Quiz 2 Review Solutions
August 1st, 2021
Written by Juliette Woodrow, Anna Mistele, John Dalloul, Brahm Capoor, and Nick Parlante
Grids
Jump Down
For this problem you will implement a new operation that works on one vertical column of squares in the grid. Every square in the grid is either a rock 'r', sand 's', or empty None. The jumpdown(grid, x, n) algorithm works as follows: The parameter x will be an in-bounds x value, indicating the column to work on. The parameter n will be 1 or more, the number of squares down to move each sand.
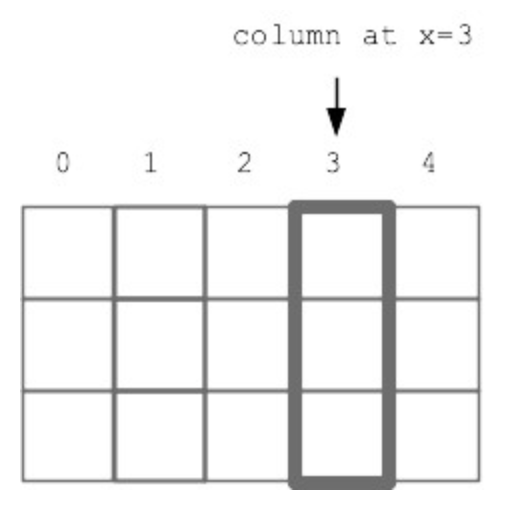
Look at every "candidate" square in the column, working from the bottom of the column to the top. If the candidate square contains sand, the sand will be moved. Its "destination" square is n squares straight down, (n=1 meaning the square immediately below). If the destination is empty, move the candidate sand there. If the destination is not empty or is out of bounds, then erase the candidate sand from the grid. Obstacles between the candidate sand and its destination do not matter - the sand jumps to its destination.
def jumpdown(grid, x, n):
"""
>>> grid = Grid.build([['s', 's'], ['r', None], [None, 'r']])
>>> jumpdown(grid, 0, 2)
[[None, 's'], ['r', None], ['s', 'r']]
>>> grid = Grid.build([['s', 's'], ['r', None], [None, 'r']])
>>> jumpdown(grid, 1, 2)
[['s', None], ['r', None], [None, 'r']]
>>> grid = Grid.build([['s', None], ['s', None], [None, None]])
>>> jumpdown(grid, 0, 1)
[[None, None], ['s', None], ['s', None]]
"""
for y in reversed(range(grid.height)):
if grid.get(x, y) == 's':
grid.set(x, y, None)
dest_y = y + n
if grid.in_bounds(x, dest_y):
if grid.get(x, dest_y) == None:
grid.set(x, dest_y, 's')
return grid
Yellowstone
There are two functions for this problem, and you can get full credit for each function independent of what you do on the other function. We have a Grid representing Yellowstone park, and every square is either a person 'p', a yelling person 'y', a bear 'b', or empty None.
- is_scared(grid, x, y): Given a grid and an in-bounds x,y, return True if there is a person or yelling person at that x,y, and there is a bear to the right of x,y or above x,y. Return False otherwise. (One could check more squares, but we are just checking two.)
- run_away(grid): This function implements the idea that when a person is scared of a bear they begin yelling and try to move one square left. Loop over the squares in the grid in the regular top to bottom, left to right order (this loop is provided in the starter code). For each square, if is_scared() is True, (a) set the person stored in the grid to 'y' (i.e. they are yelling). (b) Also, if there is an empty square to their left, then move the person to that square leaving their original square empty. You may call is_scared() even if you did not implement it.
def is_scared(grid, x , y):
if grid.get(x,y) == 'y' or grid.get(x, y) == 'p':
if grid.in_bounds(x + 1, y) and grid.get(x + 1, y) == 'b':
return True
if grid.in_bounds(x, y - 1) and grid.get(x, y - 1) == 'b':
return True
return False
def run_away(grid):
for y in range(grid.height):
for x in range(grid.width):
if is_scared(grid, x, y):
grid.set(x, y, 'y')
if grid.in_bounds(x - 1, y) and grid.get(x - 1, y) == None:
grid.set(x - 1, y, 'y')
grid.set(x, y, None)
return grid
Is Sandy Grid
Say we have the grid from the Sand homework, so every square is one of 's', 'r' or None. Write code for an is_sandy(grid, x, y) function as follows: Given a grid and an x,y which is guaranteed to be in-bounds. We'll say that x,y is "sandy" If there is sand either diagonally above-left, or diagonally below-right, or both from that x,y. Return True if the given x,y is sandy, False otherwise.
For example in the grid shown below, the two 'r' squares are the only ones where is_sandy() would return True.

def is_sandy(grid, x, y):
if grid.in_bounds(x - 1, y - 1) and grid.get(x - 1, y - 1) == 's':
return True
if grid.in_bounds(x + 1, y + 1) and grid.get(x + 1, y + 1) == 's':
return True
return False
String Parsing
Backward Hashtags
Yesterday, Juliette tried to teach her dad how to use hashtags so that he can sound hip when he texts, tweets, and emails. He wants a program to grab the first hashtag that he uses in a given line of a text, tweet, or email. The catch is that he does not fully understand how to use a hashtag and Juliette doesn't have the heart to correct him. He currently puts a hashtag at the end of a word and only wants them to contain alphabetic characters, numbers, and exclamation points (but no other punctuation). Implement a function, parse_backwards_hashtag(s), which takes in a string and returns Juliette's dad's attempt at a hashtag in that string. If there are no attempts at a hashtag in a given string, return None. A call to parse_backwards_hashtag('Check out how hipIam!!#.') would return 'hipIam#' and parse_backwards_hashtag(Tell the 106A students goodluck!# on their quiz') would return 'goodluck!#'.
def parse_backwards_hashtag(s):
hashtag = s.find('#')
if hashtag == -1:
return None
start = hashtag - 1
while start >= 0 and (s[start].isalnum() or s[start] == '!'):
start -= 1
tag = s[start+1:hashtag+1]
if len(tag) == 1:
return None
return tag
Find Alpha Piece
Implement a function, find_alpha_piece(s), which takes in a string s representing a string that has a code somewhere in it and returns the alphabetic piece of that code. If there is no code, return None. A code starts with some number (at least one) of alphabetic characters, followed by some number (at least one) of digits, and always ends in a hashtag. Some example codes would be: 'CS106#', 'aaB112#', 'xxxWxx0000#'. A call to find_alpha_piece('The code for your quiz is: CS106#') would return 'CS', a call to find_alpha_piece('aaB112# is the code to type in to prove you are not a robot') would return 'aaB', and a call to find_alpha_piece('Your 2 factor verification code is xxxWxx0000#. Please type it in in the next 5 seconds.') would return 'xxxWxx'. Strategy: rather than using two while loops from left to right, you will have to use two while loops that search from right to left starting at the character right before the hashtag.
def find_alpha_piece(s):
hashtag = s.find('#')
if hashtag == -1:
return None
# loop from right to left over the digits to find the end of the alpha chars
end_alpha = hashtag - 1
while end_alpha >= 0 and s[end_alpha].isdigit():
end_alpha -= 1
# loop from right to left over the alpha chars to find the beginning of the code
start_alpha = end_alpha
while start_alpha >= 0 and s[start_alpha].isalpha():
start_alpha -= 1
return s[start_alpha+1:end_alpha+1]
Liked Chars
Implement a function that is given a "liked" list of chars, with each char in lowercase form, e.g. ['a', 'b', 'c']. A liked word is a sequence of 1 or more liked chars. The chars making up the liked word may be in upper or lowercase form, e.g. 'cAB'. Your function should parse out and return the first liked word that is in the given string s. So for example if liked is ['a', 'b', 'c'], the string 'xxabad..A..BB' returns 'aba'. The starter code includes the first few lines of our standard parsing while-True loop.
liked = ['a', 'b', 'c']
'xxabad..A..BB' -> 'aba'
'^^AB.BBD.CD.' -> 'AB'
def parse_liked(s, liked):
start = 0
while start < len(s) and s[start].lower() not in liked:
start += 1
if start >= len(s):
return ''
end = start
while end < len(s) and s[end].lower() in liked:
end += 1
liked_word = s[start:end]
return liked_word
Strings and Lists
Censor Chats
A popular gaming site has decided to censor chat messages so that users cannot share personal information about themselves. They have created a tool that identifies personal information in each message and creates a censor pattern for each message, where a space represents a character that may be left alone and an "x" represents a character that should be censored in the final message with an "x". Now, they need a coder to create a function that takes a chat message and its corresponding censor pattern and outputs a safe message that has been censored to remove personal information.
Please design censor_chat(message, pattern) to read through the message string and replace characters with an "x" if the pattern string contains an "x" at the character's index. You can assume message and pattern will be the same length. For example, running the below program would print "My name is xxxxx, and I live in xxxxxxxxxxx!"
def main():
msg = "My name is Karel, and I live in Wilbur Hall!"
ptn = " xxxxx xxxxxxxxxxx "
print(censor_chat(msg, ptn))
def censor_chat(message, pattern):
"""
>>> msg = "My name is Karel, and I live in Wilbur Hall!"
>>> ptn = " xxxxx xxxxxxxxxxx "
>>> censor(msg, ptn)
"My name is xxxxx, and I live in xxxxxxxxxxx!"
"""
censored = ""
for i in range(len(message)):
if pattern[i] == "x":
censored += "x"
else:
censored += message[i]
return censored
Double Encrypt
This problem is similar to the Crypto homework with the simplification that the encryption is done entirely with lowercase chars. This "double" encryption uses two source lists, src1 and src2, and two slug lists, slug1 and slug2. All the lists contain chars and are the same length. Implement a function, encrypt_double(src1, slug1, src2, slug2, char), with the following algorithm: use the lowercase version of the input char, which may be uppercase. If the char is in src1, return the char at the corresponding index in slug1. If the char is in src2, return the char at the corresponding "reverse index" in slug2, e.g. like this for lists length 4:
index reverse index
0 3
1 2
2 1
3 0
If the char is not in src1 or src2, return the char unchanged. No char appears in both src1 and src2.
Double Encrypt Example (len 4)
src1 = ['a', 'b', 'c', 'd']
slug1 = ['s', 't', 'u', 'v']
src2 = ['e', 'f', 'g', 'h']
slug2 = ['w', 'x', 'y', 'z']
encrypt 'A' -> 's'
encrypt 'e' -> 'z'
encrypt 'f' -> 'y'
encrypt '$' -> '$'
def encrypt_double(src1, slug1, src2, slug2, char):
"""
>>> # Make len-4 lists for testing
>>> src1 = ['a', 'b', 'c', 'd']
>>> slug1 = ['s', 't', 'u', 'v']
>>> src2 = ['e', 'f', 'g', 'h']
>>> slug2 = ['w', 'x', 'y', 'z']
>>> encrypt_double(src1, slug1, src2, slug2, 'A')
's'
>>> encrypt_double(src1, slug1, src2, slug2, 'e')
'z'
>>> encrypt_double(src1, slug1, src2, slug2, 'f')
'y'
>>> encrypt_double(src1, slug1, src2, slug2, '$')
'$'
"""
lower = char.lower()
if lower in src1:
idx = src1.index(lower)
return slug1[idx]
if lower in src2:
idx = src2.index(lower)
rev = len(src2) - idx - 1
return slug2[rev]
return char
More Crypto
This problem is somewhat similar to the Crypto homework. This encryption will not make any adjustments for upper vs lower case.
Given source and slug lists of chars which are the same length. Compute and return the encrypted form of a char as follows: if the char appears in the source list, return the char at the next index in the slug list. So if the char is at index 2, its encrypted form is at index 3 in the slug list. Except, if the char is at the last source index, then its encrypted form is first char in the slug list. If the char does not appear in the source list, then return it unchanged.
Say we have these len-4 source and slug lists
source = ['a', 'b', 'c', 'd']
slug = ['w', 'x', 'y', 'z']
encryption:
'a' -> 'x'
'c' -> 'z'
'd' -> 'w'
def encrypt_char(source, slug, char):
if char in source:
idx = source.index(char)
if idx == len(source) - 1:
return slug[0]
return slug[idx + 1]
return char
Drawing
Fancy Lines with Margin
In this problem, impelement a function, draw(canvas, left, top, width, height, n), which takes in a left, top, width, height and number of lines n. The function should leave a 10-pixel high margin across the top and bottom of the figure without any drawing. Given int n which is 2 or more, draw n lines, as follows: The first line should begin at the left edge, 10 pixels from the top, and extend to the right edge, 10 pixels from the bottom. The last line should start at the left edge, 10 pixels from the bottom, and extend to the right edge 10 pixels from the top, with the other lines distributed proportionately.
Here is a picture showing the drawing for n=4 lines. The 4 lines to draw are shown as heavy black lines, with the outer edge of the figure and the margin areas outlined in gray.

def draw(canvas, x, y, width, height, n):
for i in range(n):
y_add = i/(n - 1) * (height - 20 - 1)
canvas.draw_line(x, y + 10 + y_add, x + width - 1, y + height - 1 - 10 - y_add)
Diagonal Lines
In this problem, impelement a function, draw(canvas, left, top, width, height, n), which takes in a left, top, width, height and number of lines n. Given int n which is 2 or more, draw n lines, each starting on the left edge and ending at the lower right corner of the figure. The first line should start at the upper left corner, the last line should start at the lower left corner, with the other lines distributed evenly.
Here is a picture showing the figure boundaries in gray with n=4 lines

def draw(canvas, x, y, width, height, n):
for i in range(n):
y_add = i/(n - 1) * (height - 1)
# Draw from points going down left side, all to lower-right corner
canvas.draw_line(x, y + y_add, x + width - 1, y + height - 1)
More Lines
As on the Quilt homework, the function takes in the (left, top, width, height) of a figure positioned on the canvas, and draw lines within that figure.
Draw a blue rectangle at the outer edge of the figure (this code is included).
Given int n which is 2 or more. Draw a series of lines distributed across the top edge of the figure, all terminating at the lower-right corner. The first line should start at the upper left corner, the last line should start at the upper right corner, with the other lines distributed evenly in between.

def draw(canvas, left, top, width, height, n):
canvas.draw_rect(left, top, width, height, color='lightblue')
for i in range(n):
x_add = i / (n - 1) * (width - 1)
# to bottom-right
canvas.draw_line(left + x_add, top, left + width - 1, top + height - 1)
Draw Grid
Working with data structures like Grids can get a little tricky when you can't visualize what you're working with! Let's code the visualize_grid(grid) function, that takes a Grid as input and draws the grid to the canvas. Each box in the grid should have height and width CELL_SIZE. We also want to print the contents of each grid cell as a string on the canvas! You can assume that the grid's contents are all strings.
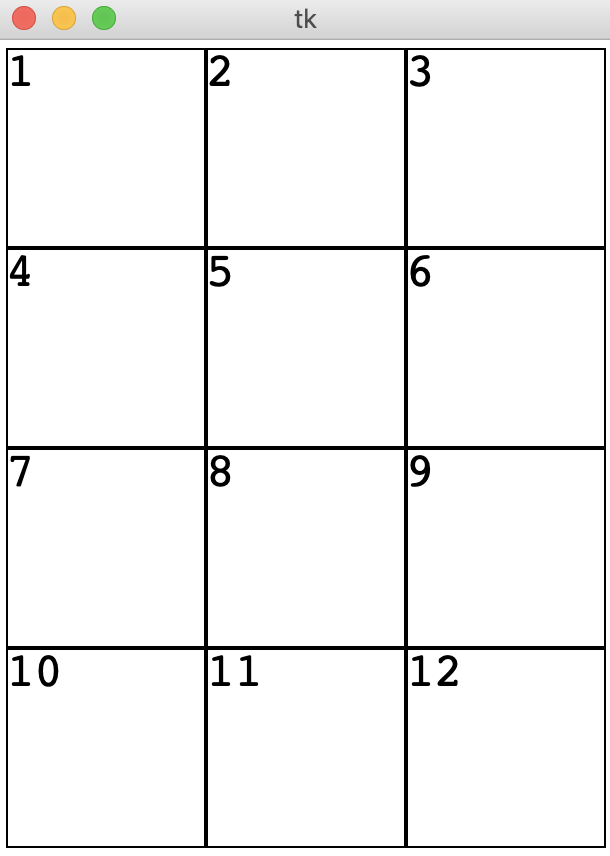
Below is an example call to visualize_grid(grid) on a grid with 4 rows and 3 columns.
grid = Grid.build([['1', '2', '3'], ['4', '5', '6'], ['7', '8', '9'], ['10', '11', '12']])
visualize_grid(grid)
CELL_SIZE = 100
def visualize_grid(grid):
"""
Working with data structures like Grids can get a little tricky when
you can't visualize what you're working with!
Let's code the visualize_grid(grid) function, that takes a Grid as input
and draws the grid to the canvas.
Each box in the grid should have height and width CELL_SIZE. We also want
to print the contents of each grid cell as a string on the canvas!
You can assume that the grid's contents are all strings.
>>> grid = Grid(3, 3)
>>> initialize_grid(grid, ['1', '2', '3'], ['4', '5', '6'], ['7', '8', '9'])
>>> visualize_grid(grid)
"""
canvas = DrawCanvas(grid.width*CELL_SIZE, grid.height*CELL_SIZE)
for row in range(grid.height):
for col in range(grid.width):
canvas.draw_rect(CELL_SIZE*col, CELL_SIZE*row, CELL_SIZE, CELL_SIZE)
canvas.draw_string(CELL_SIZE*col, CELL_SIZE*row, grid.get(col, row))
One Liners
- Given list of non-empty strs, write a map/lambda to form a list of the strings in upper case.
>>> strs = ['Rhyme', 'Donut', '3xx', 'Orange'] >>> list(map(lambda s: s.upper(), strs)) - Given list of (x, y) points, write a sorted/lambda expression to order these points in decreasing order by the sum of the x+y of each point.
>>> points = [(10, 0), (1, 3), (3, 2), (5, 4)] >>> sorted(points, key=lambda pt: pt[0] + pt[1], reverse=True)
# a. Given a list of numbers. # Call map() to produce a result where each # number is multiplied by -1. (or equivalently write a comprehension) >>> nums = [3, 0, -2, 5] # yields [-3, 0, 2, -5] # your expression:map(lambda x: x*(-1), nums)or[num*(-1) for num in nums]# b. Given a list of (x, y) "point" tuples where x and y are int values. # Call map() to produce a result where each (x, y) is replaced # by the sum of x and y. (or equivalently write a comprehension) >>> points = [(1, 2), (4, 4), (1, 3)] # yields [3, 8, 4] # your expression:map(lambda pt: pt[0]+pt[1], points)or[pt[0]+pt[1] for pt in points]# c. Given a list of (city-name, zip-code, current-temperature) tuples, like this >>> cities = [('modesto', 95351, 92), ('palo alto', 94301, 80), ...] # Call sorted() to produce a list of these tuples sorted in decreasing # order by temperature. # your expression:sorted(cities, key=lambda city: city[2], reverse=True)# d. Given a non-empty list of (flower-name, scent-score, color-score) tuples # like the following, scores are in the range 1 .. 10 >>> flowers = [('rose', 4, 8), ('orchid', 7, 2), ... ] # Call max() or min() to return the flower tuple with the highest scent score. # your expression:max(flowers, key=lambda flower: flower[1])
Dictionaries
Dict Problem from Winter Quarter Quiz #3
def send_score(recent, a, b):
if a in recent:
sent = recent[a]
if sent == b:
return 5
if sent in recent:
if recent[sent] == b:
return 1
return 0
Emails
def parse_hosts(addrs):
"""
>>> parse_hosts(['a@x', 'b@x', 'a@x'])
{'x': ['a', 'b']}
>>> parse_hosts(['a@x', 'b@x', 'a@y'])
{'x': ['a', 'b'], 'y': ['a']}
>>> parse_hosts(['a@x', 'bob@x', 'c@z'])
{'x': ['a', 'bob'], 'z': ['c']}
"""
hosts = {}
for addr in addrs:
at = addr.find('@')
user = addr[:at]
host = addr[at + 1:]
if host not in hosts:
hosts[host] = []
users = hosts[host] # style: decomp by var
if user not in users: # no duplicates
users.append(user)
return hosts
Sent Messages
def parse_sends(filename):
with open(filename, 'r') as f:
sends = {}
for line in f:
line = line.strip() # \n handling, not marking off for this
parts = line.split(',')
src = parts[0]
if src not in sends:
sends[src] = {}
nested = sends[src] # decomp by var
for dst in parts[1:]:
if dst not in nested:
nested[dst] = 0
nested[dst] += 1
return sends
Common Senders
def commons(sends, srca, srcb):
countsa = sends[srca] # Given that srca/b are in sends
countsb = sends[srcb] # so don't need "in" check first.
result = []
for dest in countsa.keys():
# is it in b too? "in" handy here
if dest in countsb:
result.append(dest)
return result
Make County
def make_county(words):
"""
Given a list of non-empty words, produce 'county' dict
where each first-char-of-word seen is a key, and its value
is a count dict of words starting with that char.
So ['aaa', 'abb', 'aaa'] yields {'a': {'aaa': 2, 'abb': 1}}
"""
county = {}
for word in words:
ch = word[0]
if ch not in county:
county[ch] = {}
inner = county[ch]
if not word in inner:
inner[word] = 0
inner[word] += 1
return county
Recipes
def is_sub_list(curr_ingredients, recipe_ingredients):
for ingredient in recipe_ingredients:
if ingredient not in curr_ingredients:
return False
return True
def find_recipes(curr_ingredients, recipe_book):
possible_recipes = []
for recipe in recipe_book:
recipe_ingredients = recipe_book[recipe]
if is_sub_list(curr_ingredients, recipe_ingredients):
possible_recipes.append(recipe)
return possible_recipes
Building a Glossary
def make_glossary(filename):
glossary = {}
with open(filename, 'r') as f:
line_num = 0
for line in f:
line = line.strip()
for word in line.split():
if word not in glossary:
glossary[word] = []
glossary[word].append((line_num, line))
line_num += 1
return glossary
Finding Grandparents
SAMPLE_INPUT = {
'Khaled': ['Chibundu', 'Jesmyn'],
'Daniel': ['Khaled', 'Eve'],
'Jesmyn': ['Frank'],
'Eve': ['Grace']
}
def add_grandchildren(grandparents_dictionary, grandparent, new_grandchildren):
if grandparent not in grandparents_dictionary:
# if we haven't seen this grandparent before, add them to the dictionary
grandparents_dictionary[grandparent] = []
# add the new grandchildren to the grandparent's list of
# grandchildren
current_grandchildren = grandparents_dictionary[grandparent]
current_grandchildren += new_grandchildren
def find_grandchildren(parents_dictionary):
"""
>>> find_grandchildren(SAMPLE_INPUT)
{'Khaled': ['Frank'], 'Daniel': ['Chibundu', 'Jesmyn', 'Grace']}
"""
grandparents_dictionary = {}
for parent in parents_dictionary:
children = parents_dictionary[parent]
for child in children:
if child in parents_dictionary: # check if the child is a parent themselves
grandchildren = parents_dictionary[child]
add_grandchildren(grandparents_dictionary,
parent, grandchildren)
return grandparents_dictionary
Capstone CS106A Problems
Dict File problem from Winter Quarter Quiz #3
def read_posts(filename):
posts = {}
with open(filename) as f:
for line in f:
# could do .strip(), not marking off
words = line.split('^')
celeb = words[0]
for chan in words[1:]:
if chan not in posts:
posts[chan] = []
inner = posts[chan]
if celeb not in inner:
inner.append(celeb)
return posts
Prime Files
def prime_file(filename):
"""
The given file contains text data on each line as follows.
Each line is made of a mixture of non-empty alphabetic words
and non-negative ints, all separated by colons. The numbers can be distinguished
since their first char is a digit. Lines like this:
aaa:123:420:xyz:xxx:44:zz:a
The first element is the "prime" for that line, and is always alphabetic.
Read through all the lines and build a dict with a key for each prime,
and its value is a list of all the int number values from all the lines
with that prime.
Add every number to the list, even if it is a duplicate.
When all the data is loaded, print the primes in alphabetical order
1 per line, each followed by its sorted list of numbers, like this
aaa [44, 123, 123, 125, 420, 693]
bbb [16, 23, 101, 101]
"""
primes = {}
with open(filename) as f:
for line in f:
parts = line.split(':')
prime = parts[0]
# pick out which parts are ints - comprehension is cute here
# or could do this as a regular old for-loop with an append
# inside is fine and full credit.
nums = [int(part) for part in parts if part[0].isdigit()]
if not prime in primes:
primes[prime] = []
primes[prime].extend(nums)
# now output
for prime in sorted(primes.keys()):
print(prime, sorted(primes[prime]))
Dict File
def count_zips(filename):
states = {}
with open(filename) as f:
for line in f:
pass
words = line.split(',')
state = words[0]
if state not in states:
states[state] = {}
counts = states[state]
for word in words[1:]:
zip = word[:5]
if zip not in counts:
counts[zip] = 0
counts[zip] += 1
for state in sorted(states.keys()):
print(state)
counts = states[state]
for zip in sorted(counts.keys()):
print(zip, counts[zip])
Lightning
def parse_lightning(filename):
states = {}
with open(filename) as f:
for line in f:
pass
words = line.split(',')
i_state = len(words) - 1
state = words[i_state].strip() # not grading off: remove \n
if state not in states:
states[state] = []
nums = states[state] # decomp by var
for numstr in words[:i_state]: # omit last elem
nums.append(int(numstr))
for state in sorted(states.keys()):
print(state, states[state], sum(states[state]))