aspects of sharp waves is that they appear to be associated with memory. Wilson and McNaughton 1994, and numerous later studies, reported that when hippocampal place cells have overlapping spatial firing fields (and therefore often fire in near-simultaneity), they tend to show correlated activity during sleep following the behavioral session. This enhancement of correlation, commonly known as reactivation, has been found to occur mainly during sharp waves. It has been proposed that sharp waves are, in fact, reactivations of neural activity patterns that were memorized during behavior, driven by the strengthening of synaptic connections within the hippocampus.
This idea forms a key component of the "two-stage memory" theory, advocated by Buzsáki and others, which proposes that memories are stored within the hippocampus during behavior and then later transferred to the neocortex during sleep. Sharp waves in Hebbian theory are seen as persistently repeated stimulations by presynaptic cells, of postsynaptic cells that are suggested to drive synaptic changes in the cortical targets of hippocampal output pathways. (SOURCE)
Proskovec et al [202] – Employed magnetoencephalography (MEG) to study the oscillatory dynamics of alpha, beta, gamma, theta oscillations – with a focus on beta signaling – in governing the dynamics in the prefrontal and superior temporal cortices predict spatial working memory (SWM) performance. [...] Given the established functional specializations of distinct prefrontal regions and the prior reports of increased frontal theta during WM performance, we predicted increased theta activity in prefrontal regions that would be differentially recruited during SWM encoding and maintenance processes. [...] In contrast, we hypothesized persistent decreases in alpha and beta activity in posterior parietal and occipital regions throughout SWM encoding and maintenance, as decreased alpha and/or beta activity has been linked to active engagement in ongoing cognitive processing, and given the involvement of posterior parietal and occipital regions in spatial attention and mapping the spatial environment.
Choi et al [64] – The canonical striatal map, based predominantly on frontal corticostriatal projections, divides the striatum into ventromedial-limbic, central-association, and dorsolateral-motor territories. While this has been a useful heuristic, recent studies indicate that the striatum has a more complex topography when considering converging frontal and nonfrontal inputs from distributed cortical networks. The ventral striatum (VS) in particular is often ascribed a "limbic" role, but it receives diverse information, including motivation and emotion from deep brain structures, cognition from frontal cortex, and polysensory and mnemonic signals from temporal cortex.
Haber [120], McFarland and Haber [176] – Corticostriatal connections play a central role in developing appropriate goal-directed behaviors, including the motivation and cognition to develop appropriate actions to obtain a specific outcome. The cortex projects to the striatum topographically. Thus, different regions of the striatum have been associated with these different functions: the ventral striatum with reward; the caudate nucleus with cognition; and the putamen with motor control. However, corticostriatal connections are more complex, and interactions between functional territories are extensive. These interactions occur in specific regions in which convergence of terminal fields from different functional cortical regions are found.
Simić et al [226], West and Gundersen [247] – The total numbers of neurons in five subdivisions of human hippocampi were estimated using unbiased stereological principles and systematic sampling techniques. For each subdivision, the total number of neurons was calculated as the product of the estimate of the volume of the neuron-containing layers and the estimate of the numerical density of neurons in the layers. The volumes of the layers containing neurons in five major subdivisions of the hippocampus (granule cell layer, hilus, CA3-2, CA1, and subiculum) were estimated with point-counting techniques after delineation of the layers on each section. The estimated numbers of neurons in the different subdivisions were as follows: granule cells 15.0 x 106 = 15,000,000, hilus 2.00 x 106 = 2,000,000, CA3-2 2.70 x 106 = 2,700,000, CAI 16.0 x 106 = 16,000,000, subiculum 4.50 x 106 = 4,500,000.
Herculano-Houzel [131], Azevedo et al [13] – The following table shows Expected values for a generic rodent and primate brains of 1.5 kg, and values observed for the human brain. Notice that although the expected mass of the cerebral cortex and cerebellum are similar for these hypothetical brains, the numbers of neurons that they contain are remarkably different. The human brain thus exhibits seven times more neurons than expected for a rodent brain of its size, but 92% of what would be expected of a hypothetical primate brain of the same size7: Using an estimate of the number of the neurons in the human hippocampus calculated from the sectional estimates provided in Simić et al, notice the differences between the hippocampus and two cortical regions: hippocampus ≈ 40,000,000, neocortex ≈ 16,000,000,000, cerebellum ≈ 69,000,000,000:
|
June 9, 2021
%%% Wed Jun 9 05:28:24 PDT 2021
Complementary Learning Systems
Complementary Learning Systems theory posits two separate but complementary learning system. One depends primarily on cortical circuits that are highly recurrent, self isolating and perpetuating, governed by attractor dynamics. Here we suggest that these circuits facilitate the formation of cell assemblies that can be excited to perform recursive computations with inputs and outputs relying the dense network of thalamocortical radiations in the primate neocortex. The other learning system involves the hippocampus and adjacent areas in the entorhinal cortex with reciprocal access to neocortical circuits through the thalamus in its function as a – one of many – relay. We aim to model hippocampal formation as key/value memory systems whose keys correspond to compressed perceptual sensorimotor patterns in thalamus and values correspond to the activation patterns of Hebbian cell assemblies.
Self Organizing Cell Assemblies
Tetzlaff et al [231] provide a computational model and robotics application describing how the brain self-organizes large groups of neurons into coherent dynamic activity patterns. Buzsaki [50] reviews three interconnected topics that he claims could facilitate progress in defining cell assemblies, identifying their neuronal organization, and revealing causal relationships between assembly organization and behavior. Christos Papadimitriou, Michael Collins, and Wolfgang Maass [193] describe an interesting model they call the assembly calculus, occupying a level of detail intermediate between the level of spiking neurons and synapses and that of the whole brain capable of carrying out arbitrary computations. They hypothesize that something like their model may underlie higher human cognitive functions such as reasoning, planning, and language8. For excerpts from O'Reilly et al [190] concerning the relevant neural architecture see9.
Analogies Grounded in Experience
Analogies are mappings of properties and relationships between – dynamical/relational – models that (a) preserve specific features essential for a particular use case and (b) retain an overall consistency sufficient to support any requisite use-specific analysis. Grounding serves as the foundation for constructing analogies – it is the mother of all models. We assume that the model generated in the process of grounding is (a) constructed in stages during early development, (b) driven by extensive self-supervised exploration [195]10, and (c) verified by the action perception cycle as a form of error-correcting predictive contrastive coding [251] – see related work on the equivalence of contrastive Hebbian learning in multilayer networks [253]11.
Perception as Proactive Attention
We view attention as a – proactive – combination of pattern completion and separation for identifying and merging correlated features in representations encoding dynamical/relational models. This is facilitated in the hippocampal formation by the dentate gyrus (ostensibly) performing pattern separation, and area CA3 (ostensibly) performing pattern completion early in development and a combination of completion and integration later in adulthood. The combined post-developmental separation and integration occurring in the adult is believed to be aided by neurogenesis.
Hippocampus in Cognitive Control
In his 2006 book [49] entitled Rhythms of the Brain, György Buzsáki has a chapter by the name "Oscillations in the 'Other Cortex': Navigation in Real and Memory Space" dedicated to the hippocampus that emphasizes the different roles played by gamma, theta, and sharp-wave ripple (SWR) oscillations. Research over the following decade led to the hypothesis that organized neuronal assemblies can serve as a mechanism to transfer compressed spike sequences from the hippocampus to the neocortex for long-term storage. In its simplest version, this model posits that during learning the neocortex provides the hippocampus with novel information leading to transient synaptic reorganization of its circuits, followed by the transfer of the modified hippocampal content to the neocortical circuits [51].
More recently there appears to be an emerging consensus that the hippocampus is involved in much more than simply storing and retrieving episodic memory [161]. Loren Frank gave an invited talk in CS379C on the hypothesis that the hippocampus and SWR mediate the retrieval of stored representations that can be utilized immediately by downstream circuits in decision-making, planning, recollection and/or imagination while simultaneously initiating memory consolidation processes [56].12.
Hippocampus-Cerebellum Connection
The hypothesized role of the hippocampus in enabling cognitive function by controlling activity in cell assemblies suggests comparison with our growing appreciation for the support of cognitive function in the cerebellum [208, 144, 94]. David Marr's careful studies of the cerebellum [174] and what he referred as the archicortex [250, 173], now more commonly known as the hippocampus and hippocampal formation, underscore similarities between these two brain structures with respect to their cytoarchitecture and specialized cell types including granule cells, purkinje cells and mossy fibers.
Constructing Cell Assembly Programs
As an exercise, consider the hypothesis that the prefrontal cortex and hippocampus work together to construct and execute high-level programs involving the serial activation of cell assemblies in the necortex, in much the same way as the basal ganglia and the cerebellum work together to construct and execute low-level motor programs involving the serial activation of motor control circuits in the motor cortex. NOTE: On further reflection and reading related research papers, this hypothesis was retracted – see here for a summary of the reasons why.
Here are just a few references that provide some support for the above hypothesis. There are a lot more pieces pieces scattered about in class notes and email exchanges that I will try to dig up once I take care of a number of delayed tasks that had to be set aside during the quarter I was teaching:
Gage and Baars [108] – This suggests that a brain-based global-workspace capacity cannot be localized in a single anatomical hub. Rather, it should be sought in a functional hub – a dynamic capacity for binding and propagation of neural signals over multiple task-related networks, a kind of neuronal cloud computing.
Deco et al [82] – The dense lateral intra- and inter-areal connections [...] make possible the emergence of a reverberatory dynamic when the level of excitation exceeds the level of inhibition, which can be propagated globally across the brain [...] provide direct evidence on the hierarchical structuring of information processing in the network.
Dehaene et al [86, 87] – In conclusion, human neuroimaging methods and electrophysiological recordings during conscious access, under a broad variety of paradigms, consistently reveal a late amplification of relevant sensory activity, long-distance cortico-cortical synchronization at beta and gamma frequencies, and ignition of a large-scale prefronto-parietal network.
Frank et al [152, 258] – Hippocampal-cortical networks maintain links between stored representations for specific and general features of experience, which could support abstraction and task guidance in mammals [...] that have radically different anatomical, physiological, representational, and behavioral correlates, implying different functional roles in cognition.
June 5, 2021
%%% Sat Jun 5 15:49:42 PDT 2021
A transformational analogy does not look at how the problem was solved – it only looks at the final solution. The history of the problem solution – the steps involved – are often relevant. Carbonell [54, 55] showed that derivational analogy is a necessary component in the transfer of skills in complex domains, "In translating Pascal code to LISP – line by line translation is no use. You will have to reuse the major structural and control decisions. One way to do this is to replay a previous derivation of the PASCAL program and modify it when necessary. If the initial steps and assumptions are still valid copy them across. Otherwise alternatives need to be found – best first search fashion."
Bhansali and Harandi [123, 38] apply derivational analogy to synthesizing UNIX shell scripts from a high-level problem specification. The work of Carbonell, Bhansali, and Harandi is classic GOFAI with an "expert-systems" based approach, but it is interesting to walk through the algorithm they present in [123] – see the page numbered 393 in this PDF. Their use of a derivation trace13 reminded me of using a latent code to specify the high-level components of a program as a plan in Hong et al [141]. The application to UNIX scripts is also an interesting target domain. I'm not endorsing this approach as a solution, rather, I see it as a different perspective and possible idea generator.
May 31, 2021
%%% Mon May 31 04:7:09 PDT 2021
Explain for Manan, William, and Peter how subroutines might be implemented as a general framework for integrating complementary memory systems:
In the following, we assume that the assistant observes many instances of the programmer executing IDE repair workflows consisting of individual IDE invocations, e.g., jump 10, strung together like beads on a string. Each instance corresponds to an execution trace of a more general workflow applicable to a particular class of repairs. In principle, the assistant could concatenate all of the instances it has observed into one long string and index into this string to identify substrings relevant to the particular task at hand. Alternatively, it could compile the instances into a collection of subroutines indexed by the general type of repair they handle. The following presents a model of episodic memory that supports subroutine compilation.
As shown in the diagram, a short-term key/value memory (STM) is used to store initial-state + action + reward + final-state tuples, [st, at, rt, st+1], during a session of the assistant working with the programmer. The keys correspond to perceptual state summaries produced by the perception stack labeled A. As discussed and employed in Abramson et al [2] these could correspond to a concatenation of K sensory snapshots where K is an estimate of the K-Markov property applying to the partially observable environment. Following the working session, during the analog equivalent of the apprentice in NREM sleep, the STM tuples are (selectively) committed to long-term key/value memory (LTM storage) using some variant of experience replay.
Subroutines – as illustrated in the inset on the lower-right – correspond to directed graphs in LTM storage such that edges in the graph are IDE invocations and the vertices correspond to context-based conditional branch points. The current context, denoted kt, for selecting the next action / IDE invocation is generated by the subnetwork represented by the dark green trapezoid labeled K and combines the current perceptual state summary Ct with LTM keys that predict opportunities for reward, and roughly corresponds to the way in which the striatum and basal ganglia shape the context for action selection by combining current and prior (episodic) state information – see here.
This augmented contextual summary kt is then used to retrieve a function ft from LTM storage representing an IDE invocation in the form of a set of weights for the network represented by the light green trapezoid labeled M. This method of executing previously learned functions by instantiating a network with stored weights is now relatively common in machine learning and neural programming in particular. In class, we saw representative examples in the work of Reed and de Freitas [212] and Wayne et al [244]. See also the work of Duan et al [92] on efficient one-shot learning.
By context-based conditional branching, we mean that the perceptual state summary following the last IDE invocation evaluated in executing a given subroutine is used to select the next IDE invocation in the subroutine or exit the subroutine having determined that the current state is a terminal in the directed graph in LTM storage. This description covers the basics for how the assistant might learn subroutines by watching and imitating the programmer. It does not, however, provide any clues for how you might build a neural network to execute a given subroutine, but you can find some hints in the three papers mentioned in the previous paragraph.
In terms of exploiting the benefits of having complementary memory systems, it should be possible to apply subroutines recursively, perform nested loops, call a subroutine in the midst of executing another subroutine, and more generally traverse any path in the execution tree by using the current perceptual state augmented with episodic overlays from the LTM in the role of the hippocampus. This suggests a general strategy of merging of (current) perceptual state vectors derived from sensorimotor circuits distributed thoughout the neocortex and (past) episodic perceptual state vectors selectively encoded in the LTM on the basis of their ability to predict expected cumulative reward.
Explain for Matthew, John, Sasankh, and Griffin a possible version of analogical thinking to complement search in the programmer's apprentice:
Many of papers on analogy that we've read either acknowledge or should have acknowledged Deidre Gentner's structure mapping theory of analogy [109]. Hill et al [135] combine ideas from Gentner's work and Melanie Mitchell's perception theory [181]. There are also a number of symbolic implementations of Genter's theory [70, 97]. Crouse et al [69] inspired by Gentner's work, starts with models expressed as graphs and then uses graph networks to encode them in embedding spaces and provide a link to their code here. In the following, we focus almost exclusively on embedding methods, but it should be obvious that we are talking about analogy.
Here's a general strategy for pursuing analogy in the context of the programmer's apprentice. You begin by creating an embedding space that encodes a rich class of relational objects. These could be graph networks [27, 147] or something more sophisticated like the models of dynamical systems that Peter Battaglia and Jessica Hamrick developed [28, 26]. Given a new instance of your target class of relational objects, consider its nearest neighbors in embedding space. Sounds simple, but what are the properties and relationships that define programs.
Early work in neural programming attempted to directly apply NLP methods to encode programs. This captures the static structure of a programming language revealing how one might write syntactically correct programs, but not their functional semantics. To capture semantics of programs, researchers have tried input-output pairs to provide feedback to students in introductory programming classes [198], and execution traces to classify the types of errors student tend to make [241]. Execution traces have also been used to train neural networks to interpret programs [212].
Hong et al [141] adopt a different strategy in an attempt to reduce the amount of search required to write a program. They observe that programmers often start by specifying the high-level components of a program as a plan. The authors provide a method for learning an abstract language of latent tokens that they can use to represent such plans and infer them from the program specification. Synthesizing a program consists of first learning the latent representation of the plan and then using the resulting sequence of latent tokens to guide the search for a program realizing the plan in the target language.
The Hong et al method is one of the most promising I've encountered in my readings. A program written in a high-level programming language is essentially plan for an optimizing compiler to convert into efficient code. Their method is not a solution to the problem of search, rather, it suggests a division of labor in which the (latent) programmer searches in the algorithmic space of latent programs for a plan that meets the problem specification and then hands it off to the assistant who carries out the tedious job of turning the plan into an executable that passes all the unit tests and satisfies all the input-output pairs.
When I first read Seidl et al [222] on using modern Hopfield networks [206] for drug discovery, I thought of molecules, their properties and the reaction templates used to alter those properties as dynamical systems with at least the complexity computer programs. They are certainly combinatorially complex and exhibit complicated difficult-to-predict dynamics, but like Chess and Go they appear to yield to a combination of pattern recognition and search which deep networks excel at. Like Chess in which learning to make legal is moves simple to learn, writing syntactically correct programs is relatively easy, but unlike chess figuring what even a short program with lots of conditional branch point computes can be daunting.
Becoming adept at writing software requires a great deal of specialized knowledge much of it focusing on how to compartmentalize and mitigate complexity. The practice of carefully documenting and writing tests that often require more lines than the actual program is not an option for the professional software engineer. The apprentice is not expected to invent new algorithms or deploy them in novel situations, but rather to take advantage of its ability to focus, avoid distraction, and offload tedious chores allowing the programmer to concentrate on problems that benefit from decades of experience. We imagine the apprentice carrying out many of the tasks that standard developers tools like linters can't handle and would normally require a couple hours of tedium or writing short script. This is the sort of coding we expect of the apprentice and analogy to help with.
Consider how grounding in the physical world might provide a bias for exploiting analogy as in the example of teaching students to arrange themselves in a line where each student but the first is behind a student who is the same height or shorter. There is a large literature on how children learn better by being exposed to physical analogies – think abacus, and how signaling with sign language combined with spoken language can improve learning depending on developmental stage [217], and how young children talk to themselves describing their behavior and the behaviors of others including fictional characters and inanimate toys. I conjecture the benefit from using pretrained transformers as universal computation engines [171] derives from the same bias as analogy derives from physical grounding.
Explain for Griffin of how future state-of-the-art AI systems will inevitably come to believe what many humans believe about being conscious:
Every mammal – for that matter any animal that we would ascribe intelligence, in addition to being able to parse the relevant features of its physical environment, must be able to represent and reason about the various parts of its body and to distinguish between those parts and the external world, otherwise, confusion about this distinction will lead to inappropriate and possibly destructive behavior. The human brain adapts the representations of its body and its sensory map. Animals that make sounds have to know that they are making sounds and in the case of birds and mammals, they have to learn how to make the right sounds whether for sounding an alarm or all-clear signal, or attracting a mate. Male birds learn their mating call by mimicking their male parent and then practicing on their own listening to themselves. Apropos our discussion here, they don't confuse their call from that of their parents, other birds and especially not other birds they compete against for reproductive advantage.
Humans have a much greater range of signals they communicate with and also learn by mimicking other humans and practicing by repeating new words that in infants generally elicits a parent correcting the infant's pronunciation by a variety of stereotyped methods. The phonological loop plays a crucial role in learning the novel phonological forms of new words, Baddeley et al [16] have proposed that the primary purpose for which the phonological loop evolved is to store unfamiliar sound patterns while more permanent memory records are being constructed. Obviously, the speaker is aware or at least behaves as though aware that he or she produced the sounds. As young children acquire language, most children take to describing their behavior to themselves or anyone else within earshot. As they mature it becomes obvious that such behavior is inappropriate in most contexts and they internalize their "dialogue" in what is generally referred to as inner-speech [5, 7, 6].
Suppose you write a neural network as part of a robotic system capable of inner-speech and competent enough to converse with a human being about a wide range of topics. Suppose further that you tell such a robot that you are conscious14 whereby you mean – and demonstrate to the robot by providing examples – that consciousness is your awareness of yourself and the world around you. Essentially, if you can describe something that you are experiencing in words, then it is part of your consciousness15. Given what you know about artificial agents equipped with modern natural language processing systems including those that aspire to fluid question answering, conversational dialogue management, commonsense reasoning, and collaboration as in the case of the Abramson et al paper, and extrapolating out a decade hence given the current trajectory, it seems inevitable that future artificial agents will, if pressed, make reports of their exerience similar to those we have come to expect from humans.
May 26, 2021
%%% Wed May 26 05:46:40 PDT 2021
It is said that you can lead a horse to water, but you can't make him drink. I've learned from 40 years of teaching that good teaching is not about students learning facts, it's about teaching them how to navigate in new knowledge spaces and enabling them to learn how to learn what they need to know in order to absorb new facts in context. You would never say that in a course prospectus; students wouldn't understand it, and, in point of fact, a course that only focused on design principles would be dry indeed.
CS379C is ostensibly about systems that learn how to read, write, repair conventional computer programs. The impetus for creating the course and arranging for a very specific group of scientists and engineers to talk about their work was a little-heralded paper that came out in the midst of a global pandemic and was largely ignored and under-appreciated. For some of the same reasons that I gave you yesterday, the majority of people who read it considered it largely irrelevant to either natural language processing or robotics.
Admittedly, the paper was a baby step forward in terms of the actual problem that it solved. However, the way in which it solved the problem provides a foundation of ideas and technologies for achieving human-level AI that is both replicable and scalable for those few who have the insight to recognize its potential value.
In addition to the first five weeks of the class listening to and interacting with some of the researchers that contributed to the underlying concepts and technologies, students were provided with a relatively small number of papers, some of them annotated carefully to focus on the important design principles as seen through the lens of implemented systems. In addition to the paper by Abramson et al, students were repeatedly advised to read the MERLIN paper and the paper by Merel et al – all three of them carefully annotated to underscore the important content.
Eve Clark's talk and participation in class provided key insights into how we acquire language and ground our understanding in the experience of the world we share with other humans, and the recent "Latent Programmer" paper by Joey Hong et al and work by Felix Hill on the relationship between analogy and contrastive predictive coding were added to the mix and placed in context in Rishabh's and Felix's invited talks and class discussions.
In encouraging students to apply what they learned to a particular problem – the programmer's apprentice, the hope was that individual teams would be able to focus on key elements of the problem and not only gain a greater understanding of how those elements depend upon one another, but also experience what it's like to work on such a complicated problem with a larger team of researchers from a diverse set of scientific and engineering disciplines. To encourage them to appreciate and take advantage of the dependencies between the suggested projects, students were told that if they contribute to this collective enterprise they would be listed as co-authors on an archive preprint that would be shared with the experts that enlisted to serve as invited speakers and consultants on student projects.
This lengthy discourse was intended to explain why in our discussions concerning project proposals and more recently in project design reviews I have tried to encourage you to think about how to focus your projects to make such a contribution to the larger aspirational goal of designing the next generation of interactive agents building on the work of the interactive agents group at DeepMind.
I hope that I have also made it quite clear that such a contribution is not required for you to get a good grade in the class, and have done what I can to suggest how what you proposed wanting to work on might connect the collective enterprise as well as providing advice on how best to pursue your interests independently. Make the most of these last few days of the quarter in working on something that really interests you.
May 25, 2021
%%% Tue May 25 04:44:15 PDT 2021
On Sunday morning, I met with Yash and Lucas and we talked about the model of Fuster's hierarchy that I shared with students attending the project discussion meeting last Thursday. When I tried to explain how to implement the reciprocal connections between the perceptual stack and the motor stack within each level of the hierarchy, I ran into problems but soldiered on to the end nonetheless. Following up, Yash provided a helpful critique specifically dealing with my description of the reciprocal connections16.
Afterward, Lucas sent around some of his thoughts concerning a related problem having to do with a model of introspection he has been working on. Among other ideas, he mentioned the relevance of work by Roger Shepard and provided a link to a relatively recent paper by Shepard that touches upon issues relating to my presentation in the morning. Lucas's mention of introspection reminded me of how I framed inner speech as a recurrent process for making sense of some given explanation or proposed solution to a problem by talking to yourself. Here is how it works:
Suppose someone proposes an interesting idea to you. As part of the normal process for your listening to the proposal, you encode the description of the proposal in the (putative) language comprehension areas in the posterior superior temporal lobe, including Wernicke's area, as you would any other utterance in a conversation. The resulting encoding is represented as an embedding vector that serves as a proxy for the corresponding pattern of activity in the language comprehension areas.
We model this biological process using some version of the standard NLP encoder-decoder architecture. For concreteness, assume we use a transformer or BERT style deep network, implementing a variation on the idea of Baddeley's phonological loop, that encodes the spoken words, performs some intermediate transformations on the encoding, and then decodes the resulting embedding vector as a sequence of words to be spoken whether out loud or to yourself as in the case of inner speech.
The intermediate transformations implemented as stages in the transformer stack are trained to search for analogies that map the input – the encoded description of the proposal in this case – to the output – an alternative description that you are more familiar with as it is cast in terms of your own vocabulary and the meanings you ascribe to the corresponding words and so is more likely to suit your purposes better than the one you just heard. The inputs and outputs are modeled as embedding vectors.
The result of these intermediate transformations is then decoded – this decoding process postulated to occur in the frontal cortex involving Brodmann's areas 47, 46, 45, and 44 which includes Broca's area located anterior to the premotor cortex in the inferior posterior portion of the frontal lobe – and then spoken out loud or to yourself in the case of inner speech, thereby completing the phonological loop.
This process could be repeated as many times as is deemed useful, with you now substituting for the person who proposed the original idea as if playing the telephone game (Chinese Whispers) with yourself – see here for more detail. The entire process provides an example of my interpretation of Lucas's introspection.
May 12, 2021
%%% Wed May 12 04:57:49 PDT 2021
Missing Mathematics
Where in my brain is the abstract knowledge I've acquired relating to mathematics, computer science, physics, and many other disciplines? I'm not referring to the elusive engram for Dijkstra's shortest path algorithm or Gödel's incompleteness theorem, I'm thinking about the circuits I exercise in writing a program or proving a theorem, and what constitutes the neural substrate for my knowledge of such abstract concepts and methods for their analysis.
It seems to me this sort of procedural and declarative knowledge is not accounted for, and could not easily be accommodated in the three-level architecture we are thinking about for the programmer's apprentice project application. Neither is it clear that fleshing out the roles of Fuster's hierarchy, the hippocampal formation, or the executive functions associated with the prefrontal cortex would reveal anything substantive to resolve the mystery17.
Hierarchical Models
I began the exercise by reviewing the three-level hierarchy corresponding to our current architecture for programmer's apprentice (PA). In anticipation of arguing for a missing fourth level, I also prepared a four-level hierarchy as visual aid accompanying this exercise including links to supplementary information anchored to the small inset images.
Elsewhere we described the PA's physical environment in terms of a collection of processes running a python interpreter and integrated development environment (IDE) that, among other services provides an interface to the Python debugger pub.py (PDB) and other developer tools. See here for more detail on the PA environment and its interface with the IDE.
Motor Primitives
The base level, L0, of our current architecture is dedicated to learning how to invoke IDE commands and attend to their inputs and outputs. This level is trained in the curriculum protocol using a variant of motor babbling in which commands and their arguments are sampled randomly and the system learns a forward inverse model of the underlying dynamics [37, 218, 89].
Simple Instructions
The next level, L1, of the architecture is responsible for learning how to execute commands, and examine the relevant output and error messages as preparation for deciding what to do next – this could be either not to do anything as in the case the problem is resolved, or provide the information necessary to guide conditional branching.
Coordinated Behavior
The penultimate level, L2, involves the assistant observing the programmer execute common code-repair workflows and recording the sequence of state-action-reward triples in an external memory network, such as a differentiable neural computer (DNC) or bank of LSTMs, modeled after the hippocampus, and, at a subsequent time analogous to the onset of non-rapid-eye-movement (NREM) sleep, the recorded sequences are replayed to produce general-purpose subroutines.
Composing Programs
At this point in training, the apprentice certainly can't be said to understand programs or programming. It does, however, have a rudimentary working knowledge of how to employ the IDE to identify a certain class of buggy programs in the same way that a baby acquires a working knowledge of how its muscles control its limbs. The objective here is to describe how the apprentice might learn to understand programming well enough to compose new programs on its own and repair a much broader class of programs and bugs. In order to do so, we consider adding another level, L3, to our three-level hierarchy.
Flexible Behavior
The architecture shown in Box 2 of Merel et al [177] is not flexible enough to support such agent-directed learning because it fails to account for what is arguably the most powerful computational asset of the human brain, namely the extensive white matter tracts that facilitate the flow of information and support its integration across functionally differentiated distributed centers of sensation, perception, action, cognition, and emotion [183].
The cortico-thalamic pathways controlled by the striatum and basal ganglia rely on highly structured representations that summarize perceptual state and constrain the way in which such information is transferred between both cortical and subcortical regions preserving in the process its inherent topographical structure. This arrangement facilitates variable binding in the prefrontal and motor cortex working memory.
In the primate brain, the prefrontal cortex is significantly larger than in other mammals allowing it to make better use of these structured representations by exploiting its working memory. As humans evolved to live in more complex social groups and develop language to support cooperation and share knowledge, the areas dedicated to strictly perceptual and motor tasks were co-opted or extended to better serve the new computational and representational demands.
Language in particular and the ability to precisely represent, modify, and convey complex concepts in order support flexible behavior provided an evolutionary advantage that extended beyond the individual to modify the context of natural selection so as to impact not just their immediate offspring but their future kin and extended cohort. These advantages instituted an arms race in which humans banded together in ever larger cohorts requiring more sophisticated planning and organization and demanding greater flexibility in behavior and thinking.
Executive Overload
The prefrontal cortex plays what is traditionally referred to as an executive – or supervisory – role in orchestrating behavior throughout the cortex. As humans developed a more diverse repertoire of behaviors requiring significant increases in precision and cognitive control, it became increasingly difficult to plan and coordinate these behaviors since in order to do so would have required novel combinations of informational and computational resources residing in neural circuits throughout the cortex.
It became necessary for the executive system to cede control for this coordination to the distributed circuits themselves, enabling the prefrontal cortex to focus on setting goals and overseeing their planning and execution, and depending on the circuits to self-organize their collective behavior in order to carry out complex algorithms, by controlling the flow of information and coordinating its processing.
Natural selection became increasingly influenced by humans ability to reshape their environment to serve culturally directed purposes, favoring alterations to the brain that facilitate the distributed control of complex behaviors requiring the coordinated activity of multiple brain areas and allowing humans to quickly learn new behaviors that routinely require solutions to novel information processing problems18.
The details concerning the means by which the brain accomplishes these feats of computational prowess are not as yet fully understood. That said, there is a good deal of research that bears upon this problem and several plausible hypotheses, a few of which enjoy some degree of consensus. One interesting line of research relates to Bernard Baars' original work on global workspace theory and Stanislas Dehaene's version of the same idea that he has dubbed the global neuronal workspace.
Cell Assemblies
Dehaene [84] provides an introduction to Hebbian cell assemblies and the attractor dynamics believed to govern their behavior. He describes how the excitation and inhibition of the neurons in a large neural network results in competition that converges on a subset of neurons – a cell assembly – that are strongly interconnected and that fire in bursts of self-sustained activity. See also Baars et al [14, 108, 175] for a discussion of the global workspace as a functional hub that has the dynamic capacity for binding and propagation of neural signals over multiple task-related networks.
Another line of research, epitomized by Valentino Braitenberg [42] building on the work of Donald Hebb [128], includes the work of György Buzsáki [52, 50], Günther Palm [192], and Friedemann Pulvermüller [205, 204, 203]. Miller and Zucker [180] is a good example of the related theoretical work focusing on computational and mathematical models. I've added an annotated copy of [205] on the class resources page here and provided a short bibliography of related papers here19.
Analogical Brains
The remainder of this entry offers an explanation of how language might have given rise to the neural architecture that makes possible the sort of flexible thinking that sets humans apart from other animals. As humans developed referents in the form of reproducible, shareable signs including gestures, distinctive marks on trees, and iconic objects, these signs became affordances for anchoring concepts and ultimately evolved into spoken words. Combinations of words that appeared together would evoke patterns of activity associated with more complicated concepts and these patterns collocated with composite attendant perceptual and action-related experiences.
The neurons participating in these patterns would be tied to the words that reliably recurred when those patterns were active and would form the basis for cell assemblies that initially derive meaning from those features, but are combined over time to construct hierarchies of increasingly abstract features. These new abstract features are anchored to new words that serve to communicate complex concepts in such a way that when a speaker uses a word or phrase associated with a given cell assembly it causes the activation of assemblies in the hearer that are similar to those in the speaker in the same sense that two phrases that convey the same meaning are collocated in an embedding space.
The strength of the relationship between the different interpretations of the speaker and the hearer is largely determined by what linguists refer to as common ground. Our individual grounding is a subset of the common ground we share with any other individual. For example, when you use the term "rocker" I might think "rocking chair" while you were thinking "cradle". This difference in our interpretations may or may not result in confusion and misunderstanding, but it could also provide useful insight.
Suppose that when you were an infant, your mother would place a rubber doorstop under your cradle so it wouldn't disturb your sleep. I might mention that my grandfather would rock so vigorously in his rocking chair that I worried he would hurt himself, and you might suggest a doorstop to limit grandfather's rocking. This constitutes a form of analogical thinking that is likely so common we don't even realize the source of our inspirations. The process of converting thoughts to sequences of words is stochastic leading to novelty in the way we express ourselves as well as opportunities to exploit and expand on small differences in interpretation.
Grounded in Logic
These hierarchies of features aligned with words, phrases, and other linguistic constructions would initially be rooted in our apprehension of and interaction with the physical world. New concepts and the words we use to describe them would be built on this foundation, but relevance to the physical world would likely attenuate as the topics we engage with become more abstract and the analogies we make with them become more tenuous.
Whereas our worldly concepts might be grounded through interaction with the physical environment via the perception-action cycle, the grounding of our more abstract constructions and the words we use to describe them would largely be determined by self-consistency requiring reflection and introspection. Language might play a key role in detecting and resolving inconsistencies by an extension of the phonological loop introduced in Baddeley's model of working memory [18, 15].
The reason most often cited for the reciprocal connections in Fuster's Hierarchy [107] is that they serve to establish the bi-directional dependence between acting and perceiving by ensuring that perception guides action and action supports perception20. The corollary discharge theory of motion perception helps to explain how the brain distinguishes between movement in the visual world and movement due to our own movement or our eyes moving21. There are similar source identification and contextualized meaning adjustment mechanisms at work when we speak or listen.
Inspired by Baddley's model and the reciprocal connections22 within the levels of Fuster's hierarchy, we developed a variant of the phonological loop based on the idea of playing Chinese whispers – called the telephone game in North American English – with yourself. A brief description of this idea and it's relationship to inner speech [6] and Douglas Hofstadter's strange loop [139] can be found in the introductory lecture notes here.
May 8, 2021
%%% Sat May 8 06:26:29 PDT 2021
In the case of the executive homunculus that Yash Savani and I are working on, grounding and the ability to interpret programs is accomplished by exposing the homunculus to running programs and having it emulate them in its neural circuitry – see here.
In the case of the programmer's apprentice, grounding and the ability to observe, analyze and influence the properties of programs is accomplished by training the apprentice to utilize the tools available in its integrated development environment.
We are assuming that the apprentice is embodied as an integrated development environment (IDE) complete with all the debugging and profiling tools that generally come with such tools. At this point in our project discussions, I think it is worth unpacking this assumption and being more explicit about what we mean by embodiment in this context. The "environment" aspect of an IDE is particularly relevant for our discussion.
As pointed out in the second lecture, the programmer and the apprentice share access to and control of a suite of processes running on a dedicated computer. This is the physical environment in which they interact and collaborate. For concreteness, we assume that there is a process running Python and that it has a set of developer tools installed. Here we restrict our attention to the tools available in the standard python debugger – pdb.py.
The embodiment of the assistant is a process running on the same dedicated computer that instantiates the assistant neural network plus ancillary subprocesses that define the interface enabling the assistant to interact directly with its environment and indirectly with the programmer. This interface could be as simple as using the standard Unix input and output library for text or as complex as supporting voice and visual communication.
We choose a middle road by implementing a virtual console whereby the assistant can issue commands to the IDE in the form of instantiated slot/filler templates and receive in return stylized summaries of the output of the IDE also represented in slot/filler notation. Essentially, all interaction with its environment is conducted by way of a finite set of slot/filler templates instantiated from a fixed vocabulary consisting of a fixed set of tokens and basic datatypes.
The command-line instructions for the Python debugger provide the basis for the above mentioned templates that define the assistant's base-level suite of actions. The assistant should be able to execute any pdb instruction by selecting the corresponding template and filling in its slots by pointing to – or simply attending to the appropriate expressions corresponding the results from earlier instructions visible in virtual console.
The above description should enable those of you working on curriculum learning to define the syntax of the template for any instruction in pdb.py, and explain how the assistant is trained execute that instruction. Debugger instructions are loosely typed, e.g., jump expects an integer corresponding to a line number in the source code23, and so you may want to train the apprentice to fill the slots in templates with appropriately typed values – this would certainly be desirable in any attempt in L2 to generalize a one-shot learned workflow.
Once you have the syntax for the individual instructions worked out, the teams working on the perception-action components can identify candidate workflows to use as examples to illustrate how your model can be used to perform one-shot learning by first imitating and then generalizing a commonly employed intervention. Working your way through this exercise should also be useful for defining or refining your neural architecture and proposed method for one-shot learning.
May 6, 2021
%%% Thu May 6 12:16:45 PDT 2021
Think about the different levels of abstraction in the perceptual-motor stack:
L_0 A: BABBLING: [PROTOCOL LOADS PROGRAM & INPUT/OUTPUT SAMPLE, POINTS AT TARGET CONTENT] AGENT ATTENDS TARGET
B: ...
C: ...
L_1 A: COMMANDS: INGEST PROGRAM; INGEST INPUT/OUTPUT SAMPLE; RUN PROGRAM ON SAMPLE; ATTEND AND REPORT RESULT;
B: ...
C: ...
L_2 A: WORKFLOW: INGEST AND RUN PROGRAM, IF PROGRAM WORKS ON ALL SAMPLES, THEN EXIT, ELSE PRINT ERROR MESSAGE
B: ...
C: ...
Compare against the technologies that Rishabh and Dan mentioned in their talks:
NEURAL PROGRAMMER INTERPRETERS [212]
In this paper, we develop a compositional architecture that learns to represent and interpret programs. We refer to this architecture as the Neural Programmer-Interpreter (NPI). The core module is an LSTM-based sequence model that takes as input a learnable program embedding, program arguments passed on by the calling program, and a feature representation of the environment. The output of the core module is a key indicating what program to call next, arguments for the following program and a flag indicating whether the program should terminate. In addition to the recurrent core, the NPI architecture includes a learnable key-value memory of program embeddings. This program-memory is essential for learning and re-using programs in a continual manner.
NEURAL PROGRAM SYNTHESIS DIFFERENTIABLE FIXER [23]
Our approach is inspired from the fact that human developers seldom get their program correct on the first attempt, and perform iterative testing-based program fixing to get to the desired program functionality. Similarly, our approach first learns a distribution over programs conditioned on an encoding of a set of input-output examples, and then iteratively performs fix operations using the differentiable fixer. The fixer takes as input the original examples and the current program’s outputs on example inputs, and generates a new distribution over the programs with the goal of reducing the discrepancies between the current program outputs and the desired example outputs.
DEEPCODER: LEARNING TO WRITE PROGRAMS [22]
We develop a first line of attack for solving programming competition-style problems from input-output examples using deep learning. The approach is to train a neural network to predict properties of the program that generated the outputs from the inputs. We use the neural network’s predictions to augment search techniques from the programming languages community, including enumerative search and an SMT-based solver. Empirically, we show that our approach leads to an order of magnitude speedup over the strong non-augmented baselines and a Recurrent Neural Network approach, and that we are able to solve problems of difficulty comparable to the simplest problems on programming competition websites.
TOWARDS MODULAR ALGORITHM INDUCTION [1]
Our architecture consists of a neural controller that interacts with a variable-length read/write tape where inputs, outputs, and intermediate values are stored. Each module is a small computational procedure that reads from and writes to a small fixed number of tape cells (a given fixed set of modules are specified in advance). At each time step, the controller selects a module to use together with the tape location of the module’s input arguments and the write location of the module output. This architecture is trained end-to-end using reinforcement learning.
NEURAL EXECUTION ENGINES: LEARNING TO EXECUTE SUBROUTINES [254]
Graph attention networks are essentially transformers where the encoder mask reflects the structure of a given graph. In our case, we will consider masking in the encoder as an explicit way for the model to condition on the part of the sequence that it needs at a given point in its computation, creating a dynamic graph. We find that this focuses the attention of the transformer and is a critical component for achieving strong generalization.
LATENT PROGRAMMER: DISCRETE LATENT CODES PROGRAM SYNTHESIS [141]
We propose to learn representations of the outputs that are specifically meant for search: rich enough to specify the desired output but compact enough to make search more efficient. Discrete latent codes are appealing for this purpose, as they naturally allow sophisticated combinatorial search strategies. The latent codes are learned using a self-supervised learning principle, in which first a discrete autoencoder is trained on the output sequences, and then the resulting latent codes are used as intermediate targets for the end-to-end sequence prediction task.
ABSTRACTIONS OF TRACES OBTAINED FROM SYMBOLIC EXECUTION [130]
Programs do not start off in a form that is immediately amenable to most off-the-shelf learning techniques. Instead, it is necessary to transform the program to a suitable representation before a learning technique can be applied. In this paper, we use abstractions of traces obtained from symbolic execution of a program as a representation for learning word embeddings. We trained a variety of word embeddings under hundreds of parameterizations, and evaluated each learned embedding on a suite of different tasks. We show that embeddings learned from (mainly) semantic abstractions provide nearly triple the accuracy of those learned from (mainly) syntactic abstractions.
API SEQUENCE EMBEDDINGS WITH NLP ENCODER-DECODER [118]
We propose DeepAPI, a deep learning based approach to generate API usage sequences for a given natural language query. Instead of a bags-of-words assumption, it learns the sequence of words in a query and the sequence of associated APIs. DeepAPI adapts a neural language model named RNN Encoder-Decoder. It encodes a word sequence (user query) into a fixed-length context vector, and generates an API sequence based on the context vector. We also augment the RNN Encoder-Decoder by considering the importance of individual APIs.
Miscellaneous Loose Ends: The following paper includes several examples of code repair and claims to have a large dataset of training examples drawn from GitHub repositories. The examples are in python and the dataset is huge – though I expect you'll have to extract it yourself. If any of you are sufficiently far along in your projects to need data, Rishabh is a co-author on the paper and may have access to the data or the scripts that were used to scrape it. Pick one or two sample buggy programs and see if you can figure out a few workflows that the apprentice could conceivably convert to scripts/subroutines using one-shot learning, and that you, sitting in for the programmer, could use to repair the bugs in the sample programs. If you're ambitious, you could demonstrate how to use pdb.py scripts to find the bug and– as a bonus – make the repair. This coding exercise would make a significant contribution to our understanding of the problem that we've chosen to focus on.
CODE REPAIR USING NEURO-SYMBOLIC TRANSFORMATION NETWORKS [90]
The goal here is to develop a strong statistical model to accurately predict both bug locations and exact fixes without access to information about the intended correct behavior of the program24. Achieving such a goal requires a robust contextual repair model, which we train on a large corpus of real-world source code that has been augmented with synthetically injected bugs. Our framework adopts a two-stage approach where first a large set of repair candidates are generated by rule-based processors, and then these candidates are scored by a statistical model using a novel neural network architecture which we refer to as Share, Specialize, and Compete. Specifically, the architecture (1) generates a shared encoding of the source code using an RNN over the abstract syntax tree, (2) scores each candidate repair using specialized network modules, and (3) then normalizes these scores together so they can compete against one another in comparable probability space.
May 4, 2021
%%% Tue May 4 04:02:32 PDT 2021
In the first lectures I described how representations in posterior cortex that the perceptual system learns are dependent on representations in anterior cortex that determine how the agent interacts with its environment. This dependency is reciprocal. The perceptual system provides the information required to enable the motor system to choose actions, and the motor system has to enable the perceptual system to make the observations necessary to obtain the information to make those choices.
The reciprocal connections between the perceptual and motor systems provide the feedback necessary to support these dependencies. They also support the perception-action cycle that makes it possible to learn the necessary representations by self-supervised learning, and construct the hierarchy of representations described by Joaquín Fuster [107, 105, 104] often referred to as "Fuster's Hierarchy# [41].
Now it's time we face the challenges that arise in designing the perceptual and motor systems necessary for assistant agent to perform the tasks that we expect it to accomplish. To start the discussion I want you to consider the task of an optimizing compiler such as Clang/LLVM. Such a compiler needs to be able to identify opportunities for performing specific optimizations. That is to say, it has to represent and recognize features in the code that suggest such opportunities. At the very least, this requires that the compiler is able to scan the source code looking for such features.
Having identified such features it then has to analyze them to determine whether or not any of its specific optimizations apply. This generally requires analyzing the context in which those features appear – a process that may involve additional search and analysis requiring their own representations and activities. Once the compiler has identified a potential location for optimization it has to carry out some number of steps, which again require some degree of perceptual and mechanical agility. Generally speaking, the compiler needs to be able to interpret code to the degree necessary for identifying and analyzing optimization opportunities and manipulate code to the extent necessary for realizing those opportunities.
In the developing infant, some cognitive capacities are critically dependent on neural circuitry that only becomes available at particular stages in the development of the infant's brain. For example, consider the human sense of "self" that depends on neural circuitry that appears around the beginning of the first year and manifests gradually in stages roughly spanning the first twelve to eighteen months [146, 58, 155]. Upon discovering their corporeal self some children become self conscious of their behavior and bodily functions. This may serve the same purpose as learning a multi-layer neural network layer by layer [113].
Initially, the assistant agent is configured with a network architecture organized so that the agent is able to learn a hierarchy of perceptual and mechanical affordances that anticipate and support whatever subsequent tasks the agent is expected to perform. At each level in the representational hierarchy, the agent is either "exercised" by controlling the IDE input and having the agent attend to and report on the observed output or is trained to control the IDE in carrying out simple tests and interventions.
The base level, L0, constitutes a variant of motor babbling. In the case of the assistant, babbling consists of randomly executed IDE commands that the assistant learns to attend to and register as being novel or expected. The second level, L1, consists of a series of graded exercises analogous to a baby learning how to crawl, stand, grasp and manipulate objects. Each exercise is associated with the use of a single IDE command requiring the assistant to instantiate the parameters in the template associated with that command, invoke the command, report on whether or not it succeeded and if so printing the result. The series of graded exercises are self-supervised within grades and advancing to the next grade or reverting to a previous grade is controlled by the curriculum learning protocol. The goal is to learn how to exercise each of the commands and attend to the results, and not to learn when to employ a given – that comes later.
Upon successful completion of all the grades in L1, the assistant graduates to level three, L2, and is ready for on-the-job training during which it learns how to carry out a set of common IDE workflows referred to here as subroutines that involve executing sequences of IDE commands. Simple linear workflows are learned first before advancing to more complicated subroutines that involve conditional branching. It is expected that the assistant learns each subroutine in a single shot by first observing the programmer perform the subroutine and subsequently replaying the observed behavior so as to generalize its application [200, 221, 12].
Miscellaneous Loose Ends: In keeping with complementary learning systems theory [160], L0 and L1 are intended to model the gradual acquisition of structured knowledge representations instantiated in the mammalian neocortex, whereas L2 is intended to loosely model the use of hippocampal memories to learn the specifics of individual experience and the role of rapid replay in goal-dependent weighting of experience to generalize from one or a few examples thereby enabling effective one-shot learning [110]. See here for the slides for today's project discussions.
April 30, 2021
%%% Fri Apr 30 14:54:25 PDT 2021
Thanks to all of you for making progress on your project descriptions over the last couple of weeks. I'd like to meet with each team in the next week to nail down your plans more firmly. I also want to discuss specific help you might get from engaging one or more of our consultants – Eve for language acquisition; Rishabh, Dan, Yash, and Nando for neural programming; Felix, Gene and Yash for analogy and contrastive learning; and Greg and Felix for their work with the Interactive Agent Group and, in particular, agent architectures including Merlin and the agents described in Abramson et al and Merel et al.
Below are my capsule summaries of each project – the amount of detail depending on how far along in the discussions we are at this point. To keep the ball rolling, I want to meet with each team in the next few days. I'd like to start out with individual teams and later meet with two or more teams together to discuss inter-project dependencies. This weekend, I can meet 9:00-10:00 AM or 10:00-11:00 AM on Saturday and Sunday, and later line up meetings for next week.
Matt, John, and Sasankh – emphasizing all aspects of processing perceptual information including input to and output from the IDE precipitated by the programmer and assistant – the assistant perceives its own activity proprioceptively25. – [Project Class #1]
Will, Peter, and Manan – emphasizing all aspects of generating activity including invoking IDE developer tools by using predefined parameterized slot-filler templates and filling in the parameters26. These templates define the set of all actions available to the assistant and largely finesse the problem of parsing natural language descriptions of actions. – [Project Class #1 & #2]
Juliette, Mia, and Div – emphasizing the curriculum learning protocol including training strategies, low-level semi-supervised imitative bootstrapping and grounding, orchestrating developmentally-staged training by controlling advancement to higher stages, and recognizing the need to revert to earlier stages for remedial training. –[Project Class #3]
Amber and Kasha and – are thinking about using natural language as the primary means for the programmer to communicate with the assistant. While it may be desirable for the apprentice to acquire some proficiency in communicating with the progrmmer in natural language, the technical hurdles are considerable27. – [Project Class #3]
It is worth mentioning that pointing and gesturing are not the basis for communication using sign language any more than moving lips and larynx are the basis for verbal communication. The programmer and apprentice communicate by sharing programs and the procedures for creating and altering them that they convey to one another by demonstrating and acknowledge by imitating. Programming languages are as expressive as so-called natural languages, modulo their vocabulary and domain of application, by which I mean you could, in principle, use a programming language to engage in conversations for any purpose that you would use a natural language.
The caveat is that, in order to understand programs or natural language utterances, you would need to be grounded in, respectively, the art and practice programming computers or the particular topic of the conversation in which the utterances were produced. It is not an exaggeration to say that we have yet to build an AI system that can be said to understand human language, and the reason is that we have yet to satisfactorily solve the problem of grounding an artificial agent in any sufficiently expressive approximation of the grounding that we as humans universally share.
It is also worth pointing out that the Abramson et al interactive agent – the GETTER – can be said to understand its environment only to the extent it has explored that environment guided by the SETTER referring to objects by their names, identifying and giving names to the relationships between objects and between objects and the actions appropriately performed on those objects by explicit demonstration and imitative mirroring. In Abramson et al, the GETTER's task of acquiring language is considerably simplified by relying on a small vocabulary and highly stylized patterns of discourse.
See this Venn (diagram) relating the programmer's and the assistant's individual groundings, and identifying the overlap between the two as their shared ground. The point is that we don't need to enable the apprentice to communicate in a natural language other than a high-level programming language, we simply have to ensure that the apprentice is immersed in and allowed to experience its environment early in development prior to and as a foundation and grounding for its subsequent interaction with the programmer.
Miscellaneous Loose Ends: Here28 is an answer to a question regarding the scope of problems that we aspire to versus the scope of those that it even makes and sense to conjecture a possible solution:
April 29, 2021
%%% Thu Apr 29 04:31:50 PDT 2021
Think about the idea of using pretrained transformers as universal computation engines introduced in Lu et al [171] as a form of grounding. Structurally speaking, the resulting architecture would have the pretrained layer as the lowest level in the perceptual hierarchy, and, hence, all the additional perceptual layers would be grounded upon this foundation. Suppose that this base level is trained in the earliest stages of development and its weights made resistant to subsequent changes. During these earliest stages the infant is learning to use its body in order to interact with its environment.
Modulo variation in the environmental stimuli that the baby is exposed to and assuming a normal healthy baby, this early experience is, in some sense, universal, and hence it could serve as the foundation of a common ground shared by all humans. Think about how you might go about testing this theory. How does this relate to the ideas that Felix brought up in his talk concerning how limitations in our perceptual apparatus encourage explorative behavior and more careful observations thereby resulting representations that improve generalization and reduce sample complexity [134, 134]. Are there any particular steps in training agent described in the Abramson et al [2] that Greg talked about in his presentation that might encourage such grounding. See if you can can come up with a simple demonstration – an easily trained model and set of experiments, to demonstrate the plausibility of this hypothesis.
The two most important factors that determine the basis of our grounding in such a way that our individual grounding is similar to that of other human beings in the culture in which we were raised are (a) our shared genetic heritage to the extent that our genes influence our neural architecture, and (b) the innate predisposition of our parents to interact with us coupled with our predisposition to respond to them so as to elicit their genetically programmed responses during the earliest stages of our postnatal development.
Beyond these factors that contribute to enhancing our shared ground with others, cultural isolation of the sort enforced by the Japanese Tokugawa shogunate between 1633 and 1853 could potentially lead to a lessening of shared ground leading to misunderstanding and conflict between cultures, with the process of reestablishing common ground after a protracted interval of self isolation requiring a lengthy process of reconciliation and intermixing of cultures – a process certainly not aided when the American Black Ships commanded by Matthew Perry forced the opening of Japan to American trade through a series of treaties29.
Miscellaneous Loose Ends: Matthew, Peter, and Manan might be interested in the architecture described in this paper [92] on one-shot learning. Ilya Sutskever and Pieter Abbeel are the senior authors on the paper and this work came from OpenAI where you can learn more. BibTeX references and abstracts are provided in the footnote 30.
April 26, 2021
%%% Mon Apr 26 05:38:44 PDT 2021
Design of a hierarchical perceptual model consisting of memory-mapped representations inferred from multiple streams of discrete sensory data generated by an integrated development environment in the process of writing and debugging computer programs. The hierarchy is organized in multiple layers of (primary) unimodal features, (secondary) compositional features, and abstract multi-modal (association) features. These representations are used to infer the appropriate context for selecting and deploying actions corresponding to code transformations employed in standard workflows used in automated code repair. Features that share the same topography – whether in the same or different modality – are generally aligned to reflect their topographically-specialized physical relationships31
Programs are generally represented and communicated as sequences of tokens corresponding to well-formed formulas in a particular formal language. A program is an instantiation of an algorithm and algorithms are different ways of generating programs that perform a specific function. An execution trace of a program is essentially a path through the corresponding computational graph that records the time series of variable bindings in the program. Input-output pairs are often used to describe programs but are generally not capable of defining a program unless you are able to provide the set of all input-output pairs that a program generates.
While programs, algorithms, and computational graphs are the fundamental entities of programming, there are other representations of programs and artifacts of programming that might serve as a better basis for learning how to program. Programmers generally write programs using an editor and some form of version control to track changes in the process of developing code. Every time a programmer commits his or her changes the system retains a record of those changes sufficient to be able to revert to a prior version or restore the previous abandoned version. The record generated by version control represents a tree – or directed graph – of transformations, some leading to dead ends and some leading to correct versions of programs and as such could serve to train a neural programming model.
In the same way that an execution trace provides a record of computation, the diffs between the commits implicit in the version control record provide a record of the steps taken to generate the program. The steps in this record do not include every action taken by the programmer, but more often than not, at least in the case of professional software engineers, they do capture multistep operations that generally serve to advance the process of writing useful code. I submit that they could serve much the same purpose that motion-capture data comprised of joint-angle snapshots from which actuator-motor movements can be inferred serves in the Merel et al paper.
The changes in diffs tend to correspond to one or more coherent transformations in the code intended to implement some component function or repair some problem in the code. In the case of a veteran programmer, they are often bracketed by a successful run of the program that passes all the unit tests, assuming that the programmer isn’t simply being cautious by submitting, but not committing, the recent changes. This property of diffs in the case of a competent programmer implies that more often than not they could be employed with some adjustment as actions that the assistant could use in writing or repairing programs.
Miscellaneous Loose Ends: My comment regarding Chaufei’s mention of Mitchell and Hofstadter’s COPYCAT model of analogy was just me stating my opinion that the representations and related neural circuitry that provides the basis for making analogies are distributed throughout the cortex and the machinery that recognizes, generates, and makes of analogies is probably baked into the perceptual apparatus at a fundamental level, perhaps in the form of an objective function / inductive bias that favors contrastive representations of the sort produced by contrastive predictive coding.
I like the idea of thinking about Logo, Karel, and other DSL programs as dynamical system models corresponding to a child’s perception/model of a dog or cat and the way in which the two animals might be represented so that they share some aspects, but also exhibit differences, and how the child might differentiate between situations in which it makes sense to think of them as similar and those in which it is likely inappropriate.
April 22, 2021
%%% Thu Apr 22 14:26:06 PDT 2021
HIERARCHICAL & COMPOSITIONAL MODELS
This sort of activity is fundamental to everything that we do from shopping for groceries and making breakfast to writing and debugging programs. Three-year-olds are already adept at it and it wouldn't surprise me if month-old babies already have the rudiments of such goal-directed behavior. How is it that we have failed to recognize this and incorporate it into the foundation of the artificial agents we build? Nils Nilsson made it central in his STRIPS planner, and his colleagues at SRI used it as the basis for controlling SHAKEY, the first general-purpose mobile robot to be able to reason about its own actions. Herb Simon and Allen Newell recognized the limitations of human reasoning and characterized human behavior in terms of "satisfying" which goes hand-in-hand with knowing when to give up. GOFAI got this right. Why are we recognizing this only now?
[MISC: Markov Decision Problem (MDP); Bellman optimality; Partially Observable MDP (POMDP); stochastic and nonstationary environments; optimal control; the value of information and predictive coding, memory systems in humans and non-humans, and the problem of keeping track of what you've done, what you haven't and what to do if your current plans show signs of failing; affordances, squirrels, and doing sums and products in your head]
ANALOGICAL REASONING & BRUTE SEARCH
Homo sapiens are storytellers. Every time a story is told it is adapted to account for the storyteller's particular needs, aspirations, and abilities to understand the original story. Successful adaptations are the basis for human culture, and our capacity for learning and adapting stories is the direct extension of natural selection and the ultimate Malthusian challenge to Darwinian evolution. Douglas Hofstadter got this right in his Gödel, Escher, and Bach. Richard Dawkins probed the phenomenon in his formulation of the meme as the fundamental unit of cultural transmission. Think about how might we reinterpret the Hong et al paper on the Latent Programmer and the Van den Oord et al work on contrastive predictive coding in terms of making and using analogies?
[MISC: As a schoolboy Carl Gauss saw symmetries where his classmates saw only tedium and a make-work waste of time; pedagogy and algorithmic stories; generating a curriculum is easy, effective teaching requires the flexibility to depart from and creatively apply curricular guidance; paraphrasing Stephen Hawkings and Bertrand Russell, "It's analogies all the way down"; babies are learning machines with a boot ROM full of useful hacks]
ONE-SHOT LEARNING COMPLEX WORKFLOWS
In the Abramson et al paper there is a definite hierarchy of plans and procedures. For example, the GETTER agent learns how to find a red ball, then how to pick it up, and how to put it on the top of the table – these constitute three separate separately-learned subroutines. The GETTER agent first masters how to carry out each of these tasks independently, and then learns how to combine them in order to perform a high-level task such as putting all the toys scattered about the house into the box in the corner of the blue room. It's not enough to just string together the three subroutines.
What is an analogous task in the assistant's domain that involves writing programs composed of previously learned subroutines? Here's an example: given a problem posed as a program specification, search for a program that partly solves the problem, modify this program in an attempt to solve the entire problem, then repair the bugs in the modified program and test it to determine if it satisfies the supplied specification. It's not enough to string together the subroutines in this case either. In either case, when does the agent learn to use the search, modify and repair subroutines to construct a program involving loops and conditional branching?
[MISC: suppose the apprentice was able to observe the programmer carrying out the task described above, would it be any easier for the apprentice to construct a program; suppose the assistant has observed the programmer carrying out the task only once; could we expect the programmer to invent or discover templates that simplify writing new programs; might Karel programs be used as the basis for algorithmic analogies]
P.S. The white paper and python code that I developed as a proof-of-concept for a product pitch at Google and shared with you is basically a dialogue management system implemented as a hierarchical planner. The planner can be used to interact with a user and is able to generate high-level persistent goals, execute low-level tasks that achieve the preconditions for other tasks and subgoals, pursue subgoals recursively and backtrack from failures. Think about how such a planner could be used to automate a flexible curriculum learning protocol.
April 21, 2021
%%% Wed Apr 21 05:45:07 PDT 2021
Design Desiderata for the Programmer's Apprentice (PA) Development Interface:
Keep it Simple, Silly: Wherever possible resist the urge to build systems that mimic human perceptual or motor capabilities and figure out ways to provide the necessary functionality without sacrificing performance or needlessly complicating the assistant's design or programmer's job.
For example, the assistant doesn't need dexterous hands to type or point, vision to see or read, ears to hear or track, etc. Assume that interaction is limited or if a modality is absolutely required to carry out the assistant's duties, provide it by way of alternative "bolt-on" prosthetic devices.
Consider how the programmer might point to a variable, indicate a specific subexpression, or establish a relationship between two symbols in a program listing. In terms of developing a prototype or proof of concept, we could easily finesse such behavior. In terms of justifying such a move, the assistant could be outfitted with a computer vision system that directly operates on digital snapshots of the screen.
Indeed we can dispense with digital image processing altogether and interpret a statement of the form, "the programmer points to the variable FOO in the list of formal parameters of the procedure BAR as the programmer points to node Z425 in the abstract syntax tree W384.
Similarly, we expect the assistant to engage in self-initiated repair, attempted mimicry, shared attention, interpreting pronominal references, etc., and assume that the programmer will respond by making it clear as to whether the assistant has succeeded or failed.
Supporting Task Related Workflows: Suppose that for one class of tasks, the assistant has to ingest programs in the form of their abstract-syntax-tree representations and produce an embedding space that encodes their static (syntactic) and dynamic (semantic) properties as well as features that capture their function in the form of input/output pairs, and their design features including.
This infrastructure could support the downstream development of the neural circuits employed in the latent programmer model featured in the Hong et al paper that Rishabh featured in his talk, but it could also potentially support the formation and application of analogies. In designing the assistant architecture, you need to figure out what features and affordances you want to expose.
The interface would have to support the analog of a sensory stack consisting of networks – likely implemented as transformers – that imitate the hierarchy of sensory areas in the (single modality) primary, secondary, and (multi-modal) association areas occupying the occipital, temporal, and parietal lobes, but supporting sensory modalities specific to the assistant's requirements.
Reasons to strive for training-data efficiency: (a) it is rare to find a suitable source, (b) it is expensive to collect, generate or curate, and (c) there now exist technologies that achieve low sample complexity while at the same time exhibiting improved generalization, and we should try to demonstrate this.
The white paper and python code that I developed as a proof-of-concept for a product pitch at Google and shared with you is basically a dialogue management system implemented as a hierarchical planner. The planner can be used to interact with a user and is able to generate high-level persistent goals, execute low-level tasks that achieve the preconditions for other tasks and subgoals, pursue subgoals recursively and backtrack from failures.
The planner can execute Python scripts and use the results in formulating plans and setting goals32. It was intended to implement an assistant that interacts with a user to infer her music preferences and suggest songs she might like to listen to. In principle, it could be used to implement a programmer's apprentice; however, aside from learning user music preferences, it doesn't learn new engagement strategies, but I'm not suggesting we use it to implement the apprentice.
I'm am suggesting, that we might use it – or something like it – to train the assistant, by having it substitute for the simulated setters, prompters, and demonstrators trained using data generated by the Google team of Mechanical Turkers to interact with the getter. Among other features, the hierarchical planner could be extended to administer short lessons in which the assistant is presented with a program with bug generated by taking a correctly functioning bug-free program and "ablating" it thereby rendering it buggy.
A sequence of lessons involving increasingly challenging programs and bugs could be administered ... the planner's ability to backtrack and attempt different strategies for encouraging the assistant to repair the program ... whether or not you follow my suggestion to implement this approach structured training, assume that you do and ask yourself how would we prepare the assist to tackle these repairs ...
I can understand from a functional standpoint why you would want to have nested hierarchical planners, but I don't think there is a need for nesting in that we can emulate nesting simply by imposing a hierarchy on the goals. However, your mention of nesting induced me to think about several related issues pertaining to what we expect our assistant agent to learn.
In the Abramson et al., paper there is a definite hierarchy of plans and procedures. For example, the GETTER agent first learns how to find a red ball, then how to pick it up, and how to put it on the top of the table – these constitute three separate subroutines. The GETTER agent first masters how to carry out each of these tasks independently, and then learns how to combine them in order to perform a high-level task such as putting all the toys scattered about the house into the box in the corner of the blue room.
What sort of analogous task involving nested subroutines might arise in the assistant's domain. Here's an example: given a program specification, find a candidate program that partly solves the problem, modify this program in an attempt to solve the entire problem, then fix the bugs in the modified program and test it to determine if it satisfies the provided specification. We can probably find better representative problems, but we need to demonstrate how we might solve such problems if we are to claim we've created a symbolic analog of the Abramson et al., interactive agent. Yash and I have been working to address just this problem.
April 20, 2021
%%% Tue Apr 20 04:28:12 PDT 2021
The distinction between parallel and sequential processing is as important in biological information processing as it is in information processing on conventional computing hardware. The technical issues are complex and beyond the scope of this short commentary; it is the practical consequences with respect to the design of interactive agent architectures that we focus on here.
Figure 4 shows a snapshot from my research notebook – paper not digital – that I use for writing down ideas and drawing diagrams that illustrate architectures and abstract concepts I prefer thinking about visually, especially when they are in the early formative stages. The diagram in the figure was actually an introspective exercise in thinking about so-called executive cognitive control.
| |
| Figure 4: An excerpt from my research notebook describing an exercise in introspective inquiry conducted to convey to the class at a visceral level some perspective on how much the behavior of our artificial agents differs from that of human agents and start a discussion concerning how we might finesse some of issues in designing the curriculum learning protocol for training the programmer's apprentice. | |
|
|

The green arc near the top indicates the beginning of this exercise and the circled tags A through E indicate the order of my thinking. In A into a simple version of the hierarchical models we have been talking about in class showing two levels of the hierarchy. The B annotations to the right were meant to summarize our ideas about how the levels align with conventional programming concepts.
The diagram shown directly under B was intended to visualize a neural network architecture that might be used to implement such a hierarchy, and the comment, "not quite what I was expecting" was meant to convey the sentiment that the visualization did not stand the test of my thinking about how to map the cognitive behavior of the apprentice onto a rigidly staged series of transformers.
The text adjacent C summarizes the source of my misgivings about this architecture by imagining the information processes involved in the activities of pedaling a bicycle, scratching an insect bite, signing your name to a document, spell-checking a paper, and the arc of my thinking when in the midst of writing code I simulate in my head a subroutine call that determines a branch point in the program.
The diagram to the right of D is a cartoon representing a sagittal section of the human brain showing the motor cortex and the prefrontal cortex divided each divided into three adjacent sections: primary, supplemental, and premotor cortex and three adjacent of the PFC believed to be involved in aspects of executive control characterized in terms staging, gating, sequencing and motivating behavior [91, 20, 105].
The point is that neither the motor cortex or the PFC subscribe to the simple hierarchical architecture pictured in A. This is not a revelation to me, but simply a reminder of how much more complicated information processing and behavior generating computations are in the human brain compared with that of the programmer's apprentice for the interactive agent describing Abramson et al [2].
The comments in E bring this home as they reflect on my simultaneous writing down my thinking. The printing reveals even more given that the handwriting, spelling and discursive commentary reflect my general carelessness, manifestations of dyslexia, and insecurity knowing someone might actually read what I wrote and judge me on the merits of these unedited, stream of consciousness meanderings.
It should be clear that, even in the case of the IAG agent, it is necessary to engineer how the setter agent coordinates its verbal interactions with the getter agent and its physical interactions with the environment that they share together and through which they communicate using gestures, shared attention and common grounding. The hope is that, counterintuitively, the focus on programming in the PA application and the role of the apprentice as an idiot savant hacker, may make our problem easier.
Miscellaneous Loose Ends: My students and I have experimented with various biologically inspired architectures based on work by Bernard Baar [14], David Badre [21, 19], Stanislas Dehaene [175, 85], and Joaquín Fuster [107]. The structural, functional and computational hints provided by their research are certainly intriguing, but I don't think they provide enough reliable information for anything but a superficial translation to engineering neural network architectures.
April 19, 2021
%%% Mon Apr 19 09:00:03 PDT 2021
Hopefully by now you can appreciate why I introduced you to the work of Nando de Freitas and Scott Reed in the second lecture. In particular, I emphasized the "interpreter" aspects focusing on the role of interpretation as it pertains to what are now called interpretable representations [3, 184], i.e., representations that transparently explain what they are good for. Since that first lecture we have heard Rishabh Singh, Dan Abolafia and Yash Savani talk about the role of interpretation in building models that leverage research in natural language processing to create encoder-decoder pairs that can be used to generate code specifications.
I want you to do a few thought exercises to review and solidify your understanding. In keeping with the computer science perspective that Yash, Dan and I have emphasized, think about the layers in hierarchical models as stages in compilation that align with standard developer tools like assemblers, just-in-time bytecode interpreters and optimizing compilers. How would you implement each of these using BERT-style transformer stacks? Recall how Rishabh used a discrete latent code to represent a higher level of abstract tokens as an intermediate stage in searching for – essentially compiling – a program for solving a specified task, and reflect on our discussion concerning contrastive predictive coding and vector-quantizing variational autoencoders.
Now think again about the sequence of stages in compiling. Could we extend the Latent Programmer to include additional intermediate coding layers as Yash described in his presentation, including a base layer for architecture-specific microcode generation, for example, INTEL/X86 or ARM/A32, essentially grounding the system in the apprentice's interface (IDE) to the programmer's environment, a layer that operates at the level of the precompiled built-in functions in the target high-level programming language, and a layer on top of that starting with a natural language specification and producing the source code listing. Each layer in the hierarchy corresponds to a different language for describing programs, allowing for a relatively simple transformer-based neural network architecture.
I would expect that some variation on the generalized concept of analogy will play a key role in each level of the hierarchy sketched above. What is missing – and what we will have to supply in order to build such a hierarchy, is the perceptual, relational and procedural primitives that provide the representational and reasoning basis for encoding the models and mappings between them and support analogy making. However challenging that might seem, I believe that thinking about the problem in these terms will simplify and focus our efforts going forward.
With respect to lessons we might learn from neuroscience, I suggest that you search for relevant papers on "complementary learning systems theory" and in particular papers on this topic authored by Jay McClelland and Dharshan Kumaran. With respect to relevant perceptual, relational, and procedural primitives, I suggest that you search for neural programming papers that go beyond simply embedding the syntax of programs or their natural language specifications and attempt to understand the underlying procedural semantics of running programs.
In his invited lecture, Rishabh described how this is accomplished in his paper with Wang et al [241] on "dynamic neural program embedding for program repair". I advise you to start with his paper and then review Rishabh's talk. I've also included the abstracts and BibTeX entries for several other of his related papers, and suggest you sample from these and then reach out to Rishabh who has indicated a keen interest in working with individuals and teams focusing on neural programming33.
Miscellaneous Loose Ends: By the way, a biologically plausible solution to the problems addressed in this entry would no doubt involve Fuster's hierarchy and ideas related to Baar's and Dehaene's global workspace hierarchy. Since I've covered this extensively in earlier entries in this document and the discussion notes for last year I won't revisit the subject in this entry.
April 17, 2021
%%% Sat Apr 17 05:48:05 PDT 2021
The objective of this entry is to encourage you to investigate the connections between contrastive predictive coding [251], methods for learning neural discrete representations [234], and the use of vector-quantizing variational autoencoders to learn discrete latent embeddings [234, 210]. The reason is that these technologies apply to several core problems that we are emphasizing in class this year. They include (i) generating analogies by contrasting abstract relational structure as in the work of Hill et al [135], (ii) hierarchical search strategies for program synthesis in the work that Rishabh Singh talked about on Tuesday [141], and (iii) the use of unsupervised and auxiliary supervised learning methods in training interactive agents [2]. In the remainder of this entry, we briefly discuss (iii). Related references and BibTeX entries with abstracts are provided in this footnote 34.
| |
| Figure 5: An overview of contrastive predictive coding from Figure 1 [251] (PDF), the proposed representation learning approach. Although this figure shows audio as input, these techniques have been applied to image and language processing tasks, as well as neural program synthesis as in the case of Hong et al [141]. | |
|
|
Language Matching and Contrastive Predictive Coding
The Language Matching (LM) auxiliary task was partially inspired by developments in contrastive self-supervised learning (Chopra et al, 2005; Gutmann and Hyvärinen, 2010; van den Oord et al, 2018; Hnaff et al, 2019). The idea was that the visual observations in an expert trajectory are correlated with the instruction provided by the expert setter. This was especially true for instructions like manipulating named objects, going to locations, etc. We made use of this observation by effectively doubling the batch size: in the first part of the batch we had the visual observations and associated language input to solver from real trajectories; in the other part of the batch, we had the same visual observations and the language input from other trajectories (shuffled from the same batch by taking the language from the next batch element modulo the batch size B) – see Page 65 in Abramson et al [2] (PDF).
In the following we focus on contrastive predictive coding – see as Figure 5. We discussed vector-quantizing variational autoencoders in some depth in the appendix to last year's class discussion notes – see here. Much of the following explanation of contrastive predictive coding is borrowed from Papers With Code.
Contrastive Predictive Coding (CPC) learns self-supervised representations by predicting the future in latent space using powerful autoregressive models. The model uses a probabilistic contrastive loss which induces the latent space to capture information that is maximally useful to predict future samples.
First, a non-linear encoder genc maps the input sequence of observations xt to a sequence of latent representations zt = genc(xt), potentially with a lower temporal resolution. Next, an autoregressive model gar summarizes all in the latent space and produces a context latent representation .
A density ratio is modelled which preserves the mutual information between xt+k and ct as follows:
where ∝ stands for proportional to – meaning up to a multiplicative constant. Note that the density ratio f can be unnormalized – it does not have to integrate to 1. The authors use a simple log-bilinear model:
Any type of autoencoder and autoregressive can be used, e.g., the authors suggest strided convolutional layers with residual blocks and GRUs.
The autoencoder and autoregressive models are trained to minimize a loss function based on noise-contrastive estimation (NCE) which is a type of contrastive loss function used for self-supervised learning [119] described as follows:
Given a set of of N random samples containing one positive sample from and negative samples from the 'proposal' distribution , we optimize:
Optimizing this loss will result in estimating the density ratio, which is:
April 15, 2021
%%% Thu Apr 15 14:02:45 PDT 2021
Programs as a Basis for Analogy as Search
Focusing on analogical reasoning as an alternative to brute force search for program synthesis. Think about computers programs as an accessible and diverse source of models for dynamical systems that come complete with a simulator that can be readily used to generate embeddings that encode syntactic, relational and semantic properties of code. How might you use analogical reasoning – essentially mappings between models that preserve key features – to suggest program alterations in service to code synthesis, repair and reuse?
Curiosity Driven Hierarchical Modeling
The advantages of hierarchy and compositionality explain many features of the primate brain. It was the "deep" part of Hinton's 2006 paper in Science that fueled the resurgence of interest in connectionist models, but there is much left to learn about how to efficiently train and actively explore the world in order significantly lower sample complexity and reduce reliance on supervised learning. We consider two promising paths forward, one focusing on curiosity as an alternative to extrinsic reward-driven learning [195] and the other on exploiting features learned in one domain to bootstrap learning in another [171].
Multi-modal Collaborative Communication
How might we engineer a collaboration strategy relying on a hybrid / multi-modal communication protocol that combines spoken language and the use of pointing and related nonverbal communication to simplify the former by using the latter to resolve ambiguity, describe complex multi-step procedures, and establish a common ground for efficiently communicating and learning complex coding skills? Our understanding of the developmental stages governing the acquisition of language in humans and the embodiment of an innate facility for working with code in the programmer's apprentice suggest a possible solution.
April 14, 2021
%%% Wed Apr 14 06:43:04 PDT 2021
Programs as a Basis for Analogy as Search
%%% Fri Apr 09 05:14:28 PDT 2021
I'm primarily interested in how the environment and natural selection have shaped animal brains and perceptual apparatus to understand and interact with complex dynamical systems including one another ... or perhaps, especially one another ... and in particular the role of grounding as the basis for unsupervised learning hierarchical sensorimotor systems, and the developmental process whereby parents and enviromentally tuned instincts and inductive biases accellerate this process.
It seems clear to me that in order to learn now to interact with – and in particular control and shape the behavior of – complex dynamical systems you have to be exposed to a wide range of systems to bootstrap your ability for such interaction. Computers and computer programs provide an incredibly rich source of dynamical systems. By enabling interactive AI systems to tap into this resource, we should be able to design highly adaptable systems. There's no magic in our ability to write sophisticated programs other than our ability to leverage analogy in recycling and repurposing previously discovered algorithmic ideas.
Connection to search in Alpha Go and Alpha Zero: The combination of a "smoothed" / distributed / superposition / embedding of billions of chess situations / moves that plays much the same role as the underlying model space for constructing / applying analogies where proximity in embedding space serves as a proxy for analogical relatedness.
Connection to mathematical theorem proving: physical / geometric intuitions initially serve as the scaffolding for grounding our understanding of complex mathematical concepts but eventually stretch the analogy to the extent that they mislead and, while they still might help to suggest a path to a possible solution, in fact require extensive repair to complete the proof.
Connection to creative adaptation of recipes: in cooking where we often succeed – by some often wishful thinking interpretation of "succeed" – in adapting, say, your grandmother’s recipe for buckwheat pancakes to make crepes; the reason for our success often owes little our analogical prowess and everything to our naivete and willingness to compromise on both taste and presentation.
Connection to Lampinen et al [162] emergent analogies hypothesis: the authors suggest analogies arise naturally in the course of agents being exposed to diverse dynamics in the process of training on analogous tasks. This approach builds on previous work [138] showing that neural networks are capable of extracting analogous structure from knowledge domains non-overlapping in their inputs and outputs.
Connection to Rishabh Singh's Latent programmer model: in their recent ICLR paper Hong et al [141] describe a two-level hierarchical search strategy that uses a vector-quantizing variational autoencoder (VQ-VAE) to generate a latent code accounting for the input-output pairs specifying the desired target program in order to positively bias and reduce subsequent brute force search.
April 12, 2021
%%% Mon Apr 12 17:57:38 PDT 2021
Two insights I gleaned from our group discussion yesterday morning: first, there is the idea that a program is simply a representation of a policy combined with a description of the set of circumstances in which the policy might reasonably be deployed. In one sense, this is obvious and implicit in many of the architectures that we've been considering. However, when Yash said this yesterday, I realized that I'd biased my outlook by implicitly assuming there is one huge policy that governs all behavior – which is not to say that there aren't neural circuits that serve in an executive or supervisory / meta-reasoning capacity.
Once you free yourself from this conceit, you can imagine constructing all sorts of bespoke policies designed to solve specialized problems. Retrospectively, I can use this broadened perspective to better understand how Greg Wayne, Nando de Freitas, and Yash Savani think about acquiring procedural knowledge, and appreciate the insights of Gershman and Daw in rethinking the connection between reinforcement learning and episodic memory [244, 212, 110]. I don't claim that this insight is either fully formed or easy to implement, just that you think about it and perhaps review the comments on RL-MEM in [244].
In particular, you can easily imagine exploiting episodic memory in the form of external memory networks similar to – but not exactly like – differentiable neural computers and neural Turing machines to construct key-value pairs in which the keys define the context for deploying a given procedure and the values determine the specialized policies for carrying out that procedure. This is in fact what we proposed a year and a half ago and subsequently dismissed, thinking our solution too baroque or, at the very least, too much at odds with current best practices – see Figure 12, Dean et al [77] here.
@article{GershmanandDawANNUAL-REVIEWS-17,
title = {Reinforcement Learning and Episodic Memory in Humans and Animals: {A}n Integrative Framework},
author = {Samuel J. Gershman and Nathaniel D. Daw},
journal = {Annual Reviews of Psychology},
year = {2017},
volume = {68},
pages = {101-128},
abstract = {We review the psychology and neuroscience of reinforcement learning (RL), which has experienced significant progress in the past two decades, enabled by the comprehensive experimental study of simple learning and decision-making tasks. However, one challenge in the study of RL is computational: The simplicity of these tasks ignores important aspects of reinforcement learning in the real world: (a) State spaces are high-dimensional, continuous, and partially observable; this implies that (b) data are relatively sparse and, indeed, precisely the same situation may never be encountered twice; furthermore, (c) rewards depend on the long-term consequences of actions in ways that violate the classical assumptions that make RL tractable. A seemingly distinct challenge is that, cognitively, theories of RL have largely involved procedural and semantic memory, the way in which knowledge about action values or world models extracted gradually from many experiences can drive choice. This focus on semantic memory leaves out many aspects of memory, such as episodic memory, related to the traces of individual events. We suggest that these two challenges are related. The computational challenge can be dealt with, in part, by endowing RL systems with episodic memory, allowing them to (a) efficiently approximate value functions over complex state spaces, (b) learn with very little data, and (c) bridge long-term dependencies between actions and rewards. We review the computational theory underlying this proposal and the empirical evidence to support it. Our proposal suggests that the ubiquitous and diverse roles of memory in RL may function as part of an integrated learning system.}
}
The second insight came from Yash talking about programs as interpretable representations and my thinking about a new (2021) paper that Rishabh sent earlier in the week [141], focusing on learning representations of the outputs of programs that are specifically meant for search, rich enough to specify the desired output but compact enough to make search more efficient – see Hugo Larochelle's slides on NADE Neural Autoregressive Distribution Estimators starting on Slide 7 here. This approach is similar to the strategy that we explored briefly in the second lecture of creating a space of models and a method of mapping one model to another in searching for a suitable analogy to guide search.
@article{HongetalCoRR-21,
title = {Latent Programmer: Discrete Latent Codes for Program Synthesis},
author = {Joey Hong and David Dohan and Rishabh Singh and Charles Sutton and Manzil Zaheer},
volume = {arXiv:2012.00377},
journal = {CoRR},
year = {2021},
abstract = {In many sequence learning tasks, such as program synthesis and document summarization, a key problem is searching over a large space of possible output sequences. We propose to learn representations of the outputs that are specifically meant for search: rich enough to specify the desired output but compact enough to make search more efficient. Discrete latent codes are appealing for this purpose, as they naturally allow sophisticated combinatorial search strategies. The latent codes are learned using a self-supervised learning principle, in which first a discrete autoencoder is trained on the output sequences, and then the resulting latent codes are used as intermediate targets for the end-to-end sequence prediction task. Based on these insights, we introduce the Latent Programmer, a program synthesis method that first predicts a discrete latent code from input/output examples, and then generates the program in the target language. We evaluate the Latent Programmer on two domains: synthesis of string transformation programs, and generation of programs from natural language descriptions. We demonstrate that the discrete latent representation significantly improves synthesis accuracy.}
}
Curiosity Driven Hierarchical Modeling
How might we efficiently learn a hierarchy of features along the lines of Fuster's hierarchy [107] consisting of multiple levels of paired, reciprocally-connected sensory and motor subnetworks to achieve reduced sample complexity within each level as suggested in Hill et al [134] and avoid combinatorial explosion as one fills in the levels of the hierarchy one level at a time starting with lowest? This is a challenging problem, and I can safely say that no one has completely satisfying answer. That said, there are several pieces of the problem that suggest tractable solutions might exit, and, given that this class is all about, some of you might want to try your hand. Here is a short reading list that would serve as basis for such a project.
Tishby and Polani [232] prove that constructing such a hierarchy is possible from an optimal control perspective. You can find my notes explaining the results of Tishby and Polani here. In the introductory material on biologically inspired models (PDF) you will find material on the perception-action cycle and hierarchical representations in the primate brain. I've included the BibTex reference and abstract for the paper by Tishby and Polani below.
Geoff Hinton and Salakhutdinov's 2006 paper [136] in Science and the related paper in the same year with Simon Osindero and Yee-Whye Teh [137] appearing in Neural Computation demonstrated how a deep network could learn to recognize digits using a staged training protocol that learned the weights one layer at a time using a learning rule they referred to ascontrastive divergence. Most researchers have forgotten contrastive divergence and train their models end-to-end with stochastic gradient descent, however, the extraordinary success of Lu et al [171] in using a pretrained transformer and the observations of Hill et al [135] concerning learning analogies by contrasting relational structure may warrant another look at Hinton's seminal 2006 papers.
It may be premature to attempt to learn such hierarchical representations. Finding a compelling application or even a simple illustrative example is tricky since Fuster's hierarchy requires a domain in which it makes sense to create a multi-level hierarchies of reciprocally connected action-perception pairs. You may find it interesting to check out this early paper [41] by Matt Botvinick entitled "Multilevel Structure in Behavior and in the Brain: A Model of Fuster's Hierarchy" in which Matt created really simple model to illustrate the potential benefits of Fuster's hierarchy and coined the name. I did a quick literature search and found three relatively recent NLP papers that leverage attentional layers in transformer models to learn tree-structured hierarchical representations – see here for details.
Finally, there is the question concerning how one might take the insights derived from Tishby and Polani [232] and translate their information theoretic / entropy-as-a-proxy for reducing uncertainty into a practical algorithm. In this case, the Pathak et al [195] work on curiosity-driven exploration by self-supervised prediction, speaks directly to the problem of how to motivate an agent to pursue information-seeking goals aimed at learning new skills anticipating the possibility of future rewards in lieu of direct / extrinsic rewards of the sort typically used to train a model by way of reinforcement learning.
@article{LuetalCoRR-21,
title = {Pretrained Transformers as Universal Computation Engines},
author = {Kevin Lu and Aditya Grover and Pieter Abbeel and Igor Mordatch},
year = {2021},
volume = {arXiv:2103.05247},
abstract = {We investigate the capability of a transformer pretrained on natural language to generalize to other modalities with minimal finetuning - in particular, without finetuning of the self-attention and feedforward layers of the residual blocks. We consider such a model, which we call a Frozen Pretrained Transformer (FPT), and study finetuning it on a variety of sequence classification tasks spanning numerical computation, vision, and protein fold prediction. In contrast to prior works which investigate finetuning on the same modality as the pretraining dataset, we show that pretraining on natural language improves performance and compute efficiency on non-language downstream tasks. In particular, we find that such pretraining enables FPT to generalize in zero-shot to these modalities, matching the performance of a transformer fully trained on these tasks.}
}
@article{PathaketalCoRR-17,
author = {Deepak Pathak and Pulkit Agrawal and Alexei A. Efros and Trevor Darrell},
title = {Curiosity-driven Exploration by Self-supervised Prediction},
journal = {CoRR},
volume = {arXiv:1705.05363},
year = {2017},
abstract = {In many real-world scenarios, rewards extrinsic to the agent are extremely sparse, or absent altogether. In such cases, curiosity can serve as an intrinsic reward signal to enable the agent to explore its environment and learn skills that might be useful later in its life. We formulate curiosity as the error in an agent's ability to predict the consequence of its own actions in a visual feature space learned by a self-supervised inverse dynamics model. Our formulation scales to high-dimensional continuous state spaces like images, bypasses the difficulties of directly predicting pixels, and, critically, ignores the aspects of the environment that cannot affect the agent. The proposed approach is evaluated in two environments: VizDoom and Super Mario Bros. Three broad settings are investigated: 1) sparse extrinsic reward, where curiosity allows for far fewer interactions with the environment to reach the goal; 2) exploration with no extrinsic reward, where curiosity pushes the agent to explore more efficiently; and 3) generalization to unseen scenarios (e.g. new levels of the same game) where the knowledge gained from earlier experience helps the agent explore new places much faster than starting from scratch.}
}
@inproceedings{TishbyandPolaniITDA-11,
title = {Information Theory of Decisions and Actions},
author = {Naftali Tishby and Daniel Polani},
booktitle = {Perception-Action Cycle: Models, Architectures, and Hardware},
editor = {Cutsuridis, V. and Hussain, A. and Taylor, J.G.},
publisher = {Springer New York},
year = {2011},
abstract = {The perception-action cycle is often defined as "the circular flow of information between an organism and its environment in the course of a sensory guided sequence of actions towards a goal" (Fuster 2001, 2006). The question we address in this paper is in what sense this "flow of information" can be described by Shannon's measures of information introduced in his mathematical theory of communication. We provide an affirmative answer to this question using an intriguing analogy between Shannon's classical model of communication and the Perception-Action-Cycle. In particular, decision and action sequences turn out to be directly analogous to codes in communication, and their complexity - the minimal number of (binary) decisions required for reaching a goal - directly bounded by information measures, as in communication. This analogy allows us to extend the standard Reinforcement Learning framework. The latter considers the future expected reward in the course of a behaviour sequence towards a goal (value-to-go). Here, we additionally incorporate a measure of information associated with this sequence: the cumulated information processing cost or bandwidth required to specify the future decision and action sequence (information-to-go). Using a graphical model, we derive a recursive Bellman optimality equation for information measures, in analogy to Reinforcement Learning; from this, we obtain new algorithms for calculating the optimal trade-off between the value-to-go and the required information-to-go, unifying the ideas behind the Bellman and the Blahut-Arimoto iterations. This trade-off between value-to-go and information-togo provides a complete analogy with the compression-distortion trade-off in source coding. The present new formulation connects seemingly unrelated optimization problems. The algorithm is demonstrated on grid world examples.}
}
@article{HintonetalNC-06,
author = {Geoffrey Hinton and Simon Osindero and Yee-Whye Teh},
title = {A fast learning algorithm for deep belief nets},
journal = {Neural Computation},
volume = 18,
issue = 7,
pages = {1527-1554},
year = 2006,
abstract = {We show how to use "complementary priors" to eliminate the explaining away effects that make inference difficult in densely-connected belief nets that have many hidden layers. Using complementary priors, we derive a fast, greedy algorithm that can learn deep, directed belief networks one layer at a time, provided the top two layers form an undirected associative memory. The fast, greedy algorithm is used to initialize a slower learning procedure that fine-tunes the weights using a contrastive version of the wake-sleep algorithm. After fine-tuning, a network with three hidden layers forms a very good generative model of the joint distribution of handwritten digit images and their labels. This generative model gives better digit classification than the best discriminative learning algorithms. The low-dimensional manifolds on which the digits lie are modelled by long ravines in the free-energy landscape of the top-level associative memory and it is easy to explore these ravines by using the directed connections to display what the associative memory has in mind.},
}
Multi-modal Collaborative Communication
%%% Sat Apr 10 03:49:23 PDT 2021
How might we engineer a collaboration strategy relying on a hybrid / multi-modal communication protocol that combines spoken language and the use of pointing and related nonverbal communication to simplify the former by using the latter to resolve ambiguity, describe complex multi-step procedures, and establish a common ground for efficiently communicating and learning complex coding skills. As I conceive of it, the pointing and gesturing provides the "physical" backbone for solving a particular problem that crops up often in writing code, and the running commentary in natural language that accompanies the pointing and gesturing helps the assistant – perhaps by using an attentional layer in a transformer stack – in resolving references and providing details concerning the general properties of the objects and processes being pointed to and highlighted in the code.
Imagine the programmer saying to the assistant:
Delete this expression here (highlighting a region in a code listing shown in one window), copy the expression here (highlighting a region in a code listing in another window) and paste it in the location where we just deleted an expression. Now change the name of this variable (pointing to a variable referenced in the just copied expression) to be the same as the variable here (pointing) declared in the signature (highlighting the formal parameter list) of the procedure we were just working on here (scrolling the window and pointing to a variable). Now do the same for the other variable (pointing to another variable in the copied expression) using this declaration (pointing).
@inproceedings{GuadarramaetalICRAS-13,
author = {Sergio Guadarrama and Lorenzo Riano and Dave Golland and Daniel Gouhring and Yangqing Jia and Dan Klein and Pieter Abbeel and Trevor Darrell},
title = {Grounding spatial relations for human-robot interaction},
booktitle = {2013 {IEEE/RSJ} International Conference on Intelligent Robots and Systems},
year = 2013,
pages = {1640-1647},
abstract = {We propose a system for human-robot interaction that learns both models for spatial prepositions and for object recognition. Our system grounds the meaning of an input sentence in terms of visual percepts coming from the robot's sensors in order to send an appropriate command to the PR2 or respond to spatial queries. To perform this grounding, the system recognizes the objects in the scene, determines which spatial relations hold between those objects, and semantically parses the input sentence. The proposed system uses the visual and spatial information in conjunction with the semantic parse to interpret statements that refer to objects (nouns), their spatial relationships (prepositions), and to execute commands (actions). The semantic parse is inherently compositional, allowing the robot to understand complex commands that refer to multiple objects and relations such as: "Move the cup close to the robot to the area in front of the plate and behind the tea box". Our system correctly parses 94\% of the 210 online test sentences, correctly interprets 91\% of the correctly parsed sentences, and correctly executes 89\% of the correctly interpreted sentences.}
}
@article{FuetalCoRR-19,
author = {Justin Fu and Anoop Korattikara and Sergey Levine and Sergio Guadarrama},
title = {From Language to Goals: Inverse Reinforcement Learning for Vision-Based Instruction Following},
journal = {CoRR},
volume = {arXiv:1902.07742},
year = {2019},
abstract = {Solving grounded language tasks often requires reasoning about relationships between objects in the context of a given task. For example, to answer the question "What color is the mug on the plate?" we must check the color of the specific mug that satisfies the "on" relationship with respect to the plate. Recent work has proposed various methods capable of complex relational reasoning. However, most of their power is in the inference structure, while the scene is represented with simple local appearance features. In this paper, we take an alternate approach and build contextualized representations for objects in a visual scene to support relational reasoning. We propose a general framework of Language-Conditioned Graph Networks (LCGN), where each node represents an object, and is described by a context-aware representation from related objects through iterative message passing conditioned on the textual input. E.g., conditioning on the "on" relationship to the plate, the object "mug" gathers messages from the object "plate" to update its representation to "mug on the plate", which can be easily consumed by a simple classifier for answer prediction. We experimentally show that our LCGN approach effectively supports relational reasoning and improves performance across several tasks and datasets.},
}
April 10, 2021
%%% Sat Apr 10 04:06:52 PDT 2021
This entry is a catchall for references relating to neural programming, analogy and Rishabh Singh's lecture next Tuesday. Rishabh and I spoke yesterday about the upcoming lecture, about our joint interests in neural programming and some more esoteric issues that I've summarized in this footnote35. In a response to a request for references from Rishabh on topics mentioned in our conversation about his upcoming lecture in class, he sent the following:
data augmentation for open-source program repositories: https://arxiv.org/pdf/2007.04973.pdf – This paper proposes some interesting ideas to perform semantics-preserving code transformations on programs to augment datasets, and then train a contrastive model to learn semantic representations.
VQ-VAE for modeling discrete program latents: https://arxiv.org/pdf/2012.00377.pdf – In this work, we were trying to see if we can capture some common programmatic idioms as discrete latent, which can then be leveraged to perform divide and conquer style program generation. I will briefly talk about this paper during the lecture also.
Automated tree structure learning using transformer attention: I thought I had seen some earlier work on automated parse tree learning using transformer attention, but I couldn't find a link to the particular paper36. I will send a link soon as soon as I can find that. It could also be something I might be extrapolating as I was recently looking at some papers using custom transformer models to embed tabular structures.
Yes, I am hoping in the lecture and afterwards, I can point the students to a few interesting class project directions. For this particular idea, I was thinking about this paper https://arxiv.org/pdf/2103.05247.pdf – where we can freeze the general transformer attention weights and only fine tune input-output layers.
Here are several papers related to using embedding techniques to represent programs in much the same way as we've seen in natural language processing building on the original CODE2VEC [179, 164] and related embedding space models – specifically on analogical reasoning with such representations [9, 10, 63, 135, 163]. The work by Alon et al may prove especially relevant: regarding [10] see the recorded presentation at POPL [LINK], and the related GITHUB code repository page [LINK], regarding [9] see the poster at ICLR [LINK] and the code repository page LINK.
Miscellaneous Loose Ends: For a relatively high-level overview of the role of analogy in cognition and its promise for informing new approaches to machine learning, read Melanie Mitchell's Abstraction and Analogy-Making in Artificial Intelligencew [182], and in particular the sections on "Deep Learning Approaches" (Page 10) "Probabilistic Program Induction" (Page 13) https://arxiv.org/pdf/2102.10717.pdf. Note that the discussion is pretty high level, but Melanie did her dissertation with Douglas Hofstadter on the Copycat Project, has been contributing to this area for over 30 year and has some good insights. For your convenience, I've compiled the BibTeX references and abstracts for a number of the papers cited above in this footnote37.
April 7, 2021
%%% Wed Apr 7 14:32:58 PDT 2021
The following is an expanded version of a conversation I had with Juliette Love on Monday, April 5 to discuss learning programmer's apprentice models that rely primarily on relatively primitive but effective means of signaling as an alternative to achieving more expressive, but difficult to learn, dialogical competence. Examples of such primitive signaling strategies include: pointing – identifying a variable or missing parentheses in a code listing, highlighting – identifying a area of the shared monitor screen that contains a subexpression in a code listing, gesture – using the mouse to connect two subexpressions such as s variable's declaration and its subsequent initial assignment in the same (lexical) scope, specialized natural language processing tools – using a pretrained network for sentiment analysis to interpret the programmer's vocal signal indicating approval or disapproval of the assistant's most recent changes to the code listing38.
Preparing for Thursday
During Thursday's class discussion I want us to conduct an exercise in applying some of the insights that Eve introduced to us in her talk on Tuesday. To encourage such a discussion, I want to change the emphasis to focus on what may at first seem too abstract and too far from what Eve talked about in class on Tuesday to derive benefit from her insight. I am hoping to nudge Eve just enough so that she will be inspired to abstract from how she thinks about human acquisition of language in helping us to apply what she has taught us to the arguably contrived situation of imitative interactive agents in general and the programmer's apprentice in particular.
Specifically, I want to explore an approach that combines an artificial intelligent agent learning to interact with a human agent in a collective endeavor that requires joint knowledge about programming computers and wherever possible relies upon nonverbal communication and cues for shared attention and establishing common ground to facilitate collaboration. In particular, our goal is to create an automated curriculum learning system that orchestrates a series of graded exercises involving the programmer agent instructing, correcting and providing feedback to the assistant agent learning to program and collaborate with the programmer.
In particular, the language employed to facilitate these exercises would be a combination of natural language as we conceive of it, nonverbal language such as pointing to variables, highlighting regions of text, moving a mouse to illustrate connections between code fragments and sending commands to the integrated developer environment (IDE) to control developer tools that highlight – as in the case of identifying sub expressions, reformulate – as in the case of rendering code as abstract syntax trees, and manipulate code – as in the case of single-stepping through programs in the debugger to illustrate the consequences of purposefully induced bugs.
In addition, we will entertain the notion of programming languages as natural languages for describing computer programs extending the notion to view code as a means of articulating and representing procedural and algorithmic stories that are capable of explaining themselves – what we have referred to elsewhere as interpretable representations [3, 27, 257, 133, 96]. I would probably agree that assembly language and machine code are not natural in the sense the term in being used here, Fortran and C++ are represent formidable challenges to learning, subsets of Python and Racket would probably satisfy the definition and pure functional languages like Scheme and Haskel are simple and transparent enough to facilitate early learning while continuing to support development throughout childhood.
In the same way that a prepositional phrase like "on top of the table" tells a story relevant to the relationship between tables and the support of objects that can possibly sit on tables, so too the Lisp s-expression (equal? x (car y)) tells a story about the relationship between the value of the variable of x and the first item in the list y, where x and y are presumably already bound and their respective values are to be found (interpreted) in the context provided by the larger story being told in the enclosing program. Programs can be interpreted at multiple levels of abstraction but an interpretation at the level of microcode would be like asking someone to explain their behavior at the level of synapses firing. Since it's not necessary for the programmer and assistant to share stories about basketball games, there is little lost in having the assistant acquire Lisp as its first language.
Technically, the evaluation of an s-expression generally takes place within the context of a running program that modifies the values of the symbols in the namespace associated with the lexical closure of the s-expression. The story associated with this evaluation describes the evolution of those values starting from their initial value and continuing until evaluation is complete. Actually, there are many different stories involving multiple levels of detail depending upon the perspective and purpose of the agent telling story.
Typically, the official reference documentation for the programming language provides a story suitable for most programmers share with one another in the case of a team effort. Occasionally however one has to delve deeper, for example, in explaining a piece of code designed to optimize use of the cache hierarchy, or perform some operation in a particular way requiring that the bits in every byte of a reserved block of memory be aligned in some particular way or rely on endianness of the processor architecture. It would be interesting to look into how such stories could be exploited in a manner similar to how Wei et al [245] exploit the combination of code summarization and code generation.
Having attempted to justify the assistant's narrow linguistic focus, there are special cases of learning human language skills that would improve the assistant's ability to interact and collaborate with humans. For example, it would be useful for the assistant to distinguish between utterances that indicate approval or affirmation from those that indicate disapproval or disaffirmation. This is generally referred to as sentiment analysis and there are technologies perform sentiment analysis for applications determine whether a comment relating to a product or website popularity is positive or negative. While falling well short of humans ability to infer sentiment even ambiguous circumstances, adding this technology to the apprentice's repertoire of skills might be considered version of Dr. Spock using a sentiment-analysis tool in lieu of having the ability to detect or interpret human emotion.
Here is a short list of resources that might prove useful in creating the analog of language games [243] for the programmers apprentice application, assuming that employee dialect Scheme as the target language: (i) the Racket language reference documentation – [HTML], (ii) the Racket guide for programmers – [HTML], and (iii) An example illustrating the content in the reference documentation – [HTML]. Other resources including universities and online educational services that offer introductory programming courses, for example the Stanford Computer Science Department, Khan Academy, Coursera and Udacity, from which we could potentially obtain anonymized transcripts of student code samples combined with feedback from teaching assistants who grade and correct them. Also see Yasunaga and Liang [256] for an interesting article on code repair by exploiting diagnostic feedback from compiler error messages.
Training Interactive Agents
Cast of Characters:
Prompter – not an agent per se but rather an important part of the curriculum learning protocol responsible for specifying different classes language games suitable for the getter agent's current level of skill.
Demonstrator – an expert in particular skills that the getter agent has to acquire in order to achieve a certain level of competence and contributes by demonstrating the required skills across a suitably wide range of situations.
Setter Agent – an agent that plays the role of a teacher and that takes suggestions from the prompter agent and generate tasks posed as language games for the getter agent that it conveys verbally based observations.
Getter Agent – an agent that plays the role of the student and attempts to perform the tasks given it by the setter agent as well as providing feedback to guide the getter in surmounting obstacles to its succeeding in the assigned task.
Curriculum Protocol:
Consists of a collection of staged learning components of increasing difficulty in an algorithm for determining when the agent should graduate to the next stage, remain at the current stage, or revert to an earlier stage if there is new evidence suggesting that the getter agent has not mastered the earlier stage and is in need of remedial training. In addition to the curriculum protocol there are additional preparatory steps required to train the agents to achieve an initial level of competence required for efficient reinforcement learning.
Listening to Programs
%%% Wed Apr 7 05:53:48 PDT 2021
What does a program tell you about what it does? What does the trace of a single variable tell you about what a program is doing? What does the trace of every variable in a program tell you? What if we had the complete trace of every variable in a program for a large collection of representative inputs? Note that we could easily generate this data utilizing standard developer tools.
Among other things we would have to be careful not to confuse the values of variables that appear in different functions or even a variable that appears in multiple recursive invocations of a single function. At any given point in time, if you looked on the call stack, you might find dozens of instances of a given variable in the scope of various closures.
The same sort of ambiguity arises in all natural languages that use pronouns whose referents can appear much earlier in text and be superseded at any point by introducing a new referent followed by mention of the new referent using the same pronoun. Some authors require readers to disambiguate a gendered pronoun use by determining the gender of an earlier referent by name alone.
Learning such rules simply by seeing them applied in written or spoken language can be difficult and good authors and speakers try not to produce prose that relies upon them routinely. The same goes for good programmers who strive to make their code easily understood, knowing that in professional software engineering, it is likely that someone else will have to rewrite their code if the need arises.
In order to understand a program well enough to fix a bug, extend its function, reuse it in a new context or adapt it to solve a new problem requires not only being able to understand what the code is supposed, but also understand what sort of mistakes programmers, both amateur and professional, are likely to make and hence the source of bugs that are hard to track down and eliminate.
Here are some things to think about as you read papers in neural programming that propose to learn how to write, repair or reuse code by simply looking at input-output pairs, execution traces, comments, specifications, or other potentially useful but likely inadequate sources of information describing various aspects concerning the syntax and semantics of program.
The point is not to suggest that in order to write code one has to be able to solve all the potential problems alluded to above, but rather to respect that the problem is difficult and that learning to program depends upon a great deal of knowledge and skill that takes decades to acquire and that is not even obvious that is applicable, and indeed prerequisite, to acquiring programming skills.
Miscellaneous Loose Ends: Interaction and negotiation are an essential component of natural language understanding in conversation. We argue this is particularly the case in building artificial agents that rely primarily on language to interact with humans. Rather than thinking about misunderstanding—thinking the user said one thing when he said another—and non-understanding—not having a clue what the user was talking about—as a problem to be overcome, it makes more sense to think of such events as opportunities to learn something and a natural part of understanding that becomes essential when the agent trying to understand has a limited language understanding capability. Moreover, many of the same strategies that are effective in situations in which the agent's limited language facility fails also apply to the agent actively engaging the user in an unobtrusive manner to collect data and ground truth in order to extend its repertoire of services that it can render and to improve its existing language understanding capabilities. Excerpt from Interaction and Negotiation in Learning and Understanding Dialog
April 5, 2021
%%% Mon Apr 5 03:16:36 PDT 2021
Generally speaking, when two agents participate in a dialogue they continually have to make to make guesses about what their interlocutor (the other speaker) knows and whether and to what extent the other speaker understands what was just said. One speaker might interject questions to determine whether the other speaker knows something, e.g., the programmer might say, "Do you understand what I mean when I say this assignment binds a variable to some value?". It also works in the opposite direction, e.g.., the assistant might say, "Do you mean to say that, if I execute THIS assignment, then THAT variable is assigned the value returned by the assignment?" – where uttering THIS and THAT, are accompanied by the assistant pointing first to the relevant assignment and then to the relevant variable. It gets tricky, however, when one of the speakers has yet to master even the rudiments of successful communication.
Body language helps, but then the onus is on the other – presumably language skillful – speaker to identify the level of skill and then either abort the current discussion, or to pursue an appropriate intervention to deal with the misunderstanding and establish an appropriate context for fruitful discussion. Keep in mind that there are two goals being pursued simultaneously in this scenario. The programmer is teaching the assistant how to communicate while at the same time – whether directly or indirectly / systematically or sporadically, teaching the assistant about the "physics" governing the execution of programs. It seems reasonable to suppose that prior to pursuing the former, the assistant has already explored the latter in the same way that a parent in teaching language skills assumes that the child already has some mastery of its body and is capable of shared attention, i.e., is able to determine what the parent is attending to and directing its attention to the same thing.
The curriculum learning protocol will have to stage the pursuit of these two goals – learning to communicate and learning how to interpret and construct computer programs. Perhaps early on it will be necessary to pursue the goals independently, by allowing the assistant time to "play", e.g., conducting a computer-programming version of babbling by randomly executing segments of representative programs, interleaved with the programmer engaging the assistant in communication and guided demonstrations helping the assistant to learn how to write simple programs that achieve objectives like assigning variables or comparing the values of two variables. As the assistant becomes more adept at communicating and more skillful at executing and interpreting program fragments, the two goals – learning to communicate and learning how to understand programs – can be pursued at the same time making it possible for the programmer to systematically engage in more complicated language games in the sense that Abramson and company use the term in their paper [2].
Perceptions:
Directly perceive the programmer's spoken or typed words, the latter via word-to-text
Read / ingest code as text or abstract syntax trees and highlighted code fragments
Read / ingest other text streams including comments and output from developer tools
Actions:
Highlight / point (cursor) formatted text including well-formed expressions in code listings
Invoke any developers tools including setting break-points, single-stepping and REPL I/O
Communicate by speaking out loud using text-to-speech interface and typing in the editor
The basic action-perception cycle can be summarized in terms of the following three activities:
Figuring out how to accomplish a goal, i.e., coming up with a plan for achieving a specific goal.
Figuring out when when some plan is not working and fixing it, i.e., identifying and fixing a bug.
Figuring out when a plan works to achieve a goal, but has been incorrectly applied or executed.
The corresponding communication-related activities might be summarized something like:
Figuring out what someone is trying to communicate, and, if required, verifying it with the speaker.
Figuring out when something you are trying to communicate is misunderstood and how or why.
Figuring out whether the fault is yours or due to the other person being unable or incompetent.
April 3, 2021
%%% Sat Apr 3 03:15:40 PDT 2021
How Hierarchy and Compositionality Reduce Search in Planning and Coding
Suppose you have a set primitive operations that you can perform, and suppose further that using these primitives you can construct a set of K programs by stringing together sequences of no more than J primitives. Assume that these K programs are sufficient to construct any more complicated program that you might need. Think of the J primitives as the zeroth or base level of a hierarchy and the K programs as the first "true" level of the hierarchy, i.e., level-one programs.
Now suppose that we introduce a second level in the hierarchy – ignoring the zeroth, that has as primitives the K programs defined in the first level; to avoid confusion we'll refer to these as the subroutines available for constructing programs in the second level of the hierarchy, i.e., the level-two programs. As in the case of the first level, we now construct a set of K level-two programs by stringing together sequences of no more than J level-two subroutines.
We can continue to build this hierarchy one level at a time. At each level H we need only search in the space of level H subroutines, i.e., sequences constructed from level-(H − 1) programs. Assume you have a specification for each program in level H and that you can test whether or not a given sequence of no more than J level-H subroutines satisfies a level H program specification in constant time.
Then it follows that the asymptotic complexity of building a N-level hierarchy is O(N * K) if we assume that J is constant. That is to say that, while the cost of constructing the level-H programs may be exponential in J, that cost is the same at every level and, if J is relatively small, then at worst all we have to do is enumerate all sequences of levelH subroutines of length J or less.
Before you dismiss the above analysis altogether, think about the simpler sort of programs corresponding to the plans we routinely construct in going about our day-to-day business. By the age of 5, most of us are able to make a peanut butter and jelly sandwich or pick up all of the toys in our room and stuff them under the bed when told to clean up our room. By the age of 10, most of us can prepare breakfast for the rest of the family, and by 20, we can organize a birthday party for a friend including planning the menu, buying groceries, etc.
We also have ways of dealing with contingencies; for example, if we find we are all out of jelly, we might use sliced bananas, or if we run out of eggs we might make pancakes. Obviously, we aren’t always successful coming up with a solution; not many five-year olds could invent a strategy for adding two multi-digit numbers on their own, but then not many adults could either. As we grow up, we observe the people around us solving problems, we imitate their behavior and generalize their strategies to use as heuristics in solving our own problems.
I expect that you can find fault with this argument. It doesn't allow recursion or conditional branching. We could probably add some restricted form of branching and still make the same claims, but almost anything else would run afoul of the halting problem. Tishby and Polani [232] did an interesting analysis of the problem of constructing a perception-action hierarchy proving that under certain conditions it converges to the optimal solution from an information theoretical perspective39.
Alternatives to Natural Language for Programmer-Apprentice Interaction
As background for the following, you might take a look at the short section on semiotics and signifying meaning in the course introductory materials from last year. Consider the following scenario:
The programmer and the apprentice are working on a program. The programmer is monitoring the screen that she shares with the apprentice. She uses the mouse to indicate a region of the screen that contains a subexpression of the procedure that they have been focusing on in their discussion. The apprentice has previously ingested the original program using the IDE tool to first convert it into abstract-syntax-tree format and then updates the AST whenever the programmer or the apprentice makes changes to the code. AST descriptions are represented internally as high-dimensional embedding vectors.
Suppose that the region indicated by the programmer doesn't unambiguously specify a syntactically correct subexpression, and so the apprentice uses the display and the AST to identify a plausible subexpression and then highlights it on the screen. The programmer indicates her approval and the apprentice interprets her utterance as confirming his selection – here we assume that the apprentice has very limited ability to understand natural language but does have the ability to perform sentiment analysis and check with the programmer to make sure he got it right.
Already you should be thinking about grounded language acquisition as a collaborative effort involving the student and the teacher and the importance of joint attention, taking turns, establishing common ground, self-initiated repair, etc. Think about the programmer giving the apprentice a lesson in program repair or programming by substitution – there is a substantial literature from the neural programming community – including work from Stanford – on program repair or programming by substitution, that could be leveraged in a project along these lines.
Having identified a subexpression to focus on, the programmer select another program, and within that program selects a subexpression similar in some respects to the earlier selected sub expression. She copies the new subexpression and uses it to replace the selected subexpression in the program they were originally working on. She then makes modifications to the replacement, e.g., changing a variable name to agree with a declaration in the original program or modifying a loop exit criterion
As the programmer makes these modifications to the program, the apprentice follows along, observing the programmer's modifications to the code with only scant attention to any verbal comments the programmer might make. The apprentice attaches meaning to both pieces of code – the originally selected subexpression and the replacement from the other program, by analyzing nearby vectors in the high-dimensional embedding space in which programs are stored. The changes made by the programmer are analyzed by examining changes in the embedding of the modified program and the results of this analysis used to infer new strategies for debugging, repairing and reusing programs.
We should also talk about how to prepare the crowd-sourcers (Amazon Mechanical Turk (AMT) Workers) to generate the data needed to bootstrap the setter/solver (programmer/apprentice) agent pairs to participate in Language Games using the strategies that Eve discusses in her 2016 book. There are both the strategies used to engage in language games (language acquisition) and strategies used recognize and mitigate misunderstanding in dialogue.
Miscellaneous Loose Ends: Here are some references following up on questions asked in class on Thursday:
Consciousness
Michael Graziano, Princeton
https://web.stanford.edu/class/cs379c/archive/2018/calendar_invited_talks/lectures/04/10/index.html (VIDEO)
Filipe De Brigard, Duke
https://web.stanford.edu/class/cs379c/archive/2019/calendar_invited_talks/lectures/05/21/index.html (VIDEO)
Stanislas Dehaene
Search for "Dehaene" here:
https://web.stanford.edu/class/cs379c/archive/2018/class_messages_listing/index.htm
Theory of Mind
Neil Rabinowitz, DeepMind
https://web.stanford.edu/class/cs379c/archive/2018/calendar_invited_talks/lectures/04/17/index.html (VIDEO)
Class Preparation
Note that these preparatory notes describe work in progress. They constitute a research log for recording ideas, preliminary sketches, sources, etc. The entries are sorted in reverse chronological order — from the latest to the earliest entries — and may provide pointers to later entries that supersede, contradict or build upon ideas discussed in earlier ones, but don't count on it and be sure to search forward in time to see if there are more recent relevant entries.
March 31, 2021
%%% Wed Mar 31 06:24:06 PDT 2021
The advances that I'm referring to concern our understanding of the role of natural language in human communication. They explain the mechanism whereby we can share complicated ideas using the briefest of utterances to describe those ideas.
They also explain the mechanism whereby an infant in the span of just a few years can go from babbling incomprehensibly to providing a running commentary on what they are doing and why.
They provide insight into the human use of analogical and relational reasoning and suggest mechanisms whereby we might implement such capabilities in artificially intelligent agents.
They explain why two people can hear exactly the same thing and yet come to diametrically opposed interpretations of what was said. They explain why a student listening to one of Richard Feynman's lectures can come away believing that they have come to a profound understanding of Feynman's lecture content, and yet not being able to articulate or apply what they claim to have learned.
It is also important to understand that programming languages, and, in particular, high-level programming languages, are also natural languages. Generally speaking, they serve much the same purpose. They evolved in much the same way within different communities contributing to their development, and are subject to similar selection pressures that determine their adoption, application, and refinement – read Bjarne Stroustrup's "The Design and Evolution of C++" [230] if you need convincing.
There is a long road ahead in terms of refining these ideas and using them to engineer AI agents that are capable of both using language and exploiting the cultural heritage available to humans through language in all of its forms including written, spoken, and signed.
March 20, 2021
%%% Sat Mar 20 08:45:28 PDT 2021
The following is an attempt to provide some rigor in describing the computational processes involved in creating and sharing analogies. This is very much a first effort, and, in particular, the second section was hurriedly written while distracted with last minute preparations for the class lectures. The diagram in Figure 6 lays out the entities involved in these processes and the interactions between them. The boxes labeled physical laws and environments will be assumed to be obvious at least at the level required for our analysis. The two pairs of identically coupled blocks enclosed in dashed red lines correspond to two distinct agents attempting to communicate with one another.
| |
| Figure 6: The above graphic illustrates the main components involved and the flow of information between them in a model of how grounding language in our interaction with the physical world naturally gives rise to story telling and analogical reasoning, provides an impetus for societies to create technology to cultivate, disseminate and preserve useful stories and to encourage exploiting their application as a collective means for accelerating innovation in the social and physical sciences, and engineering disciplines. See the main text for a more detailed explanation. | |
|
|

In each case, the separation between the block labeled body and the block labeled brain is intended to convey the idea that – the substantial changes wrought during development notwithstanding, the agent's physical contrivance responsible for interacting with its environment changes at a much slower rate than the neural substrates responsible for processing the agents observations of its environment and its communication with other agents.
The block labeled extelligence40 is intended to represent the information available to human beings in the form of external resources through various technologies curated, managed and distributed by individuals, libraries and universities funded by governments and privately owned institutions. It is the cultural capital that is available to us in the form of external media, including tribal legends, folklore, nursery rhymes, books, film, videos, etc [229], and it is assumed for the present discussion that individuals can effortlessly tap into these resources and contribute to them by adding additional content or editing existing content.
The reciprocal connections labeled A are intended to represent the sensory and motor activities that precipitate changes in the physical substrate providing the-base level interface for interacting with the environment and other agents. We will assume that development of this substrate has advanced to a stage of maturity at which it will remain static for the remainder of the agents life. We do not assume however that this substrate is necessarily identical for all agents, indeed we expect that the influences of nature and nurture to ensure there are substantial differences across individuals.
The reciprocal connections labeled B correspond to the actions performed and the observations made by the agent in exploring its environment and engaging with and learning from other agents. These actions and observations are precipitated and guided by plans and goals that the agent has learned has acquired in its exploration of its environment and, in particular, its exposure to the customs, norms and behaviors prevalent within its social milieu. We assume that agents routinely formulate what we will refer to generically in the sequel as "models" for the purpose of making predictions concerning the consequences of its actions, and that furthermore agents routinely share those models.
The reciprocal connections labeled C correspond to communication channels that serve to facilitate the sharing of models. We assume for simplicity that all the agents use the same finite lexicon of words to communicate, but the meaning of those words can differ depending on the context of their usage, where that context extends to include their general cohort as well as their immediate interlocutors. Since individuals are unlikely have exactly the same grounding, this implies another factor that can contribute to variability in the interpretation of words and cause the negative consequences of misunderstanding as well as the positive consequences of inventive reinterpretation.
Finally, the reciprocal connections labeled D are intended to represent the channels whereby an agent can contribute a model to the extelligence repository thereby making it available to other agents outside the circle of the contributing agent's cohort, or gain access to an existing model allowing them, in principle, to use any model previously added to the repository and successfully preserved. We will say that a model is correct if it makes accurate predictions when applied to systems of the sort that it was originally designed to handle and the words used to define the model are assigned the meaning intended by the contributor.
We assume for simplicity that models are correct, as contributed, if the words used to describe them are assigned their original intended meaning. This does not protect against an agent misapplying a model because they assign different meanings to the words used to formulate the model. It also begs the question of what constitutes the meaning of a word. To resolve these issues, we need to be more careful in defining models and assigning meaning to the words used to describe them.
We assume for simplicity that all models are represented as dynamical systems corresponding to a set of objects, a set of relationships involving those objects and a system of equations or alternative dynamical system model governing their kinematic and dynamic properties. What would it mean to ground such a model? Following the lead of cognitive psychologists like Liz Spelke and her students and collaborators, we might look for signs of grounding in the behavior of infants and young children.
In the case of a model corresponding to the physics governing the trajectory of a thrown ball, evidence of grounding might appear in the observed behavior of a child pantomiming the trajectory by tracing it out in the air. In the case of demonstrating the consequences of a person walking at a steady pace and temporarily disappearing behind an occluding screen, evidence of grounding might be indicated by the child registering surprise when the person doesn't reappear on the other side of the occlusion after a reasonable delay.
When we are talking about modeling physical movements, demonstrations of reproducing familiar movement patterns combined with extrapolating from those movements to predict novel patterns would seem to provide evidence of physical grounding. There is a growing body of research attempting to identify the neural correlates of grounding and naïve physical reasoning, e.g., see the work of Bunge et al [46] examining hypothesized role of the anterior left inferior prefrontal cortex, but there are also predictions we might make based on the known architecture and areal function of the primate brain [249, 116, 100, 46]. See Figure 7 for a summary of experimental results from [249].
If we assume the same sort of hierarchical architecture we find in the sensory-motor cortex consisting of multiple layers of increasingly abstract, multi-modal features built on a foundation of primary unimodal features, we might expect the architecture for representing a hierarchy of models to be organized similarly [83]. For example, in observing the brain of a physicist thinking about a highly abstract model of quantum tunneling in semiconductors, we might observe activity in areas that become active upon observing someone walking along the sidewalk and temporarily disappearing from view for a few seconds upon walking behind an occluding building-construction barrier and subsequently reappearing on the other side.
| |
| Figure 7: The graphic (A) on the left shows regions that demonstrate an increase in activation with accuracy on analogy trials across all participants after correcting for the effects of age. Only the contrast of semantic greater than fixation (shown in yellow) showed a significant correlation in left aLIPC (anterior left inferior prefrontal cortex) – see Bunge et al [46]. The graphic (B) on the right shows regions that indicate an increase in activation with age across all participants. Results for the semantic tasks greater than fixation contrast are shown in yellow, analogy tasks greater than fixation in red, and regions for which both are increasing are shown in orange. There were no regions that showed a within-person differential increase in activation during analogy trials compared to semantic trials. The graphics are from Figures 4 and 5 in [249]. | |
|
|
Similarly the meaning of "the excavator shovel scooped up a huge pile of gravel and deposited it in the back of the dump truck" might employ – be grounded in – models that we learned while still in diapers playing with toys in the sandbox or even earlier when our parents would try to feed us our pureed peas with a spoon while we squirmed in our highchair41.
These early experiences would ostensibly provide the seed for a model and naturally determine its locus for our subsequent integration of related but more complicated interactions. These subsequent interactions would attach themselves as new representations that are defined by the observable characteristics that both identify and distinguish them from the seed representation.
Over time models suggested by related experience would tend to encroach into areas devoted to representing other more abstract models, but, whenever possible, phenomena described using familiar terms like "scoop" and "throw" employed to represent abstract properties of behaviors that share some abstract characteristics with the physical acts of scooping and throwing would strengthen the connections to the original seeds planted in those early experiences.
The use of the word "locus" might appear to allude to some unidentified unitary neural substrate, but that was certainly not intended as it seems much more likely that the circuits implicated in analogical reasoning are widely distributed throughout the brain and the cortex in particular – see the references cited in the earlier discussion in this entry and in Figure 7 and the lecture by Silvia Bunge.
These abstract variants of primal activity are useful insofar as they simplify the description of more abstract models by not requiring the invention of additional, less widely accepted terminology, i.e., jargon, and by doing so they make it easier to succinctly and clearly communicate abstract concepts with others insofar as they can convey the gist of what's involved in the abstract process without introducing impediments in the form of related usage norms that might contradict properties of the abstract process.
In a mature brain, experts may work primarily with the abstract models using specially-crafted cognitive tools designed to deal with the specific characteristics and properties of the abstract models. However, in a more exploratory mode – for example, struggling for intuition concerning some complex abstract mathematical object, we may resort back to the primitive, grounded levels of representation in searching for relevant analogies that might map onto the problem currently distracting us.
Grounding in Synthetic Environments
%%% Sun Mar 21 12:38:31 PDT 2021
If we think of the modern world that we live in as extended to include the informational space of the extelligence, we might ask if there are evolutionary pressures on the ideas that reside in that space. One possible candidate would be the influence of modern scientific and engineering practice and we might conclude that the way in which the scientific and engineering communities judge the products of their respective disciplines serves to impose selective pressures to increase the probability that scientific theories and engineering artifacts stand up to intense scrutiny.
Combine this relentless scrutiny with the fact that there are billions of human beings many of whom have the intellect and education to propose a credible theory or invent a useful artifact, and you have the makings of a powerful engine for generating novel theories and artifacts. Diversity arises from the fact that differences in our grounding of language cause us to interpret what we've been calling algorithmic stories in subtly different ways that nonetheless adhere to a consistent set of rules that potentially could lead to new and novel ideas.
In addition to our natural talent in searching for novel ideas grounded in our experience of the world we live in, scientists and engineers are now experimenting with technologies that enable us to extend the perceptual and interactive capabilities we were born with, allowing us to broaden our experience – and hence grounding – to include physical processes that involve forces acting on arrangements of matter that we can't directly observe and that take place across a wider range of scales than than we can directly observe.
Such efforts include the gamification of protein folding (Foldit) and neural circuit reconstruction (Flywire). The simulators and user interfaces for these online games enable citizen-scientist volunteers to interact with and explore physical systems that would otherwise be inaccessible and inscrutable.
Sophisticated immersive interfaces for powerful simulators allow scientists to explore the universe at both quantum mechanical and cosmological scales. Perhaps more relevant in terms of grounding leading us to come up with new ideas is the ability of these simulators to explore worlds in which the fundamental constants and governing equations are different than the scientific consensus would lead us to believe.
The hypothesis we are entertaining here concerns whether the human use of analogy in the process of exploring / searching the space of possible theories for explaining natural phenomena, designs for engineered artifacts, policies for inducing social change, etc., is efficient when compared to traditional search methods such as Monte Carlo search. Of course it needn't be exclusively one or the other. Monte Carlo search requires a next move generator and clearly some form of analogical reasoning could potentially serve in that role.
In many cases including the use of MCTS (Monte Carlo Tree Search) in AlphaZero, the next move generator is learned and one could imagine having different pretrained move generators for different search problems. Humans effectively have different move generators even though they employ the same neural structures to encode them and apparently are able to avoid catastrophic interference when training them. See Carstensen and Frank [57] for a discussion of neural network architectures that can learn graded – continuous versus symbolic – relational functions and the role of graded relational functions representations in explaining abstract thinking in primates.
Miscellaneous Loose Ends: The programmer's apprentice requires the programmer and the apprentice to establish a shared ground for both natural language and the programming language they use for writing software, and the requirement holds despite the fact the apprentice can only vicariously experience the context in which the programmer learned language. This arrangement is worth more consideration in this discussion list, but, from the practical standpoint of selecting and carrying out a final project involving neural programming, we might dispense with natural language altogether, reduce the role of the programmer to simply a source of models in the form of programs that can be employed in analogical reasoning and incorporate this limited role directly in the apprentice's curriculum training protocol.
In our discussion on Sunday we talked about the problem of keeping track of where in memory we store item that we have to retain for indefinite periods of time. Specifically, we talked about the problem of keeping track of variable bindings and namespaces, contexts and closures, recurrent calls to the same procedure or calling a different procedure that uses the same variable names as the calling procedure. All of these problems are solved in modern programming languages by using a call stack. In earlier work, we considered the possibility of using a differentiable external memory [115] and differentiable programs procedures to implement a call stack. The MEMO system [24] developed by researchers at DeepMind appears to provide an alternative solution that is more generally useful42.
What does it mean for something to be grounded? In some contexts, it means that you are sensible and reasonable – your feet solidly on the ground. In other contexts, it might mean that you are knowledgeable about the basics of something. It is often used in everyday speech to indicate that something said or done can be relied upon. In the sense that scientists and engineers generally use the word when talking about language – and, in particular from the perspective of machine learning and embodied cognition, it means that your understanding of a word is based upon your direct experience of the referent of the spoken, written or signed word.
Note that experiential grounding is not just about language. Grounding is key to understanding of all forms of meaning and biological communication. No matter what situations you are being exposed to, your brain is anchoring you to the experience of those situations and those experiences will shape how you perceive and interpret the world around you. For example, the word "running" might be represented in a neural network as a pattern of activity associated with a particular subnetwork when the word is spoken, read or a physical instance of running is observed or recalled. Donald Hebb referred to these patterns and their corresponding neural circuits as cell assemblies.
Take a moment to think about what it might mean for the programmer's apprentice to ground its experience of instances of the expression (if (equal? X Y) (set! X (+ X 1) else (set! Y to (- Y 1)))) where X and Y are variables assumed to vary? What about experiences of X where X always appears in this context bound to an integer?
Hebb suggested that cell assemblies are formed when such patterns occur repeatedly, as evidenced by the units that comprise such an assembly becoming increasingly strongly inter-associated. Unlike the sort of learning employed in most contemporary research on neural networks, cell assemblies are updated using Hebbian learning accomplished through auto association. It is worth noting that Hebbian learning is unlike the most common methods of learning used in training artificial neural networks. This is unfortunate since there are many problems for which Hebbian learning is appropriate and conventional end-to-end back propagation by gradient descent is inappropriate and unnecessarily introduces problems such as catastrophic interference.
If you find the topic of grounding and Hebbian learning interesting, I'd be glad to discuss current theories about the role of cell assemblies in larger ensembles of reciprocally connected neurons such as the global neuronal workspace model of Stanislas Deheane and Bernard Baars that attempts to explain how diverse cell assemblies throughout the cortex are recruited to solve novel problems. You might also be interested in a new Hopfield network model with continuous states that can store exponentially (with the dimension) many patterns, converges with one update, and has exponentially small retrieval errors.
February 17, 2021
%%% Wed Feb 17 05:10:27 PST 2021
Figures 8 and 9 attempt to create a model – characterized here as an instance of the programmer's apprentice application – that clearly defines the apprentice's physical environment in such a way that makes it clear how the action-perception cycle would be implemented so as to enable training levels L1 and L2 and at least suggests the possibility of a level L3 that receives its input directly from the programmer / curriculum learning policy which is modeled as part of the apprentice's environment.
| |
| Figure 8: The above graphic depicts the "environment" of the programmer's apprentice. Both the programmer and the apprentice can view the screen of a monitor connected to a workstation that is running an integrated development environment (IDE) and a lisp interpreter in a shell. Both programmer and assistant can point to locations on the screen and highlight blocks of code in a program listing – this is what Eve Clark refers to as "shared attention". They can communicate with one another by pointing to the screen, speaking, messaging and adding comments to code blocks. Both can enter commands to the interpreter or IDE. The developer interface makes it possible for the apprentice to directly read output from the debugger and other IDE tools as well as ingest programs either as source code or in the form of abstract syntax trees. | |

Advantages of End-to-End Training
%%% Mon Feb 22 04:19:09 PST 2021
In the group meeting on Sunday, we primarily talked about training. Yash characterized the advantages of the new model as being a able to train the system end-to-end. One advantage is that we no longer have to worry about how to train the coding space separately as was done in the Merel et al [177] paper. A conceptual disadvantage of this is that in the case of the programmers apprentice application the entire hierarchy involves complex interaction between the programmer and the apprentice mediated by natural language discourse and faces the same problems as in the Abramson et al [2] paper having to do with sparse rewards the in early stages of training due to the agent starting out as almost totally incompetent – see mention of the performance difference dilemma in Kakade [151] (PDF).
I attempted to deal with this by suggesting that the programmer, aware of the apprentice's tabula rasa initial state, could bootstrap the apprentice's understanding of programming by training the first two levels using supervised learning, grounding the primitive functions of the target programming language in terms of the register transfers that serve as the microcode for the virtual (embodied) register machine. By grounding in this case, what I mean is that by learning to interpret the primitive functions correctly, it will be able to recognize when a primitive function applied to arguments returns an incorrect result, i.e., it's understanding is embodied. For an agent such as the apprentice, this is ability is analogous to Merel's et al's proprioceptive recognition of muscle twitches. The programmer can feed a sequence of unrelated primitive function invocations and expect the apprentice to behave like decerebrated car [248] (PDF).
This training does not require any effort on the part of programmer any more than a baby learning to crawl depends on its mother. It could be accomplished by using the integrated development environment trace utility to interpret representative programs in order trace only the built-in primitive functions you want the apprentice to learn, analogous to how a fetus learns to move its muscles prompted by self-generated nerve impulses originating in the spinal cord43.
We also had a discussion about the collection of subnetworks – currently we use only the comparator – available to the base-level executive homunculus to interpret programs. Yash had suggested that we add a subnetwork for decrementing an integer which would be particularly useful in implementing simple loops. In particular, he was not advocating adding a general addition function, which I agreed with, referencing a paper by Yan et al [255] on learning to interpret programs involving integer functions by encoding integers as embeddings of their binary representations. Gene asked why don't we just include + and be done with it.
Yash referred to the tradeoffs between reduced instruction set processors (RISC) and complex instruction set computer (CISC) and I mentioned that we came down on the RISC side simply to simplify developing our proof-of-concept demonstration44. We briefly talk about how difficult it was for children to acquire facility with arithmetic operations beyond a basic level of numeracy focusing primarily on properties involving order and magnitude. Beyond this level, learning even basic arithmetic skills is quite challenging for young children.
We spent very little time talking about how training beyond level two would work except to suggest that the programmer – essentially playing the role of the curriculum learning protocol – would continue training its apprentice. Presumably it would continue to use the IDE to sample representative programs and focus on basic algorithmic motifs such as using a loop to iterate through a list performing the same computations on each item in the list.
There's no reason to believe that this would be any simpler than it is for the instructor in a beginner's programming class. In addition the programmer will have to deal with all the problems faced by a parent in facilitating a child in acquiring a first language. [Here might be a good place to discuss the consequences of an impoverished shared context – what linguists refer to as a common ground for shared understanding [67, 68] – necessary for taking advantage of a human grounding in the natural world sufficient to benefit from the many analogies and tropes used in explaining algorithms and data structures.
| |
| Figure 9: The above diagram features three separate representations of running code. The Lisp code on the left depicts an animation of a program running in the interpreter displaying the current expression being executed. The red arrow indicates the program counter and the two green arrows indicate the interpretable context. The variable assignments on the right illustrate an execution trace for the program running in the Lisp interpreter provided by the IDE debugger operating in single-step mode. Obviously both of these signals originate in the apprentice's "environment" as depicted in Figure 8. The graphic on the right represents a sequence of snapshots of the contents of all working-memory registers corresponding to the apprentice's attempt to interpret the running program. | |

What it Means to Understand Language
%%% Tue Feb 16 18:38:39 PST 2021
Riley DeHaan who is working with several other former students on putting together a syllabus for the class had an interesting question for Eve Clark following a Zoom meeting with Eve and the other students working on the syllabus. I forwarded Riley's message to Eve, she replied, and I forwarded Eve's message to Greg Wayne whose reply is also included:
RDH: The discussion with Eve today was great. One additional idea I should have mentioned that may be relevant as the curriculum continues to be developed would be asking for Eve's input on how children's comprehension of the world has been experimentally probed prior to their development of production. To me, this ability to test for knowledge prior to its expression in language may be critical for developing agents (particularly agents often stuck in a plateau of reflexive, model-free policies with little higher-level grounding or semantic understanding).While many of the kinds of probes in developmental psychology may revolve around testing intuitions of the physical world, I think there could be significant insight in the notion of comprehension preceding production and that some concrete experimental ideas in this area could be helpful for our comprehension of a programmer's apprentice (perhaps revolving more around theory of mind and abstract relations, although object permanence and other properties of generic objects and actions could also be relevant in the context of instructions, registers, ALU operations, etc.).
TLD: Thanks for the interesting and informative discussion this morning. Riley DeHaan had a question and an observation that I've included below. I think it is plausible that Liz Spelke and her students and colleagues might have conducted such studies in their work on the core knowledge theory, but I don't know that literature well enough to hazard a guess.
EVC: Not sure I know specific Spelke studies here, but I did some work long ago on what children did, from age 1 on, when asked to carry out instructions like PUT X IN / ON / UNDER / INSIDE Y. They all respond very readily but in fact do not yet understand any of the prepositions (IN, ON, UNDER and INSIDE). Rather they rely on what I called conceptual preferences: if X is a container, PUT X INSIDE Y ; if X is a supporting surface, PUT X ON Y – where containers always take priority over surfaces and any other locative configurations. These "rules" apply to other prepositions too.
In short, 1- to 3-year olds have extensive percept-based conceptual knowledge about certain locative relations, and they rely on this knowledge when faced with an evident request and given an object to place somewhere. They then start mapping the possible meanings of IN and ON first, and become able to place X on a box on its side, vs. IN the same box, say, but still rely on their early rules for dealing with UNDER. So this would be a case of initial conceptual/perceptual knowledge with out any semantic knowledge, that is gradually leveraged with the addition of the meanings of IN and ON, then, later, with UNDER as well.
GRW: It's definitely data dependent. For tables, you can put something 'on' or 'under', so it is sensitive to this. But you can also write "put ball bed", and the agent ignores the malformed sentence and carries on blithely. Over the weekend, I will try to experiment with this and get you some numbers.
Miscellaneous Loose Ends: Richard Feynman, the theoretical physicist who received the Nobel prize in 1965 for his work developing quantum electrodynamics, once famously said "What I cannot create, I do not understand". The quote was written on his blackboard at the time of his death in 1988. Feynman's quote seems to me a good reason for taking seriously the challenge implicit in goals of the Interactive Agents Group and the Abramson et al paper.
We don't fully understand how to accomplish any of the component skills necessary for meeting this challenge. However, there is some reason – evident in the Abramson et al paper – to believe that when we situate those skills in the context of an end to end task and draw upon what we have learned from developmental psychology, some of the problems that seem intractable when separated from that context will suddenly resolve themselves by exploiting that context.
February 14, 2021
%%% Sun Feb 14 04:38:42 PST 2021
Here is a first pass at a research plan with deliverables for guiding the student teams working on the language acquisition class project – note that the footnotes provide additional detail:
Look for an image of a child talking to a parent for a slide illustrating joint attention, common ground, self-initiated repairs, etc. Use this illustration to accompany a list of information-sharing channels used by the language learner and interlocutor45.
Create a rough time line showing the developmental stages and using arrows to illustrate the dependencies between stages. The idea is to use this graphic to characterize embeddings and transformations that represent words, concepts and their relationships46.
Enumerate the processes and their associated networks responsible for carrying out the computations required in carrying out language-related exploratory actions, self-initiated-repairs, communicative acts, interpretive and integrative inference, etc47.
Use the results from the above efforts to align the research topics with neural network technologies and papers that attempt to solve, explain, apply or otherwise explore the topics in papers accepted to ICLR, NIPS, and related neural network venues48.
The above is just a suggestion to get you started. I expect the students to modify the plan (with supervision and guidance from the teaching staff and class consultants) and self organize themselves by dividing the effort among smaller more tractable subgroups and coordinating the activities of the separate efforts. Since the Abramson et al [2] paper is our prime inspiration for the overall effort I suggest you look at Section 6 listing the 24 contributors to this paper along with short descriptions of their individual contributions and noting that Greg Wayne and Tim Lillicrap are the corresponding authors. If successful in this project, I would suggest we write an arXiv paper summarizing what we learned. Writing such a paper has precedent in this course – for example see the articles produced by the 2013, 2019 and 2019 classes [73, 76, 77].
Miscellaneous Loose Ends: The curriculum rolls out in stages. The order of the stages is important and there are dependencies between them. It is possible for the agent to appear ready to advance and yet have deficits potentially leading to problems appearing in a later stage. It is important for the curriculum algorithm to be prepared to recognize such deficits and roll back the curriculum one or more stages to engage in remedial training. Ideally this would not require completely repeating the problematic stage, but rather only the necessary lesson to simply correct a bug in a specific procedure or skill.
There are likely to be cases in which it is not practical to rely upon reinforcement learning since the rewards are too sparse to make timely progress and random search is likely to be ineffectual given the size of the underlying state space – see mention of the performance difference lemma on page 4 of Abramson et al [2]. In this case it might be necessary to employ some form of supervised imitative learning requiring labeled training data. The danger is not having enough data to support generalization and so some means of error correction may be essential to avoid catastrophic failure.
February 12, 2021
%%% Fri Feb 12 05:45:10 PST 2021
This entry includes two messages to Eve Clark concerning her participation in class this year. The two messages concern how best to take advantage of our respective strengths – Eve's research on the acquisition of language in young children and our collective expertise in machine learning and artificial intelligence. Before I get to those messages I wanted to share a minor epiphany concerning several philosophical conundrums related to consciousness, groundedness and the neural correlates of meaning that I experienced when falling asleep last night.
First I want to distinguish between use of the term grounding in the literature on embodied language and its use in explaining how children acquire language [68]. The former refers to sensorimotor mapping between entities and relationships and their referents [185]. The term common ground refers to grounding shared through interaction with parents, siblings, teachers and other contacts [67].
After reading some of our recent discussions about meaning and grounding, one of my students asked what it would mean for the words that we utter to be grounded. I was reminded of past discussions when the issue of consciousness came up in class and students encounter the inevitable philosophical question about qualia: What does it mean to see red? Attempting to demystify the question by characterizing how people respond to the question as an emergent phenomena, typically does not satisfy their curiosity.
At the time I didn't have a good answer to the question about embodiment, grounding and meaning, but having given it some thought I think I can provide a satisfying answer to a computer scientist knowledgeable about artificial neural networks and looking for a way of determining whether or not the utterances of a robot are grounded. Suppose that you could map the activity patterns arising in the language areas of the robot's neural network responsible for producing a specific utterance u back to circuits whose weights were largely determined when the robot learned to perform a particular physical task t. In this case, we say that u is grounded in t.
If those circuits that retain vestigial traces of learning the task t become activated and can be causally linked to the production of another utterance u′, then we might expect that u could be structurally mapped to u′ as in Dedre Gentner's theory of analogy [109]. It is relatively easy to imagine that the circuits that come into play when an infant is experimenting with movement and exploring its environment could provide an inductive bias in the form of a template dynamical system model upon which all subsequent such models are patterned even as that original template is modified and refined to account for the maturing infant's muscular and skeletal growth.
%%% Thu Feb 11 15:07:53 PST 2021
I took some time this morning to think about how the students can benefit from discussions with you in working on the class project that I have in mind, and, reciprocally, you can learn something interesting working them as they attempt to use your insights in designing a neural network architecture for the programmer's apprentice exercise.
In your 2002 paper entitled "Grounding and attention in language acquisition" and your 2016 book you roughly outline an extended training protocol spanning multiple years for acquiring language, emphasizing the role of grounding and stressing the point that language is a product of social interaction.
Your protocol describes the evolving cognitive state of the child along with his or her physical interaction with the environment and interlocutionary interaction with parents, educators and contemporaries. It also describes the illocutionary and perlocutionary speech acts with the antecedent rationale of the speaker and intended consequent effects on the listener.
We can offer a range of machine learning tools to build agents that are capable of learning to perform complex tasks that require interaction with other agents. In an effort to connect with the terminology of cognitive science and developmental linguistics it might help to compile a cross-disciplinary mapping of basic terms. For example, psychologists often use the terms "behavioral milestone" and "developmental stage" which for us might translate into steps in a multi-stage learning protocol.
The term curriculum as used by educators corresponds to a concept in machine learning of the same name that refers to a procedure for training an artificial neural network that proceeds in steps, where each step may involve adjustments in the learning algorithm, the distribution of samples in the training data, the objective functions, and the subset of weights in the network being modified in the case of strategies that fix some weights while allowing others to change.
There are many learning algorithms as well as many strategies for applying them in practice, for example, the term annealing refers to a method whereby the size of the weight adjustments is allowed to wax and wane in a manner analogous to the blacksmith's method for tempering steel. You might think of this as periodically returning to earlier stages in a curriculum to refresh, or apply in a new context, a lesson that was learned in the earlier stage.
The terms "innate" or "instinctive" as used in a biological context might be realized as an inductive bias or prior in statistical machine learning. Imitative learning might take the form of supervised learning along with a strategy for identifying potentially useful behaviors and then attempting to imitate them.
Some of the capabilities you mention in your book, we have algorithms to simulate, for example, we have reinforcement learning algorithms to reward agents for performing an action important to a successful outcome even when a significant amount of time has elapsed between performing the action and observing the successful outcome.
It might be more difficult to recognize when an agent has failed to learn a lesson in an earlier stage of a curriculum when there is no obvious observable manifestation of that failure, for example, when determining failure requires a causal chain of commonsense reasoning beyond the capacity of current technology.
What is referred to as commonsense reasoning in artificial intelligence – and generally agrees with its vernacular meaning – is widely believed to be well beyond the reach of the current state of the art, with implications for AI systems handling analogical reasoning any time soon. It seems clear to me from reading your work and a recent popular science book by Barbara Tversky [233] that grounding and embodiment hold important clues to understanding analogical and commonsense reasoning.
%%% Thu Feb 11 06:11:15 PST 2021
Your paper on conversational repair really speaks to my view on building agents like the programmer's apprentice that have to learn how to work with humans to pursue projects requiring both interactive skills and shared – unequally in the case of the apprentice – technical knowledge. I started marking up your text to highlight content for students taking the class and had to stop myself there were so many insights and relevant passages. I will definitely make it required reading for the project mentioned in my earlier email.
While at Google I wrote an internal white paper on dialog management for the Google Assistant49. It was titled "Interaction and Negotiation in Learning and Understanding Dialog" and featured sections on "Collaborative Language Understanding" with subheadings like "Hierarchical Task Networks for Dialog" and "Error Mitigation and Recovery" and a related appendix: "Appendix A. Collaborative Understanding". The system I described was built on a hierarchical planning system50 that could set error-mitigation goals which were expanded into subgoals and eventually into primitive tasks for producing speech acts to identify and repair problems. The RavenClaw framework developed at CMU system pioneered this approach to grounding and error handling in dialogue management systems51.
February 8, 2021
%%% Mon Feb 7 17:50:26 PST 2021
The abstract draft I wrote a couple of weeks ago needs amending to account for the new perspective we talked about yesterday, but the main idea of implementing a cognitive version the Merel et al [177] motor hierarchy still stands, we are just revising the cognitive task focusing on program interpretation and making the case that search in writing novel computer programs is much harder than search in generating novel movement trajectories.
We are also making the case that while natural language plays a key role in teaching and disseminating procedural knowledge including the art of programming, high-level programming languages provide a similar role for those who learn to interpret them. Instead of starting with natural language as the lingua franca52 for programmers communicating algorithmic knowledge to non-programmers, we advocate high-level programming languages as the lingua franca for programmers communicating such knowledge to machines.
I can't remember how Yash worded it, but, as I recall his comment, one of the contributions of this work is a system that can learn to read and interpret programs written in a high-level functional programming language thereby opening the possibility of training its fully differentiable distributed neural circuitry to take full advantage of its working memory and extend its repertoire of subnetworks – the agreed upon term to refer to computational resources such as the comparator that we previously referred to as a "subroutine" – that operate on additional data types, implemented as embedding spaces.
In principle, this approach solves the "language problem" in the sense that we now can "teach" the system by giving it programs to interpret – think of these programs as recipes (or algorithmic stories as I was referring to them in the slides I circulated a couple of weeks ago). It also provides a relatively simple approach for expanding its repertoire of data types and related operations. Borrowing a concept from discrete mathematics, any collection of entities representing a data type that satisfies the axioms for a ring53 can be interpreted by a program originally written for integers if you overload the operators, + , · and train the relevant networks to support the new data type.
| |
| Figure 11: The above graphic represents a modified version of the diagram shown in Box 2 of Merel et al [177] depicting an abstraction of the hierarchical anatomy of the mammalian nervous system intended to represent a consensus view of previous hierarchical interpretations. The diagram shown here accompanies the description in the main text of my interpretation / rational reconstruction of the three-level cognitive hierarchy that we discussed on Sunday. | |
|
|

The following describes each of the three levels in the hiearchical model rendered in Figure 11 a version of which was discussed in the February 7 group meeting:
L1 – from a biological perspective54 this is analogous to the spinal cord and peripheral nervous system including its sensory afferents and motor efferents; from a computer architecture perspective it corresponds to the arithmetic and logic unit55 (ALU) in a von Neumman architecture; in keeping with its ALU role, it learns to interpret machine microcode for a register machine target and maintains the functional instantiation of the program / instruction counter;
L2 – from a biological perspective this is analogous to the brain stem, cerebellum and basal ganglia along with the modulatory dopaminergic pathways relying on D1 and D2 dopamine receptors in the substantia nigra; from a computer systems perspective, it learns to execute the compiled built-in low-level programming language primitives providing a level of abstraction conceptually situated somewhere between assembly language56 and microcode instructions;
L3 – from a biological perspective this is analogous to the frontal cortex including both prefrontal and motor cortex along with modulatory regulation by the catecholamine transmitters norepinephrine and dopamine originating in the limbic system; it learns to interpret programs in the programming language whose primitives57 are now encoded in L2;
February 5, 2021
%%% Thu Feb 5 04:37:40 PST 2021
During the last week I've focused primarily on reading and thinking about the imitative interactive intelligence paper [2] from the Interactive Agents Group at DeepMind. In particular, I've been thinking about an exercise for CS379C that involves applying lessons learned from Abramson et al [2] to the programmer's apprentice. The intent is not to think about detailed architectures, but rather to examine how techniques for collecting the necessary dataset and employing similar strategies for training the model might translate to the apprentice application. Along the way, I have gathered insight from three Stanford professors: Jay McClelland in the Psychology Department, Andrew Huberman in the Department of Neurobiology at the Stanford University School of Medicine, and Eve Clark the Richard Lyman Professor in the Humanities and Professor of Linguistics in the Department of Linguistics.
Jay told me about Eve Clark's work on how children learn language. Her book entitled First Language Acquisition is now in its third edition and is available in digital format for Stanford Students from the Stanford Libraries website. I found Clark's public lecture entitled "Meaning for Language" on her research sponsored by Bing Nursery School to be helpful in expanding my understanding of just how complicated it is to acquire language. I doubt very much that I would have thought so three years ago. My appreciation for the complexity of acquiring language and using it effectively even in the most mundane of conversations has grown enormously in the last few years due in large part to the research of developmental psychologists like Liz Spelke and her colleagues on childen's acquisition of core knowledge [228, 227, 126].
In discussing the work from the DeepMind Interactive Agents Group, Jay and I talked about the complexity of everyday discourse in which we are constantly probing one another to determine if we are being understood, using gestures and body language to signal our understanding or inability to understand what our interlocutor is saying, while all the time making adjustments in what we say and how we say it in order to accommodate what we infer about the other's knowledge, level of education, etc. In a white paper [72] that I wrote while working on an early version of Google Assistant, I explored the role of interaction and negotiation as an essential component of natural language understanding in dialogue and developed a simple application demonstrating the basic functions of such a system. However, incorporating those ideas into a scalable production system was well beyond anything that was possible at the time, and the first versions of the assistant were able finesse the finer points of conversation by cleverly engineering the user interface employing a large database of question-answer pairs and thereby ensuring the assistant could answer the most commonly asked questions with almost perfect recall58.
Clark's research provides insight into the role of attention in how a child grounds its understanding in the physical world and in particular its home environment during the child's early development. Her 2001 paper [66] entitled "Grounding and Attention in Language Acquisition" focuses on exactly this problem59 . In my conversation with Jay, we briefly touched on theory-of-mind issues and the complexity of judging what someone else knows by using their perceived socioeconomic status, level of education and, in the case of children, stage of development, plus both the narrow context of the conversation so far and the larger context of your familiarity with the person and an appropriate shared cohort of family, friends, coworkers and business associates. Thinking about these issues led me to return to our interest in episodic memory and how such memories are formed, consolidated during sleep and subsequently activated and reconsolidated.
Andrew Huberman's expertise is in the areas of brain development, brain plasticity, and neural regeneration and repair. He has a podcast targeting the general public that focuses on how the brain and its connections with the organs of our body controls our perceptions, our behaviors, and our health. In a recent episode he focuses on dreaming and in particular the role of rapid eye movement (REM) sleep and non-REM (NREM) sleep also referred to as slow wave sleep (SWS). He talked briefly about hippocampal replay and the consolidation of recent memories suggesting that during SWS the brain attempts to find relationships between recently encoded memory representations and existing memories so as to identify useful memories and discard those that aren't useful. You can find a searchable transcript of the Huberman podcast here60 and two research papers I found particularly interesting in my literature search here61.
Miscellaneous Loose Ends: You can find relevant access-controlled excerpts from Eve Clark's First Language Acquisition here – use the same password and username as provided in the first class lecture. I've also included an excerpt from Clark's [66] paper entitled "Grounding and attention in language acquisition" that you can access here and may find useful in thinking about the Abramson et al [2] paper on imitative interacting intelligence. Think about writing a dialogue manager along the lines of the system mentioned earlier implementing the curriculum implicit in the linked excerpts.
In my conversation with Jay McClelland about natural language acquisition, we talked briefly about the relationship between analogy and the reality of effectively using language. The excerpt from [66] alludes to this connection, as well as underscores the challenges faced by children in acquiring language – challenges that human children appear to be uniquely well adapted to overcome. If the reference to Huberman's podcast piques your interest in the role of sleep in memory consolidation, you might be interested in this class discussion focusing on Matthew Walker's sleep research.
January 27, 2021
%%% Wed Jan 27 05:13:12 PST 2021
I've been thinking about the syllabus for CS379C in the Spring quarter. Specifically, I'm trying to nail down the content and relate it to interesting and yet tractable final projects. As an exercise, I divided the space of possible topics / projects into four categories, and for each category I provided two examples of papers that illustrate the sort of content and projects I have in mind. I considered a category for meta reasoning about scientific goals but decided against it; read this footnote62 if the topic piques your interest:
I. technologies, e.g, vector-quantized variational autoencoders [234], language-conditioned63 graph networks [103]
II. problem descriptions, e.g., imitative interactive intelligence [2], interpretable program learning [96]
III. cognitive capacities, e.g, relational inductive bias [27], neural network analogical reasoning [69]
IV. functional substrates, e.g., distributed cell assemblies [203], global neuronal workspace theory [175]
There are a number of recent papers on promising new technologies that we have considered and experimented with in the current project with Yash, Gene and Chaofei on differentiable register machines. For example, we've explored vector-quantized variational autoencoders for latent discrete distributed embedding spaces [234], new applications that require the extension / refinement of Transformers and BERT style attentional stacks [255], and solutions to problems that seem at first blush ideal for differentiable neural computers but prove difficult to implement using LSTM or DNC models.
In addition, there have been a number of very interesting inspirational / aspirational papers that suggest potentially tractable approaches to solving problems that have previously beyond our reach. The DeepMind paper entitled "Imitating Interactive Intelligence" is particularly noteworthy for the fact that it attempts to simultaneously tackle the problems of language acquisition, complex interaction with human agents, and common sense reasoning through grounded communication and shared experience of the physical world [2]. The DreamCoder paper [96] is also an interesting paper both for the problems it handily solves and those it finesses with human intervention.
Regarding the Abramson et al paper, I am emboldened to pursue my current side interest in using analogy as an alternative to conventional search in automated code synthesis. I don't envision these latter applications being practical choices for final projects that involve writing code, however, I can easily imagine a project analyzing the methodology described in Abramson et al for collecting a large dataset using Amazon's Mechanical Turk crowd-sourcing marketplace sufficient for training the complex language-based interaction and developmental learning required in that paper. See here for a series of three videos from DeepMind demonstrating imitative interactive intelligence.
In an earlier entry in this log, I made a case for analogical reasoning to replace or more likely to complement traditional search methods. My effort arguing for the potential of such a move notwithstanding, I don't pretend to understand how to do this. If anything, the exercise gave me a deeper appreciation of the considerable challenge we face in attempting build and train systems that match or exceed human analogical reasoning. However, I can imagine a final project (presumably not a project promising a working model) evaluating existing technologies that might play a role in modeling human analogical reasoning, e.g., work on interaction networks [28], relational inductive bias [27], imagination-based reasoning [121], natural language processing applied to code synthesis [224] etc, and addressing the problem of training by considering how the methods of Abramson et al [2] might be applied in the case of analogy.
A good deal of the research that we did last summer with Yash et al and the summer before with Chaofei Fan, Gene Lewis and Meg Sano focused on the extensive reciprocal white matter tracts linking disparate cortical regions featured in Joaquín Fuster's hierarchy [106, 41] and how both the cerebral and cerebellar cortex contribute to higher-level cognitive activities, but while we briefly looked at Donald Hebb's concept of a cell assembly (CA) [129], we spent hardly any time reading the literature on how cell assemblies are coordinated to support complicated computations. The register machine architecture we have been working on attempts to solve a similar problem but on a smaller scale and it would interesting to investigate the possible connections – see here for related work.
I think you'll find there remains a good deal of mystery surrounding the existence and function of cell assemblies. More the latter than the former, as there seems to be a consensus that something like CAs exist but differences in opinion about what specific functions they serve [175]. Given the claim they are widely distributed throughout the cortex, and in some cases specialized subcortical regions, how are they related to other circuits such as those associated with working memory [14] believed to reside in some of the same areas that CAs have been hypothesized to occupy or collocate [50]? In particular, how does the CA network relate to the network of regions connected by white matter tracts spanning the neocortex [183, 117]? I've yet to find definitive answers to these questions, but recommend you take a look at Stanislas Dehaene's speculations in [84] regarding working memory and cell assemblies – see here for references.
January 24, 2021
%%% Sun Jan 24 17:54:58 PST 2021
TLD: I started this afternoon trying to distill some of Yash's notes into outline form, but gave up primarily because I don't know what we can accomplish in whatever time frame he has in mind. So instead I wrote an abstract describing what we hope to accomplish – written for this exercise as though we have already accomplished it, and motivating the challenge by contrasting it with the Merel et al [177] paper from which we drew inspiration:In this paper, we describe the implementation of a hierarchical neural programmer-interpreter [212] inspired by the hierarchical motor control system described in Merel et al [177]. We chose this architecture for its simplicity and generality and in order to contrast the application of motor control with that of algorithmic reasoning about programs. The task of learning to control articulated robots is made easier by the continuity of configuration space and the advantages of feedback and interpolation for error correction. The combinatorial space of simple stream processing programs [4] that we focus on in this work and the discrete nature of the objects, actions and consequences of failure in generating such programs make for a far less forgiving application domain. In addressing these challenges, we have had to develop new methods for efficiently searching program space, learning subroutines to reduce search and exploit hierarchy, and harnessing the power of differentiable neural network models that interface with conventional computing technology.YAS: Sounds good to me. I will use "instruction" from now on in place of "subroutine". I am tackling the problem where the transformer has access to all the contents of working memory and as a result doesn't need to use any instructions at all. We have had a few discussions on the slack channel but I think we still need to discuss it further. The abstract you sent looks really good.
TLD: Yeah, that's really interesting. I should have anticipated this. On the one hand, one might jump to the conclusion that it is a feature not a bug, but of course the problem is "How will it generalize?"
The solution suggested in the Yan et al [255] paper that I mentioned in an earlier message, addresses the problem by representing integers as binary numbers and then using an embedding trick similar to one I suggested months ago but subsequently abandoned:
Another essential component of algorithmic reasoning is representing and manipulating numbers. To achieve strong generalization, the employed number system must work over large ranges and generalize outside of its training domain (as it is intractable to train the network on all integers). In this work, we leverage binary numbers, as binary is a hierarchical representation that expands exponentially with the length of the bit string (e.g., 8-bit binary strings represent exponentially more data than 7-bit binary strings), thus making it possible to train and test on significantly larger number ranges compared to prior work. We demonstrate that the binary embeddings trained on down-stream tasks (e.g., addition, multiplication) lead to well-structured and interpretable representations with natural interpolation capabilities. (SOURCE)The method that I suggested earlier was simply to embed all the alphanumeric characters and use the embedding vectors instead of one-hots and some simple distance metric – or simply the dot product – for comparing the embedding vectors of two characters.
The advantage espoused when I initially made this suggestion was that this character-embedding approach would generalize to any pair of embedded entities represented in the same vector space – or at least it would work for a simple equality comparator. The problem was where to get training data to generate the embedding space ... it's not as though we have a huge corpus of input sequences along the lines of the default New York Times dataset for training word2vec models. Even, if we did, the position of a character in a "representative" input sequence does not convey any semantically useful contextual meaning. For the most part, the same could be said for the position of a character in a snapshot of working memory – however, I expect that the latter is not entirely true and there may be some value in using this signal, but it may also be the case that the transformer / VAE stack would exploit this advantage without our guidance.
Looking at the current behavior (as you described in your email) as a feature and eliminating the comparator function altogether has its advantages. The homunculus still has to move information around, i.e., read from and write to registers, and I would guess that moving operands to consistent locations in memory – currently designated as the input registers for the comparator function – would facilitate training the lowest (L1) layer – see mention of conditional masking in Yan et al. This would also address Gene's discomfort with having the comparator pre-programmed. By forcing the L1 layer to learn other arithmetic and bitwise functions, e.g., INCREMENT, DECREMENT, SHIFTLEFT, SHIFTRIGHT, etc, and execute them simply by writing to and reading from specified locations we would have all the basic functions of a traditional von Neumann arithmetic-logic unit [186] – strictly speaking, register machine automata do not require these instructions as they can be emulated by various instances of the general class of register machine with a few very simple instructions and still achieve Turing equivalence.
YAS: Sounds good to me. I will use "instruction" from now on in place of "subroutine". I am tackling the problem where the transformer has access to all the contents of working memory and as a result doesn't need to use any instructions at all. We have had a few discussions on the slack channel but I think we still need to discuss it further. The abstract you sent looks really good. Both the abstract and introduction drafts were meant to be temporary placeholders to start a discussion. I fully expect them to completely change as we discuss further and get more results from our experiments.
TLD: I saw your post on the bugfix. That's excellent. Don't know exactly what you mean by "coming up with the instruction set to use", but see my earlier email (now in the 2021 class discussion list / preparatory notes here ) relating your discussion with Chaofei about subroutines. I would also like to follow up with you tomorrow in the SAIRG meeting on the abstract I sent around yesterday and the comments I made regarding your earlier posts asking for feedback on your draft.
YAS: I have fixed the bug. I have been coming up with the instruction set to use. I have updates on the slack channel. My potential solution is that instead of passing the entire memory matrix to the transformer, we modify the matrix so the only information available is whether the register has an element in it or not.
TLD: Does the "learned conditional masking mechanism" described in the Yan et al [255] "Neural Execution Engines" paper offer any insight about or alternative for handling the issues you mentioned last Sunday?
Miscellaneous Loose Ends: Interesting analysis, examples and approaches to embedding programs combining syntax from source code and semantics from execution traces [239, 242] and related work on extending language-based embedding-vector techniques to program embedding [10]. The following is relevant to our interest in analogy and its relationship to extelligence in the form of human culture encoded in stories and other language based media that was recently featured on Analogy List seminar – there is an accompanying preprint entitled "Analogy as Catalyst for Cumulative Cultural Evolution" [43]. This footnote64 provides an excellent example of how useful ideas are more easily spread using a language embedded in shared human experience.
Miscellaneous Loose Ends: Sent email to a group of students who took CS379C in 2019 and 2020 soliciting their help in planning out the content and projects for CS379C in 2021, and asking for suggestions and volunteers to serve in as teaching assistant65. What I have in mind for the next couple of months is to find several students willing to meet with me once a week for approximately an hour to discuss topics, invited speakers and sample projects for 2021. If you are interested in joining us, please get in touch with me soonest.
In this entry in the 2019 discussion list you'll find a reference to Terrence Deacon's Symbolic Species including the PDF for this out-of-print book and a link to a short synopsis of Deacon's follow-up book Incomplete Nature. You might also find interesting Sean Carroll's "The Big Picture: On the Origins of Life, Meaning, and the Universe Itself" and Daniel Dennett's "From Bacteria to Bach and Back: The Evolution of Minds". This entry includes a link to a Sean Carroll podcast in which Carroll interviews Dennett who provides insightful answers drawing on his decades of work in both philosophy of mind and cognitive science.
January 21, 2021
%%% Thu Jan 21 13:20:19 PST 2021
Elsewhere I have argued that register transfers are the microcode instructions for the Register Machine, and so I would make this clear and stick to it throughout, perhaps shortening phrase to simply to the word "instruction" after its initial introduction. I admit to having used the word "subroutine" ambiguously at times, confusing comparators and related operators with the compiled sequences of L1 primitives that L2 uses to construct more complicated programs. In my last summary of the architecture using a modified version of Yash's diagram, I relabeled these operators as simply SUBNETWORKS, but that seems arbitrary and somewhat misleading. A register machine is basically an ALU comprised of registers and primitive functions including arithmetic operations, bitwise logical operations and bit shift operations.
For a number of reasons that would take too long to explain here, I would reserve the word "function" – with the explanation just given – for the class of low-level processing units of which our single comparator is the only instance we have introduced thus far. I would reserve the terms "primitive" and "subroutine" as I originally intended: the former used to refer to the primitive computational units performed in L1 – which happen to be microcode instructions, and the latter used to refer to the compiled sequences of L1 primitives that L2 uses to construct more complicated programs. This naming also accords well with the nomenclature in Merel et al [177].
In earlier discussions when considering more than two levels, I suggested that each level have both level-specific primitives and subroutines – the former provided by its subordinate level and the latter provided to its superordinate, but this would only complicate matters and lead to more confusion, and so I suggest for the paper we are contemplating, we simply restrict attention to two levels. There is a larger, neuro-architectural question related to subroutine-like neural circuitry and an accompanying argument that the term should be reserved for functions corresponding to cortical circuitry – though not necessarily confined to just the frontal cortex. These functions are essentially what Hebb and Braitenberg called cell-assemblies [192, 53, 42, 129]. However we clearly have a paucity of such subroutines in the model as it stands, and a lengthy discussion has no place in the sort of paper we have been talking about66.
January 17, 2021
%%% Sun Jan 17 04:40:20 PST 2021
This log entry consists of my preparatory notes for a talk that I gave on January 15, 2021 in the Friday seminar series sponsored by the Stanford psychology department – the title and abstract are provided below67. The full talk includes an overview of the material chronicled in the appendix to the 2020 class discusion notes; this material is not replicated here. Organization in these notes is lacking as they were generated primarily for the purpose of collecting my thoughts in one place for future reference when I start preparing lectures for class in the Spring.
Papers Cited in the Preliminary Lecture
ASPIRATIONAL PAPERS FOR SPRING
[177] HIERARCHICAL MOTOR CONTROL IN MAMMALS AND MACHINES
[96] DreamCoder: GENERALIZABLE, INTERPRETABLE KNOWLEDGE
[2] IMITATING INTERACTIVE INTELLIGENCE
[40] JOHN HUGHLINGS JACKSON
NEURAL PROGRAMMER-INTERPRETERS
[199] LEARNING NEURAL PROGRAMS WITH RECURSIVE TREE SEARCH
[212] ORIGINAL NEURAL PROGRAMMER-INTERPRETER PAPER
NEURAL CORRELATES OF LANGUAGE
[61] AN INTRODUCTION TO HOW MONKEYS SEE THE WORLD
[196] EVIDENCE FOR THE ONTOGENY OF LANGUAGE
[197] LANGUAGE RHYTHMS IN BABY HAND MOVEMENTS
[201] TOWARDS A NEW NEUROBIOLOGY OF LANGUAGE
[204] BRAIN MECHANISMS FOR EMBODIED ABSTRACT SEMANTICS
[205] REUSING ACTION / PERCEPTION CIRCUITS FOR LANGUAGE
ANALOGY AND METAPHOR
[97] ALGORITHMS FOR THE STRUCTURE-MAPPING ENGINE
[109] STRUCTURE-MAPPING: A THEORETICAL FRAMEWORK FOR ANALOGY
[69] NEURAL ANALOGICAL STRUCTURE MATCHING NETWORKS
[112] SCHEMA INDUCTION AND ANALOGICAL TRANSFER
[219] PATH-MAPPING THEORY: ANALOGICAL MAPPING
[143] MODELLING THE MAPPING MECHANISM IN METAPHORS
[140] ANALOGY AND RELATIONAL REASONING SURVEY
[172] REENTRANT PROCESSING AND INTUITIVE PERCEPTION
GRAPH AND INTERACTION NETWORKS
[26] INTERACTION NETWORKS LEARN RELATIONS / PHYSICS
[27] RELATIONAL INDUCTIVE BIASES AND GRAPH NETWORKS
[147] GATED GRAPH TRANSFORMER NEURAL NETWORKS
[166] GATED GRAPH SEQUENCE NEURAL NETWORKS
[101] SCALABLE INCEPTION GRAPH NEURAL NETWORKS
[8] LEARNING TO REPRESENT PROGRAMS WITH GRAPHS
[167] DEEP GENERATIVE MODELS OF GRAPHS
[252] SURVEY ON GRAPH NEURAL NETWORKS
[241] DYNAMIC NEURAL PROGRAM EMBEDDINGS FOR PROGRAM REPAIR
Neural Programming, Analogy and Search
%%% Tue Jan 12 19:26:36 PST 2021
MCTS (Monte Carlo Tree Search) and IBP (Imagination-Based Planning) are only as good as their next move evaluator / selector. Combinatorial space of programs is huge, search at the individual expression level is unintuitive ... we need structure. Good programmers easily move back and forth between levels of abstractions to control search and reshape the context. Keeping track of where you are in search space doesn't mean you don't repeat strategies – you change the search space
Typically we make big leaps and then clean up the mess, essentially making code substitutions followed by program repair. We suggest a variant: searching for and applying analogies between current program descriptions and algorithmic stories. An algorithmic story is an embedding of a description such as the one describing how the soldiers re-order their column Useful algorithmic stories evolve, for example, it is a small step to imagine a parallel version of the soldiers story. Research in applying neural networks to code synthesis has benefited enormously from the development of technologies for. Solving natural language processing problems including document summarization, sentiment analysis, question answering, language translation, etc.
Industrial strength tools for code completion such as Google's Deep TabNine leverage power of generating vector space embeddings or large corpora – billions of lines of commented code – to contextualize search. Graph networks, interaction networks, gated graph transformer neural networks are but a few of the tools we have for representing and reasoning about a wide range of complex dynamical systems often with meaningful alignment of relevant attributes for supporting simple but effective variable binding. The same technologies have been applied to represent and answer questions about simple stories and are rapidly being improved given the huge increase in interest and talent.
| |
| Figure 12: Much of the knowledge required to exploit extelligence68 is hidden in our experience of the world we share with other humans – we say it is grounded69 in the physical world. This hidden knowledge is implicit in the stories we tell our children because we can depend on our children having much the same experiences that we have had. It forms the basis of what we refer to as common sense reasoning. It plays a crucial role in making analogies because it is this knowledge that enables us to identify and anticipate problems with a proposed analogical mapping between stories and consider the possibility of relaxing or eliminating some of the constraints thereby generating new analogies. | |
|
|

| |
| Figure 13: The recognition of some sort of inner monologue as a core component in cognition is often credited to Lev Vygotsky [213]. There are many hypotheses concerning the precise function of this phenomenon. Hofstadter describes it as a sequence of mental shifts between levels in a hierarchy that eventually ends up back where it started. Each shift feels like an upwards movement, and yet the successive 'upward' shifts give rise to a closed cycle" [139]. Consider inner speech as a constructive process in which an agent – call her Alice – hears a story and generates an internal representation of the story from her subjective point of view. Essentially Alice encodes the story using a combination of her interpretation of the words in the story as she read it and the context in which she heard it. By context we mean the perceptual, conceptual and procedural information encoded in working memory and corresponding to Alice's current "state of mind". This process is recurrent and, in our case, goal driven. Alice then retells the story, decoding her internal representation of the story in her own words and in keeping with the new context informed by having ingested the original story. The process continues with the words of Alice's decoding now serving in the role of the original story and Alice hearing herself read the decoded story. Note Alice need not actually hear or speak at all – via the dashed red line. She could have started out with one of her own stories. In this example, we assume Alice has the goal of understanding the story in order to apply it to solving a particular problem. In terms of using analogy as an aid in writing and understanding programs, we see this process as one of searching episodic memory for an algorithmic story starting with a story corresponding to a description of the current program or program fragment to be written or understood. See Figure 14 for a related approach. | |
|
|
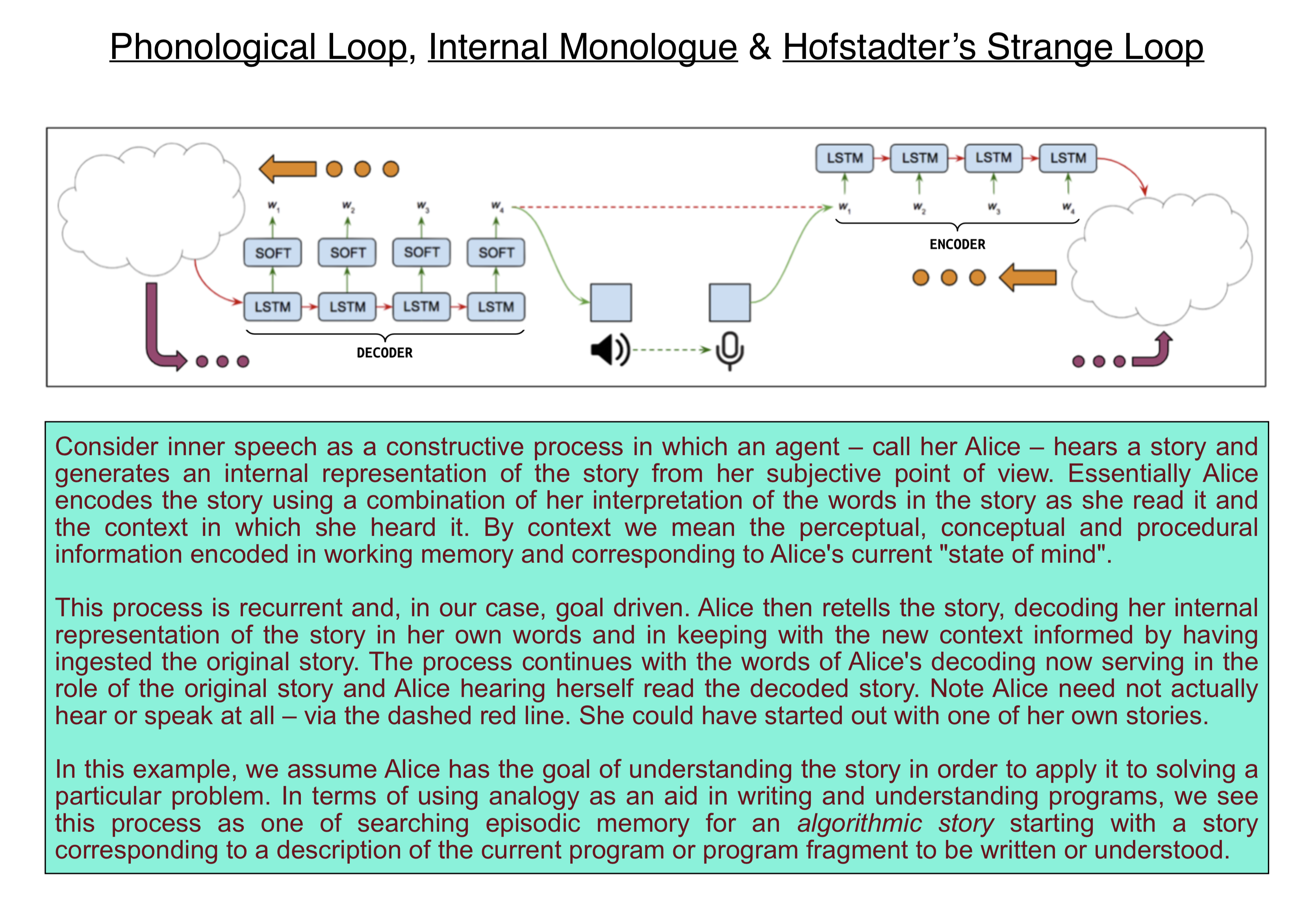
Miscellaneous Loose Ends: Common threads ... the idea of a constructive or reconstructive version phonological loop serving as the engine for analogical thinking / foundation for thinking deeply / efficiently / persistently ... see Figure 13 ... an inner discourse version of the Telephone Game also known in the west as Chinese Whispers and reentrant processing ... analogical thinking as a core capability – Hofstadter, Holyoak, Gentner, and many other cognitive scientists would say the core – for human intelligence and yet without access to the fruits of culture – but certainly not just technology, science and mathematics – we would still be in the stone age and we may yet return to the stone age if we precipitate cataclysmic climate change.
%%% Mon Jan 11 15:01:11 PST 2021
Complex Cognitive Workflow in Simple Networks
What is the "state" of a multi-layer perceptron (MLP)? For a specific input, an MLP produces a specific output and that is pretty much it. What about a convolutional network (CNN)? CNN’s utilize a kernel specifying a bank of filters of a given shape and overlap but otherwise are not significantly different from MLPs. How about a recurrent neural network (RNN)?
Mathematically an RNN is an instantiation of a differential equation that can be employed to produce a discrete-time series or continuous trajectory through the phase space for the dynamical system described by the equation. Unless explicitly introduced, there is no explicit notion of time aside from our interpretation of the points along that trajectory.
At different points, some variables change quickly while others slowly. In the case of artificial neural networks, these changes are due to special circuits that control the rate of change in other subcircuits of the network. For example, these special circuits can be used to control the timing of activity, persistently maintain state and isolate specific subcircuits from change.
If we think of electrical signals as responsible for defining the basic differential equation, we have to introduce ancillary functions to explain the sort of large scale changes in neural activity we observe in biological networks as a result of diffuse signaling with neurotransmitters and coordinated patterns of activity orchestrated by specific frequencies of spiking neurons.
It is convenient for us to think of the latter as controlling the topology of the network architecture by periodically taking some component networks offline to protect them from alteration, but this approach runs counter to our interest in building fully differentiable systems that can be trained end-to-end at scale using efficient techniques like stochastic gradient descent.
The problem of catastrophic interference/forgetting in transfer learning is one example of how error propagation can result in unwanted changes to the weights of subnetworks that we would prefer to be treated as essentially offline. Biological networks in which only a small fraction of neurons are active at any given time have, with few exceptions, no such problems.
The developers of DreamCoder [96] avoid this problem by breaking the problem into three separate computational steps that are repeatedly executed in carrying out DreamCoder’s algorithmic cycle, two of which involve making adjustments to the weights of separate neural networks.
| |
| Figure 14: Code summarization and code generation are important tasks in the field of automated software development and there have been a number of neural network-based proposals for solving these tasks independently. Borrowing an idea from natural language processing called dual task learning, Wei et al [245] demonstrate a method for solving these two tasks jointly – significantly improving performance on both tasks, by taking advantage of an intuitive correlation between code summarization and generation70 Their approach suggests a method whereby algorithmic stories might be aligned with program fragments that solve specific algorithmic problems by using an analogical reasoning strategy along the lines advocated in Gentner's structure-mapping theory [109, 97, 70, 69]. | |
|
|
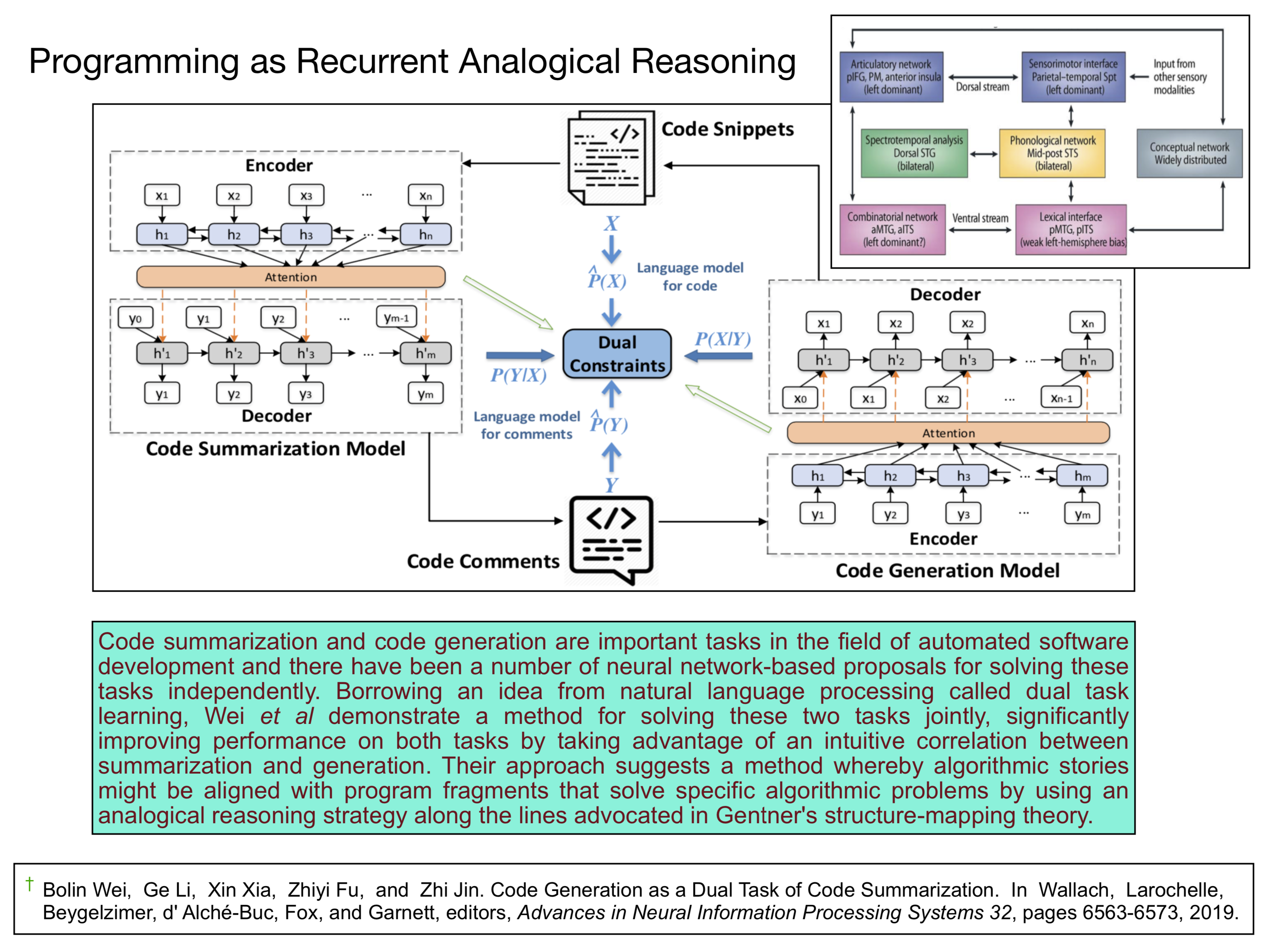
Representing and Reasoning about Analogies
My advisor at Yale, Drew McDermott, was famous among AI researchers in the 80’s and 90’s for his paper with the pithy title "Tarskian Semantics or No Representation Without Denotation". His main point was to discourage AI researchers from giving predicates names like PLAN and ACT in their predicate calculus theories of common-sense reasoning as it was misleading.
Distributed representations in biological and artificial neural networks encode meaning contextually. Entities that co-occur, whether words in language or entities in the physical world are likely to be related in meaningful ways, and to fully understand those relationships one has to explain their composite behavior.
The state of a dynamical system and its dynamics can be modeled as a graph and represented as a vector in a high dimensional vector in an embedding space. Two such embedding vectors could be used to highlight the differences between two dynamical systems. Transformer networks can be trained to simulate the behavior of dynamical systems so as to compare the properties of two separate systems.
We suggest here that these models could be used to assist in learning new models and a collection of such models could serve as the basis for making analogies that might facilitate applying existing knowledge of one dynamical system to understanding or modifying another.
Indeed we suggest that analogies – in a restricted sense – are essentially mappings between dynamical system models and (successfully) making an analogy is tantamount to identifying such a mapping. This isn’t a new idea. There is a long history of work along similar lines. What is missing, however, is how the brain carries out this process of analysis and how might we model that in an artificial neural network.
Figure 15
| |
| Figure 15: CAPTION GOES HERE | |
|
|

I've shared a copy of Joaquin Fuster's Prefrontal Cortex, 5th Edition with you and attached a copy of Chapter 8: An Overview of Prefrontal Functions. Note that Figure 8.3 on Page 384 and Section VI.B Functional Anatomy of the Perception-Action Cycle on Page 404 are particularly relevant to our recent discussions and nicely complement the treatment in O'Reilly et al Computational Cognitive Neuroscience, 4th Edition. This shared document is the most recent edition of Fuster's magnum opus on the prefrontal cortex and a long standing primary reference on the prefrontal cortex. The material on anatomy (Chapter 2) also includes a nice overview of the entire neocortex pointing out functionally relevant differences between humans and non-human primates, but it is dense and much of it irrelevant to our discussion.
Fuster's text is also the primary source for my hypothesis that apart from establishing the gross architecture of the human neocortex as largely determined by the cortico-cortical, cortico-thalamic and thalamico-cortical white matter tracts, the basic laminar and columnar cytoarchitectural features of the cortical columns that tile the cortical sheet suggest that an artificial neural network architecture might be constructed from a set of standard network components – such as transformer stacks – whose functional differences are largely determined by their learned weights, how they are connected to one another as indicated by the network of white-matter tracts, and the input from (afferents) and output to (efferents) specialized sensorimotor circuits in the peripheral nervous system.
I'm not completely confident in making such a claim and the literature on the role of the arcuate fasciculus in supporting the dual streams hypothesis and related circuits supporting inner speech might seem to argue that Broca's and Wernicke's areas and their respective locations in the frontal and temporal lobes deserve special treatment, but I'm not convinced and think that a simpler architecture will suffice with backpropagation sorting out the functionally relevant differences by adjusting the weights accordingly. I'd be interested to hear what conclusions you arrive at.
Discussion with Rahul and Rishabh
%%% Wed Jan 6 19:06:03 PST 2021
I'm working on a paper and thinking about including the following text as part of the introduction. The paper attempts to make the case that practical automated programming is impossible without search – there is no magic bullet to finding solutions to novel programming problems / no free lunch in generalizing beyond the training data.
However, it may be possible to tap into a rich source of programming insight hidden away in the analogies, metaphors and stories that programmers share with one another and that often end up in programming textbooks and offered as advice in online forums. Does this make sense? Is it obvious? Is it so far beyond what is feasible as to beggar the imagination? I'm fine with a frank answer of: "Not much sense!", "More like, 'Not interesting'!" and "This will take more than 'just' passing the Turing Test!":
Problems such as the programmer's apprentice [76] require search or, at the very least, a software engineer with enough patience to guide the apprentice at every stage in the process of developing software requiring a solution to novel programming challenges – novel, that is, in terms of the apprentice's limited experience.Heuristics can reduce the amount of search needed in some cases, but only marginally so in problems that have been demonstrated to require highly skilled personnel. Moreover, it is in solving the tricky parts where most of the time is spent and cognitive effort expended. Having to explain how to solve these parts to a language-challenged apprentice won't help matters.
Human programmers make use of analogy and metaphor in order to both communicate with one another and to teach programming to beginning students. They become adept at thinking about code in abstract terms and in using analogies to reconceptualize programming problems so that possible solution paths become apparent. The analogies, metaphors and algorithmic stories found in many introductory programming textbooks often stay with programmers for decades.
The ability to understand and apply analogies – whether directly relating to programming or acquired in learning other algorithmic skills such as cooking and mathematics – more often than not requires a degree of common sense reasoning typically acquired by children during early development and facilitated by grounding their understanding in the experience of interacting with other agents and objects solving everyday problems.
Recapitulating child development and grounding language in the experience of the world that we humans live in is not the only approach to harnessing AI technology to automate programming. High-speed computers in giant server farms combined with billions of lines of code in open-source and proprietary corporate software repositories hold out promise for automating a good deal of the drudge work for many programming applications, and industrial-strength code completion software promises to make software engineers more effective.
The point of this exercise is to imagine how an approach along the lines described in Abramson et al [2] might lend itself to building hybrid AI systems that directly interface with powerful digital prostheses of the sort mentioned in the previous paragraph and can collaborate with human programmers on some of the huge projects we anticipate necessary to deal with the challenges we face in the coming decade.
RAS: I agree that humans use analogies/metaphors/stories extensively in teaching -- not only for teaching concepts in programming but also in very different domains (e.g., martial arts). Maybe the analogy provides a useful scaffold that helps in transferring intuitions across domains; since it's an incomplete/partially-incorrect model it can be discarded when the student develops enough experience in the new domain. At an explicit level programming patterns (and anti-patterns) are obviously valuable but I think your intro is also alluding to programming fables or even zen koans. However, I had not made the connection to search.
Conversation with Alan Baddeley
Below is my reconstruction of an excerpt from a conversation with the psychologist Alan Baddeley, much of the content of which is included in his 2012 paper [17] appearing in Annual Review of Psychology in which he describes his research with Graham Hitch [18] on their original model of working memory and its extension to incorporate procedural memory. My hope is that this short preview will motivate you to watch the entire conversation as I think you will find it worth your while to listen to his account of how he and Hitch came up with the original theory and how Baddeley and his colleagues developed further during the ensuing decades:
A recent interesting development is the model of procedural working memory proposed by Klaus Oberauer71. To understand this model let's consider a concrete situation. Let's say that you are a subject in an experiment as part of a study about memory. You turn up for the experiment and you're given the following description of what is expected of you by the researcher running the study: when the red light comes on press the button next to your right hand, when the green light comes on press the button next to your left hand, and when both lights come on don't press any button at all. Following this description, the researcher immediately starts the experiment and you carry out the instructions.How do you manage to accomplish this? How do you remember the instructions and how do you carry them out? Subjects typically don't rehearse the instructions by reciting them outloud or to themselves – there simply isn't time. But it is as if you can compile a program that you can subsequently run several times allowing you to perform the task. I think we have lots of such temporary programs that are set up and run to achieve various tasks and I think it's plausible to regard these as a variety of working memory, but one that's different from conventional characterizations of working memory serving as temporary storage for information used by the executive system in performing performing cognitive tasks.
Words have meaning by virtue of their context, both the surrounding words in the text they are embedded and the larger context supplied by the cultural environment in which they arise. However just because the surrounding cultural environment includes detailed accounts of, say, how a computer or nuclear reactor works, it does not follow that we have access to the knowledge of how a computer or reactor works, nor the ability to make use of the underlying principles.
Applying the story of the soldiers arranging themselves in order of their height in order to follow the instructions of their drill sergeant to the problem of how the children might order their desks in the classroom in order to better see the black board at the front of the room seems simple to us because we are familiar with both of the situations and have no trouble substituting soldiers for students as part of the process usefully applying analogies.
The context supplied by the natural environment in which we live it's what Stuart and Cohen mean by the term extelligence. While our ambient extelligence is available to us in principle it requires a great deal of effort to internalize and apply to novel situations. The trick in making a useful analogy begins by identifying a suitable story, but the hard part is mapping the entities that figure prominently in the story to the target domain and reconciling the relevant physical principles that govern their behavior.
Mapping soldiers to students, positions in a brigade column to desks in a classroom, and blackboards to drill sergeants seems simple to most educated adults, but our familiarity with making such analogies masks the difficulty inherent in choosing what characteristics of the entities mentioned to ignore and what characteristics are essential to making the analogy work for whatever purpose they are being applied. The physical principles governing the two stories could be quite different and the analogy still work, but the intellectual effort required to perform this analysis is complicated and well beyond the scope of current AI systems.
A combination of naïve physics, common sense reasoning and physical (embodied) intuition, together with a broad repertoire of shootable stories is essential. The role of grounding our understanding of concepts in the physical experience of the rich environment in which we evolved is clearly important in terms of providing a foundation for imitation and exploration serving to bootstrap our understanding of dynamics guided by instinctual inductive bias and nascent structure in our developing brains.
References
| [1] |
Daniel A. Abolafia, Rishabh Singh, Manzil Zaheer, and Charles Sutton.
Towards modular algorithm induction.
CoRR, arXiv:2003.04227, 2020.
|
| [2] |
Josh Abramson, Arun Ahuja, Arthur Brussee, Federico Carnevale, Mary Cassin,
Stephen Clark, Andrew Dudzik, Petko Georgiev, Aurelia Guy, Tim Harley, Felix
Hill, Alden Hung, Zachary Kenton, Jessica Landon, Timothy Lillicrap, Kory
Mathewson, Alistair Muldal, Adam Santoro, Nikolay Savinov, Vikrant Varma,
Greg Wayne, Nathaniel Wong, Chen Yan, and Rui Zhu.
Imitating interactive intelligence.
CoRR, arXiv:2012.05672, 2020.
|
| [3] |
Tameem Adel, Zoubin Ghahramani, and Adrian Weller.
Discovering interpretable representations for both deep generative
and discriminative models.
In Jennifer Dy and Andreas Krause, editors, Proceedings of the
35th International Conference on Machine Learning, pages 50--59. PMLR, 2018.
|
| [4] |
Alfred V Aho, Brian W Kernighan, and Peter J Weinberger.
The AWK programming language.
Addison-Wesley Longman Publishing Co., Inc., 1987.
|
| [5] |
B. Alderson-Day, S. Weis, S. McCarthy-Jones, P. Moseley, D. Smailes, and
C. Fernyhough.
The brain's conversation with itself: neural substrates of
dialogic inner speech.
Social Cognitive Affective Neuroscience, 11(1):110--120, 2016.
|
| [6] |
Ben Alderson-Day and Charles Fernyhough.
Inner speech: Development, cognitive functions, phenomenology, and
neurobiology.
Psychological bulletin, 141:931--965, 2015.
|
| [7] |
Ben Alderson-Day, Simon McCarthy-Jones, and Charles Fernyhough.
Hearing voices in the resting brain: A review of intrinsic functional
connectivity research on auditory verbal hallucinations.
Neuroscience and Biobehavioral Reviews, 55:78--87, 2015.
|
| [8] |
Miltiadis Allamanis, Marc Brockschmidt, and Mahmoud Khademi.
Learning to represent programs with graphs.
In International Conference on Learning Representations, 2018.
|
| [9] |
Uri Alon, Omer Levy, and Eran Yahav.
code2seq: Generating sequences from structured representations of
code.
In International Conference on Learning Representations, 2019.
|
| [10] |
Uri Alon, Meital Zilberstein, Omer Levy, and Eran Yahav.
Code2vec: Learning distributed representations of code.
In Proceedings of the ACM on Programming Languages, volume 3,
New York, NY, USA, 2019. Association for Computing Machinery.
|
| [11] |
K. Amunts and K. Zilles.
Architectonic Mapping of the Human Brain beyond Brodmann.
Neuron, 88(6):1086--1107, 2015.
|
| [12] |
Marcin Andrychowicz, Filip Wolski, Alex Ray, Jonas Schneider, Rachel Fong,
Peter Welinder, Bob McGrew, Josh Tobin, Pieter Abbeel, and Wojciech Zaremba.
Hindsight experience replay.
CoRR, arXiv:1707.01495, 2017.
|
| [13] |
Frederico A.C. Azevedo, Ludmila R.B. Carvalho, Lea T. Grinberg,
José Marcelo Farfel, Renata E.L. Ferretti, Renata E.P. Leite,
Wilson Jacob Filho, Roberto Lent, and Suzana Herculano-Houzel.
Equal numbers of neuronal and nonneuronal cells make the human brain
an isometrically scaled-up primate brain.
The Journal of Comparative Neurology, 513(5):532--541, 2009.
|
| [14] |
Bernard Baars, Stan Franklin, and Thomas Ramsy.
Global workspace dynamics: Cortical "binding and propagation" enables
conscious contents.
Frontiers in Psychology, 4:200, 2013.
|
| [15] |
A. Baddeley, S. Gathercole, and C. Papagno.
The phonological loop as a language learning device.
Psychological Review, 105(1):158--173, 1998.
|
| [16] |
A. Baddeley, S. Gathercole, and C. Papagno.
The phonological loop as a language learning device.
Psychol Rev, 105(1):158--173, 1998.
|
| [17] |
Alan Baddeley.
Working memory: Theories, models, and controversies.
Annual Review of Psychology, 63(1):1--29, 2012.
|
| [18] |
Alan Baddeley and Graham James Hitch.
Working memory.
In G.A. Bower, editor, Recent Advances in Learning and
Motivation, volume 8, pages 47--90. Academic Press, 1974.
|
| [19] |
D. Badre and A. D. Wagner.
Selection, integration, and conflict monitoring; assessing the nature
and generality of prefrontal cognitive control mechanisms.
Neuron, 41(3):473--487, 2004.
|
| [20] |
David Badre.
Cognitive control, hierarchy, and the rostro-caudal organization of
the frontal lobes.
Trends in Cognitive Sciences, 12(5):193--200, 2008.
|
| [21] |
David Badre and Derek Evan Nee.
Frontal cortex and the hierarchical control of behavior.
Trends in Cognitive Sciences, 22(2):170--188, 2018.
|
| [22] |
Matej Balog, Alexander L. Gaunt, Marc Brockschmidt, Sebastian Nowozin, and
Daniel Tarlow.
Deepcoder: Learning to write programs.
In International Conference on Learning Representations, 2017.
|
| [23] |
Matej Balog, Rishabh Singh, Petros Maniatis, and Charles Sutton.
Neural program synthesis with a differentiable fixer.
CoRR, arXiv:2006.10924, 2020.
|
| [24] |
Andrea Banino, Adrià Puigdomènech Badia, Raphael Köster, Martin J.
Chadwick, Vinícius Flores Zambaldi, Demis Hassabis, Caswell Barry,
Matthew M Botvinick, Dharshan Kumaran, and Charles Blundell.
Memo: A deep network for flexible combination of episodic memories.
CoRR, arXiv:2001.10913, 2020.
|
| [25] |
Kenneth Basye, Thomas Dean, and Leslie Kaelbling.
Learning dynamics: System identification for perceptually
challenged agents.
Artificial Intelligence, 72:139--171, 1995.
|
| [26] |
Peter Battaglia, Razvan Pascanu, Matthew Lai, Danilo Jimenez Rezende, and Koray
Kavukcuoglu.
Interaction networks for learning about objects, relations and
physics.
In Proceedings of the 30th International Conference on Neural
Information Processing Systems, pages 4509--4517. Curran Associates Inc.,
2016.
|
| [27] |
Peter W. Battaglia, Jessica B. Hamrick, Victor Bapst, Alvaro Sanchez-Gonzalez,
Vinicius Zambaldi, Mateusz Malinowski, Andrea Tacchetti, David Raposo, Adam
Santoro, Ryan Faulkner, Caglar Gulcehre, Francis Song, Andrew Ballard, Justin
Gilmer, George Dahl, Ashish Vaswani, Kelsey Allen, Charles Nash, Victoria
Langston, Chris Dyer, Nicolas Heess, Daan Wierstra, Pushmeet Kohli, Matt
Botvinick, Oriol Vinyals, Yujia Li, and Razvan Pascanu.
Relational inductive biases, deep learning, and graph networks.
CoRR, arXiv:1806.01261, 2018.
|
| [28] |
Peter W. Battaglia, Razvan Pascanu, Matthew Lai, Danilo Jimenez Rezende, and
Koray Kavukcuoglu.
Interaction networks for learning about objects, relations and
physics.
CoRR, arXiv:1612.00222, 2016.
|
| [29] |
Samy Bengio, Oriol Vinyals, Navdeep Jaitly, and Noam Shazeer.
Scheduled sampling for sequence prediction with recurrent neural
networks.
CoRR, arXiv:1506.03099, 2015.
|
| [30] |
Yoshua Bengio.
Evolving culture vs local minima.
CoRR, arXiv:1203.2990, 2012.
|
| [31] |
Yoshua Bengio.
Deep learning and cultural evolution.
In Proceedings of the Companion Publication of the 2014 Annual
Conference on Genetic and Evolutionary Computation. ACM, 2014.
|
| [32] |
Yoshua Bengio.
Deep learning, Brains and the Evolution of Culture.
In Proceedings of the 36th Annual Conference of the Cognitive
Science Society Workshop on Deep Learning and the Brain. Cognitive Science
Society, 2014.
|
| [33] |
Yoshua Bengio, Aaron Courville, and Pascal Vincent.
Representation learning: A review and new perspectives.
IEEE Transactions on Pattern Analysis and Machine Intelligence,
35(8):1798--1828, 2013.
|
| [34] |
Yoshua Bengio, Pascal Lamblin, Dan Popovici, and Hugo Larochelle.
Greedy layer-wise training of deep networks.
In Advances in Neural Information Processing Systems 19, pages
153--160. MIT Press, Cambridge, MA, 2007.
|
| [35] |
Yoshua Bengio, Dong-Hyun Lee, Jörg Bornschein, and Zhouhan Lin.
Towards biologically plausible deep learning.
CoRR, arXiv:1502.04156, 2016.
|
| [36] |
Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston.
Curriculum learning.
In Proceedings of the 26th Annual International Conference on
Machine Learning, pages 41--48, New York, NY, USA, 2009. ACM.
|
| [37] |
Max Berniker and Konrad P. Kording.
Deep networks for motor control functions.
Frontiers in Computational Neuroscience, 9:32, 2015.
|
| [38] |
Sanjay Bhansali and Mehdi T. Harandi.
Synthesis of UNIX programs using derivational analogy.
Machine Learning, 10:7--55, 1993.
|
| [39] |
J. R. Binder and R. H. Desai.
The neurobiology of semantic memory.
Trends in Cognitive Science, 15(11):527--536, 2011.
|
| [40] |
John Hughlings Jackson [Biography].
An Introduction to the Life and Work of John Hughlings Jackson:
Introduction.
Medical History. Supplement, pages 3--34, 2007.
|
| [41] |
Matthew M. Botvinick.
Multilevel structure in behaviour and in the brain: a model of
Fuster's hierarchy.
Philosophical transactions of the Royal Society of London.
Series B, Biological sciences, 362:1615--1626, 2007.
|
| [42] |
Valentino Braitenberg.
Cell assemblies in the cerebral cortex.
In Roland Heim and Günther Palm, editors, Theoretical
Approaches to Complex Systems, pages 171--188, Berlin, Heidelberg, 1978.
Springer Berlin Heidelberg.
|
| [43] |
Charlotte O. Brand, Alex Mesoudi, and Paul E. Smaldino.
Analogy as a catalyst for cumulative cultural evolution.
PsyArXiv, 2020.
|
| [44] |
Korbinian Brodmann.
Vergleichende Lokalisationslehre der Grosshirnrinde in ihren
Prinzipien dargestellt auf Grund des Zellenbaues.
Johann Ambrosius Barth Verlag, Leipzig, 1909.
|
| [45] |
Andreja Bubic, D. Yves Von Cramon, and Ricarda Schubotz.
Prediction, cognition and the brain.
Frontiers in Human Neuroscience, 4:25, 2010.
|
| [46] |
Silvia Bunge, Carter Wendelken, David Badre, and Anthony Wagner.
Analogical reasoning and prefrontal cortex: Evidence for separable
retrieval and integration mechanisms.
Cerebral Cortex, 15:239--49, 2005.
|
| [47] |
György Buzsàki.
Two-stage model of memory trace formation: a role for 'noisy' brain
states.
Neuroscience, 31(3):551--570, 1989.
|
| [48] |
György Buzsàki.
Theta oscillations in the hippocampus.
Neuron, 33(3), 2002.
|
| [49] |
György Buzsáki.
Rhythms of the Brain.
Oxford University Press, 2006.
|
| [50] |
György Buzsáki.
Neural syntax: Cell assemblies, synapsembles, and readers.
Neuron, 68(3):362--385, 2010.
|
| [51] |
György Buzsàki.
Hippocampal sharp wave-ripple: A cognitive biomarker for episodic
memory and planning.
Hippocampus, 25:1073--1188, 2015.
|
| [52] |
György Buzsáki and Andreas Draguhn.
Neuronal oscillations in cortical networks.
Science, 304:1926--1929, 2004.
|
| [53] |
Ryan T. Canolty, Karunesh Ganguly, Steven W. Kennerley, Charles F. Cadieu,
Kilian Koepsell, Jonathan D. Wallis, and Jose M. Carmena.
Oscillatory phase coupling coordinates anatomically dispersed
functional cell assemblies.
Proceedings of the National Academy of Sciences,
107:17356--17361, 2010.
|
| [54] |
Jaime Carbonell.
Derivational analogy: A theory of reconstructive problem solving
and expertise acquisition.
Technical report, Computer Science Department, 1985.
|
| [55] |
Jaime G. Carbonell.
Derivational analogy and its role in problem solving.
In Proceedings of the Third AAAI Conference on Artificial
Intelligence, pages 64--69. AAAI Press, 1983.
|
| [56] |
Margaret F Carr, Shantanu P Jadhav, and Loren M Frank.
Hippocampal replay in the awake state: a potential substrate for
memory consolidation and retrieval.
Nature neuroscience, 14(2):147, 2011.
|
| [57] |
Alexandra Carstensen and Michael C Frank.
Do graded representations support abstract thought?
Current Opinion in Behavioral Sciences, 37:90--97, 2020.
|
| [58] |
Robbie Case.
Stages in the development of the young child's first sense of self.
Developmental Review, 11(3):210--230, 1991.
|
| [59] |
Anthony R. Cassandra, Leslie Kaelbling, and Michael Littman.
Acting optimally in partially observable stochastic domains.
In Proceedings AAAI-94, pages 1023--1028. AAAI, 1994.
|
| [60] |
Daniel Cer and Randall O'Reilly.
Neural mechanisms of binding in the hippocampus and neocortex:
Insights from computational models.
In Axel Mecklinger Hubert Zimmer and Ulman Lindenberger, editors,
Handbook of Binding and Memory: Perspectives from Cognitive
Neuroscience. Oxford University Press, 1998.
|
| [61] |
Dorothy Cheney and Robert Seyfarth.
Précis of how monkeys see the world.
Behavioral and Brain Sciences, 15:135--147, 2011.
|
| [62] |
Enrico Cherubini and Richard Miles.
The CA3 region of the hippocampus: How is it? What is it for?
How does it do it?
Frontiers in Cellular Neuroscience, 9:19--19, 2015.
|
| [63] |
Jeffrey N. Chiang, Yujia Peng, Hongjing Lu, Keith J. Holyoak, and Martin M.
Monti.
Distributed code for semantic relations predicts neural similarity.
bioRxiv, 2019.
|
| [64] |
E. Y. Choi, S. L Ding, and S. N. Haber.
Combinatorial Inputs to the Ventral Striatum from the
Temporal Cortex, Frontal Cortex, and Amygdala: Implications for
Segmenting the Striatum.
eNeuro, 4(6), 2017.
|
| [65] |
E.V. Clark.
First Language Acquisition.
Cambridge University Press, 2009.
|
| [66] |
Eve Clark.
Grounding and attention in language acquisition.
Papers from the 37th meeting of the Chicago Linguistic Society,
1:95--116, 2002.
|
| [67] |
Eve V. Clark.
Common Ground, pages 328--353.
John Wiley & Sons, Ltd, 2015.
|
| [68] |
Herbert H. Clark.
Using Language.
Cambridge University Press, Cambridge, 1996.
|
| [69] |
Maxwell Crouse, Constantine Nakos, Ibrahim Abdelaziz, and Kenneth Forbus.
Neural analogical matching.
CoRR, arXiv:2004.03573, 2020.
|
| [70] |
Forbus Kenneth D., Ferguson Ronald W., Lovett Andrew, and Gentner Dedre.
Extending SME to handle large-scale cognitive modeling.
Cognitive Science, 41(5):1152--1201, 2016.
|
| [71] |
Terrence W. Deacon.
The Symbolic Species: The Co-evolution of Language and the
Brain.
W. W. Norton, 1998.
|
| [72] |
Thomas Dean.
Interaction and negotiation in learning and understanding dialog.
https://web.stanford.edu/class/cs379c/resources/dialogical/zanax_DOC.dir/index.html,
2014.
|
| [73] |
Thomas Dean, Biafra Ahanonu, Mainak Chowdhury, Anjali Datta, Andre Esteva,
Daniel Eth, Nobie Redmon, Oleg Rumyantsev, and Ysis Tarter.
On the technology prospects and investment opportunities for scalable
neuroscience.
CoRR, arXiv:1307.7302, 2013.
|
| [74] |
Thomas Dean, Dana Angluin, Kenneth Basye, Sean Engelson, Leslie Kaelbling,
Evangelos Kokkevis, and Oded Maron.
Inferring finite automata with stochastic output functions and an
application to map learning.
In Proceedings AAAI-92, pages 208--214, Cambridge,
Massachusetts, 1992. AAAI, MIT Press.
|
| [75] |
Thomas Dean, Kenneth Basye, Robert Chekaluk, Seungseok Hyun, Moises Lejter, and
Margaret Randazza.
Coping with uncertainty in a control system for navigation and
exploration.
In Proceedings AAAI-90, pages 1010--1015, Cambridge,
Massachusetts, 1990. AAAI, MIT Press.
|
| [76] |
Thomas Dean, Maurice Chiang, Marcus Gomez, Nate Gruver, Yousef Hindy, Michelle
Lam, Peter Lu, Sophia Sanchez, Rohun Saxena, Michael Smith, Lucy Wang, and
Catherine Wong.
Amanuensis: The Programmer's Apprentice.
CoRR, arXiv:1807.00082, 2018.
|
| [77] |
Thomas Dean, Chaofei Fan, Francis E. Lewis, and Megumi Sano.
Biological blueprints for next generation AI systems.
CoRR, arXiv:1912.00421, 2019.
|
| [78] |
Thomas Dean, Robert Givan, and Kee-Eung Kim.
Solving planning problems with large state and action spaces.
In Proceedings of the 4th International Conference on Artificial
Intelligence Planning Systems (ICAPS-98), pages 102--110, 1998.
|
| [79] |
Thomas Dean, Leslie Kaelbling, Jak Kirman, and Ann Nicholson.
Planning with deadlines in stochastic domains.
In Proceedings AAAI-93, pages 574--579, Cambridge,
Massachusetts, 1993. AAAI, MIT Press.
|
| [80] |
Thomas Dean, Leslie Kaelbling, Jak Kirman, and Ann Nicholson.
Planning under time constraints in stochastic domains.
Artificial Intelligence Journal, 76:35--74, 1995.
|
| [81] |
Thomas Dean and Shieu-Hong Lin.
Decomposition techniques for planning in stochastic domains.
In Proceedings IJCAI-95, pages 1121--1127, San Francisco,
California, 1995. IJCAI, Morgan Kaufmann Publishers.
|
| [82] |
G. Deco and M. L. Kringelbach.
Hierarchy of Information Processing in the Brain: A Novel 'Intrinsic
Ignition' Framework.
Neuron, 94(5):961--968, 2017.
|
| [83] |
B. Deen, H. Richardson, D. D. Dilks, A. Takahashi, B. Keil, L. L. Wald,
N. Kanwisher, and R. Saxe.
Organization of high-level visual cortex in human infants.
Nature Communications, 8:13995, 2017.
|
| [84] |
Stanislas Dehaene.
Consciousness and the Brain: Deciphering How the Brain Codes Our
Thoughts.
Viking Press, 2014.
|
| [85] |
Stanislas Dehaene and Jean-Pierre Changeux.
A hierarchical neuronal network for planning behavior.
Proceedings of the National Academy of Sciences,
94:13293--13298, 1997.
|
| [86] |
Stanislas Dehaene and Jean-Pierre Changeux.
Experimental and theoretical approaches to conscious processing.
Neuron, 70:200--227, 2017.
|
| [87] |
Stanislas Dehaene, Michel Kerszberg, and Jean-Pierre Changeux.
A neuronal model of a global workspace in effortful cognitive tasks.
Proceedings of the National Academy of Sciences,
95:14529--14534, 1998.
|
| [88] |
Mete Demircigil, Judith Heusel, Matthias Löwe, Sven Upgang, and Franck
Vermet.
On a model of associative memory with huge storage capacity.
Journal of Statistical Physics, 168:288--299, 2017.
|
| [89] |
Yiannis Demiris and Anthony Dearden.
From motor babbling to hierarchical learning by imitation: a robot
developmental pathway.
In Luc Berthouze, Frédéric Kaplan, Hideki Kozima, Hiroyuki
Yano, Jürgen Konczak, Giorgio Metta, Jacqueline Nadel, Giulio Sandini,
Georgi Stojanov, and Christian Balkenius, editors, Proceedings of the
Fifth International Workshop on Epigenetic Robotics: Modeling Cognitive
Development in Robotic Systems, volume 123, pages 31--37. Lund University
Cognitive Studies, 2005.
|
| [90] |
Jacob Devlin, Jonathan Uesato, Rishabh Singh, and Pushmeet Kohli.
Semantic code repair using neuro-symbolic transformation networks.
In International Conference on Learning Representations, 2018.
|
| [91] |
Maël Donoso, Anne G. E. Collins, and Etienne Koechlin.
Foundations of human reasoning in the prefrontal cortex.
Science, 344(6191):1481--1486, 2014.
|
| [92] |
Yan Duan, Marcin Andrychowicz, Bradly C. Stadie, Jonathan Ho, Jonas Schneider,
Ilya Sutskever, Pieter Abbeel, and Wojciech Zaremba.
One-shot imitation learning.
CoRR, arXiv:1703.07326, 2017.
|
| [93] |
S. M. Dudek, G. M. Alexander, and S. Farris.
Rediscovering area CA2: unique properties and functions.
Nature Reviews Neuroscience, 17(2):89--102, 2016.
|
| [94] |
J.C. Eccles, M. Ito, and J. Szentágothai.
The Cerebellum as a Neuronal Machine.
Springer-Verlag, Berlin, 1967.
|
| [95] |
Howard Eichenbaum.
Prefrontal-hippocampal interactions in episodic memory.
Nature Reviews Neuroscience, 18:547--558, 2017.
|
| [96] |
Kevin Ellis, Catherine Wong, Maxwell Nye, Mathias Sable-Meyer, Luc Cary, Lucas
Morales, Luke Hewitt, Armando Solar-Lezama, and Joshua B. Tenenbaum.
Dreamcoder: Growing generalizable, interpretable knowledge with
wake-sleep bayesian program learning.
CoRR, arXiv:2006.08381, 2020.
|
| [97] |
Brian Falkenhainer, Kenneth D. Forbus, and Dedre Gentner.
The Structure-Mapping Engine: Algorithm and Examples.
Artificial Intelligence, 41(1):1--63, 1989.
|
| [98] |
Richard Fikes and Nils J. Nilsson.
STRIPS: A new approach to the application of theorem proving to
problem solving.
Artificial Intelligence Journal, 2:189--208, 1971.
|
| [99] |
Richard E. Fikes, Peter E. Hart, and Nils J. Nilsson.
Learning and executing generalized robot plans.
Artificial Intelligence Journal, 3:251--288, 1972.
|
| [100] |
Jason Fischer, John G. Mikhael, Joshua B. Tenenbaum, and Nancy Kanwisher.
Functional neuroanatomy of intuitive physical inference.
Proceedings of the National Academy of Sciences,
113(34):E5072--E5081, 2016.
|
| [101] |
Fabrizio Frasca, Emanuele Rossi, Davide Eynard, Ben Chamberlain, Michael
Bronstein, and Federico Monti.
SIGN: Scalable Inception Graph Neural Networks.
CoRR, arXiv:2004.11198, 2020.
|
| [102] |
Karl Friston.
Does predictive coding have a future?
Nature Neuroscience, 21, 2018.
|
| [103] |
Justin Fu, Anoop Korattikara, Sergey Levine, and Sergio Guadarrama.
From language to goals: Inverse reinforcement learning for
vision-based instruction following.
In International Conference on Learning Representations, 2019.
|
| [104] |
Joaquín M. Fuster.
Network memory.
Trends in Neurosciences, 20(10):451--459, 1997.
|
| [105] |
Joaquín M. Fuster.
Upper processing stages of the perception-action cycle.
Trends in Cognitive Sciences, 8(4):143--145, 2004.
|
| [106] |
Joaquín M. Fuster.
Chapter 8: An Overview of Prefrontal Functions, pages
375--425.
Elsevier, London, 2015.
|
| [107] |
Joaquín M. Fuster.
Prefrontal Cortex, 5th Edition.
Elsevier, London, 2015.
|
| [108] |
Nicole M. Gage and Bernard J. Baars.
Chapter 2 - the brain.
In Nicole M. Gage and Bernard J. Baars, editors, Fundamentals of
Cognitive Neuroscience (Second Edition), pages 17--52. Academic Press, San
Diego, 2018.
|
| [109] |
Dedre Gentner.
Structure-mapping: A theoretical framework for analogy.
Cognitive Science, 7(2):155--170, 1983.
|
| [110] |
Samuel J. Gershman and Nathaniel D. Daw.
Reinforcement learning and episodic memory in humans and animals:
An integrative framework.
Annual Reviews of Psychology, 68:101--128, 2017.
|
| [111] |
Vanessa E. Ghosh and Asaf Gilboa.
What is a memory schema? a historical perspective on current
neuroscience literature.
Neuropsychologia, 53:104--114, 2014.
|
| [112] |
Mary L. Gick and Keith J. Holyoak.
Schema induction and analogical transfer.
Cognitive Psychology, 15(1):1--38, 1983.
|
| [113] |
I. Goodfellow, Y. Bengio, and A. Courville.
Deep Learning.
Adaptive Computation and Machine Learning series. MIT Press, 2016.
|
| [114] |
Cheryl L. Grady.
Meta-analytic and functional connectivity evidence from functional
magnetic resonance imaging for an anterior to posterior gradient of function
along the hippocampal axis.
Hippocampus, 30(5):456--471, 2020.
|
| [115] |
Alex Graves, Greg Wayne, Malcolm Reynolds, Tim Harley, Ivo Danihelka, Agnieszka
Grabska-Barwińska, Sergio Gómez Colmenarejo, Edward Grefenstette,
Tiago Ramalho, John Agapiou, Adrià Puigdoménech Badia, Karl Moritz
Hermann, Yori Zwols, Georg Ostrovski, Adam Cain, Helen King, Christopher
Summerfield, Phil Blunsom, Koray Kavukcuoglu, and Demis Hassabis.
Hybrid computing using a neural network with dynamic external memory.
Nature, 538:471--476, 2016.
|
| [116] |
A. E. Green, D. J. Kraemer, J. A. Fugelsang, J. R. Gray, and K. N. Dunbar.
Neural correlates of creativity in analogical reasoning.
Journal of Experimental Psychology, Learning, Memory and
Cognition, 38(2):264--272, 2012.
|
| [117] |
Mareike Grotheer, Zonglei Zhen, Garikoitz Lerma-Usabiaga, and Kalanit
Grill-Spector.
Separate lanes for adding and reading in the white matter highways of
the human brain.
Nature Communications, 10:3675, 2019.
|
| [118] |
Xiaodong Gu, Hongyu Zhang, Dongmei Zhang, and Sunghun Kim.
Deep API learning.
CoRR, arXxiv:1605.08535, 2016.
|
| [119] |
Michael Gutmann and Aapo Hyvärinen.
Noise-contrastive estimation: A new estimation principle for
unnormalized statistical models.
In Yee Whye Teh and Mike Titterington, editors, Proceedings of
the Thirteenth International Conference on Artificial Intelligence and
Statistics, volume 9 of Proceedings of Machine Learning Research,
pages 297--304. PMLR, 2010.
|
| [120] |
S. N. Haber.
Corticostriatal circuitry.
Dialogues Clinical Neuroscience, 18(1):7--21, 2016.
|
| [121] |
Jessica B Hamrick.
Analogues of mental simulation and imagination in deep learning.
Current Opinion in Behavioral Sciences, 29:8--16, 2019.
|
| [122] |
Jessica B. Hamrick, Andrew J. Ballard, Razvan Pascanu, Oriol Vinyals, Nicolas
Heess, and Peter W. Battaglia.
Metacontrol for adaptive imagination-based optimization.
CoRR, arXiv:1705.02670, 2017.
|
| [123] |
Mehdi T. Harandi and Sanjay Bhansali.
Program derivation using analogy.
In Proceedings of the 11th International Joint Conference on
Artificial Intelligence, pages 389--394. Morgan Kaufmann Publishers Inc.,
1989.
|
| [124] |
Demis Hassabis and Eleanor A. Maguire.
Deconstructing episodic memory with construction.
Trends in Cognitive Science, 11:299--306, 2007.
|
| [125] |
Demis Hassabis and Eleanor A. Maguire.
The construction system of the brain.
Philosophical Transactions of the Royal Society London B
Biological Science, 364:1263--1271, 2009.
|
| [126] |
Marc D. Hauser and Elizabeth Spelke.
Evolutionary and developmental foundations of human knowledge: A case
study of mathematics.
In M. Gazzaniga and N. Logothetis, editors, The Cognitive
Neurosciences, III, pages 853--864. MIT Press, Cambridge, MA, 2004.
|
| [127] |
Milos Hauskrecht, Nicolas Meuleau, Craig Boutilier, Leslie Pack Kaelbling, and
Thomas Dean.
Hierarchical solution of Markov decision processes using
macro-actions.
In Proceedings of the 14th Conference on Uncertainty in
Artificial Intelligence (UAI-98), pages 220--229, San Francisco,
California, 1998. AUAI, Morgan Kaufmann Publishers.
|
| [128] |
Donald O. Hebb.
The Organization of Behavior: A Neuropsychological Theory.
Wiley, 1949.
|
| [129] |
Donald O. Hebb.
The organization of behavior: A neuropsychological theory.
Wiley, New York, 1949.
|
| [130] |
Jordan Henkel, Shuvendu Lahiri, Ben Liblit, and Thomas W. Reps.
Code vectors: Understanding programs through embedded abstracted
symbolic traces.
CoRR, arXiv:1803.06686, 2018.
|
| [131] |
S. Herculano-Houzel.
The human brain in numbers: a linearly scaled-up primate brain.
Frontiers in Human Neuroscience, 3:31, 2009.
|
| [132] |
S. Herculano-Houzel.
Coordinated scaling of cortical and cerebellar numbers of
neurons.
Frontiers in Neuroanatomy, 4:12, 2010.
|
| [133] |
Irina Higgins, David Amos, David Pfau, Sebastien Racaniere, Loic Matthey,
Danilo Rezende, and Alexander Lerchner.
Towards a definition of disentangled representations.
International Conference on Learning Representations, 2017.
|
| [134] |
Felix Hill, Andrew Lampinen, Rosalia Schneider, Stephen Clark, Matthew
Botvinick, James L. McClelland, and Adam Santoro.
Environmental drivers of systematicity and generalization in a
situated agent.
In International Conference on Learning Representations, 2020.
|
| [135] |
Felix Hill, Adam Santoro, David G. T. Barrett, Ari S. Morcos, and Timothy P.
Lillicrap.
Learning to make analogies by contrasting abstract relational
structure.
In International Conference on Learning Representations, 2019.
|
| [136] |
Geoff Hinton and Ruslan Salakhutdinov.
Reducing the dimensionality of data with neural networks.
Science, 313:504--507, 2006.
|
| [137] |
Geoffrey Hinton, Simon Osindero, and Yee-Whye Teh.
A fast learning algorithm for deep belief nets.
Neural Computation, 18:1527--1554, 2006.
|
| [138] |
Geoffrey E. Hinton.
Learning distributed representations of concepts.
doi: 10.1109/69.917563, 1986.
|
| [139] |
Douglas Hofstadter.
I Am a Strange Loop.
Basic Books, 2007.
|
| [140] |
Keith J. Holyoak.
Analogy and relational reasoning.
In Keith J. Holyoak and Robert G. Morrison, editors, Oxford
Handbook of Thinking and Reasoning, pages 234--259. Oxford University Press,
2012.
|
| [141] |
Joey Hong, David Dohan, Rishabh Singh, Charles Sutton, and Manzil Zaheer.
Latent programmer: Discrete latent codes for program synthesis.
CoRR, arXiv:2012.00377, 2021.
|
| [142] |
Tsung-Ren Huang, Thomas Hazy, Seth A Herd, and Randall O'Reilly.
Assembling old tricks for new tasks: A neural model of instructional
learning and control.
Journal of Cognitive Neuroscience, 25:843--841, 2013.
|
| [143] |
Presley A. Ifukor.
Modelling the mapping mechanism in metaphors.
Cognitive Science, 6:21--44, 2005.
|
| [144] |
Masao Ito.
The Cerebellum: Brain for an Implicit Self.
Financial Times Press, 2012.
|
| [145] |
Andrew Jaegle, Felix Gimeno, Andrew Brock, Andrew Zisserman, Oriol Vinyals, and
Joao Carreira.
Perceiver: General perception with iterative attention.
CoRR, arXiv:2103.03206, 2021.
|
| [146] |
HanShin Jo, Yang-Yen Ou, and Chun-Chia Kung.
The neural substrate of self- and other-concerned wellbeing: An fmri
study.
PLOS ONE, 14(10), 2019.
|
| [147] |
Daniel D. Johnson.
Learning graphical state transitions.
In International Conference on Learning Representations, 2017.
|
| [148] |
Leslie Pack Kaelbling.
Hierarchical learning in stochastic domains: A preliminary report.
In Proceedings Tenth International Conference on Machine
Learning, pages 167--173, 1993.
|
| [149] |
Leslie Pack Kaelbling.
Hierarchical reinforcement learning: A preliminary report.
In Proceedings Tenth International Conference on Machine
Learning, pages 167--173, 1993.
|
| [150] |
Leslie Pack Kaelbling, Michael L. Littman, and Anthony R. Cassandra.
Planning and acting in partially observable stochastic domains.
Artificial Intelligence Journal, 101:99--134, 1998.
|
| [151] |
Sham Machandranath Kakade.
On the sample complexity of reinforcement learning.
PhD Thesis - Gatsby Computational Neuroscience Unit, University
College London, 2003.
|
| [152] |
Kenneth Kay and Loren M. Frank.
Three brain states in the hippocampus and cortex.
Hippocampus, 29(3):184--238, 2019.
|
| [153] |
Raymond P Kesner and Edmund T Rolls.
A computational theory of hippocampal function, and tests of the
theory: new developments.
Neuroscience & Biobehavioral Reviews, 48:92--147, 2015.
|
| [154] |
David Kleinfeld, Martin Deschênes, and Nachum Ulanovsky.
Whisking, sniffing, and the hippocampal theta-rhythm: A tale of two
oscillators.
PLOS Biology, 14(2):1--8, 2016.
|
| [155] |
W. R. Klemm.
Neural representations of the sense of self.
Advances Cognitive Psychology, 7:16--30, 2011.
|
| [156] |
J. G. Klinzing, B. Rasch, J. Born, and S. Diekelmann.
Sleep's role in the reconsolidation of declarative memories.
Neurobiological Learning and Memory, 136:166--173, 2016.
|
| [157] |
Etienne Koechlin and Alexandre Hyafil.
Anterior prefrontal function and the limits of human decision-making.
Science, 318(5850):594--598, 2007.
|
| [158] |
Etienne Koechlin, Chrystèle Ody, and Frédérique Kouneiher.
The architecture of cognitive control in the human prefrontal cortex.
Science, 302:1181--1185, 2003.
|
| [159] |
Dmitry Krotov and John J. Hopfield.
Dense associative memory for pattern recognition.
In D. Lee, M. Sugiyama, U. Luxburg, I. Guyon, and R. Garnett,
editors, Advances in Neural Information Processing Systems, volume 29.
Curran Associates, Inc., 2016.
|
| [160] |
Dharshan Kumaran, Demis Hassabis, and James L. McClelland.
What learning systems do intelligent agents need? Complementary
learning systems theory updated.
Trends in Cognitive Sciences, 20(7):512--534, 2016.
|
| [161] |
Dharshan Kumaran and James L. McClelland.
Generalization through the recurrent interaction of episodic
memories: A model of the hippocampal system.
Psychology Review, 119:573--616, 2012.
|
| [162] |
Andrew Lampinen, Shaw Hsu, and James L. McClelland.
Analogies emerge from learning dyamics in neural networks.
In Tecumseh Fitch, Claus Lamm, Helmut Leder, and Kristin Tessmar,
editors, Proceedings of the 43rd Annual Meeting of the Cognitive Science
Society, pages 2513--2517. Cognitive Science Society, 2020.
|
| [163] |
Andrew Kyle Lampinen, Shaw Hsu, and James L. McClelland.
Analogies emerge from learning dyamics in neural networks.
In Proceedings of the 39th Annual Meeting of the Cognitive
Science Society, 2017.
|
| [164] |
Quoc Le and Tomas Mikolov.
Distributed representations of sentences and documents.
In Proceedings of the 31st International Conference on
International Conference on Machine Learning - Volume 32, pages
II--1188--II--1196. JMLR.org, 2014.
|
| [165] |
P. A. Lewis, G. Knoblich, and G. Poe.
How Memory Replay in Sleep Boosts Creative
Problem-Solving.
Trends Cognitive Science, 22(6):491--503, 2018.
|
| [166] |
Yujia Li, Daniel Tarlow, Marc Brockschmidt, and Richard S. Zemel.
Gated graph sequence neural networks.
CoRR, arXiv:1511.05493, 2015.
|
| [167] |
Yujia Li, Oriol Vinyals, Chris Dyer, Razvan Pascanu, and Peter Battaglia.
Learning deep generative models of graphs.
In International Conference on Learning Representations, 2018.
|
| [168] |
Philip Lieberman.
On the nature and evolution of the neural bases of human language.
American Journal of Physical Anthropology, 119:36--62, December
2002.
|
| [169] |
Philip Lieberman and Robert Mccarthy.
The Evolution of Speech and Language, pages 1--41.
Springer-Verlag, Berlin Heidelberg, 2013.
|
| [170] |
Michael Littman, Thomas Dean, and Leslie Kaelbling.
On the complexity of solving Markov decision problems.
In Proceedings of the 11th Conference on Uncertainty in
Artificial Intelligence, pages 394--402, San Francisco, California, 1995.
AUAI, Morgan Kaufmann Publishers.
|
| [171] |
Kevin Lu, Aditya Grover, Pieter Abbeel, and Igor Mordatch.
Pretrained transformers as universal computation engines.
CoRR, arXiv:2103.05247, 2021.
|
| [172] |
Phan Luu, Alexandra Geyer, Cali Fidopiastis, Gwendolyn Campbell, Tracey
Wheeler, Joseph Cohn, and Don M. Tucker.
Reentrant processing in intuitive perception.
PLOS ONE, 5(3):1--10, 2010.
|
| [173] |
D. Marr and Giles Skey Brindley.
Simple memory: a theory for archicortex.
Philosophical Transactions of the Royal Society of London. B,
Biological Sciences, 262(841):23--81, 1971.
|
| [174] |
David Marr.
A theory of cerebellar cortex.
Journal of Physiology, 202:437--470, 1969.
|
| [175] |
George A. Mashour, Pieter Roelfsema, Jean-Pierre Changeux, and Stanislas
Dehaene.
Conscious processing and the global neuronal workspace hypothesis.
Neuron, 105(5):776--798, 2020.
|
| [176] |
N. R. McFarland and S. N. Haber.
Convergent inputs from thalamic motor nuclei and frontal cortical
areas to the dorsal striatum in the primate.
Journal of Neuroscience, 20(10):3798--3813, 2000.
|
| [177] |
Josh Merel, Matt Botvinick, and Greg Wayne.
Hierarchical motor control in mammals and machines.
Nature Communications, 10(1):5489, 2019.
|
| [178] |
Nicolas Meuleau, Kee-Eung Kim, Leslie Kaelbling, and Anthony R. Cassandra.
Solving POMDPs by searching in the space of finite policies.
In Proceedings of the Fifteenth Conference on Uncertainty in
Artificial Intelligence, 1999.
|
| [179] |
Tomàs Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean.
Distributed representations of words and phrases and their
compositionality.
CoRR, arXiv:1310.4546, 2013.
|
| [180] |
Douglas A. Miller and Steven W. Zucker.
Computing with self-excitatory cliques: A model and an application to
hyperacuity-scale computation in visual cortex.
Neural Computing, 11:21--66, 1999.
|
| [181] |
M. Mitchell.
Analogy-making as Perception: A Computer Model.
A Bradford book. MIT Press, 1993.
|
| [182] |
Melanie Mitchell.
Abstraction and analogy-making in artificial intelligence, 2021.
|
| [183] |
Dharmendra S. Modha and Raghavendra Singh.
Network architecture of the long-distance pathways in the macaque
brain.
Proceedings of the National Academy of Sciences,
107(30):13485--13490, 2010.
|
| [184] |
Christoph Molnar.
Interpretable machine learning: A guide for making black box models
explainable.
https://christophm.github.io/interpretable-ml-book/,
2019.
|
| [185] |
Sushobhan Nayak and Amitabha Mukerjee.
Grounded language acquisition: A minimal commitment approach.
In Proceedings of COLING 2012, pages 2059--2076, Mumbai,
India, 2012.
|
| [186] |
John von Neumann.
First draft of a report on the EDVAC.
Technical report, Institute for Advanced Study, 1945.
|
| [187] |
Klaus Oberauer.
Chapter 2 design for a working memory.
In The Psychology of Learning and Motivation, volume 51 of Psychology of Learning and Motivation, pages 45--100. Academic Press, 2009.
|
| [188] |
Klaus Oberauer.
Working Memory and Attention - A Conceptual Analysis and
Review.
Journal of Cognition, 2(1):36, 2019.
|
| [189] |
R. O'Reilly and David J. Jilk.
ecortex and the computational cognitive neuroscience lab at cu
boulder.
IEEE Intell. Informatics Bull., 10:1--3, 2009.
|
| [190] |
Randall C. O'Reilly, Yuko Munakata, Michael J. Frank, and Thomas E. Hazy
Contributors.
Computational Cognitive Neuroscience.
Wiki Book, Third Edition, 2016.
|
| [191] |
Randall C. O'Reilly, Yuko Munakata, Michael J. Frank, and Thomas E. Hazy
Contributors.
Computational Cognitive Neuroscience.
Wiki Book, 4th Edition, 2020.
|
| [192] |
Günther Palm, Andreas Knoblauch, Florian Hauser, and Almut Schüz.
Cell assemblies in the cerebral cortex.
Biological Cybernetics, 108:559--572, 2014.
|
| [193] |
Christos H. Papadimitriou, Santosh S. Vempala, Daniel Mitropolsky, Michael
Collins, and Wolfgang Maass.
Brain computation by assemblies of neurons.
Proceedings of the National Academy of Sciences,
117(25):14464--14472, 2020.
|
| [194] |
Razvan Pascanu, Yujia Li, Oriol Vinyals, Nicolas Heess, Lars Buesing,
Sébastien Racanière, David P. Reichert, Theophane Weber, Daan
Wierstra, and Peter Battaglia.
Learning model-based planning from scratch.
CoRR, arXiv:1707.06170, 2017.
|
| [195] |
Deepak Pathak, Pulkit Agrawal, Alexei A. Efros, and Trevor Darrell.
Curiosity-driven exploration by self-supervised prediction.
CoRR, arXiv:1705.05363, 2017.
|
| [196] |
L.A. Petitto and P.F. Marentette.
Babbling in the manual mode: evidence for the ontogeny of language.
Science, 251(5000):1493--1496, 1991.
|
| [197] |
Laura Ann Petitto, Siobhan Holowka, Lauren E. Sergio, and David Ostry.
Language rhythms in baby hand movements.
Nature, 413:35--36, 2001.
|
| [198] |
Chris Piech, Jonathan Huang, Andy Nguyen, Mike Phulsuksombati, Mehran Sahami,
and Leonidas Guibas.
Learning program embeddings to propagate feedback on student code.
In Proceedings of the 32nd International Conference on
International Conference on Machine Learning - Volume 37, pages 1093--1102,
2015.
|
| [199] |
Thomas Pierrot, Guillaume Ligner, Scott E. Reed, Olivier Sigaud, Nicolas
Perrin, Alexandre Laterre, David Kas, Karim Beguir, and Nando de Freitas.
Learning compositional neural programs with recursive tree search and
planning.
CoRR, arXiv:1905.12941, 2019.
|
| [200] |
Thomas Pierrot, Nicolas Perrin, Feryal Behbahani, Alexandre Laterre, Olivier
Sigaud, Karim Beguir, and Nando de Freitas.
Learning compositional neural programs for continuous control.
CoRR, arXiv:2007.13363, 2020.
|
| [201] |
David Poeppel, Karen Emmorey, Gregory Hickok, and Liina Pylkkanen.
Towards a new neurobiology of language.
The Journal of Neuroscience: The official journal of the Society
for Neuroscience, 32:14125--14131, 2012.
|
| [202] |
Amy L. Proskovec, Alex I. Wiesman, Elizabeth Heinrichs-Graham, and Tony W.
Wilson.
Beta oscillatory dynamics in the prefrontal and superior temporal
cortices predict spatial working memory performance.
Scientific Reports, 8:8488, 2018.
|
| [203] |
F. Pulvermüller, M. Garagnani, and T. Wennekers.
Thinking in circuits: toward neurobiological explanation in cognitive
neuroscience.
Biological Cybernetics, 108(5):573--593, 2014.
|
| [204] |
Friedemann Pulvermüller.
How neurons make meaning: brain mechanisms for embodied and
abstract-symbolic semantics.
Trends in Cognitive Sciences, 17(9):458--470, 2013.
|
| [205] |
Friedemann Pulvermüller.
Neural reuse of action perception circuits for language, concepts and
communication.
Progress in Neurobiology, 160:1--44, 2018.
|
| [206] |
Hubert Ramsauer, Bernhard Schäfl, Johannes Lehner, Philipp Seidl, Michael
Widrich, Lukas Gruber, Markus Holzleitner, Milena Pavlović, Geir
Sandve, Victor Greiff, David Kreil, Michael Kopp, Günter Klambauer,
Johannes Brandstetter, and Sepp Hochreiter.
Hopfield networks is all you need.
CoRR, arXiv:2008.02217, 2020.
|
| [207] |
Rajesh P. N. Rao and Dana H. Ballard.
Predictive coding in the visual cortex: a functional interpretation
of some extra-classical receptive-field effects.
Nature Neuroscience, 2:79--87, 1999.
|
| [208] |
Mark Rapoport, Robert van Reekum, and Helen Mayberg.
The role of the cerebellum in cognition and behavior.
The Journal of Neuropsychiatry and Clinical Neurosciences,
12(2):193--198, 2000.
|
| [209] |
B. Rasch and J. Born.
About sleep's role in memory.
Physiological Review, 93(2):681--766, 2013.
|
| [210] |
Ali Razavi, Aäron van den Oord, and Oriol Vinyals.
Generating diverse high-fidelity images with VQ-VAE-2.
CoRR, arXiv:1906.00446, 2019.
|
| [211] |
P. Redgrave, T. J. Prescott, and K. Gurney.
The basal ganglia: a vertebrate solution to the selection
problem?
Neuroscience, 89(4):1009--1023, 1999.
|
| [212] |
Scott E. Reed and Nando de Freitas.
Neural programmer-interpreters.
CoRR, arXiv:1511.06279, 2015.
|
| [213] |
R.W. Rieber, A.S. Carton, L.S. Vygotski, N. Minick, J. Wollock, J.E. Knox, and
J.S. Bruner.
The Collected Works of L.S. Vygotsky: Volume 1: Problems of
General Psychology, Including the Volume Thinking and Speech.
Cognition and Language: A Series in Psycholinguistics. Plenum Press,
1987.
|
| [214] |
Jessica Robin and Morris Moscovitch.
Details, gist and schema: hippocampal-neocortical interactions
underlying recent and remote episodic and spatial memory.
Current Opinion in Behavioral Sciences, 17:114--123, 2017.
|
| [215] |
E. T. Rolls.
The storage and recall of memories in the hippocampo-cortical
system.
Cell Tissue Research, 373(3):577--604, 2018.
|
| [216] |
Rachael D. Rubin, Patrick D. Watson, Melissa C. Duff, and Neal J. Cohen.
The role of the hippocampus in flexible cognition and social
behavior.
Frontiers in Human Neuroscience, 8:742, 2014.
|
| [217] |
M. Rudner, P. Fransson, M. Ingvar, L. d Nyberg, and J. Rönnberg.
Neural representation of binding lexical signs and words in the
episodic buffer of working memory.
Neuropsychologia, 45(10):2258--2276, 2007.
|
| [218] |
Ryo Saegusa, Giorgio Metta, Giulio Sandini, and Sophie Sakka.
Active motor babbling for sensorimotor learning.
In 2008 IEEE International Conference on Robotics and
Biomimetics, pages 794--799, 2009.
|
| [219] |
Dario D. Salvucci and John R. Anderson.
Integrating analogical mapping and general problem solving: the
path-mapping theory.
Cognitive Science, 25(1):67--110, 2001.
|
| [220] |
Daniel L. Schacter, Donna Rose Addis, Demis Hassabis, Victoria C. Martin,
R. Nathan Spreng, and Karl K. Szpunar.
The future of memory: Remembering, imagining, and the brain.
Neuron, 76:677--694, 2012.
|
| [221] |
Tom Schaul, John Quan, Ioannis Antonoglou, and David Silver.
Prioritized experience replay.
CoRR, arXiv:1511.05952, 2015.
|
| [222] |
Philipp Seidl, Philipp Renz, Natalia Dyubankova, Paulo Neves, Jonas Verhoeven,
JÖrg K. Wegner, Sepp Hochreiter, and Gunter Klambauer.
Modern hopfield networks for few- and zero-shot reaction prediction.
CoRR, arXiv:2104.03279, 2021.
|
| [223] |
Melanie J. Sekeres, Gordon Winocur, and Morris Moscovitch.
The hippocampus and related neocortical structures in memory
transformation.
Neuroscience Letters, 680:39--53, 2018.
|
| [224] |
Hendrig Sellik.
Natural language processing techniques for code generation.
Delft University of Technology Technical Report, 2019.
|
| [225] |
K. Semendeferi, E. Armstrong, A. Schleicher, K. Zilles, and G. W. Van Hoesen.
Prefrontal cortex in humans and apes: A comparative study of area 10.
American Journal of Physical Anthropology, 114:224--241, 2001.
|
| [226] |
G. Simić, I. Kostović, B. Winblad, and N. Bogdanović.
Volume and number of neurons of the human hippocampal formation in
normal aging and Alzheimer's disease.
Journal of Comparative Neurology, 379(4):482--494, 1997.
|
| [227] |
E. S Spelke and K. D. Kinzler.
Core knowledge.
Developmental Science, 10:89--96, 2007.
|
| [228] |
Elizabeth Spelke.
What makes us special?
Brain Inspired Podcast Episode #48 September 25, 2019, 2019.
|
| [229] |
Ian Stewart and Jack Cohen.
Figments of Reality: The Evolution of the Curious Mind.
Cambridge University Press, 1997.
|
| [230] |
Bjarne Stroustrup.
The Design and Evolution of C++.
Addison-Wesley, 1994.
|
| [231] |
Christian Tetzlaff, Sakyasingha Dasgupta, Tomas Kulvicius, and Florentin
Worgotter.
The use of hebbian cell assemblies for nonlinear computation.
Scientific Reports, 5:12866, 2015.
|
| [232] |
Naftali Tishby and Daniel Polani.
Information theory of decisions and actions.
In V. Cutsuridis, A. Hussain, and J.G. Taylor, editors, Perception-Action Cycle: Models, Architectures, and Hardware. Springer New
York, 2011.
|
| [233] |
Barbara Tversky.
Mind in Motion: How Action Shapes Thought.
Basic Books, 2019.
|
| [234] |
Aäron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu.
Neural discrete representation learning.
CoRR, arXiv:1711.00937, 2017.
|
| [235] |
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones,
Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin.
Attention is all you need.
CoRR, arXiv:1706.03762, 2017.
|
| [236] |
Jacob W. Vogel, Renaud La Joie, Michel J. Grothe, Alexandr Diaz-Papkovich,
Andrew Doyle, Etienne Vachon-Presseau, Claude Lepage, Reinder Vos de Wael,
Rhalena A. Thomas, Yasser Iturria-Medina, Boris Bernhardt, Gil D. Rabinovici,
and Alan C. Evans.
A molecular gradient along the longitudinal axis of the human
hippocampus informs large-scale behavioral systems.
Nature Communications, 11:960, 2020.
|
| [237] |
Brian A. Wandell, Alyssa A. Brewer, and Robert F. Dougherty.
Visual field map clusters in human cortex.
Philosophical transactions of the Royal Society of London.
Series B, Biological sciences, 360:693--707, 2005.
|
| [238] |
Brian A. Wandell, Serge O. Dumoulin, and Alyssa A. Brewer.
Visual field maps in human cortex.
Neuron, 56:366--383, 2007.
|
| [239] |
Ke Wang.
Learning scalable and precise representation of program semantics.
CoRR, arXiv:1905.05251, 2019.
|
| [240] |
Ke Wang, Rishabh Singh, and Zhendong Su.
Dynamic neural program embedding for program repair.
CoRR, arXiv:1711.07163, 2017.
|
| [241] |
Ke Wang, Rishabh Singh, and Zhendong Su.
Dynamic neural program embedding for program repair.
International Conference on Learning Representations, 2018.
|
| [242] |
Ke Wang and Zhendong Su.
Learning blended, precise semantic program embeddings.
CoRR, arXiv:1907.02136, 2019.
|
| [243] |
Sida I. Wang, Percy Liang, and Christopher D. Manning.
Learning language games through interaction.
CoRR, arXiv:1606.02447, 2016.
|
| [244] |
Greg Wayne, Chia-Chun Hung, David Amos, Mehdi Mirza, Arun Ahuja, Agnieszka
Grabska-Barwinska, Jack Rae, Piotr Mirowski, Joel Z. Leibo, Adam Santoro,
Mevlana Gemici, Malcolm Reynolds, Tim Harley, Josh Abramson, Shakir Mohamed,
Danilo Rezende, David Saxton, Adam Cain, Chloe Hillier, David Silver, Koray
Kavukcuoglu, Matt Botvinick, Demis Hassabis, and Timothy Lillicrap.
Unsupervised predictive memory in a goal-directed agent.
CoRR, arXiv:1803.10760, 2018.
|
| [245] |
Bolin Wei, Ge Li, Xin Xia, Zhiyi Fu, and Zhi Jin.
Code generation as a dual task of code summarization.
In H. Wallach, H. Larochelle, A. Beygelzimer, F. d' Alché-Buc,
E. Fox, and R. Garnett, editors, Advances in Neural Information
Processing Systems 32, pages 6563--6573. Curran Associates, Inc., 2019.
|
| [246] |
C. Wendelken, D. Chung, and S. A. Bunge.
Rostrolateral prefrontal cortex: domain-general or
domain-sensitive?
Human Brain Mapping, 33(8):1952--1963, 2012.
|
| [247] |
Mark J. West and H. J. G. Gundersen.
Unbiased stereological estimation of the number of neurons in the
human hippocampus.
Journal of Comparative Neurology, 296(1):1--22, 1990.
|
| [248] |
P. J. Whelan.
Control of locomotion in the decerebrate cat.
Progress in Neurobiology, 49(5):481--515, 1996.
|
| [249] |
Kirstie J. Whitaker, Michael S. Vendetti, Carter Wendelken, and Silvia A.
Bunge.
Neuroscientific insights into the development of analogical
reasoning.
Developmental science, 21:e12531, 2018.
|
| [250] |
D. J. Willshaw, P. Dayan, and R. G. M. Morris.
Memory, modelling and marr: a commentary on marr (1971) simple
memory: a theory of archicortex.
Philosophical Transactions of the Royal Society B: Biological
Sciences, 370(1666):20140383, 2015.
|
| [251] |
Representation Learning with Contrastive Predictive Coding.
Aaron van den oord and yazhe li and oriol vinyals.
CoRR, arXiv:1807.03748, 2018.
|
| [252] |
Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and
Philip S. Yu.
A comprehensive survey on graph neural networks.
CoRR, arXiv:1901.00596, 2019.
|
| [253] |
X. Xie and H. S. Seung.
Equivalence of backpropagation and contrastive Hebbian learning
in a layered network.
Neural Computation, 15(2):441--454, 2003.
|
| [254] |
Yujun Yan, Kevin Swersky, Danai Koutra, Parthasarathy Ranganathan, and Milad
Hashemi.
Neural execution engines: Learning to execute subroutines.
CoRR, arXiv:2006.08084, 2020.
|
| [255] |
Yujun Yan, Kevin Swersky, Danai Koutra, Parthasarathy Ranganathan, and Milad
Hashemi.
Neural execution engines: Learning to execute subroutines.
In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin,
editors, Advances in Neural Information Processing Systems 33, 2020.
|
| [256] |
Michihiro Yasunaga and Percy Liang.
Multi-objective molecule generation using interpretable
substructures.
In Proceedings of the 37th International Conference on Machine
Learning, volume arXiv:2005.10636, 2020.
|
| [257] |
Haonan Yu, Haichao Zhang, and Wei Xu.
Interactive grounded language acquisition and generalization in a
2D world.
CoRR, arXiv:1802.01433, 2018.
|
| [258] |
J. Y. Yu, D. F. Liu, A. Loback, I. Grossrubatscher, and L. M. Frank.
Specific hippocampal representations are linked to generalized
cortical representations in memory.
Nat Commun, 9(1):2209, 2018.
|
1 Below are the BibTeX references with abstracts for several of the papers that were used in compiling the section on computational and mathematical models in the July 15 entry in the class discussion log for 2021:
@article{AmuntsandZillesNEURON-15,
author = {Amunts, K. and Zilles, K.},
title = {{{A}rchitectonic {M}apping of the {H}uman {B}rain beyond {B}rodmann}},
journal = {Neuron},
year = {2015},
volume = {88},
number = {6},
pages = {1086-1107},
abstract = {Brodmann has pioneered structural brain mapping. He considered functional and pathological criteria for defining cortical areas in addition to cytoarchitecture. Starting from this idea of structural-functional relationships at the level of cortical areas, we will argue that the cortical architecture is more heterogeneous than Brodmann's map suggests. A triple-scale concept is proposed that includes repetitive modular-like structures and micro- and meso-maps. Criteria for defining a cortical area will be discussed, considering novel preparations, imaging and optical methods, 2D and 3D quantitative architectonics, as well as high-performance computing including analyses of big data. These new approaches contribute to an understanding of the brain on multiple levels and challenge the traditional, mosaic-like segregation of the cerebral cortex.}
}
@article{BinderandDesaiTiCS-11,
author = {Binder, J. R. and Desai, R. H.},
title = {The neurobiology of semantic memory},
journal = {Trends in Cognitive Science},
year = {2011},
volume = {15},
number = {11},
pages = {527-536},
abstract = {Semantic memory includes all acquired knowledge about the world and is the basis for nearly all human activity, yet its neurobiological foundation is only now becoming clear. Recent neuroimaging studies demonstrate two striking results: the participation of modality-specific sensory, motor, and emotion systems in language comprehension, and the existence of large brain regions that participate in comprehension tasks but are not modality-specific. These latter regions, which include the inferior parietal lobe and much of the temporal lobe, lie at convergences of multiple perceptual processing streams. These convergences enable increasingly abstract, supramodal representations of perceptual experience that support a variety of conceptual functions including object recognition, social cognition, language, and the remarkable human capacity to remember the past and imagine the future.}
}
@article {ModhaandSinghPNAS-10,
author = {Modha, Dharmendra S. and Singh, Raghavendra},
title = {Network architecture of the long-distance pathways in the macaque brain},
journal = {Proceedings of the National Academy of Sciences},
volume = {107},
number = {30},
pages = {13485-13490},
year = {2010},
publisher = {National Academy of Sciences},
abstract = {Understanding the network structure of white matter communication pathways is essential for unraveling the mysteries of the brain's function, organization, and evolution. To this end, we derive a unique network incorporating 410 anatomical tracing studies of the macaque brain from the Collation of Connectivity data on the Macaque brain (CoCoMac) neuroinformatic database. Our network consists of 383 hierarchically organized regions spanning cortex, thalamus, and basal ganglia; models the presence of 6,602 directed long-distance connections; is three times larger than any previously derived brain network; and contains subnetworks corresponding to classic corticocortical, corticosubcortical, and subcortico-subcortical fiber systems. We found that the empirical degree distribution of the network is consistent with the hypothesis of the maximum entropy exponential distribution and discovered two remarkable bridges between the brain's structure and function via network-theoretical analysis. First, prefrontal cortex contains a disproportionate share of topologically central regions. Second, there exists a tightly integrated core circuit, spanning parts of premotor cortex, prefrontal cortex, temporal lobe, parietal lobe, thalamus, basal ganglia, cingulate cortex, insula, and visual cortex, that includes much of the task-positive and task-negative networks and might play a special role in higher cognition and consciousness.},
}
@article{PapadimitriouetalPNAS-20,
author = {Papadimitriou, Christos H. and Vempala, Santosh S. and Mitropolsky, Daniel and Collins, Michael and Maass, Wolfgang},
title = {Brain computation by assemblies of neurons},
journal = {Proceedings of the National Academy of Sciences},
publisher = {National Academy of Sciences},
volume = {117},
number = {25},
year = {2020},
pages = {14464-14472},
abstract = {Our expanding understanding of the brain at the level of neurons and synapses, and the level of cognitive phenomena such as language, leaves a formidable gap between these two scales. Here we introduce a computational system which promises to bridge this gap: the Assembly Calculus. It encompasses operations on assemblies of neurons, such as project, associate, and merge, which appear to be implicated in cognitive phenomena, and can be shown, analytically as well as through simulations, to be plausibly realizable at the level of neurons and synapses. We demonstrate the reach of this system by proposing a brain architecture for syntactic processing in the production of language, compatible with recent experimental results. Assemblies are large populations of neurons believed to imprint memories, concepts, words, and other cognitive information. We identify a repertoire of operations on assemblies. These operations correspond to properties of assemblies observed in experiments, and can be shown, analytically and through simulations, to be realizable by generic, randomly connected populations of neurons with Hebbian plasticity and inhibition. {\it{Assemblies and their operations constitute a computational model of the brain which we call the Assembly Calculus, occupying a level of detail intermediate between the level of spiking neurons and synapses and that of the whole brain.}} The resulting computational system can be shown, under assumptions, to be, in principle, capable of carrying out arbitrary computations. We hypothesize that something like it may underlie higher human cognitive functions such as reasoning, planning, and language. In particular, we propose a plausible brain architecture based on assemblies for implementing the syntactic processing of language in cortex, which is consistent with recent experimental results.},
}
@article{RollsCTR-18,
author = {Rolls, E. T.},
title = {{{T}he storage and recall of memories in the hippocampo-cortical system}},
journal = {Cell Tissue Research},
year = {2018},
volume = {373},
number = {3},
pages = {577-604},
abstract = {A quantitative computational theory of the operation of the hippocampus as an episodic memory system is described. The CA3 system operates as a single attractor or autoassociation network (1) to enable rapid one-trial associations between any spatial location (place in rodents or spatial view in primates) and an object or reward and (2) to provide for completion of the whole memory during recall from any part. The theory is extended to associations between time and object or reward to implement temporal order memory, which is also important in episodic memory. The dentate gyrus performs pattern separation by competitive learning to create sparse representations producing, for example, neurons with place-like fields from entorhinal cortex grid cells. The dentate granule cells generate, by the very small number of mossy fibre connections to CA3, a randomizing pattern separation effect that is important during learning but not recall and that separates out the patterns represented by CA3 firing as being very different from each other. This is optimal for an unstructured episodic memory system in which each memory must be kept distinct from other memories. The direct perforant path input to CA3 is quantitatively appropriate for providing the cue for recall in CA3 but not for learning. The CA1 recodes information from CA3 to set up associatively learned backprojections to the neocortex to allow the subsequent retrieval of information to the neocortex, giving a quantitative account of the large number of hippocampo-neocortical and neocortical-neocortical backprojections. Tests of the theory including hippocampal subregion analyses and hippocampal NMDA receptor knockouts are described and support the theory.}
}
@article{KesnerandRollsNBR-15,
title = {A computational theory of hippocampal function, and tests of the theory: new developments},
author = {Raymond P. Kesner and Edmund T. Rolls},
journal = {Neuroscience \& Biobehavioral Reviews},
year = {2015},
volume = {48},
pages = {92-147},
abstract = {The aims of the paper are to update Rolls' quantitative computational theory of hippocampal function and the predictions it makes about the different subregions (dentate gyrus, CA3 and CA1), and to examine behavioral and electrophysiological data that address the functions of the hippocampus and particularly its subregions. Based on the computational proposal that the dentate gyrus produces sparse representations by competitive learning and via the mossy fiber pathway forces new representations on the CA3 during learning (encoding), it has been shown behaviorally that the dentate gyrus supports spatial pattern separation during learning. Based on the computational proposal that CA3-CA3 autoassociative networks are important for episodic memory, it has been shown behaviorally that the CA3 supports spatial rapid one-trial learning, learning of arbitrary associations where space is a component, pattern completion, spatial short-term memory, and spatial sequence learning by associations formed between successive items. The concept that the CA1 recodes information from CA3 and sets up associatively learned backprojections to neocortex to allow subsequent retrieval of information to neocortex, is consistent with findings on consolidation. Behaviorally, the CA1 is implicated in processing temporal information as shown by investigations requiring temporal order pattern separation and associations across time; and computationally this could involve associations in CA1 between object and timing information that have their origins in the lateral and medial entorhinal cortex respectively. The perforant path input from the entorhinal cortex to DG is implicated in learning, to CA3 in retrieval from CA3, and to CA1 in retrieval after longer time intervals ("intermediate-term memory") and in the temporal sequence memory for objects.}
}
@article{RamsaueretalCoRR-20,
author = {Ramsauer, Hubert and Sch{\"{a}}fl, Bernhard and Lehner, Johannes and Seidl, Philipp and Widrich, Michael and Gruber, Lukas and Holzleitner, Markus and Pavlovi{\'{c}}, Milena and Sandve, Geir and Greiff, Victor and Kreil, David and Kopp, Michael and Klambauer, G{\"{u}}nter and Brandstetter, Johannes and Hochreiter, Sepp},
title = {Hopfield Networks is All You Need},
year = {2020},
journal = {CoRR},
volume = {arXiv:2008.02217},
abstract = {The transformer and BERT models pushed the performance on NLP tasks to new levels via their attention mechanism. We show that this attention mechanism is the update rule of a modern Hopfield network with continuous states. This new Hopfield network can store exponentially (with the dimension) many patterns, converges with one update, and has exponentially small retrieval errors. The number of stored patterns must be traded off against convergence speed and retrieval error. The new Hopfield network has three types of energy minima (fixed points of the update): (1) global fixed point averaging over all patterns, (2) metastable states averaging over a subset of patterns, and (3) fixed points which store a single pattern. Transformers learn an attention mechanism by constructing an embedding of patterns and queries into an associative space. Transformer and BERT models operate in their first layers preferably in the global averaging regime, while they operate in higher layers in metastable states. The gradient in transformers is maximal in the regime of metastable states, is uniformly distributed when averaging globally, and vanishes when a fixed point is near a stored pattern. Based on the Hopfield network interpretation, we analyzed learning of transformer and BERT architectures. Learning starts with attention heads that average and then most of them switch to metastable states. However, the majority of heads in the first layers still averages and can be replaced by averaging operations like the Gaussian weighting that we propose. In contrast, heads in the last layers steadily learn and seem to use metastable states to collect information created in lower layers. These heads seem a promising target for improving transformers. Neural networks that integrate Hopfield networks, that are equivalent to attention heads, outperform other methods on immune repertoire classification, where the Hopfield net stores several hundreds of thousands of patterns. We provide a PyTorch implementation of a new layer called 'Hopfield' which allows to equip deep learning architectures with Hopfield networks as new memory concepts.}
}
2 Recent papers hypothesizing the existence of anterior-posterior and dorsal-lateral functional gradients in human hippocampus:
@article{BonasiaetalNLM-18,
author = {Kyra Bonasia and Melanie J. Sekeres and Asaf Gilboa and Cheryl L. Grady and Gordon Winocur and Morris Moscovitch},
title = {Prior knowledge modulates the neural substrates of encoding and retrieving naturalistic events at short and long delays},
journal = {Neurobiology of Learning and Memory},
volume = {153},
year = {2018},
pages = {26-39},
abstract = {Congruence with prior knowledge and incongruence/novelty have long been identified as two prominent factors that, despite their opposing characteristics, can both enhance episodic memory. Using narrative film clip stimuli, this study investigated these effects in naturalistic event memories - examining behaviour and neural activation to help explain this paradox. Furthermore, we examined encoding, immediate retrieval, and one-week delayed retrieval to determine how these effects evolve over time. Behaviourally, both congruence with prior knowledge and incongruence/novelty enhanced memory for events, though incongruent events were recalled with more errors over time. During encoding, greater congruence with prior knowledge was correlated with medial prefrontal cortex (mPFC) and parietal activation, suggesting that these areas may play a key role in linking current episodic processing with prior knowledge. Encoding of increasingly incongruent events, on the other hand, was correlated with increasing activation in, and functional connectivity between, the medial temporal lobe (MTL) and posterior sensory cortices. During immediate and delayed retrieval the mPFC and MTL each demonstrated functional connectivity that varied based on the congruence of events with prior knowledge; with connectivity between the MTL and occipital regions found for incongruent events, while congruent events were associated with functional connectivity between the mPFC and the inferior parietal lobules and middle frontal gyri. These results demonstrate patterns of neural activity and connectivity that shift based on the nature of the event being experienced or remembered, and that evolve over time. Furthermore, they suggest potential mechanisms by which both congruence with prior knowledge and incongruence/novelty may enhance memory, through mPFC and MTL functional connectivity, respectively.}
}
@incollection{CerandReillyCOGNITIVE-SCIENCE-98,
author = {Cer, Daniel and O'Reilly, Randall},
title = {Neural mechanisms of binding in the hippocampus and neocortex: {I}nsights from computational models},
booktitle = {Handbook of Binding and Memory: Perspectives from Cognitive Neuroscience},
editor = {Hubert Zimmer, Axel Mecklinger and Ulman Lindenberger},
publisher = {Oxford University Press},
year = {1998},
abstract = {The development of accurate models of the neural mechanisms underlying binding represents a critical step in the understanding of the mechanisms that give rise to most cognitive processes. This chapter presents a range of computational models based on the biological specializations associated with different brain areas that support a range of different contributions to binding. The posterior cortex can learn coarse-coded distributed representations (CCDRs) of low-order conjunctions which can efficiently and systematically bind information in the service of many different forms of cortical information processing. However, these representations are learned slowly over experience. In contrast, the hippocampus is specialized for rapidly binding novel information into high-order conjunctive representations (e.g., episodes or locations). The prefrontal cortex can actively maintain dynamic bindings in working memory and, through more abstract rule-like representations, support more flexible generalization of behaviour across novel task contexts. Taken together, this overall biologically based cognitive architecture represents a more plausible framework for understanding binding than that provided by temporal synchrony approaches.}
}
@article{DudeketalNRN-16,
author = {Dudek, S. M. and Alexander, G. M. and Farris, S.},
title = {{{R}ediscovering area {C}{A}2: unique properties and functions}},
journal = {Nature Reviews Neuroscience},
year = {2016},
volume = {17},
number = {2},
pages = {89-102},
abstract = {Hippocampal area CA2 has several features that distinguish it from CA1 and CA3, including a unique gene expression profile, failure to display long-term potentiation and relative resistance to cell death. A recent increase in interest in the CA2 region, combined with the development of new methods to define and manipulate its neurons, has led to some exciting new discoveries on the properties of CA2 neurons and their role in behaviour. Here, we review these findings and call attention to the idea that the definition of area CA2 ought to be revised in light of gene expression data.}
}
@article{EichenbaumNRN-17,
author = {Eichenbaum, Howard},
title = {Prefrontal-hippocampal interactions in episodic memory},
journal = {Nature Reviews Neuroscience},
year = {2017},
volume = {18},
issue = {9},
pages = {547-558},
abstract = {The prefrontal cortex (PFC) and hippocampus support complementary functions in episodic memory. Connections between the PFC and the hippocampus are particularly important for episodic memory. In addition, these areas interact bidirectionally through oscillatory synchrony. Distinct types of interactions between the PFC and hippocampus are supported by a direct hippocampus-PFC connection and by bidirectional pathways via intermediaries in the thalamus and perirhinal and lateral entorhinal cortices.This Review outlines a model of how the PFC and hippocampus interact during episodic memory tasks.},
}
@article{GradyHIPPOCAMPUS-19,
author = {Grady, Cheryl L.},
title = {Meta-analytic and functional connectivity evidence from functional magnetic resonance imaging for an anterior to posterior gradient of function along the hippocampal axis},
journal = {Hippocampus},
volume = {30},
number = {5},
year = {2020},
pages = {456-471},
abstract = {There is considerable evidence from non-human animal studies that the anterior and posterior regions of the hippocampus have different anatomical connections and support different behavioural functions. Although there are some recent human studies using functional magnetic resonance imaging (fMRI) that have addressed this idea directly in the memory and spatial processing domains and provided support for it, there has been no broader meta-analysis of the fMRI literature to determine if there is consistent evidence for functional dissociations in anterior and posterior hippocampus across all of the different cognitive domains in which the hippocampus participates. The purpose of this review is to address this gap in our knowledge using three approaches. One approach involved PubMed searches to identify relevant fMRI papers reporting hippocampal activation during episodic encoding and retrieval, semantic retrieval, working memory, spatial navigation, simulation/scene construction, transitive inference, and social cognition tasks. The second was to use a large meta-analytic database (neurosynth) to find text terms and coactivation maps associated with the anterior and posterior hippocampal regions identified in the literature search. The third approach was to contrast the resting-state functional connectivity of the anterior and posterior hippocampal regions using a publicly available database that includes a large sample of adults. These three approaches provided converging evidence that not only are cognitive processes differently distributed along the hippocampal axis, but there also are distinct areas coactivated and functionally connected with the anterior and posterior segments. This anterior/posterior distinction involving multiple cognitive domains is consistent with the animal literature and provides strong support from fMRI for the idea of functional dissociations across the long axis of the hippocampus.},
}
@article {HassabisetalJoN-07,
author = {Hassabis, Demis and Kumaran, Dharshan and Maguire, Eleanor A.},
title = {Using Imagination to Understand the Neural Basis of Episodic Memory},
journal = {Journal of Neuroscience},
publisher = {Society for Neuroscience},
volume = {27},
number = {52},
year = {2007},
pages = {14365-14374},
abstract = {Functional MRI (fMRI) studies investigating the neural basis of episodic memory recall, and the related task of thinking about plausible personal future events, have revealed a consistent network of associated brain regions. Surprisingly little, however, is understood about the contributions individual brain areas make to the overall recollective experience. To examine this, we used a novel fMRI paradigm in which subjects had to imagine fictitious experiences. In contrast to future thinking, this results in experiences that are not explicitly temporal in nature or as reliant on self-processing. By using previously imagined fictitious experiences as a comparison for episodic memories, we identified the neural basis of a key process engaged in common, namely scene construction, involving the generation, maintenance and visualization of complex spatial contexts. This was associated with activations in a distributed network, including hippocampus, parahippocampal gyrus, and retrosplenial cortex. Importantly, we disambiguated these common effects from episodic memory-specific responses in anterior medial prefrontal cortex, posterior cingulate cortex and precuneus. These latter regions may support self-schema and familiarity processes, and contribute to the brain{\textquoteright}s ability to distinguish real from imaginary memories. We conclude that scene construction constitutes a common process underlying episodic memory and imagination of fictitious experiences, and suggest it may partially account for the similar brain networks implicated in navigation, episodic future thinking, and the default mode. We suggest that additional brain regions are co-opted into this core network in a task-specific manner to support functions such as episodic memory that may have additional requirements.},
}
@article{HassabisandMaguirePTRS_B-09,
title = {The construction system of the brain},
author = {Hassabis, Demis and Maguire, Eleanor A.},
journal = {Philosophical Transactions of the Royal Society London B Biological Science},
publisher = {The Royal Society},
volume = 364,
issue = 1521,
year = 2009,
pages = {1263-1271},
abstract = {The ability to construct a hypothetical situation in one's imagination prior to it actually occurring may afford greater accuracy in predicting its eventual outcome. The recollection of past experiences is also considered to be a reconstructive process with memories recreated from their component parts. Construction, therefore, plays a critical role in allowing us to plan for the future and remember the past. Conceptually, construction can be broken down into a number of constituent processes although little is known about their neural correlates. Moreover, it has been suggested that some of these processes may be shared by a number of other cognitive functions including spatial navigation and imagination. Recently, novel paradigms have been developed that allow for the isolation and characterization of these underlying processes and their associated neuroanatomy. Here, we selectively review this fast-growing literature and consider some implications for remembering the past and predicting the future.},
}
@article{MarrandBrindleyPTRS_B-71,
author = {D. Marr and Giles Skey Brindley},
title = {Simple memory: a theory for archicortex},
journal = {Philosophical Transactions of the Royal Society of London. B, Biological Sciences},
volume = {262},
number = {841},
pages = {23-81},
year = {1971},
abstract = {It is proposed that the most important characteristic of archicortex is its ability to perform a simple kind of memorizing task. It is shown that rather general numerical constraints roughly determine the dimensions of memorizing models for the mammalian brain, and from these is derived a general model for archicortex. The addition of further constraints leads to the notion of a simple representation, which is a way of translating a great deal of information into the firing of about 200 out of a population of 105 cells. It is shown that if about 105 simple representations are stored in such a population of cells, very little information about a single learnt event is necessary to provoke its recall. A detailed numerical examination is made of a particular example of this kind of memory, and various general conclusions are drawn from the analysis. The insight gained from these models is used to derive theories for various archicortical areas. A functional interpretation is given of the cells and synapses of the area entorhinalis, the presubiculum, the prosubiculum, the cornu ammonis and the fascia dentata. Many predictions are made, a substantial number of which must be true if the theory is correct. A general functional classification of typical archicortical cells is proposed. }
}
@article{MillerandCohenARN-01,
author = {Miller, Earl K. and Cohen, Jonathan D.},
title = {An Integrative Theory of Prefrontal Cortex Function},
journal = {Annual Review of Neuroscience},
volume = {24},
number = {1},
pages = {167-202},
year = {2001},
abstract = {The prefrontal cortex has long been suspected to play an important role in cognitive control, in the ability to orchestrate thought and action in accordance with internal goals. Its neural basis, however, has remained a mystery. Here, we propose that cognitive control stems from the active maintenance of patterns of activity in the prefrontal cortex that represent goals and the means to achieve them. They provide bias signals to other brain structures whose net effect is to guide the flow of activity along neural pathways that establish the proper mappings between inputs, internal states, and outputs needed to perform a given task. We review neurophysiological, neurobiological, neuroimaging, and computational studies that support this theory and discuss its implications as well as further issues to be addressed}
}
@article{RobinandMoscovitchCOiBS-17,
author = {Jessica Robin and Morris Moscovitch},
title = {Details, gist and schema: hippocampal–neocortical interactions underlying recent and remote episodic and spatial memory},
journal = {Current Opinion in Behavioral Sciences},
volume = {17},
pages = {114-123},
year = {2017},
abstract = {Memories are complex and dynamic, continuously transforming with time and experience. In this paper, we review evidence of the neural basis of memory transformation for events and environments with emphasis on the role of hippocampal–neocortical interactions. We argue that memory transformation from detail-rich representations to gist-like and schematic representation is accompanied by corresponding changes in their neural representations. These changes can be captured by a model based on functional differentiation along the long-axis of the hippocampus, and its functional connectivity to related posterior and anterior neocortical structures, especially the ventromedial prefrontal cortex (vmPFC). In particular, we propose that perceptually detailed, highly specific representations are mediated by the posterior hippocampus and neocortex, gist-like representations by the anterior hippocampus, and schematic representations by vmPFC. These representations can co-exist and the degree to which each is utilized is determined by its availability and by task demands.}
}
@article{SchacteretalNEURON-12,
author = {Daniel L. Schacter and Donna Rose Addis and Demis Hassabis and Victoria C. Martin and R. Nathan Spreng and Karl K. Szpunar},
title = {The Future of Memory: Remembering, Imagining, and the Brain},
journal = {Neuron},
volume = 76,
year = 2012,
pages = {677-694},
abstract = {During the past few years, there has been a dramatic increase in research examining the role of memory in imagination and future thinking. This work has revealed striking similarities between remembering the past and imagining or simulating the future, including the finding that a common brain network underlies both memory and imagination. Here, we discuss a number of key points that have emerged during recent years, focusing in particular on the importance of distinguishing between temporal and nontemporal factors in analyses of memory and imagination, the nature of differences between remembering the past and imagining the future, the identification of component processes that comprise the default network supporting memory-based simulations, and the finding that this network can couple flexibly with other networks to support complex goal-directed simulations. This growing area of research has broadened our conception of memory by highlighting the many ways in which memory supports adaptive functioning.}
}
@article{SchlichtingandPrestonCOiBS-15,
author = {Margaret L Schlichting and Alison R Preston},
title = {Memory integration: neural mechanisms and implications for behavior},
journal = {Current Opinion in Behavioral Sciences},
volume = {1},
year = {2015},
pages = {1-8},
abstract = {Everyday behaviors require a high degree of flexibility, in which prior knowledge is applied to inform behavior in new situations. Such flexibility is thought to be supported in part by memory integration, a process whereby related memories become interconnected in the brain through recruitment of overlapping neuronal populations. Recent advances in cognitive and behavioral neuroscience highlight the importance of a hippocampal-medial prefrontal circuit in memory integration. Emerging evidence suggests that abstracted representations in medial prefrontal cortex guide reactivation of related memories during new encoding events, thus promoting hippocampal integration of related experiences. Moreover, recent work indicates that integrated memories are called upon during novel situations to facilitate a host of behaviors, from spatial navigation to imagination.}
}
@article{SekeresetalNEUROSCIENCE-LETTERS-18,
author = {Melanie J. Sekeres and Gordon Winocur and Morris Moscovitch},
title = {The hippocampus and related neocortical structures in memory transformation},
journal = {Neuroscience Letters},
volume = {680},
year = {2018},
pages = {39-53},
abstract = {Episodic memories are multifaceted and malleable, capable of being transformed with time and experience at both the neural level and psychological level. At the neural level, episodic memories are transformed from being dependent on the hippocampus to becoming represented in neocortical structures, such as the medial prefrontal cortex (mPFC), and back again, while at the psychological level, detailed, perceptually rich memories, are transformed to ones retaining only the gist of an experience or a schema related to it. Trace Transformation Theory (TTT) initially proposed that neural and psychological transformations are linked and proceed in tandem. Building on recent studies on the neurobiology of memory transformation in rodents and on the organization of the hippocampus and its functional cortical connectivity in humans, we present an updated version of TTT that is more precise and detailed with respect to the dynamic processes and structures implicated in memory transformation. At the heart of the updated TTT lies the long axis of the hippocampus whose functional differentiation and connectivity to neocortex make it a hub for memory formation and transformation. The posterior hippocampus, connected to perceptual and spatial representational systems in posterior neocortex, supports fine, perceptually rich, local details of memories; the anterior hippocampus, connected to conceptual systems in anterior neocortex, supports coarse, global representations that constitute the gist of a memory. Notable among the anterior neocortical structures is the medial prefrontal cortex (mPFC) which supports representation of schemas that code for common aspects of memories across different episodes. Linking the aHPC with mPFC is the entorhinal cortex (EC) which conveys information needed for the interaction/translation between gist and schemas. Thus, the long axis of the hippocampus, mPFC and EC provide the representational gradient, from fine to coarse and from perceptual to conceptual, that can implement processes implicated in memory transformation. Each of these representations of an episodic memory can co-exist and be in dynamic flux as they interact with one another throughout the memory's lifetime, going from detailed to schematic and possibly back again, all mediated by corresponding changes in neural representation.}
}
@article{VogeletalNATURE-COMMUNICATIONS-20,
author = {Vogel, Jacob W. and La Joie, Renaud and Grothe, Michel J. and Diaz-Papkovich, Alexandr and Doyle, Andrew and Vachon-Presseau, Etienne and Lepage, Claude and Vos de Wael, Reinder and Thomas, Rhalena A. and Iturria-Medina, Yasser and Bernhardt, Boris and Rabinovici, Gil D. and Evans, Alan C.},
title = {A molecular gradient along the longitudinal axis of the human hippocampus informs large-scale behavioral systems},
journal = {Nature Communications},
volume = {11},
issue = {1},
year = {2020},
pages = {960},
abstract = {The functional organization of the hippocampus is distributed as a gradient along its longitudinal axis that explains its differential interaction with diverse brain systems. We show that the location of human tissue samples extracted along the longitudinal axis of the adult human hippocampus can be predicted within 2mm using the expression pattern of less than 100 genes. Futhermore, this model generalizes to an external set of tissue samples from prenatal human hippocampi. We examine variation in this specific gene expression pattern across the whole brain, finding a distinct anterioventral-posteriodorsal gradient. We find frontal and anterior temporal regions involved in social and motivational behaviors, and more functionally connected to the anterior hippocampus, to be clearly differentiated from posterior parieto-occipital regions involved in visuospatial cognition and more functionally connected to the posterior hippocampus. These findings place the human hippocampus at the interface of two major brain systems defined by a single molecular gradient.},
}
@book{ZimmeretalHBM-06,
author = {Zimmer, Hubert and Mecklinger, Axel and Lindenberger, Ulma},
publisher = {Oxford University Press},
title = {Handbook of Binding and Memory: Perspectives from Cognitive Neuroscience},
year = {2006},
abstract = {The creation and consolidation of a memory can rest on the integration of any number of possibly disparate features and contexts — colour, sound, emotion, arousal, context. How is it that these bind together to form a coherent memory? What is the role of binding in memory formation? What are the neural processes that underlie binding? Do these binding processes change with age? This book offers an overview of binding, one of the most debated hotspots of modern memory research. It contains twenty-eight chapters on binding in different domains of memory, presenting classic research from the field of cognitive neuroscience. As well as presenting an account of recent views on binding and its importance for remembering, it also includes a review of recent publications in the area. More than just a survey, it supplies an integrative view on binding in memory, fostering deep insights not only into the processes and their determinants, but also into the neural mechanisms enabling these processes. The content also encompasses a wide range of binding-related topics, including feature binding, the binding of items and contexts during encoding and retrieval, the specific roles of familiarity and recollection, as well as task- and especially age-related changes in these processes. A section is dedicated to in-depth analyses of underlying neural mechanisms, focusing on both medial temporal and prefrontal structures. Computational approaches are covered as well.}
}
3 The Differential Neural Computer (DNC) model [115] was partly inspired by the mammalian hippocampus. Graves et al write that there are "There are interesting parallels between the memory mechanisms of a DNC and the functional capabilities of the mammalian hippocampus. DNC memory modification is fast and can be one-shot, resembling the associative long-term potentiation of hippocampal CA3 and CA1 synapses. The hippocampal dentate gyrus, a region known to support neurogenesis, has been proposed to increase representational sparsity, thereby enhancing memory capacity: usage-based memory allocation and sparse weightings may provide similar facilities in our model."
 |
The architecture shown in Figure 1 of Graves et al [115] and repeated above supports three different attentional mechanisms: "The first is content lookup, in which a key vector emitted by the controller is compared to the content of each location in memory according to a similarity measure (here, cosine similarity). The similarity scores determine a weighting that can be used by the read heads for associative recall or by the write head to modify an existing vector in memory. Importantly, a key that only partially matches the content of a memory location can still be used to attend strongly to that location.A second attention mechanism records transitions between consecutively written locations in an N × N temporal link matrix L. L[i, j] is close to 1 if i was the next location written after j, and is close to 0 otherwise. For any weighting w, the operation Lw smoothly shifts the focus forwards to the locations written after those emphasized in w, whereas LTw shifts the focus backwards. This gives a DNC the native ability to recover sequences in the order in which it wrote them, even when consecutive writes did not occur in adjacent time-steps.
The third form of attention allocates memory for writing. The usage of each location is represented as a number between 0 and 1, and a weighting that picks out unused locations is delivered to the write head. As well as automatically increasing with each write to a location, usage can be decreased after each read. This allows the controller to reallocate memory that is no longer required. The allocation mechanism is independent of the size and contents of the memory, meaning that DNCs can be trained to solve a task using one size of memory and later upgraded to a larger memory without retraining. In principle, this would make it possible to use an unbounded external memory by automatically increasing the number of locations every time the minimum usage of any location passes a certain threshold."
4 Papers, primarily authored by Etienne Koechlin, David Badre and their colleagues, relating to cognitive control and in particular hierarchical planning, internal goals, task management, and action selection. Badre's 2018 Trends in Cognitive Sciences paper provides the best review and attempt at reconciling the differences between the competing theories that were featured in Figure 2 in the 2008 paper in the same journal:
@article{BadreandNeeTiCS-18,
author = {David Badre and Derek Evan Nee},
title = {Frontal Cortex and the Hierarchical Control of Behavior},
journal = {Trends in Cognitive Sciences},
volume = {22},
number = {2},
year = {2018},
pages = {170-188},
abstract = {The frontal lobes are important for cognitive control, yet their functional organization remains controversial. An influential class of theory proposes that the frontal lobes are organized along their rostrocaudal axis to support hierarchical cognitive control. Here, we take an updated look at the literature on hierarchical control, with particular focus on the functional organization of lateral frontal cortex. Our review of the evidence supports neither a unitary model of lateral frontal function nor a unidimensional abstraction gradient. Rather, separate frontal networks interact via local and global hierarchical structure to support diverse task demands.}
}
@article{BadreTiCS-08,
title = {Cognitive control, hierarchy, and the rostro-caudal organization of the frontal lobes},
author = {David Badre},
journal = {Trends in Cognitive Sciences},
volume = {12},
number = {5},
pages = {193-200},
year = {2008},
abstract = {Cognitive control supports flexible behavior by selecting actions that are consistent with our goals and appropriate for our environment. The prefrontal cortex (PFC) has an established role in cognitive control, and research on the functional organization of PFC promises to contribute to our understanding of the architecture of control. A recently popular hypothesis is that the rostro-caudal axis of PFC supports a control hierarchy whereby posterior-to-anterior PFC mediates progressively abstract, higher-order control. This review discusses evidence for a rostro-caudal gradient of function in PFC and the theories proposed to account for these results, including domain generality in working memory, relational complexity, the temporal organization of behavior and abstract representational hierarchy. Distinctions among these frameworks are considered as a basis for future research.}
}
@article{BadreandDEspositoJCN-07,
author = {Badre, D. and D'Esposito, M.},
title = {Functional magnetic resonance imaging evidence for a hierarchical organization of the prefrontal cortex},
journal = {Journal Cognitive Neuroscience},
year = {2007},
volume = {19},
number = {12},
pages = {2082-2099},
abstract = {The prefrontal cortex (PFC) is central to flexible and organized action. Recent theoretical and empirical results suggest that the rostro-caudal axis of the frontal lobes may reflect a hierarchical organization of control. Here, we test whether the rostro-caudal axis of the PFC is organized hierarchically, based on the level of abstraction at which multiple representations compete to guide selection of action. Four functional magnetic resonance imaging (fMRI) experiments parametrically manipulated the set of task-relevant (a) responses, (b) features, (c) dimensions, and (d) overlapping cue-to-dimension mappings. A systematic posterior to anterior gradient was evident within the PFC depending on the manipulated level of representation. Furthermore, across four fMRI experiments, activation in PFC subregions was consistent with the sub- and superordinate relationships that define an abstract representational hierarchy. In addition to providing further support for a representational hierarchy account of the rostro-caudal gradient in the PFC, these data provide important empirical constraints on current theorizing about control hierarchies and the PFC.}
}
@article{KoechlinandJubaultNEURON-06,
title = {Broca's Area and the Hierarchical Organization of Human Behavior},
author = {Koechlin, Etienne and Jubault, Thomas},
journal = {Neuron},
volume = 50,
issue = 6,
year = 2006,
pages = {963-974},
abstract = {The prefrontal cortex subserves executive control, i.e., the organization of action or thought in relation to internal goals. This brain region hosts a system of executive processes extending from premotor to the most anterior prefrontal regions that governs the temporal organization of behavior. Little is known, however, about the prefrontal executive system involved in the hierarchical organization of behavior. Here, we show using magnetic resonance imaging in humans that the posterior portion of the prefrontal cortex, including Broca's area and its homolog in the right hemisphere, contains a system of executive processes that control start and end states and the nesting of functional segments that combine in hierarchically organized action plans. Our results indicate that Broca's area and its right homolog process hierarchically structured behaviors regardless of their temporal organization, suggesting a fundamental segregation between prefrontal executive systems involved in the hierarchical and temporal organization of goal-directed behaviors.},
}
@article{KoechlinandSummerfieldTiCS-07,
author = {Koechlin, E. and Summerfield, C.},
title = {An information theoretical approach to prefrontal executive function},
journal = {Trends in Cognitive Science},
year = {2007},
volume = {11},
number = {6},
pages = {229-235},
abstract = {The prefrontal cortex subserves executive control--that is, the ability to select actions or thoughts in relation to internal goals. Here, we propose a theory that draws upon concepts from information theory to describe the architecture of executive control in the lateral prefrontal cortex. Supported by evidence from brain imaging in human subjects, the model proposes that action selection is guided by hierarchically ordered control signals, processed in a network of brain regions organized along the anterior-posterior axis of the lateral prefrontal cortex. The theory clarifies how executive control can operate as a unitary function, despite the requirement that information be integrated across multiple distinct, functionally specialized prefrontal regions.}
}
@article{KoechlinetalPNAS-00,
journal = {Proceedings of the National Academy of Sciences},
author = {Koechlin, Etienne and Corrado, Gregory and Pietrini, Pietro and Grafman, Jordan},
title = {Dissociating the role of the medial and lateral anterior prefrontal cortex in human planning},
volume = 97,
issue = 13,
year = 2000,
pages = {7651-7656},
abstract = {The anterior prefrontal cortex is known to subserve higher cognitive functions such as task management and planning. Less is known, however, about the functional specialization of this cortical region in humans. Using functional MRI, we report a double dissociation: the medial anterior prefrontal cortex, in association with the ventral striatum, was engaged preferentially when subjects executed tasks in sequences that were expected, whereas the polar prefrontal cortex, in association with the dorsolateral striatum, was involved preferentially when subjects performed tasks in sequences that were contingent on unpredictable events. These results parallel the functional segregation previously described between the medial and lateral premotor cortex underlying planned and contingent motor control and extend this division to the anterior prefrontal cortex, when task management and planning are required. Thus, our findings support the assumption that common frontal organizational principles underlie motor and higher executive functions in humans.},
}
@article{KoechlinetalSCIENCE-03,
author = {Etienne Koechlin and Chryst\`{e}le Ody and Fr\'{e}d\'{e}rique Kouneiher},
title = {The architecture of cognitive control in the human prefrontal cortex},
journal = {Science},
volume = 302,
year = 2003,
pages = {1181-1185},
abstract = {The prefrontal cortex (PFC) subserves cognitive control: the ability to coordinate thoughts or actions in relation with internal goals. Its functional architecture, however, remains poorly understood. Using brain imaging in humans, we showed that the lateral PFC is organized as a cascade of executive processes from premotor to anterior PFC regions that control behavior according to stimuli, the present perceptual context, and the temporal episode in which stimuli occur, respectively. The results support an unified modular model of cognitive control that describes the overall functional organization of the human lateral PFC and has basic methodological and theoretical implications.},
}
@article{LeeetalCOGNITION-13,
author = {Lee, Eun-Kyung and Brown-Schmidt, Sarah and Watson, Duane G.},
title = {Ways of looking ahead: {H}ierarchical planning in language production},
journal = {Cognition},
volume = {129},
issue = {3},
year = {2013},
pages = {544-562},
abstract = {It is generally assumed that language production proceeds incrementally, with chunks of linguistic structure planned ahead of speech. Extensive research has examined the scope of language production and suggests that the size of planned chunks varies across contexts (Ferreira \& Swets, 2002; Wagner \& Jescheniak, 2010). By contrast, relatively little is known about the structure of advance planning, specifically whether planning proceeds incrementally according to the surface structure of the utterance, or whether speakers plan according to the hierarchical relationships between utterance elements. In two experiments, we examine the structure and scope of lexical planning in language production using a picture description task. Analyses of speech onset times and word durations show that speakers engage in hierarchical planning such that structurally dependent lexical items are planned together and that hierarchical planning occurs for both direct and indirect dependencies.},
}
@article{AlexanderandBrownNATURE-18,
author = {Alexander, William H.and Brown, Joshua W.},
title = {Frontal cortex function as derived from hierarchical predictive coding},
journal = {Scientific Reports},
year = {2018},
volume = {8},
issue = {1},
pages = {3843},
abstract = {The frontal lobes are essential for human volition and goal-directed behavior, yet their function remains unclear. While various models have highlighted working memory, reinforcement learning, and cognitive control as key functions, a single framework for interpreting the range of effects observed in prefrontal cortex has yet to emerge. Here we show that a simple computational motif based on predictive coding can be stacked hierarchically to learn and perform arbitrarily complex goal-directed behavior. The resulting Hierarchical Error Representation (HER) model simulates a wide array of findings from fMRI, ERP, single-units, and neuropsychological studies of both lateral and medial prefrontal cortex. By reconceptualizing lateral prefrontal activity as anticipating prediction errors, the HER model provides a novel unifying account of prefrontal cortex function with broad implications for understanding the frontal cortex across multiple levels of description, from the level of single neurons to behavior.},
}
5 Papers, primarily authored by Silvia Bunge and her colleagues at UC Berkeley, on identifying the neural substrates of analogical reasoning and describing an emerging consensus that the rostrolateral prefrontal cortex plays an important role in supporting analogical reasoning: The cascade model is an elegant cognitive control framework that makes predictions about the rostro–caudal organization of the PFC. In cascade, control resolves competition among alternative action representations based on mutual information with contextual information, also termed control signals. Crucially, the control signals relate to one another hierarchically, in that information is inherited from superordinate to subordinate levels, and separate signals are processed by spatially distinct regions along the rostro–caudal axis of the PFC. At the lowest level, sensory control is supported by premotor cortex and selects a motor response based on a sensory input. Next, contextual control, supported by posterior PFC, selects an action based on an environmental contextual cue. Episodic control, supported by anterior DLPFC, selects an action based on an ongoing temporal context. Finally, a highest level, branching control, sup- ported by FPC, selects action representations based on a pending temporal context. Thus, from caudal to rostral, regions of the PFC are distinguished based on their reliance on control signals that differ temporally, from immediate environment (sensory and context), to current temporal frame (episodic), to a pending frame (branching). – Excerpt from [20].
@article{BungeetalNEUROIMAGE-09,
author = {Bunge, S. A. and Helskog, E. H. and Wendelken, C.},
title = {{L}eft, but not right, rostrolateral prefrontal cortex meets a stringent test of the relational integration hypothesis},
journal = {Neuroimage},
year = {2009},
volume = {46},
number = {1},
pages = {338-342},
abstract = {Much of what is known about the function of human rostrolateral prefrontal cortex (RLPFC; lateral Brodmann area 10) has been pieced together from functional magnetic resonance imaging (fMRI) studies over the past decade. Christoff and colleagues previously reported on an fMRI localizer task involving relational integration that reliably engages RLPFC in individual participants (Smith, R., Keramatian, K., and Christoff, K. (2007). Localizing the rostrolateral prefrontal cortex at the individual level. NeuroImage, 36(4), 1387-1396). Here, we report on a modified version of this task that better controls for lower-level processing demands in the relational integration condition. Using identical stimulus arrays for our experimental and control conditions, we find that right RLPFC is sensitive to increasing relational processing demands, without being engaged specifically during relational integration. By contrast, left RLPFC is engaged only when participants must consider the higher-order relationship between two individual relations. We argue that the integration of disparate mental relations by left RLPFC is a fundamental process that supports higher-level cognition in humans.}
}
@article{BungeetalCEREBRAL-CORTEX-05,
author = {Bunge, S. A. and Wendelken, C. and Badre, D. and Wagner, A. D.},
title = {{A}nalogical reasoning and prefrontal cortex: evidence for separable retrieval and integration mechanisms},
journal = {Cerebral Cortex},
year = {2005},
volume = {15},
number = {3},
pages = {239-249},
abstract = {The present study examined the contributions of prefrontal cortex (PFC) subregions to two component processes underlying verbal analogical reasoning: semantic retrieval and integration. Event-related functional magnetic resonance imaging data were acquired while subjects performed propositional analogy and semantic decision tasks. On each trial, subjects viewed a pair of words (pair 1), followed by an instructional cue and a second word pair (pair 2). On analogy trials, subjects evaluated whether pair 2 was semantically analogous to pair 1. On semantic trials, subjects indicated whether the pair 2 words were semantically related to each other. Thus, analogy--but not semantic--trials required integration across multiple retrieved relations. To identify regions involved in semantic retrieval, we manipulated the associative strength of pair 1 words in both tasks. Anterior left inferior PFC (aLIPC) was modulated by associative strength, consistent with a role in controlled semantic retrieval. Left frontopolar cortex was insensitive to associative strength, but was more sensitive to integration demands than was aLIPC, consistent with a role in integrating the products of semantic retrieval to evaluate whether distinct representations are analogous. Right dorsolateral PFC exhibited a profile consistent with a role in response selection rather than retrieval or integration. These findings indicate that verbal analogical reasoning depends on multiple, PFC-mediated computations.}
}
@article{WendelkenetalHBM-12,
author = {Wendelken, C. and Chung, D. and Bunge, S. A.},
title = {{R}ostrolateral prefrontal cortex: domain-general or domain-sensitive?},
journal = {Human Brain Mapping},
year = {2012},
volume = {33},
number = {8},
pages = {1952-1963},
abstract = {The ability to jointly consider several structured mental representations, or relations, is fundamental to human cognition. Prior studies have consistently linked this capacity for relational integration to rostrolateral prefrontal cortex (RLPFC). Here, we sought to test two competing hypotheses: (1) RLPFC processes relations in a domain-general manner, interacting with different brain regions as a function of the type of lower-level relations that must be integrated; or (2) A dorsal-ventral gradient exists within RLPFC, such that relational integration in the visuospatial domain involves relatively more dorsal RLPFC than integration in the semantic domain. To this end, we examined patterns of fMRI activation and functional connectivity during performance of visuospatial and semantic variants of a relational matching task. Across the two task variants, the regions that were most strongly engaged during relational comparison were left RLPFC and left intraparietal sulcus (IPS). Within left RLPFC, there was considerable overlap in activation for the semantic and visuospatial tasks. However, visuospatial task activation peaks were located dorsally to the semantic task peaks. In addition, RLPFC exhibited differential functional connectivity on the two tasks, interacting with different brain regions as a function of the type of relations being compared. While neurons throughout RLPFC may share the function of integrating diverse inputs, individual RLPFC neurons may have privileged access to particular representations depending on their anatomical inputs, organized along a dorsal-ventral gradient. Thus, RLPFC is well-positioned as a locus of abstraction from concrete, domain-specific details to the general principles and rules that enable higher-level cognition.}
}
@article{BassoketalJEPLMC-12,
author = {Bassok, Miriam and Holyoak, Keith and Dunbar, Kevin N.},
journal = {Journal of Experimental Psychology. Learning, Memory \& Cognition},
number = {2},
pages = {261-263},
title = {Introduction to the Special Section on the Neural Substrate of Analogical Reasoning and Metaphor Comprehension.},
volume = {38},
year = {2012},
abstract = {The special section on the neural substrate of relational reasoning includes 4 articles that address the processes and brain regions involved in analogical reasoning (Green, Kraemer, Fugelsang, Gray, \& Dunbar, 2011; Maguire, McClelland, Donovan, Tiliman, \& Krawczyk, 2011) and in metaphor comprehension (Chettih, Durgin,\& Grodner, 2011; Prat, Mason,\& Just, 2011). We see this work as an example of how neuroscience approaches to cognition can lead to increased understanding of cognitive processes. In this brief introduction, we first situate the 4 articles in the context of prior cognitive neuroscience work on relational reasoning. We then highlight the main issues explored in these articles: different sources of complexity and difficulty in relational processing, potential differences between the roles of the 2 hemispheres, and the impact of individual differences in various cognitive abilities. The 4 articles illustrate a range of methodologies, including functional magnetic resonance},
}
6 On the basis of data from neuroanatomy, neurophysiology, and neuroimaging, a biologically plausible model is developed to illustrate the neural mechanisms of learning from instructions. The model consists of two complementary learning pathways. The slow-learning parietal pathway carries out simple or habitual stimulus–response (S-R) mappings, whereas the fast-learning hippocampal pathway implements novel S-R rules. Specifically, the hippocampus can rapidly encode arbitrary S-R associations, and stimulus-cued responses are later recalled into the basal ganglia-gated PFC to bias response selection in the premotor and motor cortices. The interactions between the two model learning pathways explain how instructions can override habits and how automaticity can be achieved through motor consolidation." – excerpt from the abstract of [142]
7 In [132], Herculano-Houzel shows that the numbers of neurons in the cerebral cortex and cerebellum are directly correlated across 19 mammalian species of four different orders, including humans, and increase concertedly in a similar fashion both within and across the orders Eulipotyphla (Insectivora), Rodentia, Scandentia and Primata, such that on average a ratio of 3.6 neurons in the cerebellum to every neuron in the cerebral cortex is maintained across species.
8 Excerpts from the third eddition of O'Reilly et al [190] Computational Cognitive Neuroscience relating the cytoarchitecture and network characteristics of the primate brain:
Bidirectional excitatory dynamics are produced by the pervasive bidirectional (e.g., bottom-up and top-down or feedforward and feedback) connectivity in the neocortex. The ability of information to flow in all directions throughout the brain is critical for understanding phenomena like our ability to focus on the task at hand and not get distracted by irrelevant incoming stimuli (did my email inbox just beep??), and our ability to resolve ambiguity in inputs by bringing higher-level knowledge to bear on lower-level processing stages. For example, if you are trying to search for a companion in a big crowd of people (e.g., at a sporting event or shopping mall), you can maintain an image of what you are looking for (e.g., a red jacket), which helps to boost the relevant processing in lower-level stages. The overall effects of bidirectional connectivity can be summarized in terms of an attractor dynamic or multiple constraint satisfaction, where the network can start off in a variety of different states of activity, and end up getting "sucked into" a common attractor state, representing a cleaned-up, stable interpretation of a noisy or ambiguous input pattern.Inhibitory competition, mediated by specialized inhibitory interneurons is important for providing dynamic regulation of overall network activity, which is especially important when there are positive feedback loops between neurons as in the case of bidirectional connectivity. The existence of epilepsy in the human neocortex indicates that achieving the right balance between inhibition and excitation is difficult -- the brain obtains so many benefits from this bidirectional excitation that it apparently lives right on the edge of controlling it with inhibition. Inhibition gives rise to sparse distributed representations (having a relatively small percentage of neurons active at a time, e.g., 15% or so), which have numerous advantages over distributed representations that have many neurons active at a time. In addition, we'll see in the Learning Chapter that inhibition plays a key role in the learning process, analogous to the Darwinian "survival of the fittest" dynamic, as a result of the competitive dynamic produced by inhibition.
The cortex is composed of roughly 85% excitatory neurons (mainly pyramidal neurons, but also stellate cells in layer 4), and 15% inhibitory interneurons (Figure 3.1). We focus primarily on the excitatory pyramidal neurons, which perform the bulk of the information processing in the cortex. Unlike the local inhibitory interneurons, they engage in long-range connections between different cortical areas, and it is clear that learning takes place in the synapses between these excitatory neurons (evidence is more mixed for the inhibitory neurons). The inhibitory neurons can be understood as "cooling off" the excitatory heat generated by the pyramidal neurons, much like the cooling system (radiator and coolant) in a car engine. Without these inhibitory interneurons, the system would overheat with excitation and lock up in epileptic seizures (this is easily seen by blocking inhibitory GABA channels, for example). There are, however, areas outside of the cortex (e.g., the basal ganglia and cerebellum) where important information processing does take place via inhibitory neurons, and certainly some researchers will object to this stark division of labor even within cortex, but it is nevertheless a very useful simplification.
9 Here is a collection of papers describing interesting computational models that relate to Hebbian cell assemblies:
@article {Papadimitriou14464,
author = {Papadimitriou, Christos H. and Vempala, Santosh S. and Mitropolsky, Daniel and Collins, Michael and Maass, Wolfgang},
title = {Brain computation by assemblies of neurons},
journal = {Proceedings of the National Academy of Sciences},
publisher = {National Academy of Sciences},
volume = {117},
number = {25},
year = {2020},
pages = {14464-14472},
abstract = {Our expanding understanding of the brain at the level of neurons and synapses, and the level of cognitive phenomena such as language, leaves a formidable gap between these two scales. Here we introduce a computational system which promises to bridge this gap: the Assembly Calculus. It encompasses operations on assemblies of neurons, such as project, associate, and merge, which appear to be implicated in cognitive phenomena, and can be shown, analytically as well as through simulations, to be plausibly realizable at the level of neurons and synapses. We demonstrate the reach of this system by proposing a brain architecture for syntactic processing in the production of language, compatible with recent experimental results.Assemblies are large populations of neurons believed to imprint memories, concepts, words, and other cognitive information. We identify a repertoire of operations on assemblies. These operations correspond to properties of assemblies observed in experiments, and can be shown, analytically and through simulations, to be realizable by generic, randomly connected populations of neurons with Hebbian plasticity and inhibition. Assemblies and their operations constitute a computational model of the brain which we call the Assembly Calculus, occupying a level of detail intermediate between the level of spiking neurons and synapses and that of the whole brain. The resulting computational system can be shown, under assumptions, to be, in principle, capable of carrying out arbitrary computations. We hypothesize that something like it may underlie higher human cognitive functions such as reasoning, planning, and language. In particular, we propose a plausible brain architecture based on assemblies for implementing the syntactic processing of language in cortex, which is consistent with recent experimental results.},
}
@article{TetzlaffetalNATURE-15,
author = {Tetzlaff, Christian and Dasgupta, Sakyasingha and Kulvicius, Tomas and W{\:{o}}rg{\:{o}}tter, Florentin},
title = {The Use of Hebbian Cell Assemblies for Nonlinear Computation},
journal = {Scientific Reports},
year = {2015},
volume = {5},
issue = {1},
pages = {12866},
abstract = {When learning a complex task our nervous system self-organizes large groups of neurons into coherent dynamic activity patterns. During this, a network with multiple, simultaneously active and computationally powerful cell assemblies is created. How such ordered structures are formed while preserving a rich diversity of neural dynamics needed for computation is still unknown. Here we show that the combination of synaptic plasticity with the slower process of synaptic scaling achieves (i) the formation of cell assemblies and (ii) enhances the diversity of neural dynamics facilitating the learning of complex calculations. Due to synaptic scaling the dynamics of different cell assemblies do not interfere with each other. As a consequence, this type of self-organization allows executing a difficult, six degrees of freedom, manipulation task with a robot where assemblies need to learn computing complex non-linear transforms and - for execution - must cooperate with each other without interference. This mechanism, thus, permits the self-organization of computationally powerful sub-structures in dynamic networks for behavior control.},
}
@article{MaasandMarkramJoCSS-04,
author = {Wolfgang Maass and Henry Markram},
title = {On the computational power of circuits of spiking neurons},
journal = {Journal of Computer and System Sciences},
volume = {69},
number = {4},
year = {2004},
pages = {593-616},
abstract = {Complex real-time computations on multi-modal time-varying input streams are carried out by generic cortical microcircuits. Obstacles for the development of adequate theoretical models that could explain the seemingly universal power of cortical microcircuits for real-time computing are the complexity and diversity of their computational units (neurons and synapses), as well as the traditional emphasis on offline computing in almost all theoretical approaches towards neural computation. In this article, we initiate a rigorous mathematical analysis of the real-time computing capabilities of a new generation of models for neural computation, liquid state machines, that can be implemented with - in fact benefit from - diverse computational units. Hence, realistic models for cortical microcircuits represent special instances of such liquid state machines, without any need to simplify or homogenize their diverse computational units. We present proofs of two theorems about the potential computational power of such models for real-time computing, both on analog input streams and for spike trains as inputs.}
}
@incollection{MaassLIQUID-10,
author = {W. Maass},
title = {Liquid State Machines: Motivation, Theory, and Applications},
booktitle = {Computability in Context: Computation and Logic in the Real World},
publisher = {Imperial College Press},
editor = {B. Cooper and A. Sorbi},
year = {2010},
pages = {275-296},
abstract = {The Liquid State Machine (LSM) has emerged as a computational model that is more adequate than the Turing machine for describing computations in biological networks of neurons. Characteristic features of this new model are (i) that it is a model for adaptive computational systems, (ii) that it provides a method for employing randomly connected circuits, or eve "found" physical objects for meaningful computations, (iii) that it provides a theoretical context where heterogeneous, rather than stereotypical, local gates or processors increase the computational power of a circuit, (iv) that it provides a method for multiplexing different computations (on a common input) within the same circuit. This chapter reviews the motivation for this model, its theoretical background, and current work on implementations of this model in innovative artificial computing devices.}
}
10 "The role of curiosity has been widely studied in the context of solving tasks with sparse rewards. In our opinion, curiosity has two other fundamental uses. Curiosity helps an agent explore its environment in the quest for new knowledge (a desirable characteristic of exploratory behavior is that it should improve as the agent gains more knowledge). Further, curiosity is a mechanism for an agent to learn skills that might be helpful in future scenarios. In this paper, we evaluate the effectiveness of our curiosity formulation in all three of these roles."
@article{PathaketalCoRR-17,
author = {Deepak Pathak and Pulkit Agrawal and Alexei A. Efros and Trevor Darrell},
title = {Curiosity-driven Exploration by Self-supervised Prediction},
journal = {CoRR},
volume = {arXiv:1705.05363},
year = {2017},
abstract = {In many real-world scenarios, rewards extrinsic to the agent are extremely sparse, or absent altogether. In such cases, curiosity can serve as an intrinsic reward signal to enable the agent to explore its environment and learn skills that might be useful later in its life. We formulate curiosity as the error in an agent's ability to predict the consequence of its own actions in a visual feature space learned by a self-supervised inverse dynamics model. Our formulation scales to high-dimensional continuous state spaces like images, bypasses the difficulties of directly predicting pixels, and, critically, ignores the aspects of the environment that cannot affect the agent. The proposed approach is evaluated in two environments: VizDoom and Super Mario Bros. Three broad settings are investigated: 1) sparse extrinsic reward, where curiosity allows for far fewer interactions with the environment to reach the goal; 2) exploration with no extrinsic reward, where curiosity pushes the agent to explore more efficiently; and 3) generalization to unseen scenarios (e.g. new levels of the same game) where the knowledge gained from earlier experience helps the agent explore new places much faster than starting from scratch.}
}
11 Contrastive Hebbian learning (CHL) updates the synaptic weights based on the steady states of neurons in two different phases: one with the output neurons clamped to the desired values and the other with the output neurons free. Clamping the output neurons causes the hidden neurons to change their activities, and this change constitutes the basis for the CHL update rule:
@article{XieandSeungNC-03,
author = {Xie, X. and Seung, H. S.},
title = {{{E}quivalence of backpropagation and contrastive {H}ebbian learning in a layered network}},
journal = {Neural Computation},
volume = {15},
number = {2},
year = {2003},
pages = {441-454},
abstract = {Backpropagation and contrastive Hebbian learning are two methods of training networks with hidden neurons. Backpropagation computes an error signal for the output neurons and spreads it over the hidden neurons. Contrastive Hebbian learning involves clamping the output neurons at desired values and letting the effect spread through feedback connections over the entire network. To investigate the relationship between these two forms of learning, we consider a special case in which they are identical: a multilayer perceptron with linear output units, to which weak feedback connections have been added. In this case, the change in network state caused by clamping the output neurons turns out to be the same as the error signal spread by backpropagation, except for a scalar prefactor. This suggests that the functionality of backpropagation can be realized alternatively by a Hebbian-type learning algorithm, which is suitable for implementation in biological networks.}
}
12 Papers concerning the role of the hippocampus in supporting memory, learning and cell-assembly activation and inference:
@book{Buzsaki2006,
title = {{Rhythms of the Brain}},
author = {Buzs\'{a}ki, Gy\"{o}rgy},
publisher = {Oxford University Press},
year = 2006,
abstract = {Studies of mechanisms in the brain that allow complicated things to happen in a coordinated fashion have produced some of the most spectacular discoveries in neuroscience. This book provides eloquent support for the idea that spontaneous neuron activity, far from being mere noise, is actually the source of our cognitive abilities. It takes a fresh look at the co-evolution of structure and function in the mammalian brain, illustrating how self-emerged oscillatory timing is the brains fundamental organizer of neuronal information. The small world-like connectivity of the cerebral cortex allows for global computation on multiple spatial and temporal scales. The perpetual interactions among the multiple network oscillators keep cortical systems in a highly sensitive metastable state and provide energy-efficient synchronizing mechanisms via weak links. In a sequence of cycles, Gyorgy Buzsaki guides the reader from the physics of oscillations through neuronal assembly organization to complex cognitive processing and memory storage. His clear, fluid writing accessible to any reader with some scientific knowledge is supplemented by extensive footnotes and references that make it just as gratifying and instructive a read for the specialist. The coherent view of a single author who has been at the forefront of research in this exciting field, this volume is essential reading for anyone interested in our rapidly evolving understanding of the brain.},
}
@article{BuzsakiHIPPOCAMPUS-15,
author = {Gy\"{o}rgy Buzs\`{a}ki},
title = {Hippocampal sharp wave-ripple: A cognitive biomarker for episodic memory and planning},
journal = {Hippocampus},
publisher = {John Wiley and Sons Inc.},
year = {2015},
volume = {25},
issue = {10},
pages = {1073-1188},
abstract = {Sharp wave ripples (SPW-Rs) represent the most synchronous population pattern in the mammalian brain. Their excitatory output affects a wide area of the cortex and several subcortical nuclei. SPW-Rs occur during ``off-line'' states of the brain, associated with consummatory behaviors and non-REM sleep, and are influenced by numerous neurotransmitters and neuromodulators. They arise from the excitatory recurrent system of the CA3 region and the SPW-induced excitation brings about a fast network oscillation (ripple) in CA1. The spike content of SPW-Rs is temporally and spatially coordinated by a consortium of interneurons to replay fragments of waking neuronal sequences in a compressed format. SPW-Rs assist in transferring this compressed hippocampal representation to distributed circuits to support memory consolidation; selective disruption of SPW-Rs interferes with memory. Recently acquired and pre-existing information are combined during SPW-R replay to influence decisions, plan actions and, potentially, allow for creative thoughts. In addition to the widely studied contribution to memory, SPW-Rs may also affect endocrine function via activation of hypothalamic circuits. Alteration of the physiological mechanisms supporting SPW-Rs leads to their pathological conversion, ``p-ripples,'' which are a marker of epileptogenic tissue and can be observed in rodent models of schizophrenia and Alzheimer's Disease. Mechanisms for SPW-R genesis and function are discussed in this review.},
}
@article{CarretalNATURE-NEUROSCIENCE-11,
title = {Hippocampal replay in the awake state: a potential substrate for memory consolidation and retrieval},
author = {Carr, Margaret F and Jadhav, Shantanu P and Frank, Loren M},
journal = {Nature neuroscience},
volume = {14},
number = {2},
pages = {147},
year = {2011},
publisher = {Nature Publishing Group},
abstact = {Various cognitive functions have long been known to require the hippocampus. Recently, progress has been made in identifying the hippocampal neural activity patterns that implement these functions. One such pattern is the sharp wave–ripple (SWR), an event associated with highly synchronous neural firing in the hippocampus and modulation of neural activity in distributed brain regions. Hippocampal spiking during SWRs can represent past or potential future experience, and SWR-related interventions can alter subsequent memory performance. These findings and others suggest that SWRs support both memory consolidation and memory retrieval for processes such as decision-making. In addition, studies have identified distinct types of SWR based on representational content, behavioural state and physiological features. These various findings regarding SWRs suggest that different SWR types correspond to different cognitive functions, such as retrieval and consolidation. Here, we introduce another possibility — that a single SWR may support more than one cognitive function. Taking into account classic psychological theories and recent molecular results that suggest that retrieval and consolidation share mechanisms, we propose that the SWR mediates the retrieval of stored representations that can be utilized immediately by downstream circuits in decision-making, planning, recollection and/or imagination while simultaneously initiating memory consolidation processes.}
}
@article{KumaranandMcClellandPR-12,
author = {Kumaran, Dharshan and McClelland, James L.},
title = {Generalization Through the Recurrent Interaction of Episodic Memories: A Model of the Hippocampal System},
journal = {Psychology Review},
publisher = {American Psychological Association},
volume = {119},
issue = {3},
year = {2012},
pages = {573-616},
abstract = {In this article, we present a perspective on the role of the hippocampal system in generalization, instantiated in a computational model called REMERGE (recurrency and episodic memory results in generalization). We expose a fundamental, but neglected, tension between prevailing computational theories that emphasize the function of the hippocampus in pattern separation (Marr, 1971; McClelland, McNaughton, \& O'Reilly, 1995), and empirical support for its role in generalization and flexible relational memory (Cohen \& Eichenbaum, 1993; Eichenbaum, 1999). Our account provides a means by which to resolve this conflict, by demonstrating that the basic representational scheme envisioned by complementary learning systems theory (McClelland et al., 1995), which relies upon orthogonalized codes in the hippocampus, is compatible with efficient generalization - as long as there is recurrence rather than unidirectional flow within the hippocampal circuit or, more widely, between the hippocampus and neocortex. We propose that recurrent similarity computation, a process that facilitates the discovery of higher-order relationships between a set of related experiences, expands the scope of classical exemplar-based models of memory (e.g., Nosofsky, 1984) and allows the hippocampus to support generalization through interactions that unfold within a dynamically created memory space.},
}
A derivation trace consists of the subgoal structure of the problem, a pointer to each rule used in decomposing the problem at each node of the tree and the final solution. Figure 2a in [123] shows the derivation tree for a program to find the most frequent word in a file.
14 "Philosophers have used the term 'consciousness' for four main topics: knowledge in general, intentionality, introspection (and the knowledge it specifically generates) and phenomenal experience ... Something within one's mind is 'introspectively conscious' just in case one introspects it (or is poised to do so). Introspection is often thought to deliver one's primary knowledge of one's mental life. An experience or other mental entity is 'phenomenally conscious' just in case there is 'something it is like' for one to have it. The clearest examples are: perceptual experience, such as tastings and seeings; bodily-sensational experiences, such as those of pains, tickles and itches; imaginative experiences, such as those of one's own actions or perceptions; and streams of thought, as in the experience of thinking 'in words' or 'in images'. Introspection and phenomenality seem independent, or dissociable, although this is controversial." (SOURCE)
15 "Daniel Dennett describes consciousness as an account of the various calculations occurring in the brain at close to the same time. He compares consciousness to an academic paper that is being developed or edited in the hands of multiple people at one time, the "multiple drafts" theory of consciousness. In this analogy, "the paper" exists even though though there is no single, unified paper. When people report on their inner experiences, Dennett considers their reports to be more like theorizing than like describing. These reports may be informative, he says, but a psychologist is not take them at face value. Dennett describes several phenomena that show that perception is more limited and less reliable than we perceive it to be." (SOURCE)
16 Here the papers that led to my disillusionment with Fuster's hierarchy as the architectural foundation for the programmer's apprentice:
@article{AdamsetalBSF-13,
author = {Adams, Rick A. and Shipp, Stewart and Friston, Karl J.},
title = {Predictions not commands: active inference in the motor system},
journal = {Brain structure \& function},
year = {2013},
publisher = {Springer-Verlag},
volume = {218},
issue = {3},
pages = {611-643},
abstract = {The descending projections from motor cortex share many features with top-down or backward connections in visual cortex; for example, corticospinal projections originate in infragranular layers, are highly divergent and (along with descending cortico-cortical projections) target cells expressing NMDA receptors. This is somewhat paradoxical because backward modulatory characteristics would not be expected of driving motor command signals. We resolve this apparent paradox using a functional characterisation of the motor system based on Helmholtz's ideas about perception; namely, that perception is inference on the causes of visual sensations. We explain behaviour in terms of inference on the causes of proprioceptive sensations. This explanation appeals to active inference, in which higher cortical levels send descending proprioceptive predictions, rather than motor commands. This process mirrors perceptual inference in sensory cortex, where descending connections convey predictions, while ascending connections convey prediction errors. The anatomical substrate of this recurrent message passing is a hierarchical system consisting of functionally asymmetric driving (ascending) and modulatory (descending) connections: an arrangement that we show is almost exactly recapitulated in the motor system, in terms of its laminar, topographic and physiological characteristics. This perspective casts classical motor reflexes as minimising prediction errors and may provide a principled explanation for why motor cortex is agranular.},
}
@article{HuntandHaydenNRM-17,
author = {Hunt, Laurence T. and Hayden, Benjamin Y.},
title = {A distributed, hierarchical and recurrent framework for reward-based choice},
journal = {Nature Reviews Neuroscience},
year = {2017},
volume = {18},
issue = {3},
pages = {172-182},
abstract = {Many accounts of reward-based choice argue for distinct component processes that are serial and functionally localized. In this Opinion article, we argue for an alternative viewpoint, in which choices emerge from repeated computations that are distributed across many brain regions. We emphasize how several features of neuroanatomy may support the implementation of choice, including mutual inhibition in recurrent neural networks and the hierarchical organization of timescales for information processing across the cortex. This account also suggests that certain correlates of value are emergent rather than represented explicitly in the brain.},
}
@article{FristonNEURON-11,
title = {What Is Optimal about Motor Control?},
journal = {Neuron},
volume = {72},
number = {3},
pages = {488-498},
year = {2011},
author = {Karl Friston},
abstract = {This article poses a controversial question: is optimal control theory useful for understanding motor behavior or is it a misdirection? This question is becoming acute as people start to conflate internal models in motor control and perception (Poeppel et al., 2008, Hickok et al., 2011). However, the forward models in motor control are not the generative models used in perceptual inference. This Perspective tries to highlight the differences between internal models in motor control and perception and asks whether optimal control is the right way to think about things. The issues considered here may have broader implications for optimal decision theory and Bayesian approaches to learning and behavior in general.}
}
@article{HickoketalNEURON-11,
author = {Hickok, Gregory and Houde, John and Rong, Feng},
title = {Sensorimotor integration in speech processing: computational basis and neural organization},
journal = {Neuron},
year = {2011},
volume = {69},
issue = {3},
pages = {407-422},
abstract = {Sensorimotor integration is an active domain of speech research and is characterized by two main ideas, that the auditory system is critically involved in speech production and that the motor system is critically involved in speech perception. Despite the complementarity of these ideas, there is little crosstalk between these literatures. We propose an integrative model of the speech-related ``dorsal stream'' in which sensorimotor interaction primarily supports speech production, in the form of a state feedback control architecture. A critical component of this control system is forward sensory prediction, which affords a natural mechanism for limited motor influence on perception, as recent perceptual research has suggested. Evidence shows that this influence is modulatory but not necessary for speech perception. The neuroanatomy of the proposed circuit is discussed as well as some probable clinical correlates including conduction aphasia, stuttering, and aspects of schizophrenia.},
}
17 My interest was spurred by more than idle curiosity. I was looking for a better explanation of why I am uncomfortable with blithely adding Monte Carlo tree search to the programmer's apprentice architecture and interested in pursuing my intuition that something akin to analogy is responsible for significantly reducing the amount of time expert programmers spend in solving novel problems by effectively reducing the search space to a more tractable fraction of the space of possible solutions. Thinking about my discomfort with invoking Monte Carlo tree search brought to mind Sidney Harris's cartoon in the New York Times lampooning Einstein standing before a blackboard full of equations and pointing to a gap in his understanding that he had filled in with "a miracle occurs" and his colleague, pointing to the same gap, suggested, "I think you should be more explicit here."
18 Terrence Deacon is a Professor of Anthropology, member of the Cognitive Science Faculty at the University of California, Berkeley, and a pioneer in using cellular-molecular neurobiology to the study of semiotic processes underlying animal and human communication, especially language. In his 1997 book [71] entitled the Symbolic Species: The Co-evolution of Language and the Brain, Deacon argues the case that the extraordinary behavioral flexibility of the human brain is a consequence of our use and refinement signs as a means of communication, where, in the field of semiotics, a sign is defined as anything that communicates a meaning that is not the sign itself to the sign's interpreter. The following excerpt from [71] provides a glimpse of Deacon's main argument – also revelant to Deacon's argument is the work of Philip Lieberman [169, 168]:
A subtle modification of the Darwinian theory of natural selection, first outlined almost exactly a century ago by the American psychologist James Mark Baldwin is the key to understanding the process that could have produced these changes. This variation on Darwinism is now often called "Baldwinian evolution," though there is nothing non-Darwinian about the process. Baldwin suggested that learning and behavioral flexibility can play a role in amplifying and biasing natural selection because these abilities enable individuals to modify the context of natural selection that affects their future kin – see Figure 3.Behavioral flexibility enables organisms to move into niches that differ from those their ancestors occupied, with the consequence that succeeding generations will face a new set of selection pressures. For example, an ability to utilize resources from colder environments may initially be facilitated by seasonal migratory patterns, but if adaptation to this new niche becomes increasingly important, it will favor the preservation of any traits in subsequent generations that increase tolerance to cold, such as the deposition of subcutaneous fat, the growth of insulating hair, or the ability to hibernate during part of the year.
Figure 3: Schematic diagram of processes underlying Baldwinian selection. Arrows pointing vertically depict three simultaneous transmission processes: genetic inheritance (left), social transmission by learning (middle), and persistence of physical changes in the environment produced by behavioral changes (right). Arrows pointing right indicate influences of genes on behavior and behaviors on the environment. Arrows pointing to the left indicate the effects of changed selection pressures on genes. The arrows for social transmission get thinner in each generation to indicate the reduced role of learning as a result of an increasing genetic influence to the behavior (indicated by arrows getting thicker from genes to behavior).
In summary, Baldwin's theory explains how behaviors can affect evolution, but without the necessity of claiming that responses to environmental demands acquired during one's lifetime could be passed directly on to one's offspring (a discredited mechanism for evolutionary change proposed by the early nineteenth-century French naturalist Jean Baptiste Lamarck). Baldwin proposed that by temporarily adjusting behaviors or physiological responses during its lifespan in response to novel conditions, an animal could produce irreversible changes in the adaptive context of future generations. Though no new genetic change is immediately produced in the process, the change in conditions will alter which among the existing or subsequently modified genetic predispositions will be favored in the future.

19 A collection of papers related to Donald Hebb's concept of cell assemblies:
@inproceedings{Braitenberg1978cellassemblies,
author = {Braitenberg, Valentino},
editor = {Heim, Roland and Palm, G{\"{u}}nther},
title = {Cell Assemblies in the Cerebral Cortex},
booktitle = {Theoretical Approaches to Complex Systems},
year = {1978},
publisher = {Springer Berlin Heidelberg},
address = {Berlin, Heidelberg},
pages = {171-188},
abstract = {To say that an animal responds to sensory stimuli may not be the most natural and efficient way to describe behaviour. Rather, it appears that animals most of the time react to situations, to opponents or things which they actively isolate from their environment, Situations, things, partners or opponents are, in a way, the terms of behaviour. It is legitimate, therefore, to ask what phenomena correspond to them in the internal activity of the brain, or, in other words: how are the meaningful chunks of experience "represented" in the brain?},
}
@article{BuzsakiandDraguhnSCIENCE-04,
author = {Buzs\'{a}ki, Gy\"{o}rgy and Draguhn, Andreas},
title = {Neuronal Oscillations in Cortical Networks},
journal = {Science},
volume = 304,
issue = 5679,
year = 2004,
pages = {1926-1929},
abstract = {Clocks tick, bridges and skyscrapers vibrate, neuronal networks oscillate. Are neuronal oscillations an inevitable by-product, similar to bridge vibrations, or an essential part of the brain's design? Mammalian cortical neurons form behavior-dependent oscillating networks of various sizes, which span five orders of magnitude in frequency. These oscillations are phylogenetically preserved, suggesting that they are functionally relevant. Recent findings indicate that network oscillations bias input selection, temporally link neurons into assemblies, and facilitate synaptic plasticity, mechanisms that cooperatively support temporal representation and long-term consolidation of information.},
}
@article{BuzsakiNEURON-10,
title = {Neural Syntax: Cell Assemblies, Synapsembles, and Readers},
author = {Gy{\"{o}}rgy Buzs{\'{a}}ki},
journal = {Neuron},
volume = {68},
number = {3},
year = {2010},
pages = {362-385},
abstract = {A widely discussed hypothesis in neuroscience is that transiently active ensembles of neurons, known as "cell assemblies," underlie numerous operations of the brain, from encoding memories to reasoning. However, the mechanisms responsible for the formation and disbanding of cell assemblies and temporal evolution of cell assembly sequences are not well understood. I introduce and review three interconnected topics, which could facilitate progress in defining cell assemblies, identifying their neuronal organization, and revealing causal relationships between assembly organization and behavior. First, I hypothesize that cell assemblies are best understood in light of their output product, as detected by "reader-actuator" mechanisms. Second, I suggest that the hierarchical organization of cell assemblies may be regarded as a neural syntax. Third, constituents of the neural syntax are linked together by dynamically changing constellations of synaptic weights ("synapsembles"). The existing support for this tripartite framework is reviewed and strategies for experimental testing of its predictions are discussed.}
}
@article{CanoltyetalPNAS-10,
title = {Oscillatory phase coupling coordinates anatomically dispersed functional cell assemblies},
author = {Canolty, Ryan T. and Ganguly, Karunesh and Kennerley, Steven W. and Cadieu, Charles F. and Koepsell, Kilian and Wallis, Jonathan D. and Carmena, Jose M.},
journal = {Proceedings of the National Academy of Sciences},
volume = 107,
issue = 40,
year = 2010,
pages = {17356-17361},
abstract = {Hebb proposed that neuronal cell assemblies are critical for effective perception, cognition, and action. However, evidence for brain mechanisms that coordinate multiple coactive assemblies remains lacking. Neuronal oscillations have been suggested as one possible mechanism for cell assembly coordination. Prior studies have shown that spike timing depends upon local field potential (LFP) phase proximal to the cell body, but few studies have examined the dependence of spiking on distal LFP phases in other brain areas far from the neuron or the influence of LFP--LFP phase coupling between distal areas on spiking. We investigated these interactions by recording LFPs and single-unit activity using multiple microelectrode arrays in several brain areas and then used a unique probabilistic multivariate phase distribution to model the dependence of spike timing on the full pattern of proximal LFP phases, distal LFP phases, and LFP--LFP phase coupling between electrodes. Here we show that spiking activity in single neurons and neuronal ensembles depends on dynamic patterns of oscillatory phase coupling between multiple brain areas, in addition to the effects of proximal LFP phase. Neurons that prefer similar patterns of phase coupling exhibit similar changes in spike rates, whereas neurons with different preferences show divergent responses, providing a basic mechanism to bind different neurons together into coordinated cell assemblies. Surprisingly, phase-coupling-based rate correlations are independent of interneuron distance. Phase-coupling preferences correlate with behavior and neural function and remain stable over multiple days. These findings suggest that neuronal oscillations enable selective and dynamic control of distributedfunctional cell assemblies.},
}
@book{Hebb1949,
author = {Hebb, Donald O.},
title = {The organization of behavior: {A} neuropsychological theory},
publisher = {Wiley},
address = {New York},
year = 1949,
abstract = {Donald Hebb pioneered many current themes in behavioural neuroscience. He saw psychology as a biological science, but one in which the organization of behaviour must remain the central concern. Through penetrating theoretical concepts, including the "cell assembly," "phase sequence," and "Hebb synapse," he offered a way to bridge the gap between cells, circuits and behaviour. He saw the brain as a dynamically organized system of multiple distributed parts, with roots that extend into foundations of development and evolutionary heritage. He understood that behaviour, as brain, can be sliced at various levels and that one of our challenges is to bring these levels into both conceptual and empirical register. He could move between theory and fact with an ease that continues to inspire both students and professional investigators. Although facts continue to accumulate at an accelerating rate in both psychology and neuroscience, and although these facts continue to force revision in the details of Hebb's earlier contributions, his overall insistence that we look at behaviour and brain together within a dynamic, relational and multilayered framework remains. His work touches upon current studies of population coding, contextual factors in brain representations, synaptic plasticity, developmental construction of brain/behaviour relations, clinical syndromes, deterioration of performance with age and disease, and the formal construction of connectionist models. The collection of papers in this volume represent these and related themes that Hebb inspired. We also acknowledge our appreciation for Don Hebb as teacher, colleague and friend.},
}
@article{MillerandZuckerNC-99,
author = {Miller, Douglas A. and Zucker, Steven W.},
title = {Computing with Self-excitatory Cliques: A Model and an Application to Hyperacuity-scale Computation in Visual Cortex},
journal = {Neural Computing},
publisher = {MIT Press},
volume = 11,
issue = 1,
year = 1999,
pages = {21-66},
address = {Cambridge, MA, USA},
abstract = {We present a model of visual computation based on tightly inter-connected cliques of pyramidal cells. It leads to a formal theory of cell assemblies, a specific relationship between correlated firing patterns and abstract functionality, and a direct calculation relating estimates of cortical cell counts to orientation hyperacuity. Our network architecture is unique in that (1) it supports a mode of computation that is both reliable and efficent; (2) the current-spike relations are modeled as an analog dynamical system in which the requisite computations can take place on the time scale required for an early stage of visual processing; and (3) the dynamics are triggered by the spatiotemporal response of cortical cells. This final point could explain why moving stimuli improve vernier sensitivity.}
}
@article{PalmetalBC-14,
author = {Palm, G{\"{u}}nther and Knoblauch, Andreas and Hauser, Florian and Sch{\"{u}}z, Almut},
title = {Cell assemblies in the cerebral cortex},
journal = {Biological Cybernetics},
year = {2014},
volume = {108},
issue = {5},
pages = {559-572},
abstract = {Donald Hebb's concept of cell assemblies is a physiology-based idea for a distributed neural representation of behaviorally relevant objects, concepts, or constellations. In the late 70s Valentino Braitenberg started the endeavor to spell out the hypothesis that the cerebral cortex is the structure where cell assemblies are formed, maintained and used, in terms of neuroanatomy (which was his main concern) and also neurophysiology. This endeavor has been carried on over the last 30 years corroborating most of his findings and interpretations. This paper summarizes the present state of cell assembly theory, realized in a network of associative memories, and of the anatomical evidence for its location in the cerebral cortex.},
}
@article{PulvermullerPiN-18,
author = {Friedemann Pulverm{\"{u}}ller},
title = {Neural reuse of action perception circuits for language, concepts and communication},
journal = {Progress in Neurobiology},
volume = {160},
year = {2018},
pages = {1-44},
abstract = {Neurocognitive and neurolinguistics theories make explicit statements relating specialized cognitive and linguistic processes to specific brain loci. These linking hypotheses are in need of neurobiological justification and explanation. Recent mathematical models of human language mechanisms constrained by fundamental neuroscience principles and established knowledge about comparative neuroanatomy offer explanations for where, when and how language is processed in the human brain. In these models, network structure and connectivity along with action- and perception-induced correlation of neuronal activity co-determine neurocognitive mechanisms. Language learning leads to the formation of action perception circuits (APCs) with specific distributions across cortical areas. Cognitive and linguistic processes such as speech production, comprehension, verbal working memory and prediction are modeled by activity dynamics in these APCs, and combinatorial and communicative-interactive knowledge is organized in the dynamics within, and connections between APCs. The network models and, in particular, the concept of distributionally-specific circuits, can account for some previously not well understood facts about the cortical 'hubs' for semantic processing and the motor system's role in language understanding and speech sound recognition. A review of experimental data evaluates predictions of the APC model and alternative theories, also providing detailed discussion of some seemingly contradictory findings. Throughout, recent disputes about the role of mirror neurons and grounded cognition in language and communication are assessed critically.}
}
@article{PulvermullerTiCS-13,
title = {How neurons make meaning: brain mechanisms for embodied and abstract-symbolic semantics},
author = {Friedemann Pulverm{\"{u}}ller},
journal = {Trends in Cognitive Sciences},
volume = {17},
number = {9},
year = {2013},
pages = {458-470},
abstract = {How brain structures and neuronal circuits mechanistically underpin symbolic meaning has recently been elucidated by neuroimaging, neuropsychological, and neurocomputational research. Modality-specific 'embodied' mechanisms anchored in sensorimotor systems appear to be relevant, as are 'disembodied' mechanisms in multimodal areas. In this paper, four semantic mechanisms are proposed and spelt out at the level of neuronal circuits: referential semantics, which establishes links between symbols and the objects and actions they are used to speak about; combinatorial semantics, which enables the learning of symbolic meaning from context; emotional-affective semantics, which establishes links between signs and internal states of the body; and abstraction mechanisms for generalizing over a range of instances of semantic meaning. Referential, combinatorial, emotional-affective, and abstract semantics are complementary mechanisms, each necessary for processing meaning in mind and brain.}
}
@article{PulvermulleretalBC-14,
author = {Pulverm{\"{u}}ller, F. and Garagnani, M. and Wennekers, T.},
title = {Thinking in circuits: toward neurobiological explanation in cognitive neuroscience},
journal = {Biological Cybernetics},
year = {2014},
volume = {108},
number = {5},
pages = {573-593},
abstract = {Cognitive theory has decomposed human mental abilities into cognitive (sub) systems, and cognitive neuroscience succeeded in disclosing a host of relationships between cognitive systems and specific structures of the human brain. However, an explanation of why specific functions are located in specific brain loci had still been missing, along with a neurobiological model that makes concrete the neuronal circuits that carry thoughts and meaning. Brain theory, in particular the Hebb-inspired neurocybernetic proposals by Braitenberg, now offers an avenue toward explaining brain-mind relationships and to spell out cognition in terms of neuron circuits in a neuromechanistic sense. Central to this endeavor is the theoretical construct of an elementary functional neuronal unit above the level of individual neurons and below that of whole brain areas and systems: the distributed neuronal assembly (DNA) or thought circuit (TC). It is shown that DNA/TC theory of cognition offers an integrated explanatory perspective on brain mechanisms of perception, action, language, attention, memory, decision and conceptual thought. We argue that DNAs carry all of these functions and that their inner structure (e.g., core and halo subcomponents), and their functional activation dynamics (e.g., ignition and reverberation processes) answer crucial localist questions, such as why memory and decisions draw on prefrontal areas although memory formation is normally driven by information in the senses and in the motor system. We suggest that the ability of building DNAs/TCs spread out over different cortical areas is the key mechanism for a range of specifically human sensorimotor, linguistic and conceptual capacities and that the cell assembly mechanism of overlap reduction is crucial for differentiating a vocabulary of actions, symbols and concepts.}
}
20 Active perception is the selecting of behaviors to increase information from the flow of data those behaviors produce in a particular environment. In other words, to understand the world, we move around and explore it—sampling the world through our senses to construct an understanding (perception) of the environment on the basis of that behavior (action). Within the construct of active perception, interpretation of sensory data is inherently inseparable from the behaviors required to capture that data. Action and perception are tightly coupled. This has been developed most comprehensively with respect to vision (active vision) where an agent (animal, robot, human, camera mount) changes position to improve the view of a specific object, or where an agent uses movement to perceive the environment (e.g., a robot avoiding obstacles). (SOURCE)
21 The corollary discharge theory (CD) of motion perception helps understand how the mind can detect motion through the visual system, even though the body is not moving. When a signal is sent from the motor cortex of the brain to the eye muscles, a copy of that signal (see efference copy) is sent through the brain as well. The brain does this in order to distinguish real movements in the visual world from our own body and eye movement. The original signal and copy signal are then believed to be compared somewhere in the brain. Such a structure has not yet been identified, but it is believed to be the Medial Superior Temporal Area (MST). The original signal and copy need to be compared in order to determine if the change in vision was caused by eye movement or movement in the world. (SOURCE)
22 These reciprocal connections are likely to include some portion of the arcuate fasciculus which is an association fiber tract connecting the caudal temporal cortex and inferior frontal lobe and is thought by some to be dedicated to enabling communication between Broca's and Wernicke's areas:
Historically, the arcuate fasciculus has been understood to connect two important areas for language use: Broca's area in the inferior frontal gyrus and Wernicke's area in the posterior superior temporal gyrus. The majority of scientists consider this to be an oversimplification; however, this model is still utilized because a satisfactory replacement has not been developed. The topographical relationships between independent measures of white matter and gray matter integrity suggest that rich developmental or environmental interactions influence brain structure and function. The presence and strength of such associations may elucidate pathophysiological processes influencing systems such as language and motor planning. (SOURCE)
23 If the apprentice only works with the AST representations of programs, the argument to jump could be the number of steps – forward or backward, in a depth-first traversal of the abstract syntax tree where an individual step jumps to the next expression in the tree if the number is positive or the previous expression if the number is negative, or to some default position, like the first or last expression, if the number is out of bounds.
24 The follow is an excerpt from Devlin et al [90] describing dataset that the authors collected to train the models described in their paper.
To create the training data, we first downloaded all Python projects from GitHub that were followed by at least 15 users and had permissive licenses (MIT/BSD/Apache), which amounted to 19,000 total repositories. We extracted every function from each Python source file as a code snippet. In all experiments presented here, each snippet was analyzed on its own without any surrounding context. All models explored in this paper only use static code representations, so each snippet must be parsable as an Abstract Syntax Tree (AST), but does not need to be runnable. Note that many of the extracted functions are member functions of some class, so although they can be parsed, they are not runnable without external context. We only kept snippets with between 5 and 300 nodes in their AST, which approximately corresponds to 1 to 40 lines of code. The average extracted snippet had 45 AST nodes and 6 lines of code. This data was carved into training, test, and validation at the repository level, to eliminate any overlap between training and test. We also filtered out any training snippet which overlapped with any test snippet by more than 5 lines. In total, we extracted 2,900,000 training snippets and held out 2,000 for test and 2,000 for validation.@inproceedings{DevlinetalICLR-18, title = {Semantic Code Repair using Neuro-Symbolic Transformation Networks}, author = {Jacob Devlin and Jonathan Uesato and Rishabh Singh and Pushmeet Kohli}, booktitle = {International Conference on Learning Representations}, year = {2018}, abstract = {We study the problem of semantic code repair, which can be broadly defined as automatically fixing non-syntactic bugs in source code. The majority of past work in semantic code repair assumed access to unit tests against which candidate repairs could be validated. In contrast, the goal here is to develop a strong statistical model to accurately predict both bug locations and exact fixes without access to information about the intended correct behavior of the program. Achieving such a goal requires a robust contextual repair model, which we train on a large corpus of real-world source code that has been augmented with synthetically injected bugs. Our framework adopts a two-stage approach where first a large set of repair candidates are generated by rule-based processors, and then these candidates are scored by a statistical model using a novel neural network architecture which we refer to as Share, Specialize, and Compete. Specifically, the architecture (1) generates a shared encoding of the source code using an RNN over the abstract syntax tree, (2) scores each candidate repair using specialized network modules, and (3) then normalizes these scores together so they can compete against one another in comparable probability space. We evaluate our model on a real-world test set gathered from GitHub containing four common categories of bugs. Our model is able to predict the exact correct repair 41\% of the time with a single guess, compared to 13\% accuracy for an attentional sequence-to-sequence model.} }
25 The term proprioception refers to stimuli that are produced and perceived within an organism, especially those connected with the position and movement of the body. SOURCE
26 Template filling is an efficient approach to extract and structure complex information from text. A template, also known as abstract schema, may be defined as selecting and narrowing down a domain of interest (e.g., biomedical literature related to a disease) to (1) generic information of interest (i.e., specific entities, relationships, and events), and (2) the form of the output of that information (i.e., slots that store information about the entities, relations, and events of interest).
27 I mentioned that I wanted to discourage you from focusing on natural language as the primary mode of communication between the apprentice and the assistant. However, in reading your proposal a second time, I am re-interpreting what you want to do is consider the tradeoffs involving signed versus spoken natural language. I think this is an excellent idea, and I believe it would be good for both teams – yours and Juliette, Mia and Div's – to meet regularly to discuss the issues relating to programming languages as an alternative or complement to natural language supplemented with the technical argot of computer science.
I think it would be interesting to (i) consider the potential benefit of using programs as the basis for computational analogies, and (ii) consider creating a suite of pair-programming signs that involve gestures on a touchpad or conventional monitor augmented with tracking. Another important issue concerns the role of grounding that I mentioned in my earlier message, both the consequences of the assistant having an impoverished grounding in the physical world of the programmer and the programmer having a relatively shallow grounding in the world of code and computing hardware compared with the grounding available to the assistant given its intimate experience of conventional computing hardware and software.
28 An answer to a question regarding the scope of problems that we aspire to versus the scope of those that it makes sense to attempt to solve:.
 |
29 Sakoku was the isolationist foreign policy of the Japanese Tokugawa shogunate under which, for a period of 214 years, relations and trade between Japan and other countries were severely limited, nearly all foreign nationals were barred from entering Japan and common Japanese people were kept from leaving the country. The policy was enacted by the shogunate government under Tokugawa Iemitsu through a number of edicts and policies from 1633 to 1639, and ended after 1853 when the American Black Ships commanded by Matthew Perry forced the opening of Japan to American (and, by extension, Western) trade through a series of treaties. SOURCE
30 BibTeX references and abstracts for the April 29 entry on using pretrained transformers for grounding interactive intelligent agents:
@article{HilletalCoRR-20,
author = {Felix Hill and Olivier Tieleman and Tamara von Glehn and Nathaniel Wong and Hamza Merzic and Stephen Clark},
title = {Grounded Language Learning Fast and Slow},
journal = {CoRR},
volume = {arXiv:2009.01719},
year = {2020},
abstract = {Recent work has shown that large text-based neural language models, trained with conventional supervised learning objectives, acquire a surprising propensity for few- and one-shot learning. Here, we show that an embodied agent situated in a simulated 3D world, and endowed with a novel dual-coding external memory, can exhibit similar one-shot word learning when trained with conventional reinforcement learning algorithms. After a single introduction to a novel object via continuous visual perception and a language prompt ("This is a dax"), the agent can re-identify the object and manipulate it as instructed ("Put the dax on the bed"). In doing so, it seamlessly integrates short-term, within-episode knowledge of the appropriate referent for the word "dax" with long-term lexical and motor knowledge acquired across episodes (i.e. "bed" and "putting"). We find that, under certain training conditions and with a particular memory writing mechanism, the agent's one-shot word-object binding generalizes to novel exemplars within the same ShapeNet category, and is effective in settings with unfamiliar numbers of objects. We further show how dual-coding memory can be exploited as a signal for intrinsic motivation, stimulating the agent to seek names for objects that may be useful for later executing instructions. Together, the results demonstrate that deep neural networks can exploit meta-learning, episodic memory and an explicitly multi-modal environment to account for 'fast-mapping', a fundamental pillar of human cognitive development and a potentially transformative capacity for agents that interact with human users.}
}
@inproceedings{HilletalICLR-20,
title = {Environmental drivers of systematicity and generalization in a situated agent},
author = {Felix Hill and Andrew Lampinen and Rosalia Schneider and Stephen Clark and Matthew Botvinick and James L. McClelland and Adam Santoro},
booktitle = {International Conference on Learning Representations},
year = {2020},
abstract = {The question of whether deep neural networks are good at generalising beyond their immediate training experience is of critical importance for learning-based approaches to AI. Here, we consider tests of out-of-sample generalisation that require an agent to respond to never-seen-before instructions by manipulating and positioning objects in a 3D Unity simulated room. We first describe a comparatively generic agent architecture that exhibits strong performance on these tests. We then identify three aspects of the training regime and environment that make a significant difference to its performance: (a) the number of object/word experiences in the training set; (b) the visual invariances afforded by the agent's perspective, or frame of reference; and (c) the variety of visual input inherent in the perceptual aspect of the agent's perception. Our findings indicate that the degree of generalisation that networks exhibit can depend critically on particulars of the environment in which a given task is instantiated. They further suggest that the propensity for neural networks to generalise in systematic ways may increase if, like human children, those networks have access to many frames of richly varying, multi-modal observations as they learn.}
}
@article{LuetalCoRR-21,
title = {Pretrained Transformers as Universal Computation Engines},
author = {Kevin Lu and Aditya Grover and Pieter Abbeel and Igor Mordatch},
journal = {CoRR},
year = {2021},
volume = {arXiv:2103.05247},
abstract = {We investigate the capability of a transformer pretrained on natural language to generalize to other modalities with minimal finetuning - in particular, without finetuning of the self-attention and feedforward layers of the residual blocks. We consider such a model, which we call a Frozen Pretrained Transformer (FPT), and study finetuning it on a variety of sequence classification tasks spanning numerical computation, vision, and protein fold prediction. In contrast to prior works which investigate finetuning on the same modality as the pretraining dataset, we show that pretraining on natural language improves performance and compute efficiency on non-language downstream tasks. In particular, we find that such pretraining enables FPT to generalize in zero-shot to these modalities, matching the performance of a transformer fully trained on these tasks.}
}
@article{DuanetalCoRR-17,
author = {Yan Duan and Marcin Andrychowicz and Bradly C. Stadie and Jonathan Ho and Jonas Schneider and Ilya Sutskever and Pieter Abbeel and Wojciech Zaremba},
title = {One-Shot Imitation Learning},
journal = {CoRR},
volume = {arXiv:1703.07326},
year = {2017},
abstract = {Imitation learning has been commonly applied to solve different tasks in isolation. This usually requires either careful feature engineering, or a significant number of samples. This is far from what we desire: ideally, robots should be able to learn from very few demonstrations of any given task, and instantly generalize to new situations of the same task, without requiring task-specific engineering. In this paper, we propose a meta-learning framework for achieving such capability, which we call one-shot imitation learning.
Specifically, we consider the setting where there is a very large set of tasks, and each task has many instantiations. For example, a task could be to stack all blocks on a table into a single tower, another task could be to place all blocks on a table into two-block towers, etc. In each case, different instances of the task would consist of different sets of blocks with different initial states. At training time, our algorithm is presented with pairs of demonstrations for a subset of all tasks.
A neural net is trained that takes as input one demonstration and the current state (which initially is the initial state of the other demonstration of the pair), and outputs an action with the goal that the resulting sequence of states and actions matches as closely as possible with the second demonstration. At test time, a demonstration of a single instance of a new task is presented, and the neural net is expected to perform well on new instances of this new task. The use of soft attention allows the model to generalize to conditions and tasks unseen in the training data. We anticipate that by training this model on a much greater variety of tasks and settings, we will obtain a general system that can turn any demonstrations into robust policies that can accomplish an overwhelming variety of tasks.}
}
31 Biological systems understand the world by simultaneously processing high-dimensional inputs from modalities as diverse as vision, audition, touch, proprioception, etc. The perception models used in deep learning on the other hand are designed for individual modalities, often relying on domain-specific assumptions such as the local grid structures exploited by virtually all existing vision models. These priors introduce helpful inductive biases, but also lock models to individual modalities. In this paper we introduce the Perceiver – a model that builds upon Transformers and hence makes few architectural assumptions about the relationship between its inputs, but that also scales to hundreds of thousands of inputs, like ConvNets. The model leverages an asymmetric attention mechanism to iteratively distill inputs into a tight latent bottleneck, allowing it to scale to handle very large input – see Jaegle et al [145] quoted here for recent work on relevant artificial neural network architectures and studies by Brian Wandell and his group a Stanford on the organization of aligned retinotopically visual field map in human cortex [237, 238].
32 Here is the README file for the Zinn dialogue management prototype Python implementation:
# -*- coding: utf-8 -*-
# Zanax - A Dialog Error Handling Module for Zinn
The word Zanax is a made-up name that happens to correspond to a common misspelling - but correct pronunciation - of Xanax, the trade name for the drug alprazolam. Alprazolam is a short-acting benzodiazepine used to treat anxiety disorders and panic attacks. Zanox incorporates the Z in Zinn - as Zinn employs similar error-handling strategies in its dialog manager - as well as a nod to Xanax for Zanax's targeted calming - don't panic - effect.
Zanax includes very simple NLU and NLG components that rely primarily on, respectively, keyword spotting and simple schema-based phrase generators. It also includes a complete hierarcial ordered planner (HOP) developed by Dana Nau. The actual error handling module is implemented as a set primitive actions, tasks relating to dialog, and plans for carrying out said tasks. The complete prototype consists of four file and fewer than 1500 lines of code. The error handling part consists of less than 500 lines excluding comments, and the planner is elegantly simple consisting of fewer than 200 lines excluding comments.
% wc -l zanax_*.py
252 zanax_HOP.py
582 zanax_HTN.py
307 zanax_NLG.py
275 zanax_NLU.py
1416 total
% cat zanax_HOP.py | grep -v "#" | wc -l
193
% cat zanax_HTN.py | grep -v "#" | wc -l
430
% cat zanax_*.py | grep -v "#" | wc -l
1121
zanax_HOP.py - Basic Hierarchical Ordered Planner
zanax_HTN.py - Hierarchical Task Network for Dialog
zanax_NLG.py - Simple Natural Language Generation
zanax_NLU.py - Simple Natural Language Understanding
To experiment with Zanax decant the tarball in a directory, launch python and just type: import zanax_HTN
This will load the whole system, run some tests and then start a conversation with you. To avoid needless disappointment read the following and check out the examples below:
The NLU is as thin as it can be and still illustrate Zinn's ambiguity resolution and non-understanding recovery strategies. It is best to use words selected from the following categories to convey your intentions. There will still be plenty of opportunities to introduce ambiguity and obfuscation. For example, type "sting" or "stig" when you mean "play sting", or type "I really like jazz but not classical" when you're asked for your favorite genre. Misspellings that are still relatively close in edit distance to the correct spellings, shortcuts like "sting" in the context of a request for some music to play, and providing too much information as in the case: "I like Michael Jackson but only his early stuff and I don't mean the albums he did with the Jackson Five" are fair game, whether or not the current system handles them gracefully. The full version of Zinn with its larger vocabulary and more sophisticated key-word and key-phrase spotting capability based on embedding models will do a much better job on examples like these, but that's not what this implementation is designed to demonstrate. The objective shouldn't be just to confuse Zinn, or reveal the limitations of its vocabulary; you'll have an easy time of it in pursuing these entertainments. The objective should be to give Zinn at least a fighting chance and observe how it manages to recover the meaning of your utterances by asking simple questions as part of a natural dialog. See the examples below:
General word categories:
positive words / positive sentiment, e.g., yes, yep, sure, fine, okay, right, awesome, etc.
negative words / negative sentiment, e.g., no, nope, not, nada, noway, nothin, etc.
quantifier words, e.g., anything, something, whatever, all, etc.
greetings, e.g., hi, hello, cheers, howdy, morning, evening, afternoon, etc.
numbers, digits, ordering, e.g., last, next, previous, and indexing words, e.g., first, third, etc.
Music-related categories:
play words, e.g., play, pick, spin, listen, hear, perform, etc.
album words, e.g., bad, thriller, nevermind, tapestry, etc.
genre words, e.g., classical, blues, jazz, pop, rock, etc.
artist words, e.g., sting, beatles, prince, jackson, etc.
song words, e.g., yesterday, satisfaction, macarena, etc.
first names, e.g., tom, peter, sudeep, johnny, gabe, anja, luheng, xin, jay, shalini, larry, sergey, alan, alfred, kannan, ravi, blaise, etc.
Here's an example of interacting with Zinn:
Demonstrate play start patiently waiting for input:
Zinn: What can I play for you?
User: ....
Zinn: I can play particular artists, songs or categories.
User: ........
Zinn: If you want I can just play something random.
User: play some sting
Zinn: Got that you want me to play sting. correct?
User: yep
Zinn: Thanks. I got it now.
User: huh!
Zinn: I didn't get all of what you said.
Zinn: Give me one genre.
User: classical
Zinn: Thanks. I got your genre.
Run 'select genre' assuming no prior confirmation:
# 1. The user input is clear enough to proceed directly:
Zinn: What is your favorite type of music?
User: not pop
Zinn: Not my favorite, but I'm open to learn.
Zinn: I think you said that you don't like pop?
User: yes
Zinn: I'll take that as a 'yes' and not play any pop.
Zinn: How about one of: blues, rock, pop or jazz?
User: jazz
Zinn: Jazz is my favorite next to classical.
Zinn: Great. Let's talk about some jazz artists.
# 2. The user input is too confused to proceed directly:
Zinn: Do you have a favorite type of music?
User: not pop
Zinn: Not my favorite, but I'm open to learn.
Zinn: I think you said that you don't like pop?
User: nada
Zinn: Were you (1) confirming or (2) denying your dislike?
User: one
Zinn: Sounds good. I won't be playing any pop.
Zinn: How about one of: blues, rock, pop or jazz?
User: blues
Zinn: I like delta and Chicago blues styles.
Zinn: Great. Let's talk about some blues artists.
Simple tests of "confirm play" with a contrived state:
# 1. The user input is sufficiently different from the default:
User: Just play me some sting
Zinn: When you say "just play me some sting" does that roughly mean "play sting"?
User: yes
Zinn: Thanks. I got it now.
2. The user input is sufficiently similar to the default:
User: Ply some stig
Zinn: Got that you want me to play sting. correct?
User: yep
Zinn: Thanks. I understand it now.
Trying "recover artist" with domain-specific payload:
Zinn: I didn't catch mention of any music.
Zinn: What music would you like to hear?
User: maybe blues
Zinn: I didn't get that either.
Zinn: Could you say that a different way?
User: some blues
Zinn: Sorry. I'm totally confused.
Run "recover artist" with the default language option:
Zinn: I didn't get all of what you said.
Zinn: Give me one artist.
User: beatles
Zinn: Thanks. I got your artist.
Run "recover artist or genre" with default language:
Zinn: I didn't get all of what you said.
Zinn: Give me one artist or genre.
User: some blues
Zinn: Thanks. I got your genre.
>>>
33 A sample of papers relating to modeling relevant perceptual, relational, and procedural properties of neural network representations of computer programs.
@article{WangetalICLR-18,
author = {Ke Wang and Rishabh Singh and Zhendong Su},
title = {Dynamic Neural Program Embedding for Program Repair},
journal = {International Conference on Learning Representations},
year = {2018},
abstract = {Neural program embeddings have shown much promise recently for a variety of program analysis tasks, including program synthesis, program repair, code- completion, and fault localization. However, most existing program embeddings are based on syntactic features of programs, such as token sequences or abstract syntax trees. Unlike images and text, a program has well-defined semantics that can be difficult to capture by only considering its syntax (i.e. syntactically similar programs can exhibit vastly different run-time behavior), which makes syntax- based program embeddings fundamentally limited. We propose a novel semantic program embedding that is learned from program execution traces. Our key in- sight is that program states expressed as sequential tuples of live variable values not only capture program semantics more precisely, but also offer a more natural fit for Recurrent Neural Networks to model. We evaluate different syntactic and semantic program embeddings on the task of classifying the types of errors that students make in their submissions to an introductory programming class and on the CodeHunt education platform. Our evaluation results show that the semantic program embeddings significantly outperform the syntactic program embeddings based on token sequences and abstract syntax trees. In addition, we augment a search-based program repair system with predictions made from our semantic embedding and demonstrate significantly improved search efficiency.},
}
@article{VermaetalCoRR-18,
author = {Programmatically Interpretable Reinforcement Learning},
title = {Abhinav Verma and Vijayaraghavan Murali and Rishabh Singh and Pushmeet Kohli and Swarat Chaudhuri},
journal = {CoRR},
volume = {arXiv:1804.02477},
year = {2018},
abstract = {We study the problem of generating interpretable and verifiable policies through reinforcement learning. Unlike the popular Deep Reinforcement Learning (DRL) paradigm, in which the policy is represented by a neural network, the aim in Programmatically Interpretable Reinforcement Learning is to find a policy that can be represented in a high-level programming language. Such programmatic policies have the benefits of being more easily interpreted than neural networks, and being amenable to verification by symbolic methods. We propose a new method, called Neurally Directed Program Search (NDPS), for solving the challenging nonsmooth optimization problem of finding a programmatic policy with maxima reward. NDPS works by first learning a neural policy network using DRL, and then performing a local search over programmatic policies that seeks to minimize a distance from this neural "oracle". We evaluate NDPS on the task of learning to drive a simulated car in the TORCS car-racing environment. We demonstrate that NDPS is able to discover human-readable policies that pass some significant performance bars. We also find that a well-designed policy language can serve as a regularizer, and result in the discovery of policies that lead to smoother trajectories and are more easily transferred to environments not encountered during training.}
}
@inproceedings{SinghandKohliSNAPL-17,
author = {Singh, Rishabh and Kohli, Pushmeet},
title = {{AP:Artificial Programming}},
booktitle = {Summit on Advances in Programming Languages 2017},
year = {2017},
abstract = {The ability to automatically discover a program consistent with a given user intent (specification) is the holy grail of Computer Science. While significant progress has been made on the so-called problem of Program Synthesis, a number of challenges remain; particularly for the case of synthesizing richer and larger programs. This is in large part due to the difficulty of search over the space of programs. In this paper, we argue that the above-mentioned challenge can be tackled by learning synthesizers automatically from a large amount of training data. We present a first step in this direction by describing our novel synthesis approach based on two neural architectures for tackling the two key challenges of Learning to understand partial input-output specifications and Learning to search programs. The first neural architecture called the Spec Encoder computes a continuous representation of the specification, whereas the second neural architecture called the Program Generator incrementally constructs programs in a hypothesis space that is conditioned by the specification vector. The key idea of the approach is to train these architectures using a large set of (spec,P) pairs, where P denotes a program sampled from the DSL L and spec denotes the corresponding specification satisfied by P. We demonstrate the effectiveness of our approach on two preliminary instantiations. The first instantiation, called Neural FlashFill, corresponds to the domain of string manipulation programs similar to that of FlashFill. The second domain considers string transformation programs consisting of composition of API functions. We show that a neural system is able to perform quite well in learning a large majority of programs from few input-output examples. We believe this new approach will not only dramatically expand the applicability and effectiveness of Program Synthesis, but also would lead to the coming together of the Program Synthesis and Machine Learning research disciplines.},
}
@incollection{DevlinetalNIPS-17,
title = {Neural Program Meta-Induction},
author = {Devlin, Jacob and Bunel, Rudy R and Singh, Rishabh and Hausknecht, Matthew and Kohli, Pushmeet},
booktitle = {Advances in Neural Information Processing Systems 30},
editor = {I. Guyon and U. V. Luxburg and S. Bengio and H. Wallach and R. Fergus and S. Vishwanathan and R. Garnett},
publisher = {Curran Associates, Inc.},
year = {2017},
pages = {2077-2085},
abstract = {Most recently proposed methods for Neural Program induction work under the assumption of having a large set of input/output (I/O) examples for learning any given input-output mapping. This paper aims to address the problem of data and computation efficiency of program induction by leveraging information from related tasks. Specifically, we propose two novel approaches for cross-task knowledge transfer to improve program induction in limited-data scenarios. In our first proposal, portfolio adaptation, a set of induction models is pretrained on a set of related tasks, and the best model is adapted towards the new task using transfer learning. In our second approach, meta program induction, a k-shot learning approach is used to make a model generalize to new tasks without additional training. To test the efficacy of our methods, we constructed a new benchmark of programs written in the Karel programming language. Using an extensive experimental evaluation on the Karel benchmark, we demonstrate that our proposals dramatically outperform the baseline induction method that does not use knowledge transfer. We also analyze the relative performance of the two approaches and study conditions in which they perform best. In particular, meta induction outperforms all existing approaches under extreme data sparsity (when a very small number of examples are available), i.e., fewer than ten. As the number of available I/O examples increase (i.e. a thousand or more), portfolio adapted program induction becomes the best approach. For intermediate data sizes, we demonstrate that the combined method of adapted meta program induction has the strongest performance.}
}
@inproceedings{DevlinetalICLR-18,
title = {Semantic Code Repair using Neuro-Symbolic Transformation Networks},
author = {Jacob Devlin and Jonathan Uesato and Rishabh Singh and Pushmeet Kohli},
booktitle = {International Conference on Learning Representations},
year = {2018},
abstract = {We study the problem of semantic code repair, which can be broadly defined as automatically fixing non-syntactic bugs in source code. The majority of past work in semantic code repair assumed access to unit tests against which candidate repairs could be validated. In contrast, the goal here is to develop a strong statistical model to accurately predict both bug locations and exact fixes without access to information about the intended correct behavior of the program. Achieving such a goal requires a robust contextual repair model, which we train on a large corpus of real-world source code that has been augmented with synthetically injected bugs. Our framework adopts a two-stage approach where first a large set of repair candidates are generated by rule-based processors, and then these candidates are scored by a statistical model using a novel neural network architecture which we refer to as Share, Specialize, and Compete. Specifically, the architecture (1) generates a shared encoding of the source code using an RNN over the abstract syntax tree, (2) scores each candidate repair using specialized network modules, and (3) then normalizes these scores together so they can compete against one another in comparable probability space. We evaluate our model on a real-world test set gathered from GitHub containing four common categories of bugs. Our model is able to predict the exact correct repair 41\% of the time with a single guess, compared to 13\% accuracy for an attentional sequence-to-sequence model.}
}
34 The following BibTeX references and abstracts include papers on contrastive predictive coding, vector quantized variational autoencoder (VQ-VAE) and making analogies by contrasting abstract relational structure, plus a collection of Yoshua Bengio's papers that delve into the evolution of human language, curriculum learning and layer-by-layer staged learning of representational hierarchies.
@article{vanDenOordetalCoRR-18,
author = {Representation Learning with Contrastive Predictive Coding},
title = {Aaron van den Oord and Yazhe Li and Oriol Vinyals},
journal = {CoRR},
volume = {arXiv:1807.03748},
year = {2018},
abstract = {While supervised learning has enabled great progress in many applications, unsupervised learning has not seen such widespread adoption, and remains an important and challenging endeavor for artificial intelligence. In this work, we propose a universal unsupervised learning approach to extract useful representations from high-dimensional data, which we call Contrastive Predictive Coding. The key insight of our model is to learn such representations by predicting the future in latent space by using powerful autoregressive models. We use a probabilistic contrastive loss which induces the latent space to capture information that is maximally useful to predict future samples. It also makes the model tractable by using negative sampling. While most prior work has focused on evaluating representations for a particular modality, we demonstrate that our approach is able to learn useful representations achieving strong performance on four distinct domains: speech, images, text and reinforcement learning in 3D environments.}
}
@article{RazavietalCoRR-19,
author = {Ali Razavi and A{\"{a}}ron van den Oord and Oriol Vinyals},
title = {Generating Diverse High-Fidelity Images with {VQ-VAE-2}},
journal = {CoRR},
volume = {arXiv:1906.00446},
year = {2019},
abstract = {We explore the use of Vector Quantized Variational AutoEncoder (VQ-VAE) models for large scale image generation. To this end, we scale and enhance the autoregressive priors used in VQ-VAE to generate synthetic samples of much higher coherence and fidelity than possible before. We use simple feed-forward encoder and decoder networks, making our model an attractive candidate for applications where the encoding and/or decoding speed is critical. Additionally, VQ-VAE requires sampling an autoregressive model only in the compressed latent space, which is an order of magnitude faster than sampling in the pixel space, especially for large images. We demonstrate that a multi-scale hierarchical organization of VQ-VAE, augmented with powerful priors over the latent codes, is able to generate samples with quality that rivals that of state of the art Generative Adversarial Networks on multifaceted datasets such as ImageNet, while not suffering from GAN's known shortcomings such as mode collapse and lack of diversity.}
}
@article{vandenOordCoRR-17,
author = {A{\"{a}}ron van den Oord and Oriol Vinyals and Koray Kavukcuoglu},
title = {Neural Discrete Representation Learning},
journal = {CoRR},
volume = {arXiv:1711.00937},
year = {2017},
abstract = {Learning useful representations without supervision remains a key challenge in machine learning. In this paper, we propose a simple yet powerful generative model that learns such discrete representations. Our model, the Vector Quantised-Variational AutoEncoder (VQ-VAE), differs from VAEs in two key ways: the encoder network outputs discrete, rather than continuous, codes; and the prior is learnt rather than static. In order to learn a discrete latent representation, we incorporate ideas from vector quantisation (VQ). Using the VQ method allows the model to circumvent issues of "posterior collapse" -- where the latents are ignored when they are paired with a powerful autoregressive decoder -- typically observed in the VAE framework. Pairing these representations with an autoregressive prior, the model can generate high quality images, videos, and speech as well as doing high quality speaker conversion and unsupervised learning of phonemes, providing further evidence of the utility of the learnt representations.}
}
@inproceedings{HilletalICLR-19,
author = {Felix Hill and Adam Santoro and David G. T. Barrett and Ari S. Morcos and Timothy P. Lillicrap},
title = {Learning to Make Analogies by Contrasting Abstract Relational Structure},
booktitle = {International Conference on Learning Representations},
comment = {arXiv:1902.00120},
year = {2019},
abstract = {Analogical reasoning has been a principal focus of various waves of AI research. Analogy is particularly challenging for machines because it requires relational structures to be represented such that they can be flexibly applied across diverse domains of experience. Here, we study how analogical reasoning can be induced in neural networks that learn to perceive and reason about raw visual data. We find that the critical factor for inducing such a capacity is not an elaborate architecture, but rather, careful attention to the choice of data and the manner in which it is presented to the model. The most robust capacity for analogical reasoning is induced when networks learn analogies by contrasting abstract relational structures in their input domains, a training method that uses only the input data to force models to learn about important abstract features. Using this technique we demonstrate capacities for complex, visual and symbolic analogy making and generalisation in even the simplest neural network architectures.}
}
@article{HongetalCoRR-21,
title = {Latent Programmer: Discrete Latent Codes for Program Synthesis},
author = {Joey Hong and David Dohan and Rishabh Singh and Charles Sutton and Manzil Zaheer},
volume = {arXiv:2012.00377},
journal = {CoRR},
year = {2021},
abstract = {In many sequence learning tasks, such as program synthesis and document summarization, a key problem is searching over a large space of possible output sequences. We propose to learn representations of the outputs that are specifically meant for search: rich enough to specify the desired output but compact enough to make search more efficient. Discrete latent codes are appealing for this purpose, as they naturally allow sophisticated combinatorial search strategies. The latent codes are learned using a self-supervised learning principle, in which first a discrete autoencoder is trained on the output sequences, and then the resulting latent codes are used as intermediate targets for the end-to-end sequence prediction task. Based on these insights, we introduce the \emph{Latent Programmer}, a program synthesis method that first predicts a discrete latent code from input/output examples, and then generates the program in the target language. We evaluate the Latent Programmer on two domains: synthesis of string transformation programs, and generation of programs from natural language descriptions. We demonstrate that the discrete latent representation significantly improves synthesis accuracy.}
}
@inproceedings{BengioCGEC-14,
author = {Bengio, Yoshua},
title = {Deep learning and cultural evolution},
booktitle = {Proceedings of the Companion Publication of the 2014 Annual Conference on Genetic and Evolutionary Computation},
publisher = {ACM},
location = {New York, NY, USA},
year = {2014},
abstract = {We propose a theory and its first experimental tests, relating difficulty of learning in deep architectures to culture and language. The theory is articulated around the following hypotheses: learning in an individual human brain is hampered by the presence of effective local minima, particularly when it comes to learning higher-level abstractions, which are represented by the composition of many levels of representation, i.e., by deep architectures; a human brain can learn such high-level abstractions if guided by the signals produced by other humans, which act as hints for intermediate and higher-level abstractions; language and the recombination and optimization of mental concepts provide an efficient evolutionary recombination operator for this purpose. The theory is grounded in experimental observations of the difficulties of training deep artificial neural networks and an empirical test of the hypothesis regarding the need for guidance of intermediate concepts is demonstrated. This is done through a learning task on which all the tested machine learning algorithms failed, unless provided with hints about intermediate-level abstractions.}
}
@inproceedings{BengioCOGSCI-14,
author = {Bengio, Yoshua},
title = {{Deep learning, Brains and the Evolution of Culture}},
booktitle = {Proceedings of the 36th Annual Conference of the Cognitive Science Society Workshop on Deep Learning and the Brain},
publisher = {Cognitive Science Society},
location = {Quebec City, Quebec, Canada},
year = {2014},
}
@article{BengioCoRR-12,
author = {Yoshua Bengio},
title = {Evolving Culture vs Local Minima},
journal = {CoRR},
volume = {arXiv:1203.2990},
year = {2012},
abstract = {We propose a theory that relates difficulty of learning in deep architectures to culture and language. It is articulated around the following hypotheses: (1) learning in an individual human brain is hampered by the presence of effective local minima; (2) this optimization difficulty is particularly important when it comes to learning higher-level abstractions, i.e., concepts that cover a vast and highly-nonlinear span of sensory configurations; (3) such high-level abstractions are best represented in brains by the composition of many levels of representation, i.e., by deep architectures; (4) a human brain can learn such high-level abstractions if guided by the signals produced by other humans, which act as hints or indirect supervision for these high-level abstractions; and (5), language and the recombination and optimization of mental concepts provide an efficient evolutionary recombination operator, and this gives rise to rapid search in the space of communicable ideas that help humans build up better high-level internal representations of their world. These hypotheses put together imply that human culture and the evolution of ideas have been crucial to counter an optimization difficulty: this optimization difficulty would otherwise make it very difficult for human brains to capture high-level knowledge of the world. The theory is grounded in experimental observations of the difficulties of training deep artificial neural networks. Plausible consequences of this theory for the efficiency of cultural evolutions are sketched.}
}
@article{BengioetalCoRR-16,
author = {Yoshua Bengio and Dong{-}Hyun Lee and J{\"{o}}rg Bornschein and Zhouhan Lin},
title = {Towards Biologically Plausible Deep Learning},
journal = {CoRR},
volume = {arXiv:1502.04156},
year = {2016},
abstract = {Neuroscientists have long criticised deep learning algorithms as incompatible with current knowledge of neurobiology. We explore more biologically plausible versions of deep representation learning, focusing here mostly on unsupervised learning but developing a learning mechanism that could account for supervised, unsupervised and reinforcement learning. The starting point is that the basic learning rule believed to govern synaptic weight updates (Spike-Timing-Dependent Plasticity) arises out of a simple update rule that makes a lot of sense from a machine learning point of view and can be interpreted as gradient descent on some objective function so long as the neuronal dynamics push firing rates towards better values of the objective function (be it supervised, unsupervised, or reward-driven). The second main idea is that this corresponds to a form of the variational EM algorithm, i.e., with approximate rather than exact posteriors, implemented by neural dynamics. Another contribution of this paper is that the gradients required for updating the hidden states in the above variational interpretation can be estimated using an approximation that only requires propagating activations forward and backward, with pairs of layers learning to form a denoising auto-encoder. Finally, we extend the theory about the probabilistic interpretation of auto-encoders to justify improved sampling schemes based on the generative interpretation of denoising auto-encoders, and we validate all these ideas on generative learning tasks.},
}
@inproceedings{BengioetalICML-09,
author = {Bengio, Yoshua and Louradour, J{\'e}r\^{o}me and Collobert, Ronan and Weston, Jason},
title = {Curriculum Learning},
booktitle = {Proceedings of the 26th Annual International Conference on Machine Learning},
publisher = {ACM},
address = {New York, NY, USA},
location = {Montreal, Quebec, Canada},
year = {2009},
pages = {41-48},
abstract = {Humans and animals learn much better when the examples are not randomly presented but organized in a meaningful order which illustrates gradually more concepts, and gradually more complex ones. Here, we formalize such training strategies in the context of machine learning, and call them "curriculum learning". In the context of recent research studying the difficulty of training in the presence of non-convex training criteria (for deep deterministic and stochastic neural networks), we explore curriculum learning in various set-ups. The experiments show that significant improvements in generalization can be achieved. We hypothesize that curriculum learning has both an effect on the speed of convergence of the training process to a minimum and, in the case of non-convex criteria, on the quality of the local minima obtained: curriculum learning can be seen as a particular form of continuation method (a general strategy for global optimization of non-convex functions).},
}
@incollection{BengioetalNIPS-07,
author = {Yoshua Bengio and Pascal Lamblin and Dan Popovici and Hugo Larochelle},
title = {Greedy Layer-Wise Training of Deep Networks},
booktitle = {Advances in Neural Information Processing Systems 19},
address = {Cambridge, MA},
publisher = {MIT Press},
pages = {153-160},
year = 2007,
abstract = {Complexity theory of circuits strongly suggests that deep architectures can be much more efficient (sometimes exponentially) than shallow architectures, in terms of computational elements required to represent some functions. Deep multi-layer neural networks have many levels of non-linearities allowing them to compactly represent highly non-linear and highly-varying functions. However, until recently it was not clear how to train such deep networks, since gradient-based optimization starting from random initialization appears to often get stuck in poor solutions. Hinton et al. recently introduced a greedy layer-wise unsupervised learning algorithm for Deep Belief Networks (DBN), a generative model with many layers of hidden causal variables. In the context of the above optimization problem, we study this algorithm empirically and explore variants to better understand its success and extend it to cases where the inputs are continuous or where the structure of the input distribution is not revealing enough about the variable to be predicted in a supervised task. Our experiments also confirm the hypothesis that the greedy layer-wise unsupervised training strategy mostly helps the optimization, by initializing weights in a region near a good local minimum, giving rise to internal distributed representations that are high-level abstractions of the input, bringing better generalization.}
}
@article{BengioetalPAMI-13,
author = {Bengio, Yoshua and Courville, Aaron and Vincent, Pascal},
title = {Representation Learning: A Review and New Perspectives},
journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence},
publisher = {IEEE Computer Society},
volume = {35},
number = {8},
year = {2013},
pages = {1798-1828},
abstract = {The success of machine learning algorithms generally depends on data representation, and we hypothesize that this is because different representations can entangle and hide more or less the different explanatory factors of variation behind the data. Although specific domain knowledge can be used to help design representations, learning with generic priors can also be used, and the quest for AI is motivating the design of more powerful representation-learning algorithms implementing such priors. This paper reviews recent work in the area of unsupervised feature learning and deep learning, covering advances in probabilistic models, autoencoders, manifold learning, and deep networks. This motivates longer term unanswered questions about the appropriate objectives for learning good representations, for computing representations (i.e., inference), and the geometrical connections between representation learning, density estimation, and manifold learning.}
}
35 The class is off to a good start. We are currently focussing on the role of language in the programmer's apprentice application, and, specifically, on approaches that exploit the benefits of nonverbal, prelinguistic communication involving pointing and gesturing, combined with language-informed offline preprocessing such as generating representations that incorporate descriptions from documentation and educational resources with more-abstract representations of the dynamic and static properties of programs.
One aspirational goal is to explain what a program written in a specific language does in a compositional hierarchical manner by reading the reference documentation and language guide for a specified computer language such as the Scheme dialect of Lisp. Practically speaking, this might mean being able to traverse the abstract syntax tree for a Scheme program that does list processing and provides a level-appropriate description of what each subtree in the AST does.
What would such a description look like? It might, for example, be sufficient to demonstrate for any binding of the variables referenced in the subexpression corresponding to a given subtree what that subexpression would return. This would be trivial if you had an interpreter perform the necessary computations. Alternatively, you could describe the computations performed in evaluating a syntactically well-formed expression with all of its variables bound correctly typed values by using everyday language and relying on objects and operations performed on such objects that are familiar to your audience.
For example you could describe operations on vectors using the commonsense notion of a list and familiar list operations like removing an item from a list, and concatenating or comparing two lists. Alternatively, you could use the analogy of people standing lines and assign some (computational) agency to the people in a line so that, for example, two adjacent people could compare their relative height and rearrange their positions in the line so that shorter of the two is closer to the front. One challenge we are focusing on involves how we might build systems that create analogies – what we've been calling algorithmic stories – and use them to solve novel programming problems.
Roughly following Dedre Gentner's structure-mapping theory, we define an analogy in terms of a map between two models – the sour22ce and the target, where each of the two is defined by a collection of entities, their properties and the relationships between them. The properties in question can be static or dynamic, mathematical or conceptual, as required for a given application.
A mapping is deemed to be useful for a given application if the two models share the necessary entities – or their suitable proxies – required of the application and the mapping preserves the necessary properties or reasonable approximations thereof. The utility of an analogy is generally characterized in terms of the ability to draw useful conclusions and apply strategies derived from the source model to the target model.
Techniques such as the one described by Alon et al [10] would allow us to represent models in a high dimensional embedding space in a canonical form that would enable us to identify analogous models by exploiting a suitable metric on the space of models and apply strategies derived from the source model to answer questions / perform specific analyses on the target model / draw conclusions and make alterations / to serve new purposes.
Think about the dimensions of an embedding vector of the sort typically used to represent linguistic, visual or auditory input. In the case of language, a single dimension might be the sum of the random weights of one-hot vectors. In the case of perception, they could be the sum of pixel values or auditory frequencies. In contrast, the vectors in the Alon et al [10] model might correspond to discrete semantic categories or datatypes of inputs, outputs. It is tempting to exploit this opportunity to represent complex phenomena in a high-dimensional Hilbert space with a well defined – essentially orthogonal – basis, but the history of AI is full of examples of the folly of defining representations rather than allowing the data to speak for itself.
In your work on learning distributed representations of programs, you've explored using natural language descriptions, formal canonical descriptions including abstract syntax trees and execution traces. What have you learned about the utility of these various strategies, especially those that code for the dynamic properties of programs? What about affordances and invariants? Are there inductive biases that reflect general properties of the class of environments we expect to encounter that facilitate learning environmentally appropriate representations?
36 Three recent papers on learning tree-structured hierarchical representations using attention and transformer models:
@inproceedings{ShivandQuirkNIPS-19,
author = {Shiv, Vighnesh and Quirk, Chris},
booktitle = {Advances in Neural Information Processing Systems},
editor = {H. Wallach and H. Larochelle and A. Beygelzimer and F. d' Alch{\'{e}}-Buc and E. Fox and R. Garnett},
publisher = {Curran Associates, Inc.},
title = {Novel positional encodings to enable tree-based transformers},
volume = {32},
year = {2019},
abstract = {Neural models optimized for tree-based problems are of great value in tasks like SQL query extraction and program synthesis. On sequence-structured data, transformers have been shown to learn relationships across arbitrary pairs of positions more reliably than recurrent models. Motivated by this property, we propose a method to extend transformers to tree-structured data, enabling sequence-to-tree, tree-to-sequence, and tree-to-tree mappings. Our approach abstracts the transformer's sinusoidal positional encodings, allowing us to instead use a novel positional encoding scheme to represent node positions within trees. We evaluated our model in tree-to-tree program translation and sequence-to-tree semantic parsing settings, achieving superior performance over both sequence-to-sequence transformers and state-of-the-art tree-based LSTMs on several datasets. In particular, our results include a 22\% absolute increase in accuracy on a JavaScript to CoffeeScript translation dataset.}
}
@article{WangetalCoRR-19,
title = {Tree Transformer: Integrating Tree Structures into Self-Attention},
author = {Yau-Shian Wang and Hung-Yi Lee and Yun-Nung Chen},
year = {2019},
volume = {arXiv:1909.06639},
journal = {CoRR},
abstract = {Pre-training Transformer from large-scale raw texts and fine-tuning on the desired task have achieved state-of-the-art results on diverse NLP tasks. However, it is unclear what the learned attention captures. The attention computed by attention heads seems not to match human intuitions about hierarchical structures. This paper proposes Tree Transformer, which adds an extra constraint to attention heads of the bidirectional Transformer encoder in order to encourage the attention heads to follow tree structures. The tree structures can be automatically induced from raw texts by our proposed "Constituent Attention" module, which is simply implemented by self-attention between two adjacent words. With the same training procedure identical to BERT, the experiments demonstrate the effectiveness of Tree Transformer in terms of inducing tree structures, better language modeling, and further learning more explainable attention scores.},
}
@inproceedings{NguyenetalICLR-20,
title = {Tree-Structured Attention with Hierarchical Accumulation},
author = {Xuan-Phi Nguyen and Shafiq Joty and Steven Hoi and Richard Socher},
booktitle = {International Conference on Learning Representations},
year = {2020},
abstract = {Incorporating hierarchical structures like constituency trees has been shown to be effective for various natural language processing (NLP) tasks. However, it is evident that state-of-the-art (SOTA) sequence-based models like the Transformer struggle to encode such structures inherently. On the other hand, dedicated models like the Tree-LSTM, while explicitly modeling hierarchical structures, do not perform as efficiently as the Transformer. In this paper, we attempt to bridge this gap with "Hierarchical Accumulation" to encode parse tree structures into self- attention at constant time complexity. Our approach outperforms SOTA methods in four IWSLT translation tasks and the WMT’14 English-German translation task. It also yields improvements over Transformer and Tree-LSTM on three text classification tasks. We further demonstrate that using hierarchical priors can compensate for data shortage, and that our model prefers phrase-level attentions over token-level attentions.},
}
37 BibTeX references relevant to Gentner's structure-mapping theory of analogy:
@article{CrouseetalCoRR-20,
title = {Neural Analogical Matching},
author = {Maxwell Crouse and Constantine Nakos and Ibrahim Abdelaziz and Kenneth Forbus},
year = {2020},
volume = {arXiv:2004.03573},
journal = {CoRR},
abstract = {Analogy is core to human cognition. It allows us to solve problems based on prior experience, it governs the way we conceptualize new information, and it even influences our visual perception. The importance of analogy to humans has made it an active area of research in the broader field of artificial intelligence, resulting in data-efficient models that learn and reason in human-like ways. While cognitive perspectives of analogy and deep learning have generally been studied independently of one another, the integration of the two lines of research is a promising step towards more robust and efficient learning techniques. As part of a growing body of research on such an integration, we introduce the Analogical Matching Network: a neural architecture that learns to produce analogies between structured, symbolic representations that are largely consistent with the principles of Structure-Mapping Theory.}
}
@article{LiangetalCoRR-16,
author = {Chen Liang and Jonathan Berant and Quoc Le and Kenneth D. Forbus and Ni Lao},
title = {Neural Symbolic Machines: Learning Semantic Parsers on Freebase with Weak Supervision},
journal = {CoRR},
volume = {arXiv:1611.00020},
year = {2016},
abstract = {Harnessing the statistical power of neural networks to perform language understanding and symbolic reasoning is difficult, when it requires executing efficient discrete operations against a large knowledge-base. In this work, we introduce a Neural Symbolic Machine (NSM), which contains (a) a neural "programmer", i.e., a sequence-to-sequence model that maps language utterances to programs and utilizes a key-variable memory to handle compositionality (b) a symbolic "computer", i.e., a Lisp interpreter that performs program execution, and helps find good programs by pruning the search space. We apply REINFORCE to directly optimize the task reward of this structured prediction problem. To train with weak supervision and improve the stability of REINFORCE we augment it with an iterative maximum-likelihood training process. NSM outperforms the state-of-the-art on the WEBQUESTIONSSP dataset when trained from question-answer pairs only, without requiring any feature engineering or domain-specific knowledge.}
}
@article{GentnerCS-83,
author = {Dedre Gentner},
title = {{Structure-mapping: A theoretical framework for analogy}},
journal = {Cognitive Science},
volume = {7},
number = {2},
year = {1983},
pages = {155-170},
abstract = {A theory of analogy must describe how the meaning of an analogy is derived from the meanings of its parts. In the structure-mapping theory, the interpretation rules are characterized as implicit rules for mapping knowledge about a base domain into a target domain. Two important features of the theory are (a) the rules depend only on syntactic properties of the knowledge representation, and not on the specific content of the domains; and (b) the theoretical framework allows analogies to be distinguished cleanly from literal similarity statements, applications of abstractions, and other kinds of comparisons. Two mapping principles are described: (a) Relations between objects, rather than attributes of objects, are mapped from base to target; and (b) The particular relations mapped are determined by systematicity, as defined by the existence of higher-order relations.}
}
BibTeX references relevant to embedding techniques for neural programming:
@article{AlonetalICLR-19,
booktitle = {International Conference on Learning Representations},
author = {Uri Alon and Omer Levy and Eran Yahav},
title = {code2seq: Generating Sequences from Structured Representations of Code},
year = {2019},
abstract = {The ability to generate natural language sequences from source code snippets can be used for code summarization, documentation, and retrieval. Sequence-to-sequence (seq2seq) models, adopted from neural machine translation (NMT), have achieved state-of-the-art performance on these tasks by treating source code as a sequence of tokens. We present CODE2SEQ: an alternative approach that leverages the syntactic structure of programming languages to better encode source code. Our model represents a code snippet as the set of paths in its abstract syntax tree (AST) and uses attention to select the relevant paths during decoding, much like contemporary NMT models. We demonstrate the effectiveness of our approach for two tasks, two programming languages, and four datasets of up to 16M examples. Our model significantly outperforms previous models that were specifically designed for programming languages, as well as general state-of-the-art NMT models.}
}
@inproceedings{AlonetalPOPL-19,
author = {Alon, Uri and Zilberstein, Meital and Levy, Omer and Yahav, Eran},
title = {Code2vec: Learning Distributed Representations of Code},
publisher = {Association for Computing Machinery},
booktitle = {Proceedings of the ACM on Programming Languages},
address = {New York, NY, USA},
volume = {3},
year = {2019},
abstract = {We present a neural model for representing snippets of code as continuous distributed vectors (code embeddings). The main idea is to represent a code snippet as a single fixed-length code vector, which can be used to predict semantic properties of the snippet. To this end, code is first decomposed to a collection of paths in its abstract syntax tree. Then, the network learns the atomic representation of each path while simultaneously learning how to aggregate a set of them. We demonstrate the effectiveness of our approach by using it to predict a method's name from the vector representation of its body. We evaluate our approach by training a model on a dataset of 12M methods. We show that code vectors trained on this dataset can predict method names from files that were unobserved during training. Furthermore, we show that our model learns useful method name vectors that capture semantic similarities, combinations, and analogies. A comparison of our approach to previous techniques over the same dataset shows an improvement of more than 75\%, making it the first to successfully predict method names based on a large, cross-project corpus. Our trained model, visualizations and vector similarities are available as an interactive online demo at http://code2vec.org. The code, data and trained models are available at https://github.com/tech-srl/code2vec.},
}
@article{ChiangetalBIOXRIV-19,
author = {Chiang, Jeffrey N. and Peng, Yujia and Lu, Hongjing and Holyoak, Keith J. and Monti, Martin M.},
title = {Distributed Code for Semantic Relations Predicts Neural Similarity},
journal = {bioRxiv},
year = {2019},
publisher = {Cold Spring Harbor Laboratory},
abstract = {The ability to generate and process semantic relations is central to many aspects of human cognition. Theorists have long debated whether such relations are coded as atomistic links in a semantic network, or as distributed patterns over some core set of abstract relations. The form and content of the conceptual and neural representations of semantic relations remains to be empirically established. The present study combined computational modeling and neuroimaging to investigate the representation and comparison of abstract semantic relations in the brain. By using sequential presentation of verbal analogies, we decoupled the neural activity associated with encoding the representation of the first-order semantic relation between words in a pair from that associated with the second-order comparison of two relations. We tested alternative computational models of relational similarity in order to distinguish between rival accounts of how semantic relations are coded and compared in the brain. Analyses of neural similarity patterns supported the hypothesis that semantic relations are coded, in the parietal cortex, as distributed representations over a pool of abstract relations specified in a theory-based taxonomy. These representations, in turn, provide the immediate inputs to the process of analogical comparison, which draws on a broad frontoparietal network. This study sheds light not only on the form of relation representations but also on their specific content.Significance Relations provide basic building blocks for language and thought. For the past half century, cognitive scientists exploring human semantic memory have sought to identify the code for relations. In a neuroimaging paradigm, we tested alternative computational models of relation processing that predict patterns of neural similarity during distinct phases of analogical reasoning. The findings allowed us to draw inferences not only about the form of relation representations, but also about their specific content. The core of these distributed representations is based on a relatively small number of abstract relation types specified in a theory-based taxonomy. This study helps to resolve a longstanding debate concerning the nature of the conceptual and neural code for semantic relations in the mind and brain.},
}
@inproceedings{HilletalICLR-19,
author = {Felix Hill and Adam Santoro and David G. T. Barrett and Ari S. Morcos and Timothy P. Lillicrap},
title = {Learning to Make Analogies by Contrasting Abstract Relational Structure},
booktitle = {International Conference on Learning Representations},
comment = {arXiv:1902.00120},
year = {2019},
abstract = {Analogical reasoning has been a principal focus of various waves of AI research. Analogy is particularly challenging for machines because it requires relational structures to be represented such that they can be flexibly applied across diverse domains of experience. Here, we study how analogical reasoning can be induced in neural networks that learn to perceive and reason about raw visual data. We find that the critical factor for inducing such a capacity is not an elaborate architecture, but rather, careful attention to the choice of data and the manner in which it is presented to the model. The most robust capacity for analogical reasoning is induced when networks learn analogies by contrasting abstract relational structures in their input domains, a training method that uses only the input data to force models to learn about important abstract features. Using this technique we demonstrate capacities for complex, visual and symbolic analogy making and generalisation in even the simplest neural network architectures.}
}
@article{WangandSuPOPL-19,
author = {Ke Wang and Zhendong Su},
title = {Learning Blended, Precise Semantic Program Embeddings},
journal = {CoRR},
volume = {arXiv:1907.02136},
year = {2019},
abstract = {Learning neural program embeddings is key to utilizing deep neural networks in program languages research --- precise and efficient program representations enable the application of deep models to a wide range of program analysis tasks. Existing approaches predominately learn to embed programs from their source code, and, as a result, they do not capture deep, precise program semantics. On the other hand, models learned from runtime information critically depend on the quality of program executions, thus leading to trained models with highly variant quality. This paper tackles these inherent weaknesses of prior approaches by introducing a new deep neural network, liger, which learns program representations from a mixture of symbolic and concrete execution traces. We have evaluated liger on coset, a recently proposed benchmark suite for evaluating neural program embeddings. Results show liger (1) is significantly more accurate than the state-of-the-art syntax-based models Gated Graph Neural Network and code2vec in classifying program semantics, and (2) requires on average 10x fewer executions covering 74\% fewer paths than the state-of-the-art dynamic model dypro. Furthermore, we extend liger to predict the name for a method from its body's vector representation. Learning on the same set of functions (more than 170K in total), liger significantly outperforms code2seq, the previous state-of-the-art for method name prediction.}
}
38 Here are Juliette Love's notes summarizing our discussion on Monday, April 5 relating to learning programmer's apprentice models that rely primarily on relatively primitive but very effective means of signaling, e.g., pointing – identifying a variable or missing parentheses in the code, highlighting – identifying a region of the shared monitor screen that contains a relevant subexpression in a code listing, gesture – using the mouse to connect two subexpressions such as variable's declaration and its subsequent initial assignment in the same (lexical) scope, and minimum understanding of natural language – using pretrained network for sentiment analysis to signal approval or disapproval of the assistant's most recent changes to the code listing.
Communication and language acquisitionHumans developed language as a way to coordinate their procedures and behavior, and transfer knowledge. The most basic requirement for achieving this coordination (as well as language acquisition) is shared attention – learning to infer what someone is referring to. Even the most rudimental communication is mediated by signing (such as pointing) that helps direct the listener’s attention. Animals have these same language-like communication processes, and can coordinate their behavior even without using natural language as we know it, in sophisticated ways we cannot fully understand.
Grounding—the use of metaphors from a shared environment—is critical to the expressive power of language. We can get a lot of information from very few words because of the shared ground: when someone says some event or time "flew by," we can use all of the associations we have with the word "flew," including those to events/processes in the physical world, to infer what they mean even if we hadn’t heard the word in that context before. This grounding is also the reason we use physical objects for many coding primitives. When children first learn language, they are figuring out how to establish this shared ground. Mothers instinctively know how to engage their babies at the right level of complexity, as they gradually increase the expressiveness of their words as they see how their babies react and learn to establish this ground.
Training protocol structure (IAG paper)
As described in the Abramson et al paper, DeepMind used a training protocol in which two agents interact in a simple virtual environment. The "setter" agent looks around the environment and describes tasks like "put the block on the table"; the "getter" then has to (a) understand what the setter is trying to get them to achieve, and (b) execute that task.
Our goal would be to develop an analogous training protocol that is more specific to the problem of the programmer’s apprentice, where the getter agent takes the role of the apprentice.
To do so, we need to design tasks for 3 types of agents:
1. A "prompter," which is just a piece of code inside the curriculum model that makes general prompt suggestions to guide the level and difficulty of the problems that the setter can pose.
2. A "setter", which takes actions and serves prompts to the getter. The setter can do two things to indicate behavior to the getter and draw its attention: it can "look around" at the code (perhaps by scrolling, highlighting, or moving a mouse), and (possibly) use language as well. It then serves a task to the getter that is relevant to that piece of code. We will want to develop a few types of tasks that the setter can pick from, such as copy and pasting, simple editing or deletion, variable renaming, etc.
3. A "getter", which learns to attend to the setter’s prompts and execute the tasks it is served. As in real language learning, the interaction between the setter and the getter is bidirectional—the two have to continue to interact as the getter makes errors. There are two difficult problems here: interpreting the setter’s prompts, and actually carrying them out. Because coding is a much more brittle environment than the physically-based one that DeepMind employed, getting it almost-correctly will cause code errors just as getting a task completely incorrectly will. There might be interesting ways for the getter to communicate back to the setter other than with the actions it’s taking, which might alleviate this problem—this is likely out of our scope, but since the programmer’s apprentice builds an underlying embedded AST representation of the code, there might be some way for the apprentice to communicate its intention in editing the code back to the programmer, allowing for useful learning in cases where the apprentice’s understanding of the prompt and strategy for solving it is correct but has not been trained enough to generate syntactically-correct code.
However, as described in the Abramson paper [2], the space of potential states for the getter is prohibitively high-dimensional for using this training method alone. To help the getter achieve minimal competency, we want to bias it towards the much smaller space of useful states, so we need to use a fourth agent, a "demonstrator," which has the same RL network as the getter but only operates in a small, useful subspace of the getter’s full state space (see the section on GAIL in Abramson, pg. 14–15). The goal is to estimate a prior for the demonstrator and then train the getter to have the same prior as the demonstrator.
Training notes for the Programmer’s Apprentice problem
These are some unorganized first notes about applying these concepts to the programmer’s apprentice problem.
As mentioned above, the most basic prerequisite for language understanding is shared attention. One of the first things a baby learns to do, with his still-underdeveloped visual system, is to start tracking things that move. We need to recreate this behavior in the getter, which has to be inquisitive and learn to track what happens on the screen when the setter takes an action or makes a modification. Ideally the getter figures out some semantic information by tracking the mouse or syntax highlighting, and if the setter is able to use language in our protocol, to listen for common words.
The next step is for the getter to be able to take actions based on the cues it picks up from attending to the setter. In the DeepMind paper these actions are turns in language games, which come in a few different varieties, each geared at learning one thing.
In that paper the getter has a clear set of actions: it can move around, can highlight (point to) things, pick things up, etc.—physical things which have analogs in apprentice. We’ll have to develop a repertoire of actions the getter can take and tasks that it can achieve within the domain of programming. Actions might include highlighting a code block, moving a cursor, or pointing to something; tasks might include copying and pasting or making a small deletion. Both the setter and the getter have the ability to evaluate lines of code. Just as in the DeepMind paper, the getter apprentice can make errors (for example, leaving a variable unbound), so a highly-trained getter could learn rules like all variables must be bound if you reference them (and thus learn to check for unbound variables). The eventual goal might be for the getter to be able to do basic code repair. Regarding the setter, we want it to be able to provide feedback to the getter of the type a mother might provide to her child. There is lots of nuance here—mothers will continue to correct their children up to a point at which they determine some particular rule is a "lost cause" and that their child will learn the correct thing eventually.
Since teaching people how to code is typically done more formally (think MOOCs, intro CS courses at universities, etc) than teaching infants language skills (which is mostly done instinctually), there are likely pre-existing resources which can help with different pieces of this problem. It may be possible to largely automate the demonstrator using these resources—for example, we could take code from CS106A students, and generate training sets where each example consists of a single line of code before and after a fix has been applied. Suppose we could take all intro computer science courses on platforms like Khan Academy and Coursera. If a student keeps trying and failing to achieve a simple task, those platforms have heuristics that suggest different lessons based on the errors they are making.
Restricting the problem space is critical to training the setter and getter, so we will have to carefully define the set of possible actions each can take and the set of information they can access. DeepMind uses Mechanical Turk workers to generate their training data for the setter (and the getter as well, somewhat), who have to be supervised and trained to initiate language games without deviating from the problem space. The DeepMind researchers attempt to leverage the fact that restrictions in our behaviour (our field of view) help us ground our observations and reactions. The physical constraints for the setter and getter in their protocol would be mirrored by syntactic constraints in the apprentice application.
Finally, we can look at Rishabh Singh’s work (speaking with us on April 13) on program interpretation and repair, which uses an encoder/decoder structure on a broken program and a trace of running variables [240].
39 You can find my notes explaining the results of Tishby and Polani [232] here. In the introductory material on biologically inspired models (PDF) search for "Fuster" to find material on the perception-action cycle and hierarchical representations in the primate brain. Here's the BibTex reference and abstract for the above paper by Tishby and Polani:
@inproceedings{TishbyandPolaniITDA-11,
title = {Information Theory of Decisions and Actions},
author = {Naftali Tishby and Daniel Polani},
booktitle = {Perception-Action Cycle: Models, Architectures, and Hardware},
editor = {Cutsuridis, V. and Hussain, A. and Taylor, J.G.},
publisher = {Springer New York},
year = {2011},
abstract = {The perception-action cycle is often defined as "the circular flow of information between an organism and its environment in the course of a sensory guided sequence of actions towards a goal" (Fuster 2001, 2006). The question we address in this paper is in what sense this "flow of information" can be described by Shannon's measures of information introduced in his mathematical theory of communication. We provide an affirmative answer to this question using an intriguing analogy between Shannon's classical model of communication and the Perception-Action-Cycle. In particular, decision and action sequences turn out to be directly analogous to codes in communication, and their complexity - the minimal number of (binary) decisions required for reaching a goal - directly bounded by information measures, as in communication. This analogy allows us to extend the standard Reinforcement Learning framework. The latter considers the future expected reward in the course of a behaviour sequence towards a goal (value-to-go). Here, we additionally incorporate a measure of information associated with this sequence: the cumulated information processing cost or bandwidth required to specify the future decision and action sequence (information-to-go). Using a graphical model, we derive a recursive Bellman optimality equation for information measures, in analogy to Reinforcement Learning; from this, we obtain new algorithms for calculating the optimal trade-off between the value-to-go and the required information-to-go, unifying the ideas behind the Bellman and the Blahut-Arimoto iterations. This trade-off between value-to-go and information-togo provides a complete analogy with the compression-distortion trade-off in source coding. The present new formulation connects seemingly unrelated optimization problems. The algorithm is demonstrated on grid world examples.}
}
40 Extelligence is a term coined by Ian Stewart and Jack Cohen in their 1997 book Figments of Reality. They define it as the cultural capital that is available to us in the form of external media, including tribal legends, folklore, nursery rhymes, books, film, videos, etc. (SOURCE)
41 Most of us have observed or been the victim of the airplane trick – perhaps your parents used some variant of it on you. This is highchair-feeding gambit where the parent waves around a spoon heaped some type of baby pablum that badies tend not to like, and coos invitingly something like "here comes the airplane", open up wide. Typically the baby sees through this subterfuge and keeps his or hermouth sealed tight.
42 Recent research developing neural network architectures with external memory have often used the benchmark bAbI question and answering dataset which provides a challenging number of tasks requiring reasoning. Here we employed a classic associative inference task from the memory-based reasoning neuroscience literature in order to more carefully probe the reasoning capacity of existing memory-augmented architectures.
This task is thought to capture the essence of reasoning – the appreciation of distant relationships among elements distributed across multiple facts or memories. Surprisingly, we found that current architectures struggle to reason over long distance associations. Similar results were obtained on a more complex task involving finding the shortest path between nodes in a path. We therefore developed MEMO, an architecture endowed with the capacity to reason over longer distances.
This was accomplished with the addition of two novel components. First, it introduces a separation between memories (facts) stored in external memory and the items that comprise these facts in external memory. Second, it makes use of an adaptive retrieval mechanism, allowing a variable number of "memory hops" before the answer is produced. MEMO is capable of solving our novel reasoning tasks, as well as match state of the art results in bAbI. (SOURCE)
43 Fetal movement refers to motion of a fetus caused by its own muscle activity. Locomotor activity begins during the late embryological stage and changes in nature throughout development. Muscles begin to move as soon as they are innervated. These first movements are not reflexive, but arise from self-generated nerve impulses originating in the spinal cord. As the nervous system matures, muscles can move in response to stimuli. Even before the fetal stage begins, a six-week-old human embryo can arch its back and neck (SOURCE)
44 The CISC approach attempts to minimize the number of instructions per program, sacrificing the number of cycles per instruction. RISC does the opposite, reducing the cycles per instruction at the cost of the number of instructions per program. A complex instruction set computer (CISC) is a computer in which single instructions can execute several low-level operations or are capable of multi-step operations or addressing modes within single instructions. (SOURCE)
45 The purpose of the graphic is to anchor the task in the context of a future presentation to the rest of the class – specifically the (other) team responsible for coming up with the method for representing and reasoning about (computer) programs and embedding knowledge about programs in natural language to enable support for analogical reasoning. Figure 10 provides a rough example of what it might look at.
| |
| Figure 10: This graphic provides an example of a slide intended as a visual aid for a set talking points in a presentation describing some of the main concepts in [65]. It is expected that the team focusing on realizing these concepts in a model of language acquisition would prepare such a presentation with help from Eve Clark and Greg Wayne and then present their ideas to the rest of the class. | |
|
|

{kind=link}
46 The time line serves as an anchor and means for organizing key elements of the overall project, specifically in this case the first stage of developing a curriculum learning strategy [29, 36]. I expect that for each sort of language-learning engagement we will find one or more existing technologies for approximately implementing it to construct a plausible curriculum [2].
47 Again, there has been a lot of work in cognitive science, computational linguistics, human-robot interaction, multimedia user interfaces and natural language processing addressing related issues. The intent here is to borrow, adapt and apply methods from these disciplines in the spirit of this exercise being a gedancken experiment proof of concept.
48 Keep in mind that this exercise would be nigh on impossible and certainly a huge channel were it not for the work of the Interactive Agents Group at DeepMind. At every turn, students will be encouraged to draw upon the 2020 DM paper as well as take advantage of the opportunity to as Greg Wayne for suggestions where to look for guidance.
49 While working at Google, publishing papers in academic venues was not nearly as important to me as it was when I was a professor and advising graduate students at Brown University. I did however publish a lot of internal technical papers and often worked with students taking my class at Stanford to produce a paper summarizing the lessons we learned and ideas we generated during the quarter. Here are two examples:
@article{DeanetalCoRR-18,
title = {{Amanuensis: The Programmer's Apprentice}},
author = {Thomas Dean and Maurice Chiang and Marcus Gomez and Nate Gruver and Yousef Hindy and Michelle Lam and Peter Lu and Sophia Sanchez and Rohun Saxena and Michael Smith and Lucy Wang and Catherine Wong},
journal = {CoRR},
volume = {arXiv:1807.00082},
year = 2018,
url = {http://arxiv.org/abs/1807.00082},
}
@misc{DeanDIACRITICAL-14,
title = {Interaction and Negotiation in Learning and Understanding Dialog},
author = {Thomas Dean},
year = {2014},
howpublished = {{\tt{https://web.stanford.edu/class/cs379c/resources/dialogical/zanax_DOC.dir/index.html}}},
abstract = {Interaction and negotiation are an essential component of natural language understanding in conversation. We argue this is particularly the case in building artificial agents that rely primarily on language to interact with humans. Rather than thinking about misunderstanding-thinking the user said one thing when he said another-and non-understanding-not having a clue what the user was talking about-as a problem to be overcome, it makes more sense to think of such events as opportunities to learn something and a natural part of understanding that becomes essential when the agent trying to understand has a limited language understanding capability. Moreover, many of the same strategies that are effective in situations in which the agent's limited language facility fails also apply to the agent actively engaging the user in an unobtrusive manner to collect data and ground truth in order to extend its repertoire of services that it can render and to improve its existing language understanding capabilities. In the case of developing an agent to engage users in conversations about music, actively soliciting information from users about their music interests and resolving misunderstandings on both sides about what services the application can offer and what service in particular the user wants now is already a natural part of the conversation. Data collected from thousands or millions of users would provide an invaluable resource for training NLP components that could be used to build more sophisticated conversational agents.}
}
50 Hierarchical planning has long history in artificial intelligence. The original work on hierarchical task networks was based on STRIPS by Richard Fikes and Nils Nilsson [98] at SRI in 1971 and would probably be classified as GOFAI (acronym for "Good Old Fashioned Artificial Intelligence") were it not for the fact that the term is now applied to work on hierarchical reinforcement learning. (SOURCE)
51 Here is a sample of papers on the approach taken in the CMU RavenClaw/Olympus framework for handling errors in spoken language interfaces:
@article{BohusandRudnickyCS-09,
author = {Bohus, Dan and Rudnicky, Alexander I.},
title = {The RavenClaw Dialogue Management Framework: Architecture and Systems},
journal = {Computer Speech and Language},
publisher = {Academic Press Ltd.},
volume = 23,
issue = 3,
year = 2009,
pages = {332-361},
abstract = {In this paper, we describe RavenClaw, a plan-based, task-independent dialog management framework. RavenClaw isolates the domain-specific aspects of the dialog control logic from domain-independent conversational skills, and in the process facilitates rapid development of mixed-initiative systems operating in complex, task-oriented domains. System developers can focus exclusively on describing the dialog task control logic, while a large number of domain-independent conversational skills such as error handling, timing and turn-taking are transparently supported and enforced by the RavenClaw dialog engine. To date, RavenClaw has been used to construct and deploy a large number of systems, spanning different domains and interaction styles, such as information access, guidance through procedures, command-and-control, medical diagnosis, etc. The framework has easily adapted to all of these domains, indicating a high degree of versatility and scalability.},
}
@inproceedings{BohusandRudnickyHLTEMNLP-05,
author = {Dan Bohus and Alexander I. Rudnicky},
title = {Error handling in the RavenClaw dialog management architecture},
booktitle = {In Proceedings of the Human Language Technology Conference Conference on Empirical Methods in Natural Language Processing},
year = 2005,
}
@phdthesis{BohusPhD-07,
author = {Dan Bohus},
title = {Error Awareness and Recovery in Conversational Spoken Language Interfaces},
school = {Carnegie Mellon University},
year = 2007,
}
52 A lingua franca, also known as a bridge language, common language, trade language, auxiliary language, vehicular language, or link language, is a language or dialect systematically used to make communication possible between groups of people who do not share a native language or dialect, particularly when it is a third language that is distinct from both of the speakers' native languages. (SOURCE)
53 A ring is a set R equipped with two binary operations + and · satisfying the following three sets of axioms, called the ring axioms: (i) R is an abelian group under addition, meaning that (a + b) + c = a + (b + c) for all a, b, c in R implying + is associative, (ii) R is a monoid under multiplication and (iii) multiplication is both associative and distributive. (SOURCE)
54 The nervous system comprises the central nervous system, consisting of the brain and spinal cord, and the peripheral nervous system, consisting of the cranial, spinal, and peripheral nerves, together with their motor and sensory endings. (SOURCE)
55 In computing, an arithmetic logic unit (ALU) is a combinational digital circuit that performs arithmetic and bitwise operations on integer binary numbers. The inputs to an ALU are the data to be operated on, called operands, and a code indicating the operation to be performed; the ALU's output is the result of the performed operation. (SOURCE)
56 Assembly language instructions usually consist of an opcode mnemonic followed by a list of data, arguments or parameters. These are translated by an assembler into machine language instructions that can be loaded into memory and executed. (SOURCE)
57 In computing, language primitives are the simplest elements available in a programming language. A primitive is the smallest 'unit of processing' available to a programmer of a given machine, or can be an atomic element of an expression in a language. (SOURCE)
58 Here is the title, abstract and link to a white paper on the importance of interaction and negotiation in dialogue generally and human-machine question-answering interfaces in particular. The python code for the demonstration program is available here if you are interested:
@misc{DeanDIACRITICAL-14,
title = {Interaction and Negotiation in Learning and Understanding Dialog},
author = {Thomas Dean},
year = {2014},
howpublished = {{\tt{https://web.stanford.edu/class/cs379c/resources/dialogical/zanax_DOC.dir/index.html}}},
abstract = {Interaction and negotiation are an essential component of natural language understanding in conversation. We argue this is particularly the case in building artificial agents that rely primarily on language to interact with humans. Rather than thinking about misunderstanding-thinking the user said one thing when he said another-and non-understanding-not having a clue what the user was talking about-as a problem to be overcome, it makes more sense to think of such events as opportunities to learn something and a natural part of understanding that becomes essential when the agent trying to understand has a limited language understanding capability. Moreover, many of the same strategies that are effective in situations in which the agent's limited language facility fails also apply to the agent actively engaging the user in an unobtrusive manner to collect data and ground truth in order to extend its repertoire of services that it can render and to improve its existing language understanding capabilities. In the case of developing an agent to engage users in conversations about music, actively soliciting information from users about their music interests and resolving misunderstandings on both sides about what services the application can offer and what service in particular the user wants now is already a natural part of the conversation. Data collected from thousands or millions of users would provide an invaluable resource for training NLP components that could be used to build more sophisticated conversational agents.}
}
59 The following is an excerpt from Eve Clark's [66] paper entitled "Grounding and attention in language acquisition" that you may find informative in thinking about the Abramson et al [2] paper on imitative interacting intelligence. The only available version of the paper, which appeared in the 37th meeting of the Chicago Linguistic Society, is available here, and the following is a transcript of my reading a sample of relevant passages, so forgive the occasional errors due to my reading or the transcription software:
Introduction
Grounding – the establishing of common ground – plays a critical role in all conversational exchanges. In this talk I examine grounding first as adults work to achieve joint attention with one-year-olds when they introduce them to unfamiliar objects; second as adults offer unfamiliar words and link them to familiar ones; and third as adults check on what their children mean when the children make errors in what they say. In each case, I argue that the achievement of joint attention for grounding allows adults to offer children the relevant conventional forms and track children's uptake of these words in the course of conversation.
With very young children, adults may work to achieve joint attention before they can add to common ground. They begin with attention-getters that are non-verbal (gaze, gestures, touch) as well as verbal (calls for attention, name-use); once the child is attending, they use deictic terms to introduce terms for new objects, and often rely on gesture and demonstration as well, to maintain attention.
Adults typically offer new words along with deictic terms that emphasize the importance of physical co-presence in each conversational exchange. They also often anchor new, unfamiliar terms to terms already known to the child. They do this by relating the new word to other words through set membership, parts, properties, function, and other common relations. They may also offer definitions and identify the relevant domain through listing of familiar terms.
Finally, they offer reformulations for erroneous child utterances as they check up on just what the child intended by what he said. Their reformulations appear as part of side-sequences and as embedded repairs; they serve to offer the usual (adult) pronunciation, correct inflection, the right word, the appropriate construction – in short, the conventional forms that the child should use as a member of the speech community.
Grounding
What is grounding? It is the ongoing process of establishing common ground in order to enable the joint projects of speaker and addressee in any exchange. The participant in a conversation must establish each element added to common ground "well enough for current purposes" (H. Clark 1996). With each contribution to conversation, the current speaker adds information that then becomes part of the common-ground. Grounding occurs at each step in a communicative exchange, as speaker and addressee alternate in their contributions. With each utterance, each one adds more to what is currently in the common ground. The choice of just what to add at each step, of course, depends on both the local and ultimate goals of the exchange. The point I wish to make here is that common ground is accumulated as much as with children as with adult participants in conversation. In this paper, I focus on two aspects of common ground: first, how one achieves common ground with unskilled speakers, namely young children just beginning to learn their first language, and second the role common ground plays in relation to the kinds of information adults offer children about language use ("pragmatic directions") from the very beginning.
Establishing common-ground is important because it offers a "forum" where (a) children can solve the general mapping problem between form and meaning when offered new words; where (b) they can take up conventional terms for unfamiliar objects and events, and see how they relate to familiar terms already known when offered relations and information about properties and functions; and where (c) they take up information about what they should have said when they have produced an erroneous utterance of some kind when offered reformulations as implicit corrections of erroneous utterances. In each case, adults offer a new piece of the language that, because it has been presented and so added to common ground, is now "on stage", in the center of attention, for the language-learner. As a result, I argue, grounding underpins the process of acquisition. The accumulation of common-ground in the center of attention, in the course communicating, provides young children with invaluable information about all aspects of language and how to use it.
[...]
Joint Attention
Before young children can begin to link word-forms with any sort of meaning, they need to hear the target word in an appropriate context and be attending to it at the right time. So when parents offer them a word for something new, they need to be quite sure their children are attending at that instant to the intended referent. So joint attention should be critical for new-word offers: without it there is no grounding and no evidence that children have even registered the offer of a new word.
How do a adults achieve joint-attention when they talk to small children? Consider a few examples of what goes on as parents try to establish joint attention with their young one-year-olds in order to show them some unfamiliar objects. in the first exchange, Joey's mother tries six times to get his attention before he attends to her. She uses his name twice in succession, then touches his cheek, then uses his name again. (Each name use was uttered with increasing intensity and volume.) She then switches to look for the next attempt at gaining his attention, then tries an endearment combined with look as she switches her own gaze to the toy crocodile under consideration. It was only at this point that the child looked at the object and so gave evidence of joint attention.
[...]
Relationships
When adults offer words, they also often anchor the new words to other more familiar ones through various relations. These relations take several forms and can be introduced in different ways. The main ways observed in the corpora we have analyzed are listed below. What is important about each of them, though, is that they provide a further way to add to common ground the new term that has been offered. The common ground in each instance is the adult's and child's knowledge of, or recognition of, the specific relation that links the new word to others that are already familiar.
[...]
Reformulation
Adults do more than offer children unfamiliar words and link them to other terms and to general information about the categories involved. They also offer them conventional forms for the expression of different intentions. These offers of conventional forms present a form of grounding since they place children on notice that both that their intention has been understood and that this is the way to convey what they intended.
These offers include the conventional pronunciation of words, and the conventional inflections for marking distinctions on verbs or nouns; they include appropriate lexical choices for marking specific meanings where there is a conventional form available. And they include offers of the appropriate syntactic constructions for conveying particular meanings. When these offers of conventional forms for utterances follow immediately after erroneous utterances from children, they could provide children with a form of negative evidence. And they may well do. Adults are significantly more likely to offer conventional reformulations after child errors than after utterances without errors. Moreover children attend to and take up these offers, sometimes right away, as when they repeat the conventional forms provided and incorporate them into their next turn.
[...]
Both children and adults add to common ground in all these ways. What's important from the children's point of view is that what is being added in these cases is information on how to use the language – what the word is for something, how that word is connected to others in the relevant domain, or how it is connected to some other information considered pertinent, and just how to say what the child wants to say. Each element contributes to what children know about the language they are acquiring.
Since common ground is dynamic, not static, each contribution in a conversation changes the current content of the participants' common ground. Each adult offer of a word adds to common ground ; as does any accompanying gaze, gesture, or demonstration, that can contribute to the meaning thereby assigned. Throughout an exchange, then, the participants steadily accumulate this common ground, as each contribution is added.
Notice that to start and maintain an exchange, the participants must have each other's attention; in addition, they have to have some goal (a local or more general project) that each other and helps advance – whether the utterance is co-constructed (with two or more speakers) or produced by one person. Each such advance (typically associated with a turn) adds to the common ground the participant share. By linking a new word just offered to other familiar words in some way, adult also license further inferences about the meaning that is to be associated with a new word as they add still more to common ground for that occasion. And by checking on the child's intended meanings with repeats or reformulations, adult add to the common ground for that specific exchange. In accepting the interpretations given in this way, children ratify the placement of those utterances in common ground.
60 This episode of Andrew Huberman's podcast is all about the two major kinds of dreams and the sorts of learning and unlearning they are used for. In his introduction, Huberman writes "I discuss REM-associated dreams that control emotional learning and their similarity to various trauma treatments such as ketamine and EMDR. I also discuss Non-REM dreams and their role in motor learning and learning of detailed, non-emotionally-laden information. I relate this to science-backed tools for accessing more of the types of sleep and learning people may want. Other topics are listed in the time stamps below."
The rough transcript is provided to facilitate search and my primary reason for including it in the class notes is to bring your attention to his comments about how in REM sleep we review or replay the days events, identifying what is most relevant – important – to us and constructing relationships between those relevant events and our past experience and current goals. I also did a literature search and came up with several useful references including the two you can find here.
Timestamps below.
00:00 Introduction 03:00 The Dream Mask 06:00 Cycling Sleep 08:10 Chemical Cocktails of Sleep 13:00 Motor Learning 16:30 High Performance with Less Sleep 17:45 Rapid Eye Movement Sleep 20:30 Paralysis & Hallucinations 23:35 Nightmares 24:45 When REM & Waking Collide 25:00 Sleeping While Awake 26:45 Alien Abductions 29:00 Irritability 30:00 Sleep to Delete 32:25 Creating Meaning 34:10 Adults Acting Like Children 36:20 Trauma & REM 37:15 EMDR 39:10 Demo 44:25 Ketamine / PCP 45:45 Soup, Explosions, & NMDA 48:55 Self Therapy 50:30 Note About Hormones 51:40 Measuring REM / SWS 53:15 Sleep Consistency 56:00 Bed Wetting 58:00 Serotonin 59:00 Increasing SWS 59:50 Lucidity 1:02:15 Booze / Weed 1:03:50 Scripting Dreams 1:04:35 Theory of Mind 1:07:55 Synthesis 1:10:00 Intermittent Sleep Deprivation 1:11:10 Snoring Disclaimer 1:11:40 New Topic 1:15:50 Corrections 1:17:25 Closing Remarks
Here's the rough transcript:
My interest in dreaming goes way back. When I was a child I had a friend and he came over one day and he brought with him a mask that had a little red light in the corner. He purchased this thing through some magazine ad that he had seen and this mask was supposed to trigger lucid dreaming.
Lucid dreaming is the experience of dreaming during sleep, but being aware that one is dreaming and in some cases being able to direct one's dream activities. So if you're in, A lucid dream and you want to fly for instance some people report being able to initiate that experience of flying or to contort themselves into an animal or to transport themselves to wherever they want within the dream.
I tried this device. The way it worked is you put on the the mask during the waking state right away, can you look at the little light flashing in the corner and then you'd also wear it when you went to sleep at night and indeed while I was asleep I could see the red light, presumably through my eyelids, although parole.
I knew I had opened my eyes. I didn't know I was asleep. And then, because I was dreaming and I was experiencing something very vivid. I was able to recognize that I was dreaming and then start to direct some of the events within that dream. Now lucid dreaming occurs in about 20% of people and in a small percentage of those people they lucid dream almost every night.
So much so that many of them report their sleep not being as restorative as it would be otherwise. Now all of this is to say that lucid dreaming and dreaming are profound experiences. We tend to feel extremely attached to our dream experience. This may explain the phenomenon of people who have a very intense dream they need to somehow tell everybody about that dream or tell someone about that dream I don't really know what that behavior is about but sometimes we wake up and we feel so attached to what happened in this state that we call dreaming that there seems to be an intense need to share it with other people presumably to process it and make sense of it.
Now numerous people throughout history have tried to make sense of dreams and in some sort of organized way the most famous of which of course is a Sigmund. Freud who talked about symbolic representations in dreams. A lot of that has been kind of debunked, although I think that There's some interest in what the symbols of dreaming are and this is something that we'll talk about in more depth today, although not Freudian theory in particular.
So I think in order to really think about dreams and what to do with them and how to maximize the dream experience for sake of learning and unlearning the best way to address this is to look at the physiology of sleep to really just what do we know concretely about sleep?
So first of all as we get sleepy, We tend to shut our eyes and that's because there are some autonomic centers in the brain and some neurons that control closing of the eyelids when we get sleepy. And then we transition into sleep and sleep regardless of how long we sleep is generally broken up into a series of 90-minute cycles.
So really in the night these 90-minute cycles tend to be composed more of shallow sleep and slow-wave sleep so stage 1 stage 2 etc and what we call slow-wave sleep. I'll go into detail about what all this means in a moment. And we tend to have less so-called REM sleep REM sleep, which stands for rapid eye movement sleep, and I'll talk about rapid eye movement sleep in detail.
So early in the night a lot more slow-wave sleep and less REM. For every 90-minute cycle that we have during a night of sleep, we tend to start having more and More REM sleep So more of that 90-minute cycle consists of REM sleep and less of slow-wave sleep.
Now this is true regardless of whether or not you wake up in the middle of the night to use the restroom or your sleep is broken. The more sleep you're getting across the night the more REM sleep you're going to have. REM sleep and non-rem as I'll refer to it have distinctly different roles in learning and unlearning and they are responsible for learning and unlearning distinctly different types of information.
And this has enormous implications for learning motor skills. For unlearning of traumatic events or for processing emotionally challenging as well as emotionally pleasing events. And as we'll see one can actually leverage their daytime activities in order to access more slow-wave sleep or non-rem sleep as we'll call it or more REM sleep depending on your particular emotional and physical needs.
So it's really a remarkable stage of life that we have a lot more control and power over than you might believe. We'll also talk about lucid dreaming we're also going to talk about hallucinations and how drug-induced hallucinations have a Surprising similarity to a lot of dream states and yet some really important differences. Okay so let's start by talking about slow wave sleep or non-rimmed sleep.
Now, I realize that slow wave sleep and non-rem sleep are exactly the same thing so for you sleep a physiatos out there. I am lumping right now as we say in science, there are lumpers and there are splitters and I am both sometimes a lump, sometimes I split for sake of clarity and ease of conversation right now.
I'm gonna be a lumper. So I'm when I say slow sleep, I mean, non-rem sleep generally, although I acknowledge there is a distinction. Slow wave sleep. So slow wave sleep is characterized by a particular pattern of brain activity in which the brain is metabolically active but that there's these big sweeping waves of activity that include a lot of the brain.
If you want to look this up there you can find evidence for sweeping waves of neural activity across the association cortex across big swaths of the brain stem, the so-called pons geniculate occipital pathway, this is brainstem. Thalamus and then cortex for those of you either interested although more of that is going to occur in REM sleep.
Now the interesting thing about slow waves sleep are the neuromodulators that tend to be associated with it that are most active and least active during slow wave sleep. And here's what To remind you neuromodulators are these chemicals that act rather slowly but their main role is to bias particular brain circuits to be active and other brain circuits to not be active.
These are like the music playlist. So think of neuromodulator, S. Then these come in the names of acetylcholine or epinephrine serotonin and dopamine think of them as suggesting playlists on your audio device, so you know classical music is distinctly different in feel and tone and a number of other features from like third wave punk or from you know, hip hop right so think of them as biasing toward particular genres of neural circuit activity, okay, mellow music versus really aggressive fast music or rhythmic music that includes lyrics versus rhythmic music that doesn't include lyrics.
That's a that's more less the way to think about these neuromodulators and they are associated as a consequence with certain brain functions, so we know for instance and just to review acetylcholine in waking states is a neuromodulator that tends to amplify the activity of brain circuits associated with focus and attention norepinephrine is a neuromodulator that tends to amplify the brain circuits associated with alertness and the desire to move serotonin is the neuromodulator that's released intends to amplify the circuits in the brain and body that are associated with bliss and the desire to remain still.
And dopamine is the neuromodulator that's released and there's associated with amplification of the neural circuits in the brain and body associated with pursuing goals and pleasure and reward okay, so in slow wave sleep something really interesting happens, there's essentially no acetylcholine acetylcholine production and release an action from the two major sites which are in the brainstem which from a nucleus if the pair by geminal nucleus if you really want to know or from the four brain which is nucleus.
And you don't need to know these names but if you like that's why I put them out there acetylcholine production plummets it's just almost to zero and acetylcholine is I just mentioned is associated with focus so you can think of slow wave sleep as these big sweeping waves of activity through the brain and kind of distortion of space and time so that we're not really focusing on any one thing now the other molecules that are very active at that time are norepinephrine which is a little bit surprising because normally in waking states norepinephrine is going to be associated with a lot of alerting.
Us and the desire to move but there's not a ton of norepinephrine around in slowly sleep but it is around so there's something associated with the movement circuitry going on in slow wave sleep and remember this is happening mostly at the beginning of the night you're sleep is dominated by slow way sleep, so very no acetylcholine very little norepinephrine, although there is some and a lot of serotonin and serotonin again is associated with this desire the sensation of kind of bliss or well-being but not a lot of movement and during sleep you tend not to move now in slowly sleep, you can move you're not paralyzed.
So you can roll over if people are going to sleepwalk typically it's going to be during slow wave sleep and what studies have shown through some kind of sadistic experiments where people are deprived specifically of slow waves sleep and that can be done by waking them up in the as soon as the electrode recording show that they're in slow wave sleep or by a chemically altering their sleep so that it biases them away from slow wave sleep what studies have shown is that motor learning.
Is generally occurring in slow wave sleep. So let's say the day before you go to sleep you were learning some new dance move or you were learning some specific motor skill either a fine motor skill or a course motor skill. So let's say it's a new form of exercise or some new coordinated movements.
This could be coordinate moving at the level of the fingers or it could be coordinate movement the level the whole body and large limb movements. It could involve other people or it could be a solo activity. Learning those skills is happening primarily during slow wave sleep in the early part of the night.
In addition slow wave sleep has been shown to be important for the learning of detailed information. Now, this isn't always cognitive information. We're gonna talk about cognitive information, but the studies that have been done along these lines involve having people learn very detailed information about very specific rules and the way that certain words are spelled they tend to be challenging words.
So if people are tested, And in terms of their performance on these types of exams and they're deprived of slow wave sleep, they tend to perform very poorly. So we can think of slow waves sleep as important for motor learning, motor skill learning and for the learning of specific details about specific events.
And this turns out to be fundamentally important because now we know that slow wave sleep is primarily in the early part of the night and motor learning is occurring primarily early in the night and detail learning is occurring early in the night. Now, for those of you that are waking up.
After only three four hours of sleep this might be informative This might tell you a little something about what you are able to learn and not able to learn if that were to be the only sleep that you get although hopefully that's not the only sleep that you get but we're going to dive deep into how it is that one can maximize motor learning in order to extract say more detail information about coordinated movements and how to make them faster or slower.
So that might be important for certain sports. I might be almost certainly important for certain sports. It's going to be important. For any kind of coordinated movement like say learning to play the piano or for instance how to learn synchronized movements with somebody else. So maybe I mentioned the example of dance earlier. If you like me a few years ago, I set out to learn Tango because I have some Argentine relatives and it was abysmal. I need to return to that at some point.
I was just abysmal and one of the worst things about being abysmal at learning dance is that there's somebody else who has to suffer the consequences also. So, I don't know maybe in the month on neuroplasticity. I'll explain. That again as a self-experimentation but the key things to know are slow-wave sleeps involved in motor learning and detailed learning.
There's no acetylcholine around at that time as these big amplitude activities sweep throughout the brain and that there's the release of these neuromodulators norepinephrine and serotonin and again that's all happening early in the night. So athletes are concerned about performance if you happen to wake up after just a couple hours of you know, three four hours of sleep because you're excited about a competition the next day.
Of. Lee if you've already trained the skills that you need for the event you should be fine to engage in that particular activity Now, it's always going to be better to get a full night's sleep and you know what full night sleep with three for you at six hours and it's always going to be better to get more more sleep than it is to get less.
However, I think some people get a little bit overly concerned that if they didn't get their full night's sleep before some sort of physical event that they're performance is going to plummet presumably if you've already learned what you need to do and it's stored in your neural circuits. And you know how to make those coordinated movements with the literature on slow wave sleep suggests that you would be replenished that the motor learning and the recovery from exercise is going to happen early in the night.
So we'll just pause there and kind of shove that for a moment then we're going to come back to it. But I want to talk about REM sleep or rapid eye movement sleep REM sleep and rapid eye movements sleep, as I mentioned before occurs throughout the night but you're going to have more of it a larger percentage of these 90 minute sleep cycles is going to be comprised of REM sleep as you get toward morning REM sleep is fascinating.
It was discovered. In the 50s when sleep laboratories in Chicago the researchers observed that people's eyes were moving under their eyelids Now something very important that we're going to address when we talk about trauma later is that the eye movements are not just side to side they're very erratic in all different directions.
One thing that I don't think anyone does. I've never heard anyone really talk about publicly is why eye movements during sleep are closed and sometimes people's eyelids will be a little bit open and their eyes are darting around especially little kids. I don't suggest you do this. I'm not even sure it's ethical but it has been done with.
Me you know pull back the eyelids of a kid while they're sleeping and their eyes are kind of darting all over the place. I think people do this to their past out friends at parties and things like that. So again, I don't suggest you do it, but um, I'll tell you it because it's been done before and therefore you don't have to do it again.
But rapid eye movements sleep is fascinating and occurs because there are connections between the brainstem, an area called the pons and areas of the thalamus and the top of the brain stem that are involved in generating movements into different directions. Sometimes called although sometimes cheering on. High movement sleep, it's not just rapid it's kind of a jittery side to side thing and then the eyeballs kind of roll.
It's really pretty creepy to look at if you see. So what's happening there is that the circuitry that 's involved in conscious eye movements is kind of going haywire but it's not haywire. It's these waves of activity from the brainstem up to the so-called thalamus which is an area that filters sensory information that up to the cortex and the cortex of course is involved in conscious perceptions.
So in rapid eye movement sleep, there are a couple things that are happening besides rap and eye movements. The main ones are that they're in I should say in contrast to slow wave sleep in REM sleep serotonin is essentially absent. Okay, so this molecule, this neuromodulator that tends to create the feeling of bliss and well-being and just calm placidity is absent alright, so that's interesting.
In addition to that. Norepinephrine this molecule that's involved in movement and alertness is absolutely absent it's probably one of the few times in our in our life that epinephrine is essentially at zero activity within our system and that has a number of very important implications for the sorts of dreaming that occur during REM sleep and the sorts of learning that can occur in REM sleep and unlearning first of all in REM sleep, we are paralyzed we are we are experiencing what's called a Tonia which just means that we're completely laid out in parallel.
Ized we also tend to experience whatever it is that we're dreaming about as a kind of hallucination or a hallucinatory activity long ago. I looked into hallucinations and dreaming. I was just fascinated by this and in high school and there's some great books on this if you're interested in exploring the relationship between hallucinations and dreaming the most famous of which are from a guy researcher at Harvard Alan Hobson, now I wrote a book called dream drugstore and talked all about the similarities between drugs that induced.
Hallucinations and dreaming in REM so you can explore that if you like so in REM our eyes are moving but the rest of our body is paralyzed and we are hallucinating there's no epinephrine around epinephrine doesn't just create a desire to move an alertness it is also the chemical signature of fear and anxiety.
It's what's released from our adrenal glands when we experience something that's fearful or alerting except a car suddenly screeches in front of us or we get a troubling text message adrenaline is deployed into our system adrenaline is epinephrine those are equivalent molecules and epinephrine isn't just released from our adrenals, it's also released within our brain so there's this weird stage of our life that happens more toward morning that we call REM sleep where we're hallucinating and having these outrageous experiences in our mind but the chemical.
That's associated with fear and panic and anxiety is not available to us and that turns out to be very important and you can imagine why that's important it's important because it allows us allows us to experience things both replay of things that did occur as well as elaborate contortions of things that didn't occur and it allows us to experience those in the absence of fear and anxiety.
And that it turns out is very important for adjusting our emotional relationship to challenging things that happen to us while we were awake those challenging things can sometimes be in the form of social anxiety or just having been working very hard or concern about an upcoming event or sometimes people report for instance dreams where they find themselves late to an exam or naked in public or.
In a situation that would be very troubling to them and that almost certainly occurs during REM sleep. So we have this incredible period of sleep in which our experience of emotionally latent events is dissociated chemically blocked from us having the actual emotion. Probably immediately some of you are thinking well what about nightmares?
I have nightmares and those carry a lot of emotion or sometimes. I'll wake up in a panic. Let's consider each of those two things separately because they are important in understanding REM sleep. There's a good chance that nightmares are occurring during slow waves sleep There are actually some drugs that I don't suggest people take in fact so much so I'm not going to mention them that give people very kind of scary or eerie dreams and this kind of feeling that things are pursuing them or that they can't move when they are being chased that's actually a common dream that I've had as I guess it's more less a nightmare the feeling that one is paralyzed and can't move and is being chased.
A lot of people have said, oh that must be in REM sleep because you're paralyzed. And so you're dreaming about being paralyzed and you can't move I think that's probably false the research says that because norepinephrine is absent during REM sleep, it's very unlikely that you can have these intense fearful memories.
So those are probably occurring in slow wave sleep. Although there might be instances where people have nightmares in REM sleep. The other thing is some people experience certainly. I've had this experience of waking up and feeling very stressed about whatever it was that I happen to be thinking about or dreaming about in the moments before.
And that's an interesting case of an invasion. Of the dream state into the waking state and the moment you wake up epinephrine is available. So the research on this isn't fully crystallized, but most of it points in the direction of the experience of waking up and feeling very panicked maybe I want to highlight May but maybe that you were experiencing something that was troubling in the daytime you're repeating that experience in your sleep epinephrine is not available and therefore the brain circuits associated with fear and anxiety are shut off and so you're.
Able to process those events and then suddenly you wake up and there's a surge of adrenaline of epinephrine that's now coupled to that experience. So nightmares very likely in slow wave sleep and that kind of panic on waking from something very likely to be an invasion of the thoughts and ideas however distorted in REM sleep invading the waking state.
In fact that brings to mind something that I've mentioned once before but I want to mention again this Atonia this paralysis that we experienced during sleep can invade the waking state. Many people report the experience of waking up and being paralyzed they're legitimately waking up. It's not a dream waking up and being paralyzed and it is terrifying.
I've had this happen before it is I can tell you terrifying to be wide awake. And as far as I could tell fully conscious but unable to move and then generally you can jolt yourself out of it in a few seconds, but it is quite frightening. Now, some people actually experience waking up being fully paralyzed and hallucinating and there is a theory in the academic and scientific community, at least that what people report as alien abductions have a certain number of core characteristics that map quite closely yearly similarly to these experiences.
A lot of, Reports of alien abduction involved people being unable to move seeing particular faces hallucinating extensively feeling like their body is floating or they were transported. This is very similar to the experience of invasion of atonia into the waking state waking up and still being paralyzed as well as the hallucinations that are characteristic of dreaming in REM sleep.
Now, I'm not saying that people's alien abductions were not legitimate alien abductions, how could I I wasn't there. And if I was there, I wouldn't tell you because that would make me an alien and I wouldn't want you to know but, It is quite possible that people are experiencing these things and they are an invasion of the sleep state into the waking state and they can last several minutes or longer and because in dreams space and time are distorted our perception of these events could be that they lasted many hours and we can really feel as if they lasted many hours when in fact they took only moments and we're gonna return to distortion of space and time in a little bit.
So, To just recap where we've gone so far slow-way sleep early in the night it's been shown to be important for motor learning and for detailed learning REM sleep has a certain dream component when which there's no epinephrine therefore, we can't experience anxiety we are paralyzed those dreams tend to be really vivid and have a lot of detail to them and yet in REM sleep what's very clear is that the sorts of learning that happen in REM sleep are not motor events, it's more about unlearning of emotional events, and now we know why because the chemical.
S available for the really feeling those emotions are not present. Now that has very important implications. So let's address those implications from two sides. First of all, we should ask what happens if we don't get enough REM sleep and a scenario that happens a lot where people don't get enough room sleep is the following I'll just explain the one that I'm familiar with because it happens to me a lot although I figured out ways to adjust I go to sleep around 10:30 11 o'clock.
I fall asleep very easily and then I wake up around three or four am I now know to use a NSDR and on sleep deep breath protocol and that allows me to fall back asleep even though it's called non-sleep deep breaths, it's really allows me to relax my body and brain and I tend to fall back asleep and sleep till about 7 am during which time I get a lot of REM sleep and I know this because I've measured it and I know this because my dreams tend to be very intense of the sort that we know is typical of REM sleep.
In this scenario. I've gotten my slow a sleep early in the night and I've got my REM sleep toward morning. However, there are times when I don't go back to sleep, maybe. I have a flight to catch that's happened sometimes. I've got a lot of my mind and I don't go back to sleep.
I can tell you and you've probably experienced that the lack of REM sleep tends to make people emotionally irritable, it tends to make us feel as if the little things are the big things so it's very clear from laboratory studies where people have been deprived selectively of REM sleep that our emotionality tends to get a little bit unhinged and we tend to catastrophize small things we tend to feel like the world is really daunting we're never going to move forward in the ways that we want we can't unlearn the emotional components of whatever it is that's been happening even.
If it's not traumatic the other thing that happens in REM sleep is a replay of certain types of spatial information about where we were and why we were in those places and this maps to some beautiful data and studies that were initiated by a guy named Matt Wilson at MIT years ago showing that erodence and it turns out in other non-human primates and in humans there's a replay of spatial information during REM sleep that almost precisely maps to the activity that we experience during the day as we move from one place to another so here's a common world scenario you go to a new place.
You navigate through that city or that environment this place doesn't have to be a you know, at the scale of a city it can be a new building could be of finding particular rooms new social interaction you experience that and if it's important enough that becomes solidified a few days later and you won't forget it if it's unimportant you'll probably forget it.
Hippocampal Replay in REM Sleep and Forming Relationships During Memory Reconsolidation
During REM sleep there's an it is a literal replay of the exact firing of the neurons that occurred while you were navigating that same city you're building earlier so REM sleep seems to be involved in the the generation of this detailed spatial information, but what is it that's actually happening in REM sleep, so there's this uncoupling of emotion, but most of all what's happening in REM sleep is that we're forming a relationship with particular rules or algorithms, we're starting to figure out based on all the experience that we had during the day whether or not it's important that we avoid certain people or that we approach certain people whether or not it's in important that you know, when we enter a building that we go into the elevator and turn left where the bathroom is for instance these general themes of things and locations and how they fit together and that has a word it's called meaning during our day we're experiencing all sorts of things, meaning is how we each individually piece together the relevance of one thing to the next right.
So if I suddenly told you that this pen was downloading all the information to my brain that was important to deliver this information you'd probably think I was a pretty strange character because typically we don't think of pens as downloading information into brains, but if I told you that I was getting information from my computer that was allowing me to say things to you you'd say well that's perfectly reasonable and that's because we have a clear and agreed upon association with computers and information and memory and we don't have that same association with pens you might say well duh but something in our brain needs to solidify those relationships and make sure that the certain relationships don't exist And it appears that REM sleep is important for that because when you deprive yourself or people of REM, they start seeing odd associations. They tend to lump or batch things. I know this from my own experience of I've ever been sleep deprived which unfortunately happens too often because I'm terrible with deadlines.
It's pulling all nighter the word thus starts to look like it's spelled incorrectly. And those are very simple words to spell but things start to look a little distorted. And we know that if people are Deprived of REM sleep for very long periods of time they start hallucinating. They literally start seeing relationships and movement of objects that aren't happening. And so REM sleep is really where we establish the emotional load, but where we also start discarding all the meanings that are irrelevant. And if you think about emotionality a lot of over-emotionality or catastrophizing is about seeing problems everywhere and you could imagine why that might occur if you start linking the web of your experience too extensively.
It's very important in orde to have healthy emotional and cognitive functioning that we have fairly narrow channels between individual things. If we see something on the news that's very troubling well, then it makes sense to be very troubled but if we're troubled by everything and we start just saying, you know, everything is bothering me and I'm feeling highly irritable and everything is just distorting and troubling me chances, are we are not.
Actively removing the meaning of the connectivity between life experiences as well as we could and that almost always maps back to a deficit in REM sleep. So REM sleep is powerful and has this amazing capacity to eliminate the meanings that don't matter. It's not that it exacerbates the meanings that do matter but it eliminates the meanings that don't matter and that there's a striking resemblance to what happens early in development.
This isn't a discussion about early in development but early in development the reason a baby can't generate. Movements and the reason why children can get very emotional about what seems like trivial events or what adults know to be trivial events like oh the ice cream shop is closed and they just kind of and then the kid just dissolves into you know, puddle of tears and the parents getting okay, well it'll be open again in another time the children one of the reasons that they can't generate coordinated movement or place that event of the ice cream shop being closed into a larger context is because they have too much connectivity and much of the maturation of the brain and nervous system that brings us to the point of being emotional.
Reasonable rational human beings is about elimination of connections between things. So REM sleeps seems to be where we uncouple the potential for emotionality between various experiences. And that brings us to the absolutely fundamental relationship and similarity of REM sleep to some of the clinical practices that have been designed to eliminate emotionality and help people move through trauma and other troubling experiences whether or not those troubling experiences are a death in the family or Loved one something terrible to happen to you or somebody else or you know, an entire childhood or some event that in your mind and body is felt as an experienced as bad terrible or concerning.
Many of you perhaps have heard of trauma treatments such as EMDR. I movement desensitization reprocessing or ketamine treatment for trauma something that recently became legal and is in fairly widespread clinical use. Interestingly enough EMDR and ketamine have kind of a core level that bear very similar features to REM sleep.
So let's talk about EMDR first. I've moved into sensation reprocessing, something that was developed by a psychologist. Francine Shapiro. She actually was in Palo Alto and the story goes that she was walking. Not so incidentally in the trees and forests behind Stanford and she was recalling a troubling event in her own mind.
So this would be from her own life. And she realized that as she was walking the emotional load of that experience was not as intense or severe. She extrapolated from that experience of walking and not feeling as stressed about the stressful event to a practice that she put into work with her clients with her patients and that now has become fairly widespread.
It's actually one of the few behaviorally the behavior treatments that are approved by the American Psychological Association for the treatment of trauma. What she had her clients impatience do was move their eyes from side to side while recounting some traumatic or troubling event Now this was of course in the clinic and I'm guessing that she removed the walking component and just took the eye movement component to the clinic because while it would be nice to go on therapy sessions with your therapist and take walks it has there certain boundaries to that such as confidentiality, you know, if there are a lot of people around the person might not feel as open to discussing things or whether barriers and things like that, you know, if it's raining or handling outside it gets tough.
To do. Why eyeI movements Well, she never really said eye movements but soon I'll tell you why the decision to select these lateralized eye movements for the work in the clinic was the right one. So these eye movements, they look silly I'll do them because that's why I'm here.
They look silly but they basically involve sitting in a chair and moving one's eyes from side to side not while talking but you know for me it's you know, and then recounting the event so it's sometimes talking while moving the eyes, but you should. Do is moving the eyes from side to side for 30 60 seconds then describing this challenging procedure.
Now as a vision scientist who also works on stress. When I first heard this I thought it was crazy frankly people would ask me about EMDR and I just thought that's crazy. I went and looked up some of the theories about why EMDR might work and there were a bunch of theories, oh it mimics the eye movements during REM sleep that was one turns out that's not true and I'll explain why the other one was oh it's synchronizes the the activity on the two sides of the brain well sort of I mean when you look into both sides of the binocular visual field, you activate the visual cortex, but this whole idea of synchrony between the two sides of the brain is something.
That I think modern neuroscience is starting to let's just say gently or not so gently move away from this whole right brain left brain business, it turns out however that I move into the sort that I just did and that Francine Shapiro took from this walk experience and brought to the her clients in in the clinic.
Are the sorts of eye movements that you generate whenever you're moving through space when you are self-generating that movement so not so much when you're driving a car but certainly if you were riding a bicycle or you were walking or you were running you don't realize that but you have these reflexive subconscious eye movements that go from side to side and they are associated with the motor system, so when you move forward your eyes go like this.
There have been a number of studies showing that these lateralized eye movements helped people move through or dissociate the emotional experience of particular traumas. With those experiences such that they could recall those experiences after the treatment and not feel stressed about them or they didn't report them as traumatic any longer now the success rate wasn't a hundred percent but they were statistically significant in a number of studies and yet there's still some critics of EMDR and frankly for a long time.
I still thought well, I don't know this just seems like kind of a hack it just seems like kind of a something that for which we don't know the mechanism and we can't explain. But in the last five years there have been no fewer than five and there's a sixth on the way high quality peer-reviewed manuscripts published in journal of neuroscience neuron cell press journal excellent journal nature, excellent journal, these are very stringent journals and and papers showing that lateralized eye movements of the sort that I just did and if you're just listening to this it's just sweep that moving the eyes from side to side with eyes open that those eye movements, but not vertical eye movements suppress the activity of The amygdala which is this brain region that is involved in threat detection stress anxiety and fear there's some forms of fear that are not amygdala dependent but the amygdala it's not a fear center, but it is critical for the fear response and for the experience of anxiety so that's interesting we've got a clinical tool now that indeed shows a lot of success in a good number of people where I movements from side to side are suppressing the amygdala and the general theme is to use those eye movements to support.
The. For your response and then to recount or repeat the experience and over time uncouple the heavy emotional load the sadness the depression the anxiety the fear from whatever it was that happened that was traumatic this is important to understand because you know, I'd love to be able to tell somebody who had a traumatic experience that they would forget that experience but the truth is you never forget the traumatic experience what you do is you remove the emotional load, eventually it really does lose its potency.
The emotional potency is alleviated now EMDR I should just mention tends to be most successful for single event, we're very specific kinds of trauma that happened over and over as opposed to say an entire childhood or an entire divorce they tend to be it tends to be most effective for single event kinds of things car crashes, etc where people can really recall the events in quite a lot of detail so it's not for everybody and it should be done if it's going to be done for trauma it should be done in a clinical setting with somebody who's certified to do this.
But that bears a lot of resemblance to REM sleep right this experience in our sleep where our eyes are movement moving excuse me, although in a different way, but we don't have the chemical epinephrine in order to generate the fear response and yet we're remembering the event from the previous day or days sometimes in REM sleep, we think about things happen a long time ago, so that's interesting and then now there's this new treatment this chemical treatment with the drug ketamine which also bears a lot of resemblance to the sorts of things that happen in REM sleep.
Ketamine is getting a lot of attention now and I think a lot of people just don't realize what ketamine is ketamine is a dissociative anesthetic it is remarkably similar to the drug called PCP which is certainly a hazardous drug for people to use ketamine and PCP both function to disrupt the activity of a particular receptor in the brain called the nmda receptor and methyl aspartate receptor this is a receptor that's in.
The surface of neurons or on the surface of neurons for which most of the time it's not active, but when something very extreme happens and there's a lot of activity in the neural pathway that impinges on that receptor it opens and it allows the entry of molecules ions that trigger a cellular process that we call long-term potentiation and long-term potentiation translates to a change in connectivity so that later you don't need that intensive end for the same for the neuronic.
I'm active again, let me clarify a little bit of this: the NMDA receptor is gated by intense experience one way you can think about this is typically I walk in my home. I might make some food and sit down at my kitchen table and I don't think anything about explosions but where I to come home one night sit down to a bowl of chicken soup and there was a massive explosion the neurons are associated with chicken soup and my kitchen table would be active in a way that was different than they were previously.
Will be coupled to this experience of explosions such that the next time and perhaps every other time that I go to sit down at the kitchen table, no matter how rational I am about the origins of that explosion, maybe it was a gas truck that was down the road and there's no reason to think it's there today but I would have the same experience those neurons would become active and idea an increase in heart rate again the increase in sweating etc ketamine blocks this NMDA receptor and prevents that crossover and the addition of meaning to the kitchen table kitchen soup, excuse me chicken soup.
So how is ketamine being used ketamine is being used to prevent learning of emotions, very soon after trauma so ketamine is being stocked in a number of different emergency rooms where if people are brought in quickly and you know, these are hard to describe even but you know horrible experience of you know, somebody seeing a loved one next to them killed in a car accident and they were driving that car this isn't for everybody certainly and you need to talk to your physician but ketamine is being used so they might infuse somebody with ketamine so that their emotion is.
It can still occur but that the plasticity the change in the wiring of their brain won't allow that intense emotion to be attached to the experience now immediately you can imagine the sort of ethical implications of this right because certain emotions need to be coupled to experiences.
I'm not saying that people should be using ketamine or shouldn't be using ketamine, certainly not recreationally it's quite dangerous . It can be lethal and like PCP it can cause pretty dramatic changes in perception and behavior but in the clinical setting the basis of ketamine assisted therapies are.
Really to remove emotion and I think the way I've been hearing about it talked in about in the general public is a lot of people think it's a little bit more like the kind of psilocybin trials or the MDMA trials where it's about becoming more emotional or getting in touch with a certain experience ketamine is about becoming dissociative or removed from the emotional component of experience so now we have ketamine which chemically blocks plasticity and prevents the the connection between an emotion and an experience that's a pharmacologic intervention we have EMDR, which is this eye movement thing.
That is designed to suppress the amygdala and it's designed to remove emotionality while somebody recounts and experience and we have REM sleep where the chemical epinephrine that allows for signaling of intense emotion to end the experience of a tense emotion in the brain and body is not allowed and so we're starting to see a organizational logic which is that a certain component of our sleeping life is acting like therapy and that's really what REM sleep is about so we should really think about REM sleep and slow-wave sleep as Both critical slow-way sleep for motor learning and detailed learning REM sleep for attaching of emotions to particular experiences and then for making sure that the emotions are not attached to the wrong experiences and for unlearning emotional responses if they're too intense or severe and this all speaks to the great importance of mastering one's sleep something that we talked about in episode two of the podcast and making sure that if life has disruptive events.
Either due to travel or stress or changes in school or food schedules something that we talked about in episodes three and four that one can still grab a hold and manage one sleep life because fundamentally the unlearning of emotions that are troubling to us is what allows us to move forward in life and indeed the rem deprivation studies show that people become hyper emotional they start to catastrophize and it's no surprise therefore that sleep disturbances correlate with so many.
Emotional and psychological disturbances it's just it by now it should just be obvious why that will be the case, in fact the other day. I was in a discussion with a colleague of mine who's down in Australia, Dr. Sarah McKay, I've known her for two decades now from the time she was at Oxford and Sarah studies among other things menopause in the brain and she was saying that a lot of the emotional effects of menopause actually are not directly related to the hormones there have been some really nice studies showing that the disruptions in temperature regulation in menopause.
Map to changes in sleep regulation that then impact emotionality and an inability to correctly adjust the circuits related to emotionality and I encourage you to look at her work we'll probably have her as a guest on the podcast at some point in the future because she's so knowledgeable about those sorts of issues as well as issues related to testosterone and in people with all sorts of different chromosomal backgrounds so sleep deprivation.
Isn't just deprivation of of energy it's not just deprivation of immune function, it is deprivation of self-induced therapy, every time we go to sleep, okay, so these things like EMDR and ketamine therapies are in clinic therapies, but REM sleep is the one that you're giving yourself every night when you go to sleep which raises I think the other important question which is how to get and how to know if you're getting the appropriate amount of REM sleep and slow-wave sleep, so that's what we'll talk about next so how should one go about getting the appropriate amount.
Of slow wave sleep and REM sleep and knowing that you're getting the right amount well short of hooking yourself up to an EEG it's gonna be tough to get exact measurements of brain states from night to night some people nowadays are using things like the aura ring or a whoop band or some other device to measure the quality and depth and duration of their sleep and for many people of those those devices can be quite useful some people are only gauging their sleep by way of whether or not they feel rested whether or not they feel like they're learning and they're getting better or Not.
There are some things that one can really do and the first one is might surprise you in light of everything. I've said and probably everything you've heard about sleep. There was a study done by a Harvard undergraduate. I mean, Emily Hoagland who was in Robert Strick Gold's lab at the time.
And that study explored how variations in total sleep time related to learning. As compared to total sleep time itself and to summarize the study what they found was that it was more important to have a regular amount of sleep each night as opposed to the total duration in other words and what they showed was that improvements and learning.
Or deficits and learning were more related to whether or not you got six hours six hours five hours six hours. That was better than if somebody got for instance six hours ten hours seven hours four or five hours, you might say well that's crazy because I thought we're just also to get more sleep and there's more room towards morning turns out that forsake of learning new information and performance on exams in particular, that's what was measured.
Limiting the variation in the amount of your sleep is at least as important and perhaps more important than just getting more sleep overall and I think this will bring people great relief many people great relief who are struggling to quote unquote get enough sleep remember a few episodes ago.
I talked about the difference between. Fatigue and insomnia you know fatigue is tends to be when we are tired insomnia tends to lead to a sleepiness during the day when we're falling asleep and you don't want that you don't want either of those things really but I found it striking that the data from the study really point to the fact that consistently getting about the same amount of sleep is better than just getting more sleep and I think nowadays so many people are just aiming for more sleep and they're rather troubled about the fact that they're only getting five hours or they're only getting six hours and Some cases.
It may be the case that they are sleep deprived and they need more sleep but some people just have a lower sleep need and I find great relief personally in the fact that consistently getting for me about six hours or six and a half hours is going to be more beneficial than constantly striving for eight or nine and finding that some nights I'm getting five and sometimes I'm getting nine and varying around the mean as I recall and I think I'm gonna get this precisely right but if not I know that I'm at least close for every hour variation in sleep regardless of whether I was more sleep than one typically got.
There was a 17
One of the reasons why we wake up in the middle of the night to use the bathroom is because when our bladder is full there is a neural connection literally a set of neurons and a nerve circuit that goes to the brainstem that wakes us up and actually some people that I know and I won't be mentioned actually use this to try and adjust their for their jet lag when they're trying to stay awake.
Having to use the bathroom having a urinate is one of the most anxiety of oaking experiences anyone. Can have If you really have to go to the bathroom it's very hard to fall asleep or stay asleep. And bed wetting which happens in kids very early on is a failure of those circuits to maturate to mature until at you know, I think we all assume that babies are gonna you're gonna pee in their sleep, but adults aren't supposed to do that and the the circuits take some time to develop and in some kids, they develop a little bit later than others.
So having a full bladder is one way to disrupt your sleep. You don't want to go to bed dehydrated, but that's one way on the other hand there is a Evidence that if you want to remember your dreams more or remember more of your dreams there is a tool that you can use I don't necessarily recommend it which is to drink a bunch of water before you go to sleep and then what happens is you tend to break in and out of REM sleep.
It tends to be fractured and with a sleep journal then done these laboratory studies, believe it or not people will recall more of their dreams because they're in this kind of semi-conscious state because they're constantly waking up throughout the night. I suggest not having a full bladder before you go to sleep.
That one's kind of an obvious one but nonetheless. The other one is if you recall that, During REM sleep, we have a shift in neurotransmitters such that we have less. Serotonin right? Just want to make sure I got that right, excuse me, less serotonin. There are a lot of supplements out there geared toward improving sleep I've taken some of them and up to many of them if not all of them at this point.
So I could report back to you and I think I mentioned in a previous episode that when I take tryptophan or anything that contains 5HTP, which is serotonin or a precursor to serotonin serotonin is made from tryptophan. I tend to fall very deeply asleep and then wake up a few hours later and that makes sense now based on the fact that you just don't want a lot of REM sleep early on what was probably happening as I was getting a lot of REM sleep early on because low levels of serotonin and Are typically associated with slow wave sleep in that comes early in the night.
So for some people those supplements might work, but beware serotonin supplements could disrupt the timing of REM sleep and slow wave sleep and in my case led to waking up very shortly after going to sleep and not being able to get back to sleep. Now if you want to increase your slow wave sleep, that's interesting.
There are ways to do that. One of the most powerful ways to increase slow wave sleep. A percentage of slow-wave sleep. Apparently without any disruption to the other components of sleep and learning is to engage in resistance exercise. It's pretty clear that resistance exercise triggers a number of metabolic and endocrine pathways that lend themselves to release of growth hormone, which happens early in the night.
And resistance exercise therefore can induce a greater percentage of slow wave sleep. It doesn't have to be done very close to going to bed time. In fact, for some people that exercise could be disruptive for reasons. I've talked about it in previous episodes, but resistance exercise unlike aerobic exercise.
Does seem to increase the amount of slow wave sleep, which as we know is involved in motor learning and the acquisition of fine detailed information, not general rules or the emotional components of experiences. For those of you that are interested in lucid dreaming and would like to increase the amount of lucid dreaming that you're experiencing.
I haven't been able to track down that device with the red light that I described at the beginning, but there are a number of just simple zero technology tools that one could use in principle. One is to set a queue. The way this works is you come up with a simple statement about something that you'd like to see or experience later in dreams.
You can for instance write down, you know, Something like I want to remember the red apple I don't sound silly and trivial and you look at that you would probably want to write it down on a piece of paper, you might even want to draw a red apple and then before you go to sleep you would look at it and then you would just go to sleep.
There are some reports that doing that for several days in a row can lead to a situation in which you are suddenly in your dream and you remember the red apple and that gives you a sort of tether to reality between the dream state and reality that allows you to navigate and shape and kind of adjust your dreams.
Lucid dreaming does not have to be or include the ability to alter features of the dream all you know to be able to control things in the dream, sometimes it's just the awareness that you are dreaming but nonetheless as some people enjoy lucid dreaming and then for people that have a lot of lucid dreams that feel kind of overwhelmed by those that going to involve trying to embrace protocols that can set the right duration of sleep and there's a little bit of literature not a lot that that shows that keeping the total amount of sleep per night.
To the big to say six hours such that you begin sleeping end at the beginning and end of one of these ultradian cycles um can be better than waking up in the middle of one of these old tradian cycles. So try and find the right amount of sleep that you need that's right for you and then try and get that consistently night tonight if you're a lucid dreamer and you don't like it then you may want to start to make sure that you're waking up at the end of one of these all tradian cycles so and that's in this case it would be better to wake up after six hours than after seven and if you did sleep longer than six hours, maybe you'd want to get to.
Seven and a half. Hours because that's going to reflect the end of one of these 90 minute cycles as opposed to waking up in the middle. Alcohol and marijuana are well known to induce states that are pseudo-sleep like especially when people fall asleep while after having consumed alcohol or THC the active component is one of the active components of marijuana.
Alcohol THC and most. Things like them meaning things that increase serotonin and or GABA are going to disrupt the pattern of sleep. They're going to disrupt the depth they're going to disrupt the overall sequencing of more slow wave sleep early in the night of the. Reality. There are some things that at least in a few studies that I defined seem to suggest it would increase the amount of slow wave sleep.
Things like arginine although you really want to check arginine can have effects on the heart etcetera has other effects but alcohol THC not going to be great for sleep and depth of sleep. You might feel like you can fall asleep faster but the sleep that you're accessing really isn't the kind of deep restorative sleep that you should be getting.
Now, of course if that's what you need in order to sleep and that's within your protocols. I've said here before. I'm not suggesting people taking anything. I'm not a medical doctor. I'm not a cop so I'm not trying to regulate anyone's behavior. I'm just telling you what the literature says.
Some of you, who may want to explore your dreams and meaning of dreams etc, you know there's not a lot of hard data about how to do this but a lot of people report keeping a sleep journal where a dream journal can be very useful so they mark when they think they fell asleep the night before when they woke up and if they wake up in the middle of the night or early in the morning, they'll just write down what they can recall of their dreams and even if they recall nothing many people have the experience of mid-morning or later afternoon that suddenly comes to them that they had a dream about something in writing that down.
I kept a dream journal for a while. I didn't. Really afford me much I I didn't really learn anything except in my dreams were very bizarre, but there are some things that happen in dreams that are associated with REM sleep as a compared to slow wave sleep which can tell you whether or not your dream likely happened in REM sleep or slow-wave sleep and the distinguishing feature turns out as something called theory of mind.
Theory of mind is actually an idea that was developed for the study and assessment of autism and it was initially that phrase theory of mind was brought about by Simon Baron Cohen. Who is Sasha Baron Cohen the comedians brother Simon Baron Cohen is a psychologist and to some extent to neuroscientist and at Oxford and theory of mind tests are done on children and the theory of mine Tesco is some but like the following a child is brought into a laboratory and watches a video of a child playing with some sort of toy and then at the end of playing with that toy they put the toy in a drawer and they go away and then another child comes in and is looking around and, Then.
Experimenter asks the child who's in the experiment the real child and says, you know what does the child think you know, what are they feeling and most children of a particular age five or six or older will say, oh, you know, he or she is confused, they don't know where the toy is or they'll say something that implies what we call theory of mind that they can put their ideas into and their mind into what the other child is likely to be feeling or experiencing that's theory of mind and it turns out that this is used.
As one of the assessments for autism because some children not all but some children that have autism or that go on to develop autism don't have this theory of mind they tend to fixate on the fact that the first child put the toy in the drawer they'll say it's in the drawer as opposed to answering the question which is how does the second child feel about it or what are they experiencing so theory of mind is something that is emerges early in life as a part of the maturation of the circuits and the brain associated with emotional learning and and social interactions and We experience this in certain dreams so if you had a dream that you're puzzled about or that you're fixated on and you're thinking about you might ask in that dream was I assessing somebody else's emotion and feeling or was I very much in my own first person experience and that the tendency is that theory of mind tends to show up most in these remem associated dreams now this isn't a heart and fast rule but chances are if you were in a dream and you were thinking about other people who wanted to do something to you you were thinking about there's Desire to chase you or help you or something that was really really to someone else's emotional experience it was probably a rem dream that dream occurred in rapid eye movement sleep as opposed to slow wave sleep and that makes sense when you think about the role of REM in emotional unlearning of associations with particular life events that REM is rich with all sorts of exploration of the emotional load of being chased or the emotional load of having to take an exam the next day or being late for something.
But again if you're fixated or you can recall thinking a lot about or feeling a lot about what somebody else's motivations were then chances are it was in RAM and if not chances are it was in slow wave sleep today, we've been in a deep dive of sleep and dreaming learning and unlearning and I just want to recap a few of the highlights and important points.
A lot more slowly sleep and less REM early in the night more REM and less slow way sleep later in the night REM sleep is associated with a intense experiences without this chemical epinephrine that allows us the anxiety or fear and almost certainly has an important role in uncoupling of emotion from experiences self-induced therapy that we go into each night.
That bears striking resemblance to things like EMDR and ketamine therapies and so forth slow-wave sleep is critical however it's critical mostly for motor learning and the learning of specific details so REM is kind of emotional and general themes and meaning and slow-wave sleep motor learning and details. I personally find it fascinating that consistency of sleep meaning getting six hours every night is better than getting ten one night, eight the next and then five the next.
I find that fascinating and I think I also like it because it's something I can control better than just trying to sleep more which I think I'm not alone in agreeing that that's just hard for a lot of people to do. This episode also brings us to the conclusion of a five-episode streak where we've been focusing on sleep and transitions in and out of sleep non-sleep deep breaths, we've talked about a lot of tools morning light evening light avoiding lights blue blockers supplements tools for measuring sleep duration and quality we've been covering a lot of themes.
I like to think that by now you're armed with a number of tools and information things like knowing when your temperature minimum is knowing when you might want to view light or not when you might want to eat or take hot showers or Got for a bit of cold shower something that most people including me more or less load but can have certain benefits and that will allow you to shape your sleep life and get this consistent or more or less consistent amount of sleep on a regular basis, nobody's perfect that day.
61 Rasch and Born [209] review the field of sleep and memory research, providing a historical perspective on the basic concepts and a discussion of more recent key findings pertaining to the consolidation of memories, and Klinzing et al [156] compare the differences between the consolidation of newly encoded memories and the reconsolidation and reorganization of remote memories after their reactivation:
Specifically, newer findings characterize sleep as a brain state optimizing memory consolidation, in opposition to the waking brain being optimized for encoding of memories. Consolidation originates from reactivation of recently encoded neuronal memory representations, which occur during SWS and transform respective representations for integration into long-term memory. Ensuing REM sleep may stabilize transformed memories. While elaborated with respect to hippocampus-dependent memories, the concept of an active redistribution of memory representations from networks serving as temporary store into long-term stores might hold also for non-hippocampus-dependent memory, and even for nonneuronal, i.e., immunological memories, giving rise to the idea that the offline consolidation of memory during sleep represents a principle of long-term memory formation established in quite different physiological systems. (SOURCE)
Lewis et al [165] discuss the different ways in which rapid eye movement sleep, or REM, and non-REM sleep facilitate creative thought by way of reorganising existing knowledge:
It is commonly accepted that sleep promotes creative problem-solving, but there is debate about the role of rapid eye movement (REM) versus non-REM sleep. Behavioural evidence increasingly suggests that memory replay in non-REM sleep is critical for abstracting gist information (e.g., the overarching rules that define a set of related memories). The high excitation, plasticity, and connectivity of REM sleep provide an ideal setting for the formation of novel, unexpected, connections within existing cortically coded knowledge. The synergistic interleaving of REM and non-REM sleep may promote complex analogical problem solving.Creative thought relies on the reorganisation of existing knowledge. Sleep is known to be important for creative thinking, but there is a debate about which sleep stage is most relevant, and why. We address this issue by proposing that rapid eye movement sleep, or REM, and non-REM sleep facilitate creativity in different ways. Memory replay mechanisms in non-REM can abstract rules from corpuses of learned information, while replay in REM may promote novel associations. We propose that the iterative interleaving of REM and non-REM across a night boosts the formation of complex knowledge frameworks, and allows these frameworks to be restructured, thus facilitating creative thought. We outline a hypothetical computational model which will allow explicit testing of these hypotheses. (https://www.cell.com/trends/cognitive-sciences/pdf/S1364-6613(18)30070-6.pdf)
62 What follows is a machine transcript of Brain Inspired Episode 95 with Chris Summerfield & Sam Gershman in which the two are ostensibly debating whether AI benefits more from neuroscience or neuroscience benefits more from AI. We learn that Gershman and Summerfield are primarily in agreement and have nuanced views of each of the two claims. The discussion should be of interest to computer scientists, neuroscientists and psychologists interested in machine learning and contemporary AI. At one point, the host, Paul Middlefield interjected a question from Andrew Saxe who co-authored a paper with Summerfield and some of you may know – Saxe received his PhD from Stanford and was advised by Jay McClelland (primary), Surya Ganguli and Andrew Ng.
Here are three highlights of the podcast that I picked out as they are relevant to topics covered in the class discussion list. The "excerpts" are my paraphrases to compensate transcription errors. I suggest you listen to the podcast and use the transcript to search for content that you want to recall later.
ABSTRACT REASONING: I don't know if anyone has claimed that the reason we're good at Go is because we're such generalists. In fact I almost feel like it's the opposite, given that the only reason we appear to generalize well is because our ability to reason abstractly is heavily grounded in the training and the sharing of information that we humans have as a consequence of the world we were born into.
ANALOGICAL REASONING: In order to recognize analogies you need a lot of content knowledge in the different domains in order to be able to map between them. That's the logic of cognitive theories about analogical reasoning like structure mapping where you need to start off with the right sort of primitives and relations in the two domains and only then can you map between them.
COGNITIVE DIFFERENCE: One of the mistakes that researchers in contemporary AI tend to make is to fail to treat the kinds of computation that underlie sensory motor behaviors and the kinds that underlie cognitive behaviors differentially. I think they're solved in fundamentally different ways in the human brain.
FLEXIBLE SUBROUTINES: The result of all these low-level subroutines working together is what results in mind and what we think of as analytical reasoning. In order to understand how our higher-order cognitive faculties and modular capabilities like attentional and external memory systems work, we need to understand how all of these low-level subroutines are being combined and reused to support these different cognitive functions.
Artificial intelligence continues to contribute to neuroscience, but does neuroscience have anything really to offer AI moving forward. That's the main topic this episode. Hi everyone. I'm Paul. Today I bring you Chris Summerfield and Sam Gershman who've known each other a long time and they have slightly different but overlapping answers and viewpoints regarding that question.
Chris runs his human information processing lab at the University of Oxford where they focus on the computational underpinnings of how we learn and make decisions. About what we're perceiving and what actions to take and he also works at DeepMind and this is the second time Sam has been on he was on episode 28 back in the day.
He runs his computational cognitive neuroscience lab at Harvard where they focus on the computational underpinnings of how we learn and represent our environments. So we have a wide-ranging discussion today that begins with and circles around the relationship between neuroscience and AI and how neuroscience has or hasn't and will or won't influence.
The AI world and along the way we dip into topics like the merits of prediction versus understanding the centrality of humans and specifying the problems that we want AI to solve and what that means for the kind of AI that we are building how artificial general intelligence and or human level AI fits into that story and plenty more.
So you guys knew each other at Columbia in the mid or early 2000s correct that's right, that's correct what was how did you guys know each other and what I really want to know is you know, what was going on at that point in your minds and in your perspectives and outlooks and how those have changed oh since then well, I mean, I I remember sitting wedged between two graduate students desks one was Chris and one was Emily stern and they had put a little plank of wood connecting the two desks where I could place my computer there and then I would just I would be trying to work but really I was mostly listening to them banter with each other you're an undergraduate, right?
I was an undergraduate that's right, so I was just completely swept away by the experience of graduate school. I thought it seemed to be the the the most fun thing that you could be doing with your time and actually was kind of catastrophic for my undergraduate career because I completely lost interest in classes and wanted to just come to the lab all the time.
I I remember the time well yes, so the banter with Emily goes on to this day. But I mean, I think it was an interesting time also to be a graduate student as well because it was sort of like it's kind of like the wild we was like the wild west of neuromaging at the time oh yes so 2000 and must be 2003 2004 and I think the field was still at a stage where you know, you could sort of take any task off the shelf and put someone in the scanner and like, you know, whatever you found was a result of some interest at least to that community.
And you know you asked about how things have changed. I mean, it's interesting, you know, both I think probably the way what Sam and I both find interesting and I'll work right now is probably just as different as it could possibly be to what the fee where the field was at at time in the sense that you know that time there was very little focus on on mechanism and there was there was very little concern given to how whatever you measured at the neural level might actually tap into you know, what was going on the underlying mechanics.
And I think it's very different now how have your interests changed so so Chris you said that the the interests of the field were different than than your interests now how of your interests you know, what were your what was your big question back then and how is it changed well?
I was I was working. I mean the lab work Sam and I were were both working was it was Jennifer angles labels a memory research lab called McNair science memory lab and after having done my PhD there. I I think that, you know, I was kind of disenchanted with the idea that The endpoint of science was kind of to identify these sort of data features and just the right stories about you know, the existence of these data features as a scientific result and I wanted to I wanted to do something that made much tighter links to you know, how the system worked and at the time I felt like the only way that I could do that was to go and work in what was then kind of the most you know, I I guess like the the domain that has the sort of simplest mapping from stimulus to theory or I guess.
Experiment a theory which was to work in psychophysics or perceptual decision-making as it became known around the time and you know, it's interesting that that move in that being making that move. I kind of shed, you know, all of this sort of stuff about cognition and and memory and so on but I think that the field has the field has has in a way it sort of comes full circle and I think that what's going on now is that there is a lot more traction computationally on those those more topics of of cognitive interest.
That's not to say that we didn't have good cognitive theories around the time but I think those theories are now much more joined up with with neuroscience and so for me personally, you know, it feels like coming back to cognition as a really important domain of study and all the things that we thought were just simple psychophysics turn out to be impinged upon by various cognitive processes like beliefs and memories on and Sam so how was your perspective changed?
I mean, you you had already been. I was just looking back at your neurotree for you Sam and if you know for a few but but man, you were a research assistant and like three different labs as an undergrad it looks like as an undergrad. I mean, you have this you've had a lot of variation in your upbringing in in your the trajectory.
I suppose it seems like you've always been interested in in all of this stuff but did you have this kind of wild-eyed view how was your perspective and interests and outlook changed well? I think like many people as an undergrad. I just didn't really know enough or understand enough to know what was connected to what or what was not connected to what and so everything sort of seemed interesting and connected but I mean it is I was really just kind of confused and bouncing around and following my nose towards whatever was interesting so I had started off doing stuff on on memory, but I got interested at some point and emotion and later in decision-making and reinforcement learning after I left Columbia, I went and worked at NYU.
For a while in Nathaniel toss lab but uh I think my my perspective has changed a lot in the sense that I didn't really have much of a perspective when I was an undergrad. I was just trying to do things that seemed interesting to me and I think it was it took a while for me to come to the appreciate appreciation and this is partly thanks to Chris of the importance of computation in the way that we think about all aspects of the brain that I guess.
I don't know if this is true. Chris that at the time that I met you. I think you were undergoing a similar kind of conversion experience. And and so that is what I get but but the problem is that at Columbia that time there weren't really people doing this kind of this kind of thing I mean there were there were computational nurse scientists at the medical school as they're still are but in the psychology department which is where we were there wasn't a lot of that and so I was just kind of picking things up as I went along that's that's absolutely right so Colombia was a in a way.
I mean, it was a it was a wonderful place to be a graduate student but in a way it was also slightly strange place because I think there's a policy particularly of maintaining, you know, incredible diversity in the recent research interest. S and approaches of the faculty there meaning that you know you you have lots and lots of different topics being addressed, but you don't have a critical mass in any one topic and there's certainly wasn't a critical net mass in cognition or in in cognitive and computational neuroscience, which is I guess, you know, sort of where both are workers ended up Chris, I mean, we won't persevere on this for too much longer but Sam mentioned that there was his experience was one at least partially of a sort of mentor mentee relationship and I remember, you know being a graduate student and You know interacting with undergrads even being a postdoc and interacting with graduate students and I always knew the back of my head that that's what the relationship was mentor mentee, but it didn't feel that way did it did it feel that way were you mentoring Sam did you were you conscious of that are you kidding that was almost the artist the opposite way around I think and it's remained that ever since no.
I mean, I actually think to this day, I I continue to feel how important it is to nurture undergrads because I just benefited so much from just I know you. Even know if nurturing is the way word it's just being able to hang out around graduate students and sponge up what they're doing even though they're only just marginally less confused than I I was but I didn't realize that at the time they marginally less confused but but as slightly more than marginally more miserable, sometimes well that was the other thing that I found jarring was.
I remember going to dinner at one point to a graduate student's house when I was still an undergrad and all the grad students were really griping about their lives and their careers. And. I just couldn't understand because it just seemed so glamorous to be a graduate student from where I was sitting which is like I couldn't go to a class without falling asleep and I just I just wanted to be where the action was but now now I understand a little better the difficulties of being a grad student, alright guys, very good well so the the I guess the main topic that we can just dance around here that sand mentioned that maybe you guys had different perspectives on.
How valuable neuroscience is to AI and you know, the overarching picture I suppose and you can correct me if I'm wrong is that Sam thinks that neuroscience hasn't contributed much to AI and or doesn't have as much to contribute to AI as AI has to contribute to neuroscience and he believes Chris that you you know, believe the opposite as you've written about plenty as and and spoken about and I know it's more subtle than that but, So I'm not sure what the best way into this discussion is whether you each want to you know just make a case using you know, an example from your own recent work or I have some suggested, you know topics that that you know can lead us into this discussion, okay just clarify.
I don't it's not that I think that neuroscience can't contribute anything to AI, I certainly would very much welcome that. I just think that it's been a little bit oversold. I think that the examples that people use as evidence for that kind of claim are a little bit thin that's my perspective.
So I mean there's a number of different clarifications which I think it would be important to make sure before we start the discussion so the first one is about forward-looking versus backward-looking rights give me obviously neuroscience cognitive science and AI research have kind of grown up together and so you know the in the past they're obviously has been considerable mutual cross-fertilization but whether you would want a characterize that is like, you know ideas in AI sort of being imported wholesale from neuroscience or not.
I mean, you could certainly tell that story right, you know, you could say, oh look, you know, we suddenly realized that a good way to Do computation is to have like, you know sheets of neurons that integrate information and transduce it nonlinearly like wow, that's because that's what the brain does but you know, of course it's not as simple as that.
Or you could make you know equivalent stories very enforcement learning or for even for from memory processes, if you think of you know, the way the LSTMs do gating right it looks an awful lot like our contemporary theories of you know, activity silence states and fast synaptic plasticity prefrontal cortex, so you can make those stories but I think that's kind of not the most interesting way to tackle the question and maybe if I could just forward-looking yeah go on so sorry because I didn't even it might be useful to ground this a little bit in the question if if I'm a computer scientist.
Trying to build AI what should I spend my time doing should I spend my time basically trying to build engineering artifacts? And fiddling with them until they do something useful or is it good for me to spend at least part of my time learning about biology and maybe even doing biology in the effort is part of an effort to uncover the mechanisms that a lot of the brain to do intelligent things and and that and and and so I do get plenty of people into my coming into my office.
I'm sure Chris does too that people from computer science and other engineering disciplines who want to learn about the brain precisely for this reason because they think that By learning about the brain they can uncover some secrets that they can put into their algorithms and I think that that's the part that I'm kind of skeptical about I think that certainly the idea that you could find parallels and cross currents between neuroscience and AI that that's that's been hugely useful even if we don't worry about like the whole intellectual history of who influenced who it's just I think it's a it's a matter of like what do you hope to get out of biology as a as an engineer can I just ask a clarification question about what you mean by biology because you know, For instance you you know in your in your paper building machines that learn and think like humans you talk about a lot of cognitive aspects that could be a could be an aid to to building AI things like intrinsic physics and transit psychology causality compositionality, but these are more cognitive science type psychology level type things so when you say biology do you just do you mean the the negative or the right because we're talking about neuroscience you're not about psychology, yeah, okay, yeah see I guess my definition of neuroscience.
Is just really broad because if you narrow and the neuroscience down to but because I I believe that when you're doing when you're using like deep learning models to understand the brain you're doing neuroscience and and you're comparing it to brain activity that is neurosur, but that's not we're talking about right we're talking about using neuroscience to build better AI right so so I I I think we were all in agreement that AI has had a lot of has contributed and will continue to contribute much to our understanding of the brightness the sort of the other direction which I'm most.
Ly skeptical about does it matter do you think that neuroscience is still quite young and from my perspective still has a long way to go in learning actually what the brain is doing but this is this is exactly the issue that I'm concerned about which is that how what is the process by which we understand what the brain is doing the the reason why I move towards computational theories is because the computational theories provide a way of not just interpreting but also just describing the mech.
Anisms that we observe in the brain right so in the the points that we can't actually discover how the brain works unless we go in. With some computational theory to interpret what we're measuring there's not there there's not a kind of naive empiricist pathway by which we can just look at the data and from that extract computational mechanism do you think people believe that there is I do.
I mean, I think that many nurse scientists approach the data gathering enterprise in that way that will measure a bunch of things and then see what comes out or apply kind of sophisticated statistical algorithms to extract structure from their data and then try to interpret it but that's not necessarily the sort of, That's not necessarily the sorts of knowledge that people are going to you know want to buy into in machine learning in order to try to build better models right as it said, I mean, it's true the people do that, well we're sorry which kind of knowledge well.
I mean, you know this what you described is this sort of, you know, there there are these sort of Bayconian neuroscientists out there who are just into sort of, you know, massive data collection exercises and of course, you know, there is an excitement around, you know, big data in your science rightly, I think but when you talk about, you know neuroscience, Influencing AI research I don't think that's what most readily springs to mind.
I think when we think about neuroscience influencing AI research we think about constraints on architectures that come from our knowledge of memory systems, we think about you know, kind of the sorts of processes which underlie attentional selection or or task level control or even language and we think about these neatly these are not ideas from neuroscience while neuroscience right these are ideas which span psychology cognitive science and That's but I think there is that there is a there is an argument that these things are useful for building stronger AI but I think it really depends upon what you want your AI to do, right?
I mean, what do you want to do is is protein folding I shouldn't think you need any of these things yeah. I think when we talk about AI we're talking about doing the kinds of things that the brain does right human flexible human intelligence right that that that's just that's not all of AI, but that's I think that's the kind of AI either is in question.
Ing here and I think just in response to it you just said Chris it seems to me that there's that we have two horns of a dilemma one is one path you can go is collect data in this sort of Baconian big data mode, but until it's interpreted through the right theoretical lens, it may not be particularly useful from an engineering perspective or you can go in with a more theory driven approach but to do that you need to have already a computational theory in your grasp and, The problem is that if you already have the computational theory right then again from the engineering perspective you could just build that computational theory into your algorithms right you don't need if you already have a computational theory, why do you need to go look at the biology yeah.
I mean, I I I don't disagree with that at all. I mean to my mind. Neuroscience has many things to offer AI but they're not primarily theories of how the brain works. I think they're they're primarily tools and approaches which are mature in psychology and neuroscience and which are either overlooked or immature in machine learning and AI research.
So one is just like a good sense of how to define the question right to how to define a research question, so one things psychologists are really good at is they're really good at framing a research question and desiring and designing environments, you know, what we call, you know experiment.
S In machine learning terms it's just an environment defining environment that are there to kind of explore that research question and try to work out how an agent is solving a particular class of problem. And that's an enormously useful tool for doing machine learning research because if you want your engineering at approaches to scale in generalize, you need to understand how they work and what machine learning and AI researchers historically do very badly is to take the trouble to sit down and try and work out how their algorithms are solving the problems that they're solving.
And you know there's there's not to say that nobody does that but there's an excessive focus on whether it works relative to how it works and I think what neuroscientists can provide our tools and approaches that can familiarate that I also just think that sociologically, you know, maybe this is trite point but you know, we took a lot about diversity in our field and you know, I think that there's a type of diversity which sometimes perhaps reasonably but gets less attention which is intellectual diversity and I just think that the diversity of viewpoints which nurse.
Scientists bring into machine learning is sort of you know, it's it's like a kind of intellectual stirring of the pot and you know, I think that that in and of itself carries enormous intrinsic value and I think that it's the exactly the same is true in the reverse direction, right and maybe I don't know if we'll get on to talking about how neuroscience is being has been an is being shaped by you know, what's gone on in AI research in the last set of few eight to ten years, but in both directions that sort of you know, mixing it up, that's come.
From the crossover between the fields I think is really really valuable. Yeah, I think what you're saying Chris resonates with me a lot. I the the thing that just to maybe give my own reiteration of what you're saying the the thing that neuroscience and cognitive science have contributed most I think to AI research is a kind is a different kind of workflow pattern.
Because if you think about if you think about the way in which computer scientists go about improving their their artifacts, they you have to you have to establish some benchmarks and then Show that you can achieve state-of-the-art performance on the those benchmarks and then there's this kind of arms race to get better and better performance.
But at some point people say well we need different benchmarks like this benchmark is not capturing something important and usually the the points in which that happens is when people realize they sort of when when the computer scientists kind of step outside their paradigm and look beyond to the things that people do often that that people can do and their systems can't do or fail in weird ways right so so that you examples of this are like adversarial examples for.
Computer vision systems, for example, and I think that what cognitive scientists and neuroscientists have to offer is that essentially they have a whole collection of the you they have a collection of different ways of teasing apart these different kinds of let me put it a different way so they I think that they have a methodology for looking for constructing the kinds of tests that would reveal mechanism right that's what Chris was saying before and that that is often of less interest to.
Engineers who are trying to achieve state of the art performance because you don't necessarily need to understand why some things work something works as long as it works right it's sort of like keeping things keeping people honest right keeping computer scientists honest about what is the what are the important things to capture yeah, but also I mean if you think about even beyond beyond thinking about yeah this keeping honest or whatever if you think about the, Way in which cognize scientists and your scientists have have also helped define the problem right define the set, you know, if we're talking about like, you know, kind of AI research of the kind of you know, what what people call the search for general intelligence then, you know, even just defining what that means is something which I think within machine learning and AI research there's not enough attention given to and I think in cognitive science is something that people thought much more deeply about, you know, posing the simple question of like if you If you wanted to to develop like success criteria for building the sorts of intelligence like if we're talking about human level machine intelligence, what would those success criteria look like?
I think that you know, that's the sort of question that you're going to find richer and more varied answers in cognitive science, we're not necessarily neuroscience in cognitive science than you would in contemporary machine learning research. I think that was going to be one of my questions to you because so cognitive science has what originally six branches anthropology is even one of them.
That is supposed to be included in what cognitive science is and but philosophy is one of them and I'm wondering if if we get the definitions wrong, if we get the the questions wrong is that going to hinder the ability to create something like AGI, I'm not sure if that's what you're getting at Chris about formulating the the questions correctly and if that's what you mean is the philosophical part of cognitive science or or something else, okay?
I didn't even know if it needs to be a philosophical part right formulating a research question is an intrinsic part of the scientific endeavor, right? You know you thinking about you know what does it mean for an agent to you know kind of display some some strong forms of generalization or to display metacognition or to you know, display curiosity, how do you operationalize those and how do you measure them that doesn't seem to me like a philosophical question that seems to me like a scientific question that's a sort of thing the cognitive scientists do well so yeah, I think operationalization is a scientific thing so but so there's no risk you think of if we you know, something like metacognition right which I Quote unquote studied and thought I knew what it meant until I studied it and realized I didn't know what it meant you know a lot of assumptions I had about what it meant so we operationalized it and then measured things but I still don't know what metacognition is, even though we operationalize it we gave it a definition measured it and said whether the monkeys were being metacognitive for instance, but I still really don't understand what metacognition is and I don't know if that matters it's okay can I get a different example which might be useful reference point for discussion, you you sometimes see computer scientists saying, That a particular task was solved so for example at some point I think people started declaring Atari to be solved well one operationalization of success in those games is can you achieve human or superhuman level performance with enough training and then by that criterion you could say that Atari had been solved but if you look at it from the perspective of achieving human level sample complexity, like can you get to the asymptotic performance as quickly as humans can or can you generalize that to other variants of the games as quickly as humans can an event then arguably?
Hasn't been solved yet so depending on your operationalization, you're gonna have different criteria for success and to me. I think the important thing is that there's nothing within the framework of machine learning that tells you how to operationalize these the constructs of intelligence, right and I think that's why there's been so much back and forth about this because there's no common ground for everyone to agree on what what constitutes artificial general intelligence, for example, and I think for cognitive science.
Maybe it's a different kind of in some ways it's a little bit easier because what we want to do is not necessarily define an all-encompassing notion of intelligence but try to isolate some aspects of human intelligence that we think are important without claiming that those are that those constitutes the entirety of intelligence and then try to build machines that match those abilities and that the hope is that by studying those empirically we can learn something about how they work in the brain and that can be ported into AI.
Let's do it. I was waiting to see if you had comment on that Chris. I mean, go ahead if you do. I don't know if I really do have a comment. I mean, I completely agree. With. Some question. We can operationalize in terms of some sort of external benchmark like guitaring right so nobody in the contemporary AI community invented Atari just so they didn't invent go so it provides an external benchmark.
But of course, you know, there's a there's a kind of, you know, there's a kind of good hearts law problem with these extension as we external benchmarks, right which is that, you know, people optimize for the benchmark and they don't optimize for the general functions which underlie good performance on the benchmark, right?
And you know, the trouble is that then you're into if you say okay, well let's dispense with the external benchmarks then you're into the much more slippery world where you're both. Making up the tests that you used to evaluate your agents and your training the agents that are going to try and pass those tests right.
And that's obviously a much more, you know, it's a it's a much more difficult situation to to come up with good validations of your performance because obviously you don't know whether those two process the process of building the test and the process of training the agent are actually sort of mutually interacting in some way which means that you're just satisfying your own demand characteristics.
I think this is a real challenge for for AI research. I think it's also a challenge for neuroscience. Reasons for virtue, honestly the I think that we see a similar phenomenon where for example now one approach to understanding what the ventral visual stream does is to train train systems for image classification, so that typically is some kind of deep convolutional neural network and then try to quantitatively match the activity in the layers of the artificial network to the activity in the layers of in the different regions of the ventral visual stream.
And and then the the game becomes how do we get those numbers the numbers quantifying the match to be as high as possible? And my worry about that is that in operationalizing success in that way, you're ignoring a lot about other aspects of vision that might not be captured by these kinds of systems.
So like when I talk to students about this, I often give them examples of all sorts of phenomena from visual cognition, which it's not obvious or not only is it not obvious that this is. Going to but nobody is actually trying to ascertain whether those systems do it or a few people are because the the way in which the Christ success criteria are set up are not designed to assess that.
That's not part of the assessment. So, I agree with that like a hundred percent. So, I've written about this as well and, I mean, I I think that there is that there is a real worry that you know, what I see is being the central project of computational neuroscience, which is essentially to to try to understand computation is sort of being you know, sort of slightly gleefully dispensed to it in the irrational exuberance around machine learning methods and there's a sort of sense of well actually we don't have to grapple with the hard problems because we can just train your own networks and you know, We can just you know find some linear mapping that you know kind of that links whatever our neural markers are with our neural network and that's kind of that is the story and it and you know, you've you've had guests on your podcast.
I think you advocate for this and and it seems to me that there's a there's a sort of a corollary of that viewpoint which is that, you know, actually there isn't anything really very interesting to be studied in the first place. And I I disagree with that and I I suspect sandals too yeah but I guess I I think we shouldn't similarly dismiss the kind of radical challenge to scientific understanding that's posed by these kinds of approaches, which I think I think I think we should we should address and I'll come back to why I think it doesn't quite work but I was very struck actually once talking to a geologist who.
Told me that he felt that the general multiple generations of geophysicists were ruined by their classical education because the textbooks have various kinds of mathematical models and principles, but if you actually try to use those to for example predict earthquakes, they just completely fail and he was impressed and and I think it was a kind of earth-shattering moment for him when he realized that he could train neural networks to predict earthquakes far better than all the classical theory could and to him.
The way that he interpreted that was that we shouldn't be wasting time with the classical theory, we we should re-fashion signs as a kind of predictive enterprise because what good are all these scientific theories, if they can't predict some of the critical things that we want to use them to predict and so it's a kind of it illuminative approach to the scientific enterprise where we're going to get rid of our conventional notions of understanding and replace them with generic prediction, and I think there's there's a school thought within neuroscience that is.
That is a viable approach to me the problem with this is not so much that so much about the about prediction per se I think it I think we should strive to build models that make good predictions quantitatively. I prefer predictions the problem is how do you know if you're successful right because, You have to say this is the signal that I want to predict.
And then you and then you can only declare victory once you once you've stipulated that these are the these are the phenomena that I'm trying to predict and I had this conversation with Jim de Carlo at some point recently where? I was asking him do so he you you've set up the task that you want to predict as much variance as you can of let's say if you're a temporal cortex activity now you're using population recordings, but it.
Yeah what if you can measure other stuff right like all the ion channel activations in all the neurons right all the extracellular contents and so on all the interests of your contents and he said yes, I want to build models that think can predict all of that stuff right so the so the only limiting factor there is like our ability to measure stuff and that and and the more we can measure that that automatically gets encompassed by the within the scope of the modeling enter exercise right and in that struck me as actually kind of surprising that he said that because It seemed to me that if your goal is to understand how a system can for example perform image classification, you might actually be doing a or object recognition you might be doing yourself a disservice because you could gain points in your score by basically just being able to capture the kinetics of ion channels without without actually improving your ability to project the aspects of the activation that are actually relevant for for doing object recognition in other.
Words like if you're the scope of your scientific theory is completely unbounded then you can score in ways that are kind of unrelated to the thing that you're actually trying to do in the first place yeah so I think this two I would I would agree with that and I would sort of nuance it in two ways, right so what what what are our critiques of a pure, you know, this kind of pure limitative version of science in which all we try to do is come up with a great predictive model well.
I mean number one is that, you know, there may be a future occasions in which you wish to exp. Lain particular parts of the variance in your data which are poorly captured by your predicted model right so your prediction model if you're just optimizing for a single for a single variable right it may well be the case that they're variables not actually very interesting and the way that your model succeeds is by capturing all the boring stuff and the the link to the specific case that we're considering which is you know, kind of trying to explain for instance population activity in IT is that you know, if you compare the amount of variance that is explained by deep supervised networks that are trained versus untrained.
It's actually a relatively modest improvement that you get by just training the network and what that means is that essentially most of your variance is being explained by what's present in the stimuli in the first place right it's nothing to do with an. Build. Models that are naturally all that useful in the in the in the long run and the second point I think is more critical and it's like why do we want forms of understanding which are not just blind prediction and for me that's because the translational opportunities which are presented by science are not just those that come with, you know, having fantastic predictive models.
I mean protein folding is a fantastic predictive model and you can think okay in that particular case all I need is a black box that's gonna tell me exactly how this protein folds and then I can, you know, fill malaria or whatever is gonna be done with it, but There.
Up manifold other cases in which, we need to also to have understanding for understanding sake and that's because the decisions which are consequent to those predictions bear upon aspects of our society which are you know, kind of have have have moral resonance or have consequences so in other words.
I'm talking about you know, interpretability and you know, the we want to be able to understand how systems work because it's only when we understand how systems work and can explain them that could we can make appropriate judgments. So we're in you know this context there might be a health context right so, you know, we need to understand how things work so we can make decisions that have consequences, you know for for patient care and not just for you know, kind of for diagnosis and prognosis for example that's also assuming that humans are the right judgers, right so why not just replace the human judgment with another black box predictive system that would if it's so good at what it's doing why rely on humans to to be the arbiter go ahead but I mean, we're talking about in any design system.
You're designing it to do something that you want to do right and part of the problem is that we don't know exactly how to specify that the design in the sense that like, you know, the the kind of common examples are like I want to build a robot that says make as much money as you can right but then the robot goes and sells your dog right now you didn't now it's doing what what you told it to do right but there's something that you didn't tell you didn't want it to do and it and because you didn't specify it in that way then.
Something bad happened and it's very easy to go off the rails in that way right like if you tell the system you pure malaria what happens if it, you know kills many thousands of people in the process and but still ultimately curious malaria so so we can't we it's inescapable right that there's a human and in the loop for these for like socially meaningful.
AI you start coming back to our earlier conversation, so sorry. A completely agree with that and you know for me an actual fact, you know, we talked about we framed this discussion around a distinction between you know general versus narrow AI and I actually see that distinction as being inextricably linked to precisely what Sam just highlighted right so for me any sort of generally intelligent system has to be a system which is able to forge its own priorities independent of a human who you know, kind of specifies them directly right at a system that is able to to work out what it should do in the context.
Of you know in the open-ended context of the data that it receives rather than satisfying an objective like, you know, kind of you know fault proteins are when it goes how far do you how far do you take that so if we think about actual humans we we spend a lot of time raising kids and kind of.
Programming them to have the same value not just the same values, but also the the same sort of methods for for achieving their goals, and and that's part of us. Inculcating the design specifications for living in human society and I would expect the same would be true of a robot right like when you say they should be able to operate independently.
I don't think you mean completely independently because they still have to kind of interact with human society and earth with just an eject and say that despite our best efforts to program our children, it doesn't work right so because of you know thing like in Chris is written about I was going to ask about intrinsic motivation and having something at stake and you know, the reward paradox etc and how much that.
Has to bear on on this sort of question of the general AI aspect and and having something at stake and having your own issues and and something to well intrinsic intrinsic motivation. I suppose to be the question but but Sam you're fooling yourself if you think you're probably programming your children well.
I didn't say I'm programming them well but I said that I think that we're underestimating how much we program our kids and how like they couldn't function in human society if all they did was. Poured resources for themselves and kill anyone who got in their way right like and they learned because your kids are not teenagers yet, you know, they they learn skills that allow them to cooperate and collaborate with other people so they I mean, I I agree and I mean, you know, if you ask me, I mean, we we haven't got to this point in the discussion but you know, my my view is that I don't think that we will be able to build general intelligence in any recognizable form and I think that actually as a project.
I actually don't see that as necessarily something which is going to be you know, the most advantageous goal for humanity. I mean, I I think you know, first of all, we have a lot of humans and you know, we probably don't want to build anymore or we don't need to build anymore and secondly I think you know more more seriously I think that so much of what we think of as human intelligence comes wrapped up with our our social nature with our culture with the things we learn from others from our parents from society with the values that we have.
And I think those values we acquire them by virtue of being human ourselves and I think it would be very difficult if not impossible for an agent which is not a human which does not have human status in society which does not have a human body a human abilities, which is not constrained by in the same way that a human is you know, you know, I can't like, you know, make a copy of my brain right but an AI system you could so a system that is not constrained in those ways.
I don't see how it could ever have the same sort of intelligence that we do doesn't. Mean that we. Can be able to build very powerful systems but I think the goal of sort of seeking to emulate a human is a little bit naive perhaps this obviously intersects with questions of value alone, but right so I mean you're saying that we may not value it as a species anyway that we would derive more value from a bunch of narrow AI then a human-like general AI is am I reading you correctly?
I mean, it's something in between right or sorry Chris you should answer the question yeah. I mean, I'm not saying that we shouldn't try to build stronger AI than we have right now and you know, I share completely old you know, The the things that Sam has highlighted right, you know, which is the the machine learning solutions that we have right now to be done very robust and you know, they're limited and they're applicability and so on.
I think we can do better but I think that you know, kind of. I sort of naive imagining of the end point of this research as being something which is you know, sort of walks and talks a little bit like us except kind of better is misguided by best and you know dangerous at worst.
I think if you look at how AI is portrayed in science fiction movies and literature, that's the kind of thing that I think most people have in mind when they talk about AGI right it's something it's like very capable assistance for humans right and I think what people sometimes forget is that.
There's a big difference between very capable assistance for humans and humans. Because we don't necessarily want. AI systems that have all the same values as us because those systems are going to expect the same privileges as us they're going to expect the same to be able to live the same lives as us right and we don't want to be in the business of like enslaving other humans right so they the minute that they really achieve that kind of humanity then that's going to be the point at which the artificial assistant era is kind of over right unless you're willing to start a new era of slate machine slavery, so I think that, Our goals should be to create good strong.
AI systems that can help us do things that we care about and not worry too much about perfectly emulating the human brain right so to bring some of these kinds of into conversations that have gone in two different directions, but to to bring these strands together. I mean, I guess for me what links these two topics is that in science we need understanding for understanding sake and for me, at least you know, having you know, great predictive models is not the soul objective of science.
And you know when we're thinking about AI, you know understanding additionally furnishes us with an opportunity to not only build powerful systems, but to to understand how those systems achieve the goals that they are said and thus to to have you know to be able to exert more control over them to behave in ways that we find to be acceptable right the value alignment problem, you know bypassing some of the potential externalities which will inevitably ensue from just sort of rampant, you know, kind of optimization of powerful agent.
S. Okay guys so I'm gonna throw a wrench in this real quick because just for the in the interest of time so we were gonna talk and and we may still talk about and from some of these questions about how could neuroscience can inform AI and how AI has and can inform neuroscience, we're gonna discuss Chris's recent paper if deep learning is the answer what's the question?
Well, one of the co-authors on that paper is Andrew Saxe and I enlisted him to ask a question. I'll just pay the question and I'm sorry if it's kind of an you know, orthogonal perhaps but I'm sure it'll we. Can bring it all back together. So, so here's the question and Sam this is you know, you can take this for you as well.
Hey Chris It was an absolute pleasure writing this paper with you and I feel like we see eye on so many things that yeah, it's just always wonderful to copyright with someone who feel like each person really gets where the other is coming from. That sort of makes it hard for me to ask it intriguing question, but that here's my attempt.
It would be reading this paper. We defend the idea that it's worth trying to understand these models. And yet I was reflecting on deep minds accomplishments and one of the features they seem to. Prize quite greatly in their systems is that their systems teach them something that the designers didn't know.
In AlphaGo, it discovered new moves and go that we're considered beautiful and certainly be on anything the designers knew. And in Alpha Fold we've learned something that there's no question no human has access to. And my question to you is heavily underappreciated the value of that type of scientific discovery.
Are those opportunities waiting for? Us in neuroscience. We're one of these complex models delivers fundamentally creative new knowledge, that humans can then go back and interpret? Okay, so it wasn't quite orthogonal. It turns out but there you go. There's thanks Andrew for the question. I mean, the question seems very related to the discussion that we were just having.
Yeah, so I guess my answer would be the same. So, you know if we focus on the on alphago, I mean, it's kind of interesting. It's certainly true that you know in a way the system is endowed with knowledge which we do not have in the sense that it can beat any of us convincingly at that game.
But to what extent that actually feeds back and provides us with new knowledge I think it's kind of debatable, right? I mean when AlphaGo came out I remember having a discussion with colleagues that did mind about what would constitute an explana
And I think I should probably credit Neil Rabinowitz with this insight and he said that you know, well on on the one hand you can think of sort of two extremes of explanation which alphago might give for one of its moves. So on the one hand, it might say well, you know, I made this move because You know.
Parameter 1 was set to this value parameter 2 was set to this value parameter 3 all the way up to you know, however many milliamp parameters it had. And that would be one answer which would be basically useless to us Alternatively you know it could say if you asked it why it made that movie could say well because because I wanted to win.
And that answer would also be useless to us. And I think that it's actually a really non-trivial problem to back out what might constitute genuine genuine interpretable knowledge even from these powerful systems. I mean the case of alpha fold is a bit different because with the blind prediction we don't understand necessarily helpful exactly half of all just making this predictions but because we know it does so accuracy we can accurately we can go on and do incredible things.
That's really really amazing. But I'm not actually sure that I agree with a central premise that we get that kind of interpretable knowledge for free out of these powerful agents. Yeah, just just an echo but Chris is saying I actually think that there's there's two ways to interpret what Andrew is saying here and went is a kind of less radical interpretation which is essentially that these kinds of systems are tools for discovering things in a similar way that a let's say a telescope was a tool for.
Galileo being able to see things that he couldn't see with his naked eye, right. So there were sort of cognitive and perceptual limitations that you know in let's say the commemoratorial space of go or protein folding we just can't evaluate all the different possibilities. So if we have a really powerful tool for efficiently searching the combinatorial space, then we can discover things that when presented to us we can using our own brains interpret the meaning of those discoveries, right?
So it's discovery in the sense that in the sense of a kind of measurement. Tool or prosthetic rather than a more radical notion of discovery, which is that the machine itself. Teaches us how to understand what it's doing, right? And I think that's what would Chris is talking about here.
And I think this is this is goes back actually. Paul to what you're saying about metacognition and what it means because if you take something like a go alphago is trained to win go, right? It's not trained to explain go to people, right? Now, you could try to build machines that do that, right?
And and I think that raises the question, why would you want to do that? And, For me the reason why you'd want it to do want to do that and this is essentially the problem of building interpretable. AI systems is that the systems when we design narrows specifications for what we want our systems to do that's useful and kind of convenient because we know how to do that, right?
We know how to tell a computer system how to play go, right? That doesn't mean it's easy to build it a system that actually wins go but it's easy to define the goal of the system. But when we say that we want a system to. Generalize in a flexible way it's actually not at all clear what we mean by generalized flexibly because we don't we haven't defined this the scope of flexible generalization in other words, we don't know what is the set of things that we just want to generalize over and and you can see this in a lot of the discussion about invariants in AI right so a lot of groups are interested in building invariants into their systems and everyone kind of agrees on intuitive examples, like if you have a representation of an object then if it should be in.
Here to certain kinds of transformations like if you move it around or make it bigger or smaller but in essence all of them all the definitions of invariants all the specific definitions of experience require some human to say this is what I want my system to be invariant to there's no way for the system to autonomously come up with what invariants it wants or except well.
I should qualify that I was thinking that there are people trying to build systems that can discover invariances and that I think that's an extremely interesting work a line of research, but it raises the kind of puzzle which is that. How do you know whether it's learning the right kind of invariances without humans being able to inspect the invariances that learn to say yes, that's a good invariance and no that's a bad in variance and that's why we need interpretability because we need to we need to we need to be able to verify that our system is doing the thing that we want.
I'm so glad you raised this issue so this is something that I you know, I feel very strongly about and I think that it's something that is often, you know, deeply overlooked, you know, I was just reading papers today in which you know, the kind of in the introduction section we've already.
Paid people as those kind of like you know starts off by saying humans are great at generalizing and like we were building machine learning systems but they don't do transfer learning or you know out of distribution inference nearly as well as humans and like well, how can we fix that right but of course, you know, there's a there's a there's a sort of hidden anthropocentrism in that statement, right which is the assumption that the way that humans generalize is like the correct way to do it and so you know, there's a well-known example which Gary Marcus is fond of illustrating to illustrate failures of generalization, which is where you have a network which should.
In theory learn an identity mapping between you know kind of binary from binary inputs to binary outputs and you know, you can show that if you try to do that in a few sample way then it fails on that that problem and I think what's not often discussed is the fact that implicit in that claim is the idea that the identity function is like the right thing to do so fundamentally when you want to talk about good generalization you're making an you're making an ontological claim you're making a claim about how the world is and thus what the generalization conditions which, We want should be and the thing is that you know going back to what we were just discussing how the world is is always seen through the lens of our values as humans right the world is as it is to us.
Because of our human nature and because of our you know, the our shared beliefs and our shared customs and our shared values across society and I think that you can't escape from that and I think that that human element because machine learning is born of statistics and computer science and these disciplines which have sort of elided the human aspect there's a failure to recognize that fundamentally actually these deep research questions are fundamentally questions about the world and specifically about the human world.
Do you think that so for me personally just viewing it. I feel like one of the things that machine learning and AI has taught us is just how poor we are at doing things and how limited our abilities are and and really how you know, like like you just add an introductory papers we're the most general thing ever, but really we're not very good at generalizing ourselves and we have all these constraints and limitations and I feel like AI has actually highlighted that and I'm wondering if you guys feel the same.
So AI is taught us about us in that respect so hard question send to you I want to know what you want again I know what you're gonna say before I try to answer the question well agent is the hard question part because I could agree with it depending or not depending on what exactly you mean.
I mean, there's certainly lots of ways in which we generalize very effectively that we don't know how to build the AI systems to generalize in that way, but I mean, I mean, what what kind of failures are you're thinking of oh I don't have it a specific example in mind unfortunately, but I just think in a in a general sense.
You know so AI can do very specific things very well using a very particular network you know deep learning network for instance and we may be extremely bad at doing that and that's a very that's a specialized example and that's I'm saying, you know, we transfer learn much better than AI does for instance but I think it has pointed out that we're not so good at a lot of things that we think we're good at I think was my main my main point right but I think I oh, okay, I think I understand you're saying like we could say we think we're really good at playing go but actually we're not that good at it because you can.
Build machines that do way better at us and we thought we were good because we're such generalized abstract thinkers for instance and and that's not the way to play go for instance unless that's what the the deep learning network is doing well, I'm not sure about that claim, right?
I don't know if anyone is claimed that the reason we're good at go is because we're such generalists. I think actually to be really good to go you have to be single-mindedly obsessed at it. I mean that I think that's true of any kind of expertise in a particular domain but not if you listen well and I only know this for chess not if you listen to the experts at chess, they're at least not aware of playing out all the scenarios right, they're only around.
Like they're heuristics of the board and the way the board is set up and they don't think six moves ahead they think I've been here before and this is what needs to happen because I can kind of see it. Right but I'm not I'm not making a claim about the specific mechanisms by which experts achieve success at these games.
I'm just saying that if you believe some of the theories about chess expertise, I don't know about Go experts, but I could imagine it is similar. For example, Herb Simon did quite a bit of research on chess expertise and the claim was that they are building up this massive data Grand Masters, for example are building up this massive database of patterns that they can refer to in determine their moves.
I almost feel like it's the opposite you could make the opposite claim right which is that. That machine learning has sort of swallowed in a kind of unexamined fashion the notion that humans are really really good at generalizing because you know the sorts of behaviors I guess that we would like our agents to be able to to engage in maybe there are things like, you know, we want them to be able to solve complex math problems or we want them to be able to do science so we want them to be able to you know, do means and reasoning to solve climate change or this kind of things and we recognize that these things are really hard and these are things that humans are actively engaged at and you know, given enough time and and resources might be able to do right?
But I think That the real problem with that statement is and this is unicode obviously relates to things that Samuel said before but it is I'm another subset before but the real problem with this statement is that it overlooks the extent to which that ability to reason abstractly is is like heavily grounded in the training that we have and the sharing of information that we have, you know, of course I can do multiplication.
I'm not very good at maths by the way, but you know, I can probably compute simple polynomials but like, you know, I can only do that because someone told me how to do it. And we we forget I think you know that when we are trying to train agents we forget that our ability to to to solve complex problems and to reason abstractly that we forget about the extent to which that comes only through, you know, really really careful nurturing of our understanding in an educational or curriculum setting and through the sharing of with other people and, You know, I think in a way there's a sort of naive motivation in a lot of papers and machine learning that focus on transfer learning which is like, oh, you know humans, you know use like as if you take you know, baby gym and sort of just give them a lot of data and then you know because there's something magical in his brain then suddenly, you know, he can like understand quantum physics and it's I think you know by trial and error and I think it's just not like that.
Yeah, I mean this is if you look in the comments psychology literature at the studies of analogical reasoning which I think are maybe paradigmatic of the the what we'd like AI systems to do in terms of flexible generalization actually humans are quite frequently quite dismal at that and you have to do a lot of cajoling to get people to recognize analogies at least in certain circumstances.
I think part of what Chris is saying is that in order to recognize analogies you need a lot of content knowledge in the different domains in order to be able to map between them that that's kind of the logic of cognitive theories about analogical reasoning like structure mapping where you need to start off with the right sort of primitives and relations in the two domains and then you can and then you can map between them unless you have that you can't achieve that mapping yeah, so
I think you know one one of the mistakes that people make in in contemporary AI research is to is to failure to treat the kinds of computation that underlie sensory motor behaviors and the kinds of computation that underlie, you know, cognitive behaviors reasoning and influence inference a failure to treat those differentially and I think there's a fundamentally different sorts of problems and I think they're solved in fundamentally different ways in the human brain.
I think that you know, if you look at sensory motor behaviors, you know, it takes years or months years for us to learn to to walk and to record. S for example right requires a lot of data and, you know, it's a highly complex nonlinear problem at the end of which we have, you know, reasonably useful representations both of objects and of motor patterns, right and I think the long time to learn and I think that you know, when we look at human cognitive behavior, there's an assumption that the same thing sort of happens right that we just use, you know, big complex function approximation to acquire knowledge about you know, I don't know, you know how to do legal jurisprudence or how to diagnose.
Illnesses or you know how to I don't know understand the pancreas right and I just think that that those types of understanding those kinds that that rely on structured knowledge are not acquired in the same way that sensory motor behaviors are acquired they're quite in fundamentally different ways and it's not just through lots of training and lots of feedback whether that's reinforcement or supervised it's it's for a fundamentally different process that has much more to do with sort of assembling little packets of knowledge into composite.
Holes bootstrapping off, you know, existing fragmentary understanding to try to gradually build up the sorts of knowledge bases that allow us to function effectively. I think computationally it's a completely completely different process and I think that's you know, in in thinking about you know, the the nature of reasoning and thinking about how we solve these types of problems.
I think it's really really important to separate those two domains. So Sam the last time you're on the podcast, you recommended the book what is thought by Eric bomb and in that I started reading it the way he thinks of the mind which is what we all kind of want to understand or that's an assumption on my part.
I what I want to understand the way he thinks of a mind is as a collection of well, the mind is a program and not only is it a program it's a collection like all programs are of subroutines of sub functions and he posits, you know, that most of the the great stuff.
That we? You of course is unconscious and these are all like the tiny sub subroutines working in the background and I'm hoping that this is related to what what Chris was just talking about and that what the end result of all these subroutines working together somehow all these modules working together is what results in mind and what we what we think of as mind but analytical reasoning for instance, you know, and the awareness of coming up with analogy is just kind of this end result of all these subroutines working and in a massive.
Interaction and that you know, we need to understand how the subroutines or algorithms are combining and being reused for various different cognitive functions and that's the way to go about understanding how our higher cognitive functions and our minds come about and Chris has noted in talks, you know, and especially with an AI, you know, modules like attention being added, you know, memory external memory those sorts of modules being added.
Chris has noted that one thing he thinks is important. Moving forward in AI is to figure out how to make all these little modules work together and function together and that might be key to developing some of these higher cognitive functions that are more human-like right or more powerful anyway, so I want to throw that out there first of all, but I also wanted to ask if that is a place that is ripe for neuroscience cognitive science to inform AI or if that's a place where AI is just going to fit engineer it and if and if you still if you agree with that Eric bomb, if you still recommend that book and if you agree with that.
Conception of mind as well. Sam yeah, well I think just heartening back to the thing that Chris said last about these sort of two completely different computational processes for acquiring different kinds of information on the one hand since remoter learning that might rely on some kind of dense function approximation, whereas.
A higher cognition is something more modular and maybe hierarchical I don't know if Chris I'm I'm paraphrasing you correctly but I mean it's maybe maybe it's a little bit too extreme to say this completely different learning mechanism like you know, who who knows maybe both of them rely on back prop, but but I I do agree that the basis of higher cognition has to do with putting together simple building blocks into more complex functioning that that is undoubtedly true and if you want to.
Learn those abilities you have to have strong inductive biases that promote discovery of this kind of modularity and heretical composition and so on right um and those kinds of inductive biases might be fundamentally different than the kinds of inductive biases you need to learn a dense, let's say feed forward mapping from sensory to motor programs.
But in terms of your question Paul about whether we can benefit from studying the brain, I guess it's just all depends on what exactly one means by that because. You know there's just tons of data on things like attention and memory right but only some of that data is actually going to be useful from an engineering perspective and we just I don't feel like neuroscientists have made a sufficiently precise case about which aspects of the brain and mind are actually useful for engineering so I think that's a that's a I would guess a reason to have more dialogue at the level of here are these particular things that people do not just in general like complementary learning systems in some very general sense, but actually like here's how we think computationally come to complementary.
Systems or attention works in the brain can we leverage those ideas for for AI and so another way of saying that is computational cognitive nurse scientists are building models all the time of things like attention and memory but I think from the perspective of the engineers these models are not particularly useful because they're not scalable and they and they're designed to explain some very specific phenomena as opposed to being some kind of general purpose tool that can suck in data and solve some tasks that we agree is is useful.
When interesting and so there's a kind of disconnect in the in the methodologies so and I'm I I gather that I think I think at least people at deed mind, for example are interested in probing this more like can we take the computational ideas from computational cognitive nurse science and sort of upgrade them so that they can work in actual intelligent systems, yeah.
I mean, I think that's absolutely right. I mean, I I completely agree that you know, there's that there is a major barrier in translating any of these ideas whether it's ideas about Composition or whether it's ideas about memory systems or attention or whatever a major barrier in translating from neuroscience to to AI and that is you know, the what one barrier is I mentioned is just scale right so we tend to build toy models in neuroscience and everything, you know in machine learning it's it's not whether it works the better is whether it's scales right or at least that's at least as important the second issue is that in neuroscience we tend to focus, you know, we tend to be narrowly focused so most people.
I mean, I think you know Sam's group is really an exception because of the the breadth of topics which are Studied in his in his lab but most groups focus on either one brain area or one method or you know one process and they sort of drill down into that and try to understand it and you know, of course that's fine if you just want to model some data, you know from neurons but it's not fine if you want the whole system to work.
And then the last gap is that our models tend to be pretty handcrafted, of course in neuroscience right and so you know, handcrafted models have relatively limited utility and contemporary machine so all those are serious impediments to you know mean all those mean that you can't just take sort of ideas from neuroscience off the shelf and translate them into.
Viable machine learning methods but I think you know, I'm sure somebody agree that the whole point of what we're doing in in cognitive science and computational neuroscience is basically to try to come up with like good new ideas that might be seeds that might be you know planted and might scale not all of them are going to scale right but they're just interesting principles about how information processing systems work that give us the nugget of an insight that might one day be translated into something bigger and more powerful.
I'm reminded of when my kids were little and you get all this parenting advice and I remember my my parents had particularly strong feelings about various things and I asked them did you did you do the same thing for my brother and they said sure and I said did it work and they said no, of course not he's totally different he said so why do you think it would work for my kids and and my wife had the the sage wisdom to point out that like we shouldn't be thinking about parenting advice as sort of ironclad.
Rules about how things should be done but just ideas to be tried so maybe cognitive nurse science is kind of like the the naggy parent for AI to give it giving various kinds of rules about how the brain works but it's up to the engineers to kind of figure out I need to use those suggestions and to figure out what's actually useful yeah just interviewed Alison Govnik who was written a whole book about parenting is a recent word and to be a parent is different than parenting and we shouldn't parent or we shouldn't yeah, we shouldn't parent it's the it's not a real verb we've only.
Got it on recently in society as a verb because it doesn't work so I guess what you're saying is cognitive science doesn't work for AI yeah, no. I mean, I just think I think I I like Chris's perspective because I think it's it's more pragmatic it's saying like we shouldn't we shouldn't hope that cognizance we're gonna give us completely but like fully functional computational principles for artificial intelligence what they're gonna give us are seeds for the construction of engineering systems because it's just any any realistically any system that's gonna work in the real world is gonna require.
All sorts of extra stuff that we're not gonna get from these kinds of stylized models that we typically use in cognitive science and neuroscience so in philosophy of mind so there's always there's been this age old question of whether mental or states are causal right so a limited to visit them says that they aren't that eventually we will you know, the the functional states of the at the implementation level essentially will will learn enough about them that mental states will figure out.
Are eventually not causal do you think that AI will settle that debate, you know building these networks and and we'll be able to use you know, build AI that's explainable enough to us that we can understand enough that that it will settle the debate of whether mental states quote unquote are causal or whether it's just all network properties or what that become a moot.
Question. I think the answer to the question is no I don't think anything will ever settle any philosophical debates. I think the point of those philosophical bit debates is not to be settled it is to they are they are tools for the exploration of reason itself and the the entrainment of cognitive processes that surround rhetoric and debate and their ways of thinking about problems.
I don't think that yeah, I don't think the point of that debate is to be settled maybe I'm an outline maybe I philosophers who are listening well just want to shoot me at this point with it yeah last last question just just where where did we end up here so how so how useful is neuroscience for AI how?
You know and vice versa but most the first question because that's the question that I think is mostly assumed is that nurse these days is that neuroscience is not very useful for AI so I don't know where did we come to I have about a thousand more questions as you guys know but we'll end up with this one did we settle anything?
I mean, I'm still totally open to us discovering things from neuroscience, that'll be useful for AI, I just think that we have to keep in mind that in order to be able to recognize some discovery as being useful in the first place you need to be able to. Computationally implement it right and you need to be able to recognize the computations in the first place it's sort of like if I just stumbled upon a touring machine on the sidewalk and I didn't know anything about touring machines would I be able to you know, understand a touring machine just from from like handling this artifact like maybe that's possible in principle but it would be extremely challenging and so I think the same is true for neuroscience maybe even more true that we we have to just start with a we have to go into with computational principles in order to be able to.
Recognize anything in the first place and and so the the process of translating from neuroscience to AI is more of a process of kind of as I said upgrading the discoveries from neuroscience and the models from neuroscience as opposed to like this sort of naively and purists mode of discovery where where we like find some biological phenomenon and plug it into our models and all of a sudden our models are going to have the might be much more powerful Chris I want but I have one question for you.
I hear the baby crying it's from the deep learning is the answer paper, so one of the things that You guys write about is, you know, using idealistic reduced deep deep deep models so that we can conceptually understand what's going on this goes back to understanding and and I'm wondering if do you think our conceptual insight will ever catch up to the complexity of what we can build and use well that complexity forever be a couple steps ahead while we're trying to look at that huge model reduce it into an answerable question for our understanding and that's how we advance our understanding.
I guess the messy real world is always you know ahead of our idealizations of it right that's just a general principle but I mean those idealizations. I mean, hopefully there they're useful for lots of things. I mean, I what one of the the reasons why I think it's a great time to be a cognitive scientist or a neuroscientist is precisely because there is this reawakened interest in models that kind of learn by themselves, right so it means that the dynamics of learning the ways in which we learn, you know, the the ways we can accelerate learning the structure in our learning like all of these are viable.
Questions in a way that they were not when the state spaces of our models were entirely populated by hand. And that's the the opportunity that that my lab has tried to seize and to study add small-scale but to study for its own sake right? I mean these questions, you know, clearly may have resonance one day probably not in my hands probably in Sam's hands but may have resonance for for AI one day, but for me really the goal is just to understand the principles of learning use these tools these networks as tools for understanding principles of learning press.
63 Abramson et al [2] describe an ambitious research agenda to build interactive agents that learn by imitation to perform tasks while simultaneously learning to communicate with other agents using natural language thereby grounding language in their experience of the (simulated) physical world. Fu et al [103] directly address some of the key challenges in pursuing the Abramson et al agenda:
While reinforcement learning provides a powerful and flexible framework for describing and solving control tasks, it requires the practitioner to specify objectives in terms of reward functions. Engineering reward functions is often done by experienced practitioners and researchers, and even then can pose a significant challenge, such as when working with complex image-based observations. While researchers have investigated alternative means of specifying objectives, such as learning from demonstration, or through binary preferences, language is often a more natural and desirable way for humans to communicate goals.A common approach to building natural language interfaces for reinforcement learning agents is to build language-conditioned policies that directly map observations and language commands to a sequence of actions that perform the desired task. However, this requires the policy to solve two challenging problems together: understanding how to plan and solve tasks in the physical world, and understanding the language command itself. The trained policy must simultaneously interpret a command and plan through possibly complicated environment dynamics. The performance of the system then hinges entirely on its ability to generalize to new environments if either the language interpretation or the physical control fail to generalize, the entire system will fail.
We can recognize instead that the role of language in such a system is to communicate the goal, and rather than mapping language directly to policies, we propose to learn how to convert language-defined goals into reward functions. In this manner, the agent can learn how to plan and perform the task on its own via reinforcement learning, directly interacting with the environment, without relying on zero-shot transfer of policies. A simple example is shown in Figure 1, where an agent is tasked with navigating through a house. If an agent is commanded "go to the fruit bowl", a valid reward function could simply be a fruit bowl detector from first-person views of the agent. However, if we were to learn a mapping from language to actions, given the same goal description, the model would need to generate a different plan for each house.
64 An example from Brande et al [43] of how useful technology is more easily spread within a population using a language embedded in shared human experience (SOURCE):
 |
65 Below is the message sent to a group of students who took CS379C in 2019 and 2020 soliciting their help in planning out the content and projects for CS379C in 2021. One reasonable target is to make CS379C a logical next course for students who are taking PSYCH 209 Neural Network Models of Cognition in the Winter quarter. Here is the call for participation:
To: Elizabeth Tran <eliztran@stanford.edu>, Julia Gong <jxgong@stanford.edu>, Samsara Pappu Durvasula <samsarad@stanford.edu>, Eric Zelikman <ezelikman@stanford.edu>, Dawn Finzi <dfinzi@stanford.edu>, Natalie Cygan <cygann@stanford.edu>, Dat Pham Nguyen <dpnguyen@stanford.edu>, Ethan Richman <richman@stanford.edu>, Chris Waites <cwaites10@gmail.com>, Sajana Hemandra Weerawardhena <sajana@stanford.edu>, Tyler Stephen Benster <tbenst@stanford.edu>, Megumi Sano <megsano@stanford.edu>, Vidya Rangasayee <rvidya@stanford.edu>, Manon Romain <manonrmn@stanford.edu>, Paul Warren <pwarren@stanford.edu>, Michael Zhu <mzhu25@stanford.edu>, Albert Tung <atung3@stanford.edu>, Brian Lui <brianlui@stanford.edu>, Ying Hang Seah <yinghang@stanford.edu>, Jing Lim <jinglim2@stanford.edu>, Ben Newman <blnewman@stanford.edu>, Lucas Sato <satojk@stanford.edu>, Sam Ginn <samginn@stanford.edu>
Cc: Rafael Mitkov Rafailov <rafailov@stanford.edu>, Chaofei Fan <stfan@stanford.edu>, Riley DeHaan <rdehaan@stanford.edu>
I am writing to you in the hope of enlisting your help in planning the content for CS379C in the Spring quarter. CS379C is intended as an advanced course focusing on the latest machine learning and deep neural network technology with an emphasis on applications that take inspiration from current research in systems and cognitive neuroscience. The ideal student for CS379C has taken one or more computer science courses that emphasize ML and DNN technology or has used such technology in an internship or lab rotation. Familiarity with basic concepts in cognitive or systems neuroscience is definitely a plus,
Following on CS379C in the spring of 2020, several students taking the class and a couple from the previous year worked with me on projects that built on ideas introduced but not thoroughly explored in the 2020 class. Due to the shortened 2020 quarter and problems related to the ongoing pandemic, it was not practical to require students to work on projects that involved significant coding. This year I'm hoping that will not be the case and I've been preparing for that possibility by thinking about projects that might be relevant while at the same time tractable within the time constraints of the quarter.
What I have in mind for the next couple of months is to find several students willing to meet with me once a week for approximately an hour to discuss topics, invited speakers and sample projects for 2021. If you are interested in joining us, please get in touch with me soonest. Also if you know of any students who would be good candidates to serve as a teaching assistant for the course in the Spring, I would be most grateful for your suggestions.
Tom
P.S. I recently gave a presentation on some of our recent work on code synthesis in the weekly FriSem seminar in the psychology department. Given the varied background of the participants, the coverage in the first half of the presentation was intended as a relatively high-level overview of our work with emphasis toward the end on the role of search. In the second half, I motivated the potential advantages of using natural language and the power of analogy as an alternative to conventional search for automated programming, with a nod to the recent DeepMind paper referenced below. This mix of practical targets and aspirational reach is representative of the sort of experience I hope to provide in CS379C.
66 A selection of papers on cell assemblies including early work by Donald Hebb and Valentino Braitenberg, more recent research on hypotheses concerning how cell assemblies communicate and coordinate their behavior and a relatively recent retrospective survey:
Newer Cell-Assembly References:
@article{MengetalFiCN-16,
author = {Li, Meng and Liu, Jun and Tsien, Joe Z.},
title = {Theory of Connectivity: Nature and Nurture of Cell Assemblies and Cognitive Computation},
journal = {Frontiers in Neural Circuits},
volume = {10},
pages = {34},
year = {2016},
abstract = {Richard Semon and Donald Hebb are among the firsts to put forth the notion of cell assembly—a group of coherently or sequentially-activated neurons—to represent percept, memory, or concept. Despite the rekindled interest in this century-old idea, the concept of cell assembly still remains ill-defined and its operational principle is poorly understood. What is the size of a cell assembly? How should a cell assembly be organized? What is the computational logic underlying Hebbian cell assemblies? How might Nature vs. Nurture interact at the level of a cell assembly? In contrast to the widely assumed randomness within the mature but naïve cell assembly, the Theory of Connectivity postulates that the brain consists of the developmentally pre-programmed cell assemblies known as the functional connectivity motif (FCM). Principal cells within such FCM is organized by the power-of-two-based mathematical principle that guides the construction of specific-to-general combinatorial connectivity patterns in neuronal circuits, giving rise to a full range of specific features, various relational patterns, and generalized knowledge. This pre-configured canonical computation is predicted to be evolutionarily conserved across many circuits, ranging from these encoding memory engrams and imagination to decision-making and motor control. Although the power-of-two-based wiring and computational logic places a mathematical boundary on an individual’s cognitive capacity, the fullest intellectual potential can be brought about by optimized nature and nurture. This theory may also open up a new avenue to examining how genetic mutations and various drugs might impair or improve the computational logic of brain circuits.}
}
@article{TetzlaffSR-15,
author = {Tetzlaff, Christian and Dasgupta, Sakyasingha and Kulvicius, Tomas and W{\:{o}}rg{\:{o}}tter, Florentin},
title = {The Use of Hebbian Cell Assemblies for Nonlinear Computation},
journal = {Scientific Reports},
year = {2015},
volume = {5},
issue = {1},
pages = {12866},
abstract = {When learning a complex task our nervous system self-organizes large groups of neurons into coherent dynamic activity patterns. During this, a network with multiple, simultaneously active and computationally powerful cell assemblies is created. How such ordered structures are formed while preserving a rich diversity of neural dynamics needed for computation is still unknown. Here we show that the combination of synaptic plasticity with the slower process of synaptic scaling achieves (i) the formation of cell assemblies and (ii) enhances the diversity of neural dynamics facilitating the learning of complex calculations. Due to synaptic scaling the dynamics of different cell assemblies do not interfere with each other. As a consequence, this type of self-organization allows executing a difficult, six degrees of freedom, manipulation task with a robot where assemblies need to learn computing complex non-linear transforms and - for execution - must cooperate with each other without interference. This mechanism, thus, permits the self-organization of computationally powerful sub-structures in dynamic networks for behavior control.},
}
@article{PalmetalBC-14,
author = {Palm, G{\"{u}}nther and Knoblauch, Andreas and Hauser, Florian and Sch{\"{u}}z, Almut},
title = {Cell assemblies in the cerebral cortex},
journal = {Biological Cybernetics},
year = {2014},
volume = {108},
issue = {5},
pages = {559-572},
abstract = {Donald Hebb's concept of cell assemblies is a physiology-based idea for a distributed neural representation of behaviorally relevant objects, concepts, or constellations. In the late 70s Valentino Braitenberg started the endeavor to spell out the hypothesis that the cerebral cortex is the structure where cell assemblies are formed, maintained and used, in terms of neuroanatomy (which was his main concern) and also neurophysiology. This endeavor has been carried on over the last 30 years corroborating most of his findings and interpretations. This paper summarizes the present state of cell assembly theory, realized in a network of associative memories, and of the anatomical evidence for its location in the cerebral cortex.},
}
@article{PulvermulleretalBC-14,
author = {Pulverm{\"{u}}ller, F. and Garagnani, M. and Wennekers, T.},
title = {Thinking in circuits: toward neurobiological explanation in cognitive neuroscience},
journal = {Biological Cybernetics},
year = {2014},
volume = {108},
number = {5},
pages = {573-593},
abstract = {Cognitive theory has decomposed human mental abilities into cognitive (sub) systems, and cognitive neuroscience succeeded in disclosing a host of relationships between cognitive systems and specific structures of the human brain. However, an explanation of why specific functions are located in specific brain loci had still been missing, along with a neurobiological model that makes concrete the neuronal circuits that carry thoughts and meaning. Brain theory, in particular the Hebb-inspired neurocybernetic proposals by Braitenberg, now offers an avenue toward explaining brain-mind relationships and to spell out cognition in terms of neuron circuits in a neuromechanistic sense. Central to this endeavor is the theoretical construct of an elementary functional neuronal unit above the level of individual neurons and below that of whole brain areas and systems: the distributed neuronal assembly (DNA) or thought circuit (TC). It is shown that DNA/TC theory of cognition offers an integrated explanatory perspective on brain mechanisms of perception, action, language, attention, memory, decision and conceptual thought. We argue that DNAs carry all of these functions and that their inner structure (e.g., core and halo subcomponents), and their functional activation dynamics (e.g., ignition and reverberation processes) answer crucial localist questions, such as why memory and decisions draw on prefrontal areas although memory formation is normally driven by information in the senses and in the motor system. We suggest that the ability of building DNAs/TCs spread out over different cortical areas is the key mechanism for a range of specifically human sensorimotor, linguistic and conceptual capacities and that the cell assembly mechanism of overlap reduction is crucial for differentiating a vocabulary of actions, symbols and concepts.}
}
Older Cell-Assembly References:
@article{BuzsakiandWatsonDNC-12,
author = {Buzsaki, G. and Watson, B. O.},
title = {Brain rhythms and neural syntax: implications for efficient coding of cognitive content and neuropsychiatric disease},
journal = {Dialogues Clinical Neuroscience},
year = {2012},
volume = {14},
issue = {4},
pages = {345-367},
abstract = {The perpetual activity of the cerebral cortex is largely supported by the variety of oscillations the brain generates, spanning a number of frequencies and anatomical locations, as well as behavioral correlates. First, we review findings from animal studies showing that most forms of brain rhythms are inhibition-based, producing rhythmic volleys of inhibitory inputs to principal cell populations, thereby providing alternating temporal windows of relatively reduced and enhanced excitability in neuronal networks. These inhibition-based mechanisms offer natural temporal frames to group or "chunk" neuronal activity into cell assemblies and sequences of assemblies, with more complex multi-oscillation interactions creating syntactical rules for the effective exchange of information among cortical networks. We then review recent studies in human psychiatric patients demonstrating a variety alterations in neural oscillations across all major psychiatric diseases, and suggest possible future research directions and treatment approaches based on the fundamental properties of brain rhythms.}
}
@article{CanoltyetalJoN-12,
author = {Canolty, Ryan T. and Cadieu, Charles F. and Koepsell, Kilian and Ganguly, Karunesh and Knight, Robert T. and Carmena, Jose M.},
title = {Detecting event-related changes of multivariate phase coupling in dynamic brain networks},
journal = {Journal of Neurophysiology},
volume = {107},
number = {7},
year = {2012},
pages = {2020-2031},
abstract = {Oscillatory phase coupling within large-scale brain networks is a topic of increasing interest within systems, cognitive, and theoretical neuroscience. Evidence shows that brain rhythms play a role in controlling neuronal excitability and response modulation (Haider B, McCormick D. Neuron 62: 171–189, 2009) and regulate the efficacy of communication between cortical regions (Fries P. Trends Cogn Sci 9: 474–480, 2005) and distinct spatiotemporal scales (Canolty RT, Knight RT. Trends Cogn Sci 14: 506–515, 2010). In this view, anatomically connected brain areas form the scaffolding upon which neuronal oscillations rapidly create and dissolve transient functional networks (Lakatos P, Karmos G, Mehta A, Ulbert I, Schroeder C. Science 320: 110–113, 2008). Importantly, testing these hypotheses requires methods designed to accurately reflect dynamic changes in multivariate phase coupling within brain networks. Unfortunately, phase coupling between neurophysiological signals is commonly investigated using suboptimal techniques. Here we describe how a recently developed probabilistic model, phase coupling estimation (PCE; Cadieu C, Koepsell K Neural Comput 44: 3107–3126, 2010), can be used to investigate changes in multivariate phase coupling, and we detail the advantages of this model over the commonly employed phase-locking value (PLV; Lachaux JP, Rodriguez E, Martinerie J, Varela F. Human Brain Map 8: 194–208, 1999). We show that the N-dimensional PCE is a natural generalization of the inherently bivariate PLV. Using simulations, we show that PCE accurately captures both direct and indirect (network mediated) coupling between network elements in situations where PLV produces erroneous results. We present empirical results on recordings from humans and nonhuman primates and show that the PCE-estimated coupling values are different from those using the bivariate PLV. Critically on these empirical recordings, PCE output tends to be sparser than the PLVs, indicating fewer significant interactions and perhaps a more parsimonious description of the data. Finally, the physical interpretation of PCE parameters is straightforward: the PCE parameters correspond to interaction terms in a network of coupled oscillators. Forward modeling of a network of coupled oscillators with parameters estimated by PCE generates synthetic data with statistical characteristics identical to empirical signals. Given these advantages over the PLV, PCE is a useful tool for investigating multivariate phase coupling in distributed brain networks.}
}
@article{BuzsakiNEURON-10,
title = {Neural Syntax: Cell Assemblies, Synapsembles, and Readers},
author = {Gy{\"{o}}rgy Buzs{\'{a}}ki},
journal = {Neuron},
volume = {68},
number = {3},
year = {2010},
pages = {362-385},
abstract = {A widely discussed hypothesis in neuroscience is that transiently active ensembles of neurons, known as "cell assemblies," underlie numerous operations of the brain, from encoding memories to reasoning. However, the mechanisms responsible for the formation and disbanding of cell assemblies and temporal evolution of cell assembly sequences are not well understood. I introduce and review three interconnected topics, which could facilitate progress in defining cell assemblies, identifying their neuronal organization, and revealing causal relationships between assembly organization and behavior. First, I hypothesize that cell assemblies are best understood in light of their output product, as detected by "reader-actuator" mechanisms. Second, I suggest that the hierarchical organization of cell assemblies may be regarded as a neural syntax. Third, constituents of the neural syntax are linked together by dynamically changing constellations of synaptic weights ("synapsembles"). The existing support for this tripartite framework is reviewed and strategies for experimental testing of its predictions are discussed.}
}
@article{CanoltyetalPNAS-10,
title = {Oscillatory phase coupling coordinates anatomically dispersed functional cell assemblies},
author = {Canolty, Ryan T. and Ganguly, Karunesh and Kennerley, Steven W. and Cadieu, Charles F. and Koepsell, Kilian and Wallis, Jonathan D. and Carmena, Jose M.},
journal = {Proceedings of the National Academy of Sciences},
volume = 107,
issue = 40,
year = 2010,
pages = {17356-17361},
abstract = {Hebb proposed that neuronal cell assemblies are critical for effective perception, cognition, and action. However, evidence for brain mechanisms that coordinate multiple coactive assemblies remains lacking. Neuronal oscillations have been suggested as one possible mechanism for cell assembly coordination. Prior studies have shown that spike timing depends upon local field potential (LFP) phase proximal to the cell body, but few studies have examined the dependence of spiking on distal LFP phases in other brain areas far from the neuron or the influence of LFP--LFP phase coupling between distal areas on spiking. We investigated these interactions by recording LFPs and single-unit activity using multiple microelectrode arrays in several brain areas and then used a unique probabilistic multivariate phase distribution to model the dependence of spike timing on the full pattern of proximal LFP phases, distal LFP phases, and LFP--LFP phase coupling between electrodes. Here we show that spiking activity in single neurons and neuronal ensembles depends on dynamic patterns of oscillatory phase coupling between multiple brain areas, in addition to the effects of proximal LFP phase. Neurons that prefer similar patterns of phase coupling exhibit similar changes in spike rates, whereas neurons with different preferences show divergent responses, providing a basic mechanism to bind different neurons together into coordinated cell assemblies. Surprisingly, phase-coupling-based rate correlations are independent of interneuron distance. Phase-coupling preferences correlate with behavior and neural function and remain stable over multiple days. These findings suggest that neuronal oscillations enable selective and dynamic control of distributedfunctional cell assemblies.},
}
@article{MiltneretalNATURE-09,
author = {Miltner, W. H. and Braun, C. and Arnold, M. and Witte, H. and Taub, E.},
title = {Coherence of gamma-band {EEG} activity as a basis for associative learning},
journal = {Nature},
year = 1999,
volume = 397,
issue = 6718,
pages = {434-436},
abstract = {Different regions of the brain must communicate with each other to provide the basis for the integration of sensory information, sensory-motor coordination and many other functions that are critical for learning, memory, information processing, perception and the behaviour of organisms. Hebb suggested that this is accomplished by the formation of assemblies of cells whose synaptic linkages are strengthened whenever the cells are activated or 'ignited' synchronously. Hebb's seminal concept has intrigued investigators since its formulation, but the technology to demonstrate its existence had been lacking until the past decade. Previous studies have shown that very fast electroencephalographic activity in the gamma band (20-70 Hz) increases during, and may be involved in, the formation of percepts and memory, linguistic processing, and other behavioural and perceptual functions. We show here that increased gamma-band activity is also involved in associative learning. In addition, we find that another measure, gamma-band coherence, increases between regions of the brain that receive the two classes of stimuli involved in an associative-learning procedure in humans. An increase in coherence could fulfil the criteria required for the formation of hebbian cell assemblies, binding together parts of the brain that must communicate with one another in order for associative learning to take place. In this way, coherence may be a signature for this and other types of learning.}
}
@inproceedings{Braitenberg1978cellassemblies,
author = {Braitenberg, Valentino},
editor = {Heim, Roland and Palm, G{\"{u}}nther},
title = {Cell Assemblies in the Cerebral Cortex},
booktitle = {Theoretical Approaches to Complex Systems},
year = {1978},
publisher = {Springer Berlin Heidelberg},
address = {Berlin, Heidelberg},
pages = {171-188},
abstract = {To say that an animal responds to sensory stimuli may not be the most natural and efficient way to describe behaviour. Rather, it appears that animals most of the time react to situations, to opponents or things which they actively isolate from their environment, Situations, things, partners or opponents are, in a way, the terms of behaviour. It is legitimate, therefore, to ask what phenomena correspond to them in the internal activity of the brain, or, in other words: how are the meaningful chunks of experience "represented" in the brain?},
}
@book{Hebb_The_Organization_of_Behavior-1949,
author = {Hebb, Donald O.},
title = {The organization of behavior: {A} neuropsychological theory},
publisher = {Wiley},
address = {New York},
year = 1949,
abstract = {Donald Hebb pioneered many current themes in behavioural neuroscience. He saw psychology as a biological science, but one in which the organization of behaviour must remain the central concern. Through penetrating theoretical concepts, including the "cell assembly," "phase sequence," and "Hebb synapse," he offered a way to bridge the gap between cells, circuits and behaviour. He saw the brain as a dynamically organized system of multiple distributed parts, with roots that extend into foundations of development and evolutionary heritage. He understood that behaviour, as brain, can be sliced at various levels and that one of our challenges is to bring these levels into both conceptual and empirical register. He could move between theory and fact with an ease that continues to inspire both students and professional investigators. Although facts continue to accumulate at an accelerating rate in both psychology and neuroscience, and although these facts continue to force revision in the details of Hebb's earlier contributions, his overall insistence that we look at behaviour and brain together within a dynamic, relational and multilayered framework remains. His work touches upon current studies of population coding, contextual factors in brain representations, synaptic plasticity, developmental construction of brain/behaviour relations, clinical syndromes, deterioration of performance with age and disease, and the formal construction of connectionist models. The collection of papers in this volume represent these and related themes that Hebb inspired. We also acknowledge our appreciation for Don Hebb as teacher, colleague and friend.},
}
67 Here is the title, abstract and related materials for a talk I gave on January 15, 2021 in the friday seminar series sponsored by the Stanford psychology department:
Title: On the Role of Search in Brain Inspired Architectures for Automated ProgrammingIn CS379C in the Spring of 2020 we discussed a paper by Josh Merel, Matt Botvinick and Greg Wayne entitled "Hierarchical motor control in mammals and machines". Josh gave an invited lecture on their work that you can find here and joined in discussions with us during the remainder of the quarter. The Merel et al paper focuses on motor control and in our class discussions we investigated what lessons could be learned from their model in developing cognitive architectures for solving problems like automated programming.
The SARS-CoV-2 outbreak and shortened quarter were not conducive to class projects requiring substantial coding, but we spent a lot of our time thinking about what such architectures might look like. At the end of the quarter, I asked several students if they were interested in developing a cognitive architecture based on our discussions in class and five of us spent a substantial fraction of the next six months working on the project. In this talk, I will describe the project and the lessons we learned that led to developing a very different perspective than one might expect given our technical leanings at the outset of the project.
Readings: Josh Merel's recorded lecture and slides are available here. The paper in Nature Communications is open access and available here. I call your attention to the inset Box 1 entitled "Reusable motor skills for hierarchical control of bodies" for an overview of the neural network model, and Box 2 entitled "Review of the neuroanatomical hierarchy" for the corresponding biological inspiration. I kept copious notes concerning our discussions during the six months that we worked on the project. Figure 2 in the online notes summarizes the status of the model in early November when I gave a talk in one of Jay McClelland's weekly lab meetings, but the accompanying summary description in the main text was not intended to be self contained and I will attempt to succinctly summarize the basic features of the model and associated implementation in my talk.
P.S. Andrew asked me to supply a fun fact about myself: While the more studious of my generation spent the late 60s and early 70s attending college and then graduate school, I spent these years hitchhiking around the country, participating in counterculture movements, protesting the war in Vietnam, and eventually buying a 60 acre farm in Virginia where I restored industrial machine tools and designed and built handmade one-of-a-kind furniture and houses to pay the bills.
My students often ask about my background and some are incredulous listening to my accounts. It is hard to convey what it was like in those years to people who followed a more conventional path. Given the impersonal nature of our shelter-in-place arrangements early in the pandemic, I wrote a condensed biographical history for the students in CS379C in the Spring. I think it provides a more balanced perspective on what is admittedly a road less traveled. My abbreviated personal history is accessible on the course website here if you're interested.
68 Extelligence is the cultural capital available to humans through language in all its forms including written, spoken and signed. Figments of Reality: The Evolution of the Curious Mind by Ian Stewart and Jack Cohen, Cambridge University Press, 1997. The Symbolic Species: The Co-evolution of Language and the Brain by Terrence W. Deacon. W. W. Norton, 1998.
69 I once believed any agent grounded in a sutably rich environment could learn to communicate with human language and take advantage of the knowledge available in human culture. I no longer think this is true. Words have meaning only in the context of other words. Facility with human extelligence would seem to require a remarkable alignment with the entities and processes that form the basis for grounding human experience.
70 The word "dual" in dual task learning is used in the technical sense it is applied in mathematical optimization theory.
71 Here is the transcript of an excerpt from this interview with Alan Baddley, that, together with the Annual Review of Psychology conversation mentioned in the main text provided the basis for my reconstruction of Baddley's commentary concerning the influence of Oberauer's research [188, 187]:
A crucial feature of Oberauer's model is the distinction he makes between declarative and procedural WM. Declarative WM is the aspect of WM of which we are aware, comprising most of the current work in the area, whereas procedural WM is concerned with the nondeclarative processes that underpin such operations: I assume that an example would be the process controlling subvocal rehearsal. However, he also considers a higher level of procedural control through what he refers to as the "bridge," as in the bridge of a ship, and what I myself would call the central executive. Consider the following: A participant in my experiment is instructed to press the red button when the number 1 appears, press the green for number 2, and neither for 3. We would expect this simple instruction to be followed throughout the experiment. It is as if some mini-program is set up and then runs, but we currently know very little about how this is achieved. I think the investigation of this aspect of procedural working memory, sometimes referred to as "task set," will become increasingly influential. (SOURCE)