Current Projects
Sparse Spatiotemporal Codes
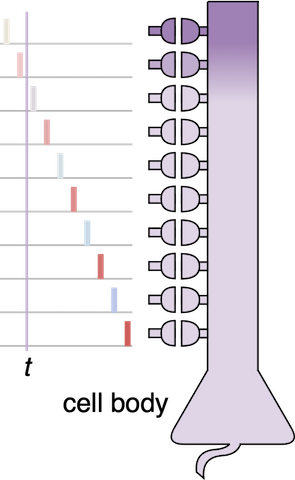
Artificial intelligence benefited from shrinking transistors and connecting them densely in two dimensions to reduce the energy cost of calculating. Now the energy cost of signaling greatly exceeds that of calculating, reducing the benefits of additional miniaturization. Signaling distance is now being shortened by stacking circuits, but stacking reduces surface area for dissipating heat, forcing a 3D processor to operate serially, rather than in parallel. A fundamental solution would exchange binary numbers, whereby each signal from a pair of units encodes one bit, for n-ary numbers, whereby each signal from an entire layer of, say, 1,024 units encodes 10 bits. These sparser and richer signals would require exchanging Boolean logic for operators inseparable in time and space. Advances in cortical physiology suggest that this inseparability could be achieved with dendrite-like detectors that weight an input based on when it occurs and where it is received. This could allow a silicon brain to scale like a biological brain in energy and heat––linearly with the number of neurons––and thus be thermally viable in 3D. Join this project.
Parallel Computing in 3D
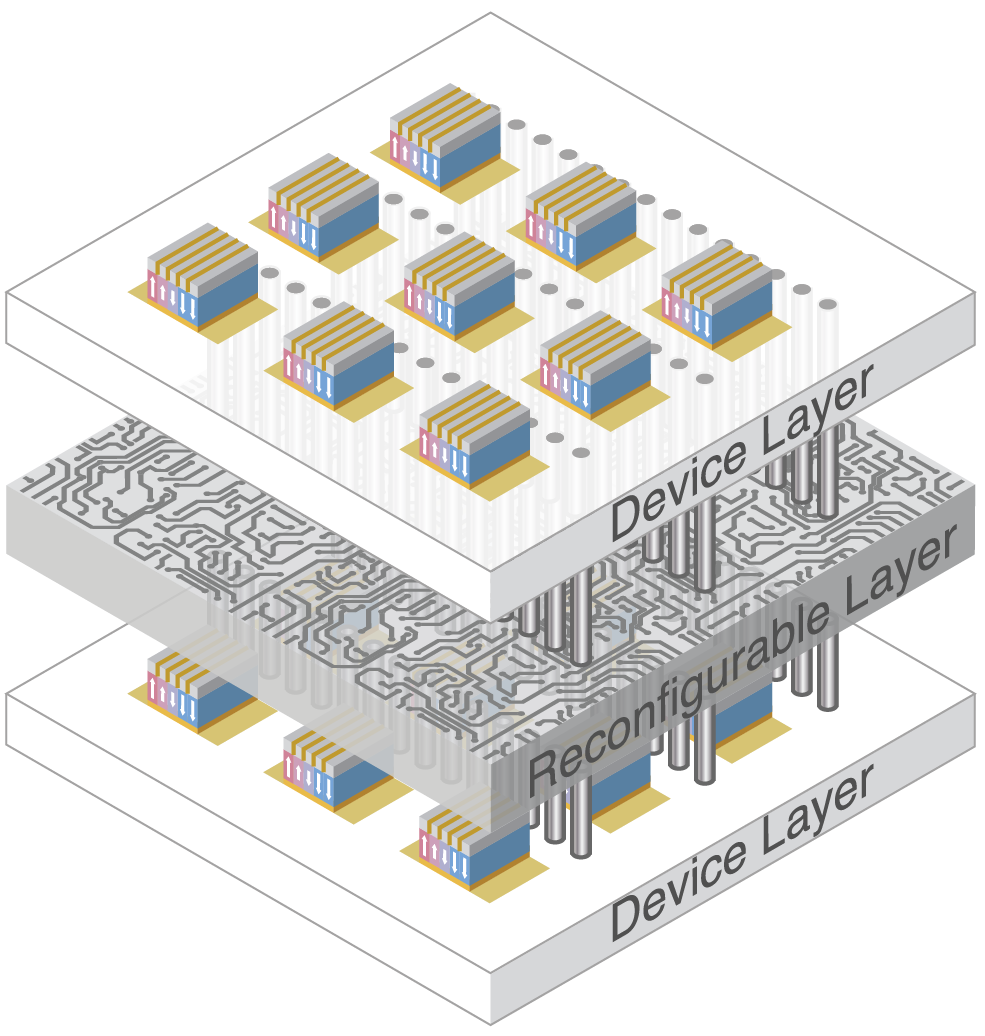
A deep net infers a response to a stimulus by multiplying a vector that comprises activations of all units in a layer by a matrix that comprises weights of all connections from that layer to the next layer, repeating these calculations for each tier of connections. Communicating weights to and fro, between memory and processor, consumes by far the most energy. This weight movement is eliminated by calculating a vector-matrix product inside the memory array. A vector represented as voltages on word lines is multiplied by a matrix represented as charge in bit cells to yield a vector represented as currents on bit lines. Now skip, residual, or feedback connections that route signals to non-sequential crossbars dominate energy consumption. Stacking the crossbars shortens these interconnects and thereby reduces energy use, but surface area drops even more. To avoid overheating, stacked crossbars operate sequentially, but that throttles computation. Moving away from learning with synapses to learning with dendrites transcends the 3D thermal constraint. Synaptic inputs are not weighted precisely but rather ordered meticulously along a short stretch of dendrite. Emulating this stretch in a ferroelectric device and fabricating these nanodendrites in 3D could run AI not with megawatts in the cloud but rather with watts on a smartphone. Join this project.

Retinomorphic Vision Sensors
Retinomorphic cameras preprocess their photodetectors’ signals to produce spatiotemporally sparse “spikes”. Event-based—as opposed to frame-based—readout translates this lower data-rate into a higher (equivalent) frame-rate and a shorter latency. In the row-column architecture that event-based vision sensors currently use, however, latency and jitter (its standard deviation) increase nearly a thousandfold when spike rate exceeds row-readout rate (approx. 6M eps). This shortcoming may be rectified by taking advantage of two-chip stacking in state-of-the-art CMOS image sensor fabrication processes: Photodetectors reside on one chip and a metal bump connects each photosignal to another chip. That allows event-based readout’s asynchronous logic circuitry to be moved from the periphery into the array without sacrificing the fill-factor. This network-on-a-chip, laid out in a 2D fractal pattern (H-tree), reduces latency and jitter by three to four orders-of-magnitude—they become significant only when spike rate approaches output bandwidth (approx. 1G eps). Join this project.