The Myhill-Nerode theorem is our go-to tool for proving that languages are not regular. This guide recaps the major definitions needed for the Myhill-Nerode theorem, then describes strategies for finding infinite distinguishing sets.
Core Definitions
Nonregular Languages
The regular languages are the languages for which you can either
- build a DFA that accepts every string in the language and rejects everything else, or
- build an NFA that accepts every string in the language and rejects everything else, or
- write a regular expression that matches all the strings in the language and nothing else.
On the other hand, a nonregular language is one where you can't do any of the above. You can't build a DFA for it, or design an NFA for it, or write a regex for it.
Distinguishability
At its core, the Myhill-Nerode theorem revolves around the notion of distinguishability. Suppose you have a language $L$ over some alphabet $\Sigma\text.$ Two strings $x$ and $y$ are called distinguishable relative to $L$ when there is a string $w$ such that exactly one of $xw$ and $yw$ is in $L\text.$
I like to visualize distinguishable strings in the following manner. To show that $x$ and $y$ are distinguishable relative to some language, draw the strings $x$ and $y$ over one another with a large horizontal line to their right. Your goal is to come up with a string $w$ that you can put to the right of the line so that either (1) $xw \in L$ and $yw \notin L$ or (2) $xw \notin L$ and $yw \in L\text.$
Let's make this concrete. Consider the language $L = \set{ w \in \mathtt{\set{a, b}}^\star \suchthat \abs{w} = 4 }\text.$ This is the language of all strings whose length is exactly four. We want to show that the strings aba and bb are distinguishable relative to $L\text.$ We'll start off by writing aba on top of bb with a line to their right.
We need to pick a single string we can put to the right of the line that puts one of the two resulting strings in $L$ and the other outside of $L\text.$ Since $L$ is the language of all strings whose length is exactly four, we need a string on the right so that, of the two resulting strings, exactly one of them has length four. There are many ways to do this; here's two. I've added colors to the different strings here so that it's a bit easier to discuss them later:
\[\begin{array}{r|l} {\color{teal} \mathtt{aba}} & {\color{purple} \mathtt{a}} \\ {\color{olive} \mathtt{bb}} & {\color{purple} \mathtt{a}} \end{array} \qquad \qquad \begin{array}{r|l} {\color{teal} \mathtt{aba}} & {\color{purple} \mathtt{bb}} \\ {\color{olive} \mathtt{bb}} & {\color{purple} \mathtt{bb}} \end{array}\]In the example on the left, we end up with abaa (length four) and bba (length three), so only one string is in $L\text.$ In the second example, the strings are ababb (length five) and bbbb (length four).
You can think of this way of thinking about distinguishability as a "distinguishability game." If you want to know whether two strings are distinguishable relative to a language $L\text,$ write those strings out as we did above. You win the game if you can find a suffix you can tack on to both strings that puts one in $L$ and keeps the other out of $L\text.$ In that case, the strings are distinguishable relative to $L\text.$ You lose the game if, no matter what string you tack onto the end of both $x$ and $y\text,$ you end up with both strings staying in $L$ or staying out of $L\text.$ In that case, the strings are indistinguishable relative to $L\text.$
There are no restrictions on what kinds of strings you're allowed to append to $x$ and $y\text.$ The string $w$ you append can be very short (even as short as $\varepsilon\text)$ or very long.
Distinguishing Sets
If $L$ is a language over $\Sigma\text,$ a distinguishing set for $L$ is a set $S \subseteq \Sigma^\star$ where the following is true:
\[\forall x \in S. \forall y \in S. (x \ne y \ \to \ x \not\equiv_L y)\text.\]Let's clarify what all the pieces here mean. We begin with some language $L$ over an alphabet $\Sigma\text.$ A distinguishing set $S$ for $L$ has to be a subset of $\Sigma^\star\text,$ meaning that $S$ itself is going to be a set of strings. (We would be correct in calling it a language over $\Sigma$ because everything in $S$ is a string over $\Sigma\text,$ but for whatever reason we generally don't do that here.) Notice that $S$ is just required to be a subset of $\Sigma^\star$ and that there's no requirement that $S$ is a subset of $L\text.$
The key property about $S$ is the one given in the FOL notation above. You can read that formula as saying "for any pair of two different strings $x$ and $y$ in $S\text,$ the strings $x$ and $y$ are distinguishable relative to $L\text.$" Stated differently, if you pick any two distinct strings out of $S$ and play the distinguishability game with them, you're guaranteed that you can always win.
Let's see an example. In class, we looked at the language $E = \set{ \mathtt{a}^n\mathtt{b}^n \suchthat n \in \naturals }$ over the alphabet $\Sigma = \mathtt{\set{a, b}}$ and saw that $S = \set{\mathtt{a}^n \suchthat n \in \naturals}$ is a distinguishing set for $E\text.$ Let's quickly check that is indeed the case.
First, we have to see whether $S \subseteq \Sigma^\star\text.$ Every string in $S$ is made purely of a's, and $\mathtt{a} \in \Sigma\text,$ so, yep, it's the case that $S \subseteq \Sigma^\star\text.$ Next, we have to check whether it's really the case that, given any two arbitrary distinct (different) strings chosen out of $S\text,$ those strings are distinguishable relative to $E\text.$ To do that, let's try out a few examples. Let's pick $\mathtt{a}^{137}$ and $\mathtt{a}^{103}\text.$ To see if they're distinguishable relative to $E\text,$ let's play the distinguishability game! We write them out like this:
Now, we need to figure out what goes on the right. We need to tack something onto the end of both strings so that one ends up in the language $E$ and one stays outside. Every string in $E$ needs to consist of some number of a's followed by an equal number of b's. The two strings we have here already consist of some number of a's, and so a reasonable guess would be to tack on some number of b's to the end of each. We should pick the number of b's in a way that matches one of the number of a's, since otherwise neither string would consist of a number of a's followed by an equal number of b's. Here's two ways we could do this:
In each case, one of the strings ends up in $E\text,$ and the other doesn't.
Of course, we've just checked one pair of strings in $S$ here, and the definition of a distinguishing set says that every pair of distinct strings must be distinguishable. But the above exercise was still worthwhile because it nicely generalizes. Now suppose we pick two strings $\mathtt{a}^m$ and $\mathtt{a}^n$ out of $S\text,$ where $m \ne n\text.$ (We don't need to worry about the case where $m = n$ because the strings would be the same in that case, and the definition of distinguishability promises that we only need to look at different strings.) We can set up our distinguishability game like this:
\[\begin{array}{r|l} \mathtt{a}^{m} & \\ \mathtt{a}^{n} & \end{array}\]And, by generalizing how we won this game in the concrete case, we see two ways to win:
\[\begin{array}{r|l} \mathtt{a}^{m} & \mathtt{b}^{m} \\ \mathtt{a}^{n} & \mathtt{b}^{m} \end{array} \qquad \qquad \begin{array}{r|l} \mathtt{a}^{m} & \mathtt{b}^{n} \\ \mathtt{a}^{n} & \mathtt{b}^{n} \end{array}\]This argument explains why we $S$ is indeed a distinguishing set for $E\text.$
Returning to an earlier point, notice that $S \not\subseteq E\text.$ For example, we have $\mathtt{a} \in S$ even though $\mathtt{a} \notin E\text.$ And that's perfectly fine: nothing in the definition of a distinguishing set says that a distinguishing set for a language must be a subset of the language.
One other point worth mentioning before we move on: notice that to show that $S$ is a distinguishing set, we need to prove that for every pair of distinct strings $x$ and $y$ in $S\text,$ there's some string $w$ you can tack onto the end of $x$ and $y$ so that exactly one of $xw$ and $yw$ belongs to $L\text.$ The quantifier ordering here is $\forall x. \forall y. \exists w\text{.,}$ meaning that we pick $x$ and $y$ arbitrarily first, then get to choose what $w$ is. And, importantly, because of this quantifier ordering, the choice of $w$ can depend on what $x$ and $y$ are. You are not required to pick some $w$ that works for every possible choice of $x$ and $y\text,$ and indeed in most cases it won't be possible to do that.
Infinite Distinguishing Sets
An infinite distinguishing set is simply a distinguishing set that contains infinitely many strings. Or, stated differently, $S$ is an infinite distinguishing set for $L\text,$ it means that $\abs{S}$ is infinite and that $S$ is a distinguishing set for $L\text.$
In the preceding section, we say that $S = \set{\mathtt{a}^n \suchthat n \in \naturals}$ is a distinguishing set for $E = \set{\mathtt{a}^n\mathtt{b}^n \suchthat n \in \naturals}\text.$ It's also an infinite distinguishing set: the set $S$ contains infinitely many strings (specifically, $\mathtt{a}^0\text,$ $\mathtt{a}^1\text,$ $\mathtt{a}^2\text,$ etc.).
Not all distinguishing sets are infinite. Later in this guide, we'll see that finite distinguishing sets can still be useful as a stepping stone toward finding infinite distinguishing sets. If we have enough time this quarter, you might see other applications of finite distinguishing sets either in lecture or on the problem sets. They're certainly useful in Theoryland!
The Myhill-Nerode Theorem
The Myhill-Nerode theorem says the following:
Theorem: Let $L$ be a language over $\Sigma\text.$ If $L$ has an infinite distinguishing set, then $L$ is not regular.
The Myhill-Nerode theorem is an incredibly powerful tool. If you want to prove that a language is not regular, your first instinct should be to try to use this theorem. Stated differently, if you want to prove a language is nonregular, you should start off by searching for an infinite distinguishing set for that language.
For example, suppose you want to prove that the language $E = \set{\mathtt{a}^n\mathtt{b}^n \suchthat n \in \naturals }$ is not regular. One way to do this would be to come up with the set $S = \set{\mathtt{a}^n \suchthat n \in \naturals}$ and prove that it is indeed an infinite distinguishing set for $E\text.$ Once you've done that, you can immediately apply the Myhill-Nerode theorem to conclude that $E$ is not regular.
In order to do this, you need to be able to find infinite distinguishing sets for a given language. That's a skill that you can improve over time, and it's the focus of the rest of this guide.
Finding Distinguishing Sets
To use the Myhill-Nerode theorem to prove that a language $L$ is not regular, you need to find an infinite distinguishing set $S$ for $L\text.$ There are a lot of ways you can come up with these sets. Some degree of trial-and-error is likely required, but you can be more principled than just guessing random sets and hoping they work. This section introduces some useful techniques, each of which is accompanied by a worked example that shows the principle in action.
Start Small
Your goal is to come up with an infinite distinguishing set - a set of infinitely many strings where any two different strings in the set are distinguishable. Finding infinitely many strings is going to be tough if you can't even find a single pair of distinguishable strings. So one way to approach finding an infinite distinguishing set is to start off with two distinguishable strings, then find a third string distinguishable from each of those, then a fourth string distinguishable from the three others, etc. until you find a pattern that generalizes.
Let's see an example of this. Let $\Sigma = \set{\mathtt{a}, \ge}$ and consider this language $L\text:$
\[L = \set{\mathtt{a}^m \ge \mathtt{a}^n \suchthat m, n \in \naturals \land m \ge n }\text.\]This language consists of strings made up of two groups of a's, with a $\ge$ symbol separating them, such that there are at least as many a's in the first group as there are in the second. So, for example, the string $\mathtt{aaaa \ge aa} \in L$ and $\mathtt{aaa \ge aaa} \in L\text,$ as are $\mathtt{aa \ge}$ and $\ge$ (in those cases, we have groups of zero a's, which are fine). However, the string $\mathtt{aa \ge aaa}$ is not in $L$ (there's more a's in the second group than the first), and the string $\mathtt{aa \ge aa \ge aa}$ is not in $L$ (strings in $L$ must specifically consist of some number of a's, then a single $\ge\text,$ and then a second group of a's). It turns out that this language $L$ is not regular, and our goal is going to be to prove this.
Let's begin by looking for two strings that are distinguishable relative to this language $L\text.$ To do this, let's pick two strings or more less at random and see if they're distinguishable. Let's begin with $\mathtt{aaaa} \ge \mathtt{aa}$ and $\mathtt{aaa} \ge \mathtt{a}\text.$ Are these distinguishable relative to one another? To find out, let's set up our distinguishability game:
\[\begin{array}{r|l} \mathtt{aaaa \ge aa} & \\ \mathtt{aaa \ge a} & \end{array}\]What could we tack onto the ends of these strings? If we append a $\ge$ to both strings, then neither ends up in the language; every string in $L$ has exactly one $\ge$ symbol in it. If we append a to both strings, then they each stay inside the language. The first one becomes $\mathtt{aaaa \ge aaa}$ and the second one is $\mathtt{aaa \ge aa}\text,$ both of which are in $L\text.$ If we append aa to both strings, they're both still in the language. If we append aaa, then they're both not in the language - the first one becomes $\mathtt{aaaa \ge aaaaa}$ and the second one becomes $\mathtt{aaa \ge aaaa}\text.$ And, with a little thought, we can see that appending any more a's than this will make both strings not be in the language. So it looks like we just picked two strings that actually were indistinguishable relative to $L\text.$ Oops.
But not to worry! We tried a thing and it didn't work, so let's reflect on why it didn't work and try something else. Looking at the two strings we picked, we can notice that, in retrospect, we accidentally picked two strings where the relative numbers of a's on the sides of the $\ge$ were the same. That's why, regardless of how many a's we tacked on the end, we ended up with both strings in $L$ or both strings not in $L\text.$
With that in mind, let's try picking two other, similar strings where the relative difference in a's in the two strings isn't the same. Let's try $\mathtt{aaaa \ge aa}$ and $\mathtt{aaaa \ge aaa}\text.$ Are these distinguishable? Once again, let's set up our game:
As before, we can't tack $\ge$ onto the ends of these strings, since they already have their needed $\ge$'s. But maybe tacking on some number of a's will do it? With a little thought, we can come up with this:
Success! These strings are distinguishable. That's good progress.
We've just found two distinguishable strings. Can we find a third? The two strings we have above have four a's on one side of the $\ge$ and a smaller number of a's on the other. Maybe we could find another string of that form? With a little experimentation, we'll find that any other number of a's in the right-hand group will work. So let's add to our two other strings a third string, say, $\mathtt{aaaa \ge a}\text.$ We can see that it's distinguishable from the other two strings:
Okay, we now have three distinguishable strings. Could we find a fourth? Sure - $\mathtt{aaaa \ge aaaa}$ works. Here's how to distinguish it from the three other strings:
\[\begin{array}{r|l} \mathtt{aaaa \ge aaa} & \mathtt{a} \\ \mathtt{aaaa \ge aaaa} & \mathtt{a} \end{array} \qquad \begin{array}{r|l} \mathtt{aaaa \ge aa} & \mathtt{a} \\ \mathtt{aaaa \ge aaaa} & \mathtt{a} \end{array} \qquad \begin{array}{r|l} \mathtt{aaaa \ge a} & \mathtt{a} \\ \mathtt{aaaa \ge aaaa} & \mathtt{a} \end{array}\]It's not too hard to see that we could also toss in $\mathtt{aaaa \ge }$ into the mix. That would be distinguishable from the others as well. That gives us five distinguishable strings. And it turns out that $\mathtt{aaaa \ge aaaaa}$ is also distinguishable from all the other strings in the group. Take a second to explore - do you see why?
So we now have this group of distinguishable strings:
\[\mathtt{aaaa\ge \quad aaaa\ge a \quad aaaa\ge aa \quad aaaa\ge aaa \quad aaaa\ge aaaa \quad aaaa \ge aaaaa}\]All of these strings start with four a's and a $\ge$ sign. Unfortunately, we can't add any more strings of that form into this set to get a bigger one. For example, $\mathtt{aaaa} \ge \mathtt{aaaaaa}$ is indistinguishable from $\mathtt{aaaa \ge aaaaa}\text.$ No matter what we tack onto the ends of both of those strings, we end up with something not in the language $L\text.$
But that doesn't mean we've hit a dead-end. We ended up finding these strings by looking for strings with different imbalances between the number of a's to the left and to the right of the $\ge$ sign. The fact that we picked strings that all start with aaaa is an artifact of our original exploration rather than something deep and intrinsic to the strings we picked. If we step away from the aaaa business and instead focus on finding strings with different imbalances, perhaps we'll have some more luck.
For example, let's look at our string $\mathtt{aaaa \ge aaaa}\text.$ This is a string where there's an imbalance of 0 between the left and right sides. Lots of strings have an imbalance of zero; $\mathtt{aaa \ge aaa}$ also works, as does $\mathtt{aa \ge aa}\text.$ Is there a "simplest" string showing an imbalance like this? The answer is yes - it would be $\mathtt{a}^0 \ge \mathtt{a}^0\text,$ which is just a fancy way of writing out the string $\ge\text.$
What about strings with an imbalance of 1 between the left and right groups? The simplest such string here would be $\mathtt{a}^1 \ge \mathtt{a}^0\text,$ which is the string $\mathtt{a \ge }\text.$ And notice that $\mathtt{a}^0 \ge \mathtt{a}^0$ is distinguishable from $\mathtt{a}^1 \ge \mathtt{a}^0\text,$ since we can tack $\mathtt{a}$ onto the end of both.
What about a string with an imbalance of 2? We could pick $\mathtt{a}^2 \ge \mathtt{a}^0\text,$ or, more compactly, $\mathtt{aa \ge }\text.$ That string is distinguishable from the two previous strings - do you see why?
If we look at these strings, we can see that there is a nice pattern that will let us find an infinite distinguishing set. Simply look at all strings of the form $\mathtt{a}^n \ge$ for different values of $n\text.$ We can use that to define our distinguishing set:
\[S = \set{\mathtt{a}^n \ge \suchthat n \in \naturals}\text.\]The intuition for why this works is that given any two strings with different imbalances, we can tack on a number of a's to both strings that will break the inequality in one of the two strings but not in the other.
I wanted to walk you through the process of getting here because I think it's helpful to see how things like this actually get worked out. We didn't come up with this set by starting at the definition of $L\text,$ thinking really hard, and immediately coming up with it. Instead, we started with some small strings, found a modest-sized distinguishing set, realized that it wouldn't generalize to infinitely many strings, saw a different pattern that did generalize, and eventually used that pattern to make our infinite distinguishing set. When you're first starting off with Myhill-Nerode arguments, it's common to need to do this sort of trial and error! Over time you'll start picking up on patterns that will let you guess more effectively on unknown problems, but even in those cases usually some experimentation is required.
Now that we have our distinguishing set, how might we formally prove that $L$ is nonregular? Essentially, we just need to argue why $S$ is an infinite distinguishing set, then cite the Myhill-Nerode theorem. Here's one way to do that:
Theorem: $L$ is nonregular.
Proof: Consider the set $S = \set{\mathtt{a}^n \ge \suchthat n \in \naturals }\text.$ We claim that $S$ is an infinite distinguishing set for $L\text.$
To see that $S$ is infinite, note that $S$ contains one string for each natural number.
To see that $S$ is a distinguishing set, pick any two distinct strings $\mathtt{a}^m \ge\, \mathtt{a}^n \ge \in S\text.$ We need to show that $\mathtt{a}^m \ge \not\equiv_L \mathtt{a}^n \ge\text.$ To see this, assume, without loss of generality, that $m \gt n\text.$ Then we see that $\mathtt{a}^m \ge \mathtt{a}^m \in L$ but that $\mathtt{a}^n \ge \mathtt{a}^m \notin L$ (since $n \lt m\text{),}$ so $\mathtt{a}^m \ge \not\equiv_L \mathtt{a}^n \ge\text,$ as required.
Since $S$ is an infinite distinguishing set for $L\text,$ by the Myhill-Nerode theorem $L$ is not regular. $\qed$
Notice how this proof argues that $S$ is infinite and explains why any two strings in $S$ are distinguishable relative to $L\text.$ Commonly, the justification as to why $S$ is infinite will be relatively straightforward, as is the case here. The justification that $S$ is a distinguishing set, though, may be more elaborate. Here, we pick two arbitrary strings in $S$ and then find a concrete string we can tack onto the end of those strings to distinguish them.
You might notice that the strings we picked initially all happened to be in $L\text,$ and our final distinguishing set $S$ is a subset of $L\text.$ That is purely a coincidence. There is nothing requiring that we do this. In fact, in general, you won't necessarily be able to find a distinguishing set for a language that is a subset of that language. The next section talks about an example of this and what to do in the (very common) case where that happens.
What "Must" You Remember?
Let's work through another example. Here, we'll let $\Sigma = \mathtt{\set{a, b}}$ and will consider this language $L\text:$
\[\set{ w \in \Sigma^\star \suchthat w \text{ has the same number of } \mathtt{a} \text{'s and } \mathtt{b} \text{'s}}\text.\]We're going to show that this language is not regular, and we'll do so by finding an infinite distingushing set for it.
Let's begin by looking for any pair of distinguishable strings. In the previous section, we picked some sample strings from the language as our starting point. Let's try that here to see what happens. How about, say, abba and aaabbb? Are they distinguishable relative to $L\text?$ Alas, no. The string abba has two a's and two b's, and aaabbb has three of each. Whatever string we tack onto the end of each will increase the relative counts of a's and b's the same way. And "relative" is the key word here - the language $L$ doesn't care about precisely how many a's and b's there are in the string, but does care whether they're the same. So if each string starts with the same relative frequencies of a's and b's, and we append the same blend of characters to each, then the two strings will end up with the same relative frequencies as one another. Thus either both will be in $L\text,$ or both won't be in $L\text.$
This immediately signals something to us - we're going to have to look for strings that are not in $L$ if we're going to find an infinite distinguishing set.
This is surprisingly common. In fact, that's the case for the very first nonregular language we looked at, $E = \set{\mathtt{a}^n\mathtt{b}^n \suchthat n \in \naturals }\text.$ The distinguishing set we came up with, $S = \set{\mathtt{a}^n \suchthat n \in \naturals}\text,$ is not a subset of $E\text.$ It only contains one element that is also in $E\text,$ and that's $\mathtt{a}^0 = \varepsilon = \mathtt{a}^0\mathtt{b}^0\text,$ which is essentially only in $E$ by pure coincidence.
If you have to pick strings not in $L$ to build a distinguishing set, where should you start? You could, if you wanted to, try random strings to see what works and what doesn't, as we did in the previous example, and often times that will lead you in a promising direction. But it would be nicer to have something a bit more principled serving as a guide.
Here's a very useful technique for building distinguishing sets. Regular languages are those for which you can build a DFA. A DFA reads the characters of an input string from left to right, then, only at the end, decides whether to accept or reject. Now, a DFA only has finitely many states (the "F" in "DFA" stands for "finite"). However, there are infinitely many possible strings you can feed into a DFA. This means that as the DFA is processing the string it sees from left to right, it can't "remember" what string it's seen. Its only memory is which state it happens to be in, and there's more strings than states. Therefore, the DFA has to operate by "summarizing" the string it's seen thus far and just remembering that summary.
For example, take a look at the DFA we built in lecture that checks whether a string contains aa as a substring. It has three states:
- $q_0\text,$ which holds strings where we haven't seen
aayet and where the most recent character isn'ta. - $q_1\text,$ which holds strings where we haven't seen
aabut have just seen ana. - $q_2\text,$ which holds strings containing
aaas a substring.
As the DFA operates, scanning the characters of the string from left to right, it essentially "summarizes" or "remembers" only one fact about the string it's seen thus far: which of the three cases above apply to it.
You can make a similar sort of argument about any DFA. Each state corresponds to some fact that must be "remembered" about the string that's been seen thus far. What that information is will depend on the choice of the language and the way the DFA is built.
Now, let's return to our language $L$ from above, which is reprinted here:
\[\set{ w \in \Sigma^\star \suchthat w \text{ has the same number of } \mathtt{a} \text{'s and } \mathtt{b} \text{'s}}\text.\]Our goal is to show that this language isn't regular, which means that we need to show there's no DFA for it. But for the moment, let's pretend we didn't know that no DFA exists for $L$ and instead think about how we might try to build such a DFA. How would it need to work? Well, at each point in time, it would need to somehow summarize the string it had seen thus far. What might that summary look like? The DFA wouldn't necessarily need to remember the exact string it had read - that's too specific. However, it would need to know something about the relative frequencies of a's and b's of what it's seen thus far. If the DFA couldn't remember that information, then upon seeing the rest of the string, it would have no way of knowing whether the counts of a's and b's are the same. In that sense, the DFA would "have to remember" the relative frequencies of a's and b's of the strings it processes.
What can we do with this knowledge? We are ultimately interested in building a distinguishing set for $L\text.$ We also have some idea of what information a DFA for $L$ would "have" to remember. We can therefore use the following, powerful intuition for building distinguishing sets:
Choose each string in the distinguishing set to correspond to different pieces of information that "must" be remembered.
For example, the relative frequencies of the a's and b's in a string could be 0 (same number of a's and b's), +1 (one more a than b), -1 (one more b than a), +2 (two more a's than b's), -2 (two more b's than a's), etc. There's infinitely many different possibilities for what the relative delta could be. To build our distinguishing set, let's pick a set of infinitely many strings, each of which has a different relative balance of a's and b's. Each one of those strings will require that a DFA "remember" a different fact about it (specifically, the relative balance of a's and b's), and intuitively that should make them distinguishable.
One simple way to do this is to pick $S = \set{\mathtt{a}^n \suchthat n \in \naturals}\text.$ The string $\mathtt{a}^n$ has a relative balance of $+n\text,$ so each string has a different "fact" that must be remembered.
Does this make what we have a distinguishing set? Let's find out! Suppose we pick $\mathtt{a}^m, \mathtt{a}^n \in S$ where $m \ne n\text.$ We can set up our distinguishability game below:
\[\begin{array}{r|l} \mathtt{a}^m & \\ \mathtt{a}^n & \end{array}\]To win the game, we need to tack something onto the end of both strings to put one in $L$ and to keep the other out. There's lots of ways to do this, but the simplest two options are these:
\[\begin{array}{r|l} \mathtt{a}^m & \mathtt{b}^m \\ \mathtt{a}^n & \mathtt{b}^m \end{array} \qquad \qquad \begin{array}{r|l} \mathtt{a}^m & \mathtt{b}^n \\ \mathtt{a}^n & \mathtt{b}^n \end{array}\]So it looks like, indeed, we have a distinguishing set - and an infinite one to boot!
Here's a formal proof that $L$ is not regular that uses this distinguishing set.
Proof: Let $S = \set{\mathtt{a}^n \suchthat n \in \naturals}\text.$ We will prove that $S$ is an infinite distinguishing set for $L\text.$ By the Myhill-Nerode theorem, this proves $L$ is not regular.
To see that $S$ is infinite, note that it contains one string for each natural number.
To see that $S$ is a distinguishing set for $L\text,$ pick any distinct strings $\mathtt{a}^m, \mathtt{a}^n \in S\text.$ We will show there is a string $w$ such that $\mathtt{a}^m w \in L$ but $\mathtt{a}^n w \notin L\text.$
Specifically, pick $w = \mathtt{b}^m\text.$ Then we see that $\mathtt{a}^m w = \mathtt{a}^m\mathtt{b}^m \in L$ because it has $m$ a's and $m$ b's. On the other hand, $\mathtt{a}^n w = \mathtt{a}^n \mathtt{b}^m \notin L$ because it has $n$ a's but $m \ne n$ b's. $\qed$
"Hey wait a minute," you might be saying, "isn't that the same distinguishing set that we used for $E = \set{\mathtt{a}^n\mathtt{b}^n \suchthat n \in \naturals}\text?$" Yes. Yes it is. That's not a problem - the same set can serve as a distinguishing set for multiple languages.
"Well, in that case, shouldn't we always try to use the set $S = \set{\mathtt{a}^n \suchthat n \in \naturals}$ as a distinguishing set? The answer is "it depends on what language you're working with." It's not bad to try guessing $S$ will work just to see what happens, but that doesn't mean it's always going to work. There are many languages for which this choice won't work, and others for which it will, but where the proof is going to be gnarly.
Let's see an example of such a language.
Consider Changing Distinguishing Sets
In this section, let's pick the following language $L$ over $\Sigma = \set{\mathtt{a}}\text:$
\[L = \set{\mathtt{a}^{2^n} \suchthat n \in \naturals}\text.\]This is the language of all strings of a's whose lengths are powers of two. Thus we have $\mathtt{a} \in L$ $(2^0 = 1)\text,$ and we have $\mathtt{aa} \in L$ $(2^1 = 2)\text,$ and we have $\mathtt{aaaaaaaa} \in L$ $(2^3 = 8)\text,$ etc. It turns out that this language isn't regular, and our goal will be to prove that.
Hot on the heels of the previous example, suppose we decide to try using $S = \set{\mathtt{a}^n \suchthat n \in \naturals}$ as a distinguishing set. I mean, it worked for two other languages, so I suppose it'll probably work here too, right?
The answer is "yes, technically." To see why, let's pick a few example strings and think about how to distinguish them. Let's take, say, $\mathtt{a}^6$ and $\mathtt{a}^{14}\text.$ How might we distinguish them? There are lots of ways we can do this. Here's two:
\[\begin{array}{r|ll} \mathtt{a}^{6} & \mathtt{a}^{10} & (16 = 2^4)\\ \mathtt{a}^{14} & \mathtt{a}^{10} & (24 \text{ is not a power of two }) \end{array}\] \[\begin{array}{r|ll} \mathtt{a}^{6} & \mathtt{a}^{18} & (24 \text{ is not a power of two })\\ \mathtt{a}^{14} & \mathtt{a}^{18} & (32 = 2^5) \end{array}\]In each case, we're adding an amount to bump one of the two numbers up to a power of two, but not the other.
However, the actual choice of how much to add is more subtle than it looks. The nearest powers of two to 6 and 14 are, respectively, $2^3 = 8$ and $2^4 = 16\text.$ But we can't append $\mathtt{a}^2$ to the two strings, the amount needed to bump each up to its next power of two, because if we did that, we'd end up with both strings having lengths that were powers of two (8 and 16, respectively). The other choices shown above work, though.
Let's peek ahead to what would happen if we wanted to use this choice of $S$ as our infinite distinguishing set. Given two strings $\mathtt{a}^m$ and $\mathtt{a}^n\text,$ where $m \ne n\text,$ we'd need to somehow prove there was a number $k$ where exactly one of $m$ and $n$ is a power of two. It's certainly possible to do this (it's a true statement), but this is decidedly nontrivial. (We've left it as an exercise here if you'd like to try it!)
What we've encountered here is a common case when finding distinguishing sets. We've found a distinguishing set that works, but the justification that it is actually a distinguishing set is challenging. We're thus left at a junction: we could either press ahead and try to prove it's a distinguishign set, or we can change our distinguishing set to try to make the proof easier. It's hard to know which of the two is the easier route, and some amount of guesswork is involved. A reasonable idea would be to spend a few minutes trying to get the proof to work, and if that doesn't work, a few minutes finding another distinguishing set, alternating until we get something that works.
For the purposes of this example, let's try doing some searching to find a better distinguishing set. Earlier on, we talked about how sometimes strings in the language $L$ can serve as elements of a distinguishing set, while in other cases that's not possible. We haven't specifically looked at elements of $L$ yet when trying to find distinguishable strings, so let's try that out.
Suppose we pick $\mathtt{a}^4$ and $\mathtt{a}^{16}\text.$ To distinguish these, we need to append some string to both that makes one of them have a length that's a power of two and the other a length that isn't a power of two. How might we do that? Well, looking at $\mathtt{a}^4\text,$ we can see that the next power of two after 4 is 8. So let's try appending $\mathtt{a}^4\text.$ That would do the following:
\[\begin{array}{r|ll} \mathtt{a}^{4} & \mathtt{a}^{4} & (8 = 2^3)\\ \mathtt{a}^{16} & \mathtt{a}^{4} & (20 = 4 \cdot 5 \text{ is not a power of two }) \end{array}\]Hey, that works!
Let's try another pair of strings - this time, $\mathtt{a}^{32}$ and $\mathtt{a}^{128}\text.$ What do we append this time? Let's try the same technique we did above - take one of the strings and bump it up to the next power of two. The next power of two after 32 is 64, so let's append $\mathtt{a}^{32}$ to both strings:
\[\begin{array}{r|ll} \mathtt{a}^{32} & \mathtt{a}^{32} & (64 = 2^6)\\ \mathtt{a}^{128} & \mathtt{a}^{32} & (160 = 5 \cdot 32 \text{ is not a power of two }) \end{array}\]Huh, this seems to be working! Let's try one last example: $\mathtt{a}^1$ and $\mathtt{a}^{256}\text.$ If we try the same technique as before, we would try to bump 1 up to the next power of two (2) by adding 1:
\[\begin{array}{r|ll} \mathtt{a}^{1} & \mathtt{a}^{1} & (2 = 2^1)\\ \mathtt{a}^{256} & \mathtt{a}^{1} & (257 \text{ is not a power of two }) \end{array}\]Okay, it seems like we're on to something! It looks like every pair of powers of two we look at can be distinguished by appending the shorter of the two strings to both. That might counsel us to pick $S = \set{\mathtt{a}^{2^n} \suchthat n \in \naturals}\text,$ or, stated differently, to pick $S = L\text.$ Can we do that? Sure! Nothing in the definition of a distinguishing set says that the distinguishing set has to be different than the language it's a distinguishing set for.
Now, to justify why this is a distinguishing set, we should come up with a general procedure to distinguish $\mathtt{a}^{2^m}$ from $\mathtt{a}^{2^n}\text.$ Our idea is to take the shorter of the two (suppose $m \lt n$ here) and append it to both strings. We now have the strings $\mathtt{a}^{2^m}\mathtt{a}^{2^m}$ and $\mathtt{a}^{2^n}\mathtt{a}^{2^m}\text.$ From the above examples, it seems like the first of these should have a length that's a power of two and the second should not. Now we need to see why that is.
First, let's look at $\mathtt{a}^{2^m}\mathtt{a}^{2^m}\text.$ We can rewrite this as
\[\mathtt{a}^{2^m}\mathtt{a}^{2^m} = \mathtt{a}^{2^m + 2^m} = \mathtt{a}^{2 \cdot 2^m} = \mathtt{a}^{2^{m+1}}\text.\]This string's length is a power of two, so it's in $L\text.$
Now, let's look at $\mathtt{a}^{2^n}\mathtt{a}^{2^n}\text.$ We can rewrite this string as
\[\mathtt{a}^{2^n}\mathtt{a}^{2^m} = \mathtt{a}^{2^n + 2^m} = \mathtt{a}^{2^m \cdot (2^{n - m} + 1)}\text.\]We know that $m \lt n\text,$ which means that $n - m \gt 0\text,$ and since $m$ and $n$ are integers, that means $n - m \ge 1$ and in turn that $n - m - 1 \ge 0\text.$ We can therefore continue rewriting this string as follows:
\[\mathtt{a}^{2^m \cdot (2^{n - m} + 1)} = \mathtt{a}^{2^m \cdot (2 \cdot 2^{n - m - 1} + 1)}\text.\]Notice that that last term is an odd number: it's of the form $2k + 1$ for some integer $k\text.$ (Specifically, since $n - m - 1 \ge 0\text,$ we know that $n - m - 1$ is an integer, so $2^{n - m - 1}$ is as well.) Moreover, it's an odd number greater than 1, since $2^{n - m - 1} \ge 2^0 = 1\text.$ That in turn means that $2^m \cdot (2 \cdot 2^{n - m - 1} + 1)$ can't be a power of two - it has an odd divisor other than 1, and the only odd number that divides a power of two is 1. So after a lot of math and wrangling, we've shown that this string isn't in $L\text!$
The math here is definitely not trivial, but it's much easier than what we'd have to do if we stuck with our original distinguishing set. We're able to heavily lean on the fact that the strings' lengths are powers of two to remove a bunch of cases and make the factorization of the products easier to do. As you're working with distinguishing sets, remember that sometimes it's easier to change the shape of the strings in your distinguishing set to have a much more restrictive shape than it is to try to handle a ton of unusual or odd cases in the proof that what you have is indeed a distinguishing set.
Here's a proof showing how we'd argue $L$ is nonregular:
Proof: We will show that $L$ is an infinite distinguishing set for itself, which, by the Myhill-Nerode theorem, proves $L$ is nonregular. We thus must show that $L$ is infinite and that $L$ is a distinguishing set for itself.
To see that $L$ is infinite, note that it contains one string for each natural number; amely, for each $n \in \naturals\text,$ it contains the string $\mathtt{a}^{2^n}\text.$
To see that $L$ is a distinguishing set for itself, pick any distinct strings $\mathtt{a}^{2^m}, \mathtt{a}^{2^n} \in L$ and assume without loss of generality that $m \lt n\text.$ We will show that $\mathtt{a}^{2^m} \mathtt{a}^{2^m} \in L$ and that $\mathtt{a}^{2^n} \mathtt{a}^{2^m} \notin L\text.$
First, focus on $\mathtt{a}^{2^m} \mathtt{a}^{2^m}\text.$ Notice that
\[\begin{aligned} \mathtt{a}^{2^m}\mathtt{a}^{2^m} &= \mathtt{a}^{2^m + 2^m} \\ &= \mathtt{a}^{2 \cdot 2^m} \\ &= \mathtt{a}^{2^{m+1}}\text, \end{aligned}\]which means that $\mathtt{a}^{2^m}\mathtt{a}^{2^m} \in L\text.$
Now, focus on $\mathtt{a}^{2^n} \mathtt{a}^{2^m}\text,$ which we can rewrite as $\mathtt{a}^{2^m + 2^n}\text.$ Earlier we assumed that $m \lt n\text,$ which means that there exists a natural number $k$ such that $n = m + k + 1\text.$ We thus see that
\[\begin{aligned} 2^n + 2^m &= 2^{m + k + 1} + 2^m \\ &= 2^m \cdot (2^{k+1} + 1) \\ &= 2^m \cdot (2 \cdot 2^k + 1)\text. \end{aligned}\]We note that $2 \cdot 2^k + 1$ is odd. Moreover, since $2^k \ge 2^0 = 1\text,$ we see that $2 \cdot 2^k + 1 \ge 3\text.$ Therefore, $2^n + 2^m$ has an odd divisor greater than or equal to three, which means that $2^n + 2^m$ is not a power of two. Thus $\mathtt{a}^{2^n + 2^m} \notin L\text,$ as required. $\qed$
This is definitely a more involved proof than the other ones we've done thus far, but if you zoom out a bit it's still arguing that we found our infinite distinguishing set.
Exercises
Looking for some more practice with the Myhill-Nerode theorem? Feel free to work through the following (optional, not collected for a grade) exercises.
-
Let $\Sigma = \mathtt{\set{a, b}}$ and let $L$ be the following language over $\Sigma\text:$
\[L = \set{w \in \Sigma^\star \suchthat \abs{w} \text{ is odd and the middle character of } w \text{ is } \mathtt{a}}\text.\]Prove that $L$ is not regular.
There are lots of ways of approaching this one. We'll use the intuition of thinking of what we "must" remember to check if a string is in the language. Suppose you're scanning a string from the left to the right and all you've seen thus far are
\[\begin{array}{r|l} \mathtt{b}^{m} & \mathtt{a}\mathtt{b}^m \\ \mathtt{b}^{n} & \mathtt{a}\mathtt{b}^n \end{array}\]b's. You'd need to remember how manyb's you've seen so that, if the next character isaand you see a series of characters after thata, you can determine whether thatahappens to fall in the exact middle of the string. (You'd possibly need to remember more information than that, but that would be a starting point.) We can therefore think about building our distinguishing set $S$ by picking strings with different numbers ofb's in them. We could start off by trying something like $S = \set{\mathtt{b}^n \suchthat n \in \naturals}\text.$ Our idea would be that if we have strings $\mathtt{b}^m$ and $\mathtt{b}^n$ with $m \ne n\text,$ we could distinguish them like this:The top string has an odd length (specifically, $2m + 1\text)$ and has an
ain the middle, so it's in $L\text.$ The bottom string doesn't have anain the middle, since there's moreb's on one side than on the other. (It might not even have a "middle" character, which would happen if its length wasn't odd.)Here's one way we could formally prove $L$ isn't regular:
Proof: Let $S = \set{\mathtt{b}^n \suchthat n \in \naturals}\text.$ We will prove that $S$ is an infinite distinguishing set for $L\text.$
To see that $S$ is infinite, note that it has one string for each natural number.
To see that $S$ is a distinguishing set, choose any two distinct strings $\mathtt{b}^m, \mathtt{b}^n \in S\text.$ We will prove that $\mathtt{b}^m \not\equiv_L \mathtt{b}^n\text.$ To see this, first note that $\mathtt{b}^m\mathtt{a}\mathtt{b}^m$ has odd length $2m + 1\text.$ Moreover, its middle character is
a. Thus $\mathtt{b}^m\mathtt{a}\mathtt{b}^m \in L\text.$However, we claim that $\mathtt{b}^n\mathtt{a}\mathtt{b}^m \notin L\text.$ To see this, note that there is exactly one
ain $\mathtt{b}^n\mathtt{a}\mathtt{b}^m\text.$ If it were in the middle of the string, then there would have to be an equal number of characters on each side. However, there are $n$ characters to one side and $m$ to the other. Thusais not the middle character of $\mathtt{b}^n\mathtt{a}\mathtt{b}^m\text,$ and so $\mathtt{b}^n\mathtt{a}\mathtt{b}^m \notin L\text.$Since $S$ is an infinite distinguishing set for $L\text,$ by the Myhill-Nerode theorem we know that $L$ is not regular. $\qed$
-
Let $\Sigma = \set{\mathtt{a}, \mathtt{b}}$ and consider the finite language $L = \set{\varepsilon, \mathtt{a}}$. Draw the smallest possible DFA for $L\text.$ By "smallest," we mean "using as few states as possible." Then, prove that every DFA for $L$ has at least as many states as your DFA. To do so, use the following theorem, which you can use without proof: if $S$ is a distinguishing set for $L$ containing finitely many strings, then any DFA for $L$ must have at least $\abs{S}$ states.
The smallest possible DFA for this language has three states and is shown here:
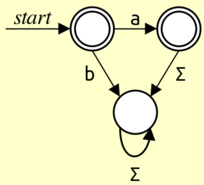
To prove that this is the smallest possible DFA, we'll use the theorem given in the problem statement. That requires us to find a distinguishing set for $L$ that has three strings in it. This is where we can use a bit of trial and error, and once we've done some scouting, we can find a distinguishing set like the one used in the proof below:
Theorem: Every DFA for $L = \Set{\varepsilon, \mathtt{a}}$ has at least three states.
Proof: Let $S = \Set{\varepsilon, \mathtt{a}, \mathtt{b}}\text.$ We will prove that $S$ is a distinguishing set for $L\text,$ which means all DFAs for $L$ need at least three states. To see this, we must prove that any two distinct strings in $S$ are distinguishable relative to $L\text.$
We note that there are only three possible pairs of distinct strings in $S\text:$
- $\varepsilon$ and $\mathtt{a}\text:$ Appending $a$ to each string gives $\mathtt{a} \in L$ and $\mathtt{aa} \notin L\text.$
- $\varepsilon$ and $\mathtt{b}\text:$ Appending $\varepsilon$ to each string gives $\varepsilon \in L$ and $\mathtt{b} \notin L\text.$
- $\mathtt{a}$ and $\mathtt{b}\text:$ Appending $\varepsilon$ to each string gives $\mathtt{a} \in L$ and $\mathtt{b} \notin L\text.$
In each case there is a string we can append that results in one string in $L$ and one not in $L\text,$ so the two strings are distinguishable relative to $L\text,$ as required. $\qed$
-
Let $\Sigma$ be an arbitrary alphabet and let $L$ be an arbitrary language where $L \ne \Sigma^\star$ and $L \ne \emptyset\text.$ Prove that $L$ has a distinguishing set of cardinality two.
This is an interesting problem in that we're given essentially no information at all about what $L$ is. It could be regular or nonregular, finite or infinite, etc. All we know is that it isn't $\Sigma^\star$ and it isn't $\emptyset\text.$ What does that tell us?
Well, the fact that $L \ne \emptyset$ means that there must be at least one string $w_{yes}$ that is in $L\text.$ Similarly, the fact that $L \ne \Sigma^\star$ means that there must be at least one string $w_{no}$ that is not in $L\text.$ We have no idea what these strings are - they could be short, long, simple, complex, etc. All we know is that they have to exist.
We're looking for a distinguishing set of two strings, and we happen to have two strings, so it would be really nice if they happened to be distinguishable. So let's see if we can win the distinguishability game:
\[\begin{array}{r|l} w_{yes} & \\ w_{no} & \end{array}\]What can we tack onto the end of each string so that one string ends up in $L$ and the other ends up not in $L\text?$ Well, we already know that $w_{yes}$ is in $L$ and that $w_{no}$ is not in $L\text,$ so it would be great if we could just say "don't tack anything onto the ends of these strings." But we must append something, so saying "don't append anything" isn't an option.
Or is it? There's nothing saying that the string we append to end of each string has to be nonempty. What if we tack $\varepsilon$ onto the end of both strings? Remember that concatenating the empty string has no effect, so that would leave us with $w_{yes}$ and $w_{no}\text,$ and exactly one of those is in $S\text.$ Success!
Here's what that looks like as a formal proof:
Proof: We will show there is a set $S$ where $S$ contains two strings and $S$ is a distinguishing set for $L\text.$
Since $L \ne \emptyset\text,$ we know that there exists some string $w_{yes} \in L\text.$ Similarly, since $L \ne \Sigma^\star\text,$ we know there is a string $w_{no} \in \Sigma^\star$ where $w_{no} \notin L\text.$ We claim that $w_{yes} \not\equiv w_{no}\text.$ To see this, notice that $w_{yes}\varepsilon = w_{yes} \in L$ and that $w_{no}\varepsilon = w_{no} \notin L\text.$ Thus $w_{yes} \not\equiv_L w_{no}\text.$
Now, let $S = \set{w_{yes}, w_{no}}\text.$ This set contains two strings (we can't have $w_{yes} = w_{no}\text,$ since one of these strings is in $L$ and the other is not). Furthermore, it's a distinguishing set; the only pair of distinct strings it contains is $w_{yes}$ and $w_{no}\text,$ and as shown above we know that $w_{yes} \not\equiv_L w_{no}.$ Thus $S$ is a distinguishing set for $L$ of cardinality two, as required. $\qed$
-
The language $E = \set{\mathtt{a}^n \mathtt{b}^n \suchthat n \in \naturals }$ is the poster child of a nonregular language. This language has another interesting property not shared by all nonregular languages.
Let $L \subseteq E$ be a language where $\abs{L}$ is infinite. Prove that $L$ is not regular.
What makes this problem interesting is that we don't know what specific language $L$ is. It could be $E$ itself, or it could consist of strings of the form $\mathtt{a}^n\mathtt{b}^n$ where $n$ is even, or it could be formed by tossing a coin for each string in $E$ and only taking the ones where the coin comes up heads. All we know is that all the strings in $L$ have the form $\mathtt{a}^n\mathtt{b}^n$ for some natural number $n\text.$
Although we don't know what specific strings we're dealing with, we can still say that the intuition for why $E$ is nonregular still applies - we "have" to remember how many
a's we've seen so we can match them against the same number ofb's.Does this mean we could pick the same distinguishing set $S = \set{\mathtt{a}^n \suchthat n \in \naturals}$ that we picked for $E\text?$ The answer is "yes, technically, but it's trickier than it looks." The reason for this is the following: suppose we do choose $S$ this way, and we pick two distinct strings $\mathtt{a}^m, \mathtt{a}^n \in S\text.$ If we were trying to distinguish those strings relative to $E\text,$ all we'd have to do is tack on $\mathtt{b}^m$ to both, giving $\mathtt{a}^m\mathtt{b}^m$ and $\mathtt{a}^n\mathtt{b}^m\text.$ The first of these strings is definitely in $E\text,$ and the second definitely isn't.
But if we're working with an arbitrary subset $L$ of $E\text,$ we actually can't say for certain that $\mathtt{a}^m\mathtt{b}^m \in L\text,$ because $L$ doesn't necessarily contain all the strings from $E\text.$ That makes the above line of reasoning not work any more.
Can we salvage this somehow? If we could somehow restrict the sorts of strings we could pick for $\mathtt{a}^m$ so that $\mathtt{a}^m\mathtt{b}^m$ was guaranteed to be in $L\text,$ then we'd be done. By choosing $S = \set{\mathtt{a}^n \suchthat n \in \naturals}\text,$ we don't have that guarantee. But perhaps we could change $S$ so that we'd be sure that, if we picked an $\mathtt{a}^m \in S\text,$ we'd know that $\mathtt{a}^m\mathtt{b}^m \in L\text.$ And indeed, we can do this. Let's redefine $S$ like this:
\[S = \set{\mathtt{a}^n \suchthat \mathtt{a}^n\mathtt{b}^n \in L}\text.\]This is essentially the first halves of every string in $S\text.$
With that choice of $S$ in mind, here's how we'd carry out the proof:
Proof: Let $S = \set{\mathtt{a}^n \suchthat \mathtt{a}^n\mathtt{b}^n \in L}\text.$ We will prove that $S$ is an infinite distinguishing set for $L\text.$
To see that $S$ is infinite, note that it contains one string for each string in $L\text,$ and since $L$ is infinite, this means there are infinitely many strings in $S\text.$
To see that $S$ is a distinguishing set for $L\text,$ choose any strings $\mathtt{a}^m, \mathtt{a}^n \in S$ where $m \ne n\text.$ We will prove that $\mathtt{a}^m \not\equiv_L \mathtt{a}^n\text.$ To see this, first note that by definition of $S$ we have $\mathtt{a}^m\mathtt{b}^m \in L\text.$ However, we see that $\mathtt{a}^n\mathtt{b}^m \notin E\text,$ and since $L \subseteq E$ this means that $\mathtt{a}^n\mathtt{b}^m \notin L\text.$ Consequently, there's a string $w$ (namely, $\mathtt{b}^m\text)$ such that $\mathtt{a}^m w \in L$ but $\mathtt{a}^n w \notin L\text,$ and thus $\mathtt{a}^m \not \equiv \mathtt{a}^n\text,$ as required.
Since $S$ is an infinite distinguishing set for $L\text,$ by the Myhill-Nerode theorem $L$ is not regular. $\qed$
-
Let $\Sigma = \set{\mathtt{a}}\text.$ Prove that $S = \set{\mathtt{a}^n \suchthat n \in \naturals}$ is a distinguishing set for $L = \set{\mathtt{a}^{2^n} \suchthat n \in \naturals}\text.$ (This shows we weren't kidding earlier when we said that it's possible to use this as a distinguishing set but that it's nontrivial.)
There are many different lines of reasoning you can use to prove this result. Here's the simplest one I know. (Did you find a simpler way to do this? If so, please let me know!)
Proof: Choose any distinct strings $\mathtt{a}^m, \mathtt{a}^n \in S\text.$ Assume, without loss of generality, that $m \lt n\text.$ We need to show that there exists a string $w \in \Sigma^\star$ such that exactly one of $\mathtt{a}^m w$ and $\mathtt{a}^n w \in L\text.$
There are infinitely many powers of two, and so in particular there exists at least one $k$ such that $m \le 2^k\text.$ We know that $\mathtt{a}^m \mathtt{a}^{2^k - m} = \mathtt{a}^{2^k} \in L\text.$ We then consider two cases:
-
Case 1: $\mathtt{a}^n\mathtt{a}^{2^k - m} \notin L\text.$ Then there is a choice of $w\text,$ namely $w = \mathtt{a}^{2^k - m}\text,$ such that exactly one of $\mathtt{a}^m w$ and $\mathtt{a}^n w$ belongs to $L\text.$
-
Case 2: $\mathtt{a}^n\mathtt{a}^{2^k - n} \in L\text.$ This means that there exists some $r \in \naturals$ such that $\mathtt{a}^n\mathtt{a}^{2^k - m} = \mathtt{a}^{2^r}\text.$ Moreover, since $m \lt n\text,$ we know that $2^k = m + 2^k - m \lt n + 2^k - m = 2^r\text,$ so $2^k \lt 2^r\text.$ By the proof that we did in our earlier section, we know that $\mathtt{a}^{2^k} \not\equiv_L \mathtt{a}^{2^r}\text,$ so there exists a string $y$ such that exactly one of $\mathtt{a}^{2^k} y$ and $\mathtt{a}^{2^r} y$ belongs to $L\text.$
Now let $w = \mathtt{a}^{2^k - m} y\text.$ Then exactly one of $\mathtt{a}^m w = \mathtt{a}^m \mathtt{a}^{2^k - m} y = \mathtt{a}^{2^k}y$ and $\mathtt{a}^n w = \mathtt{a}^n \mathtt{a}^{2^k - m} y = \mathtt{a}^{2^r} y$ is in $L\text.$
In either case we find a choice of $w$ satisfying the requirements, so $\mathtt{a}^m \not\equiv_L \mathtt{a}^n\text,$ as required. $\qed$
-