Execution across domains
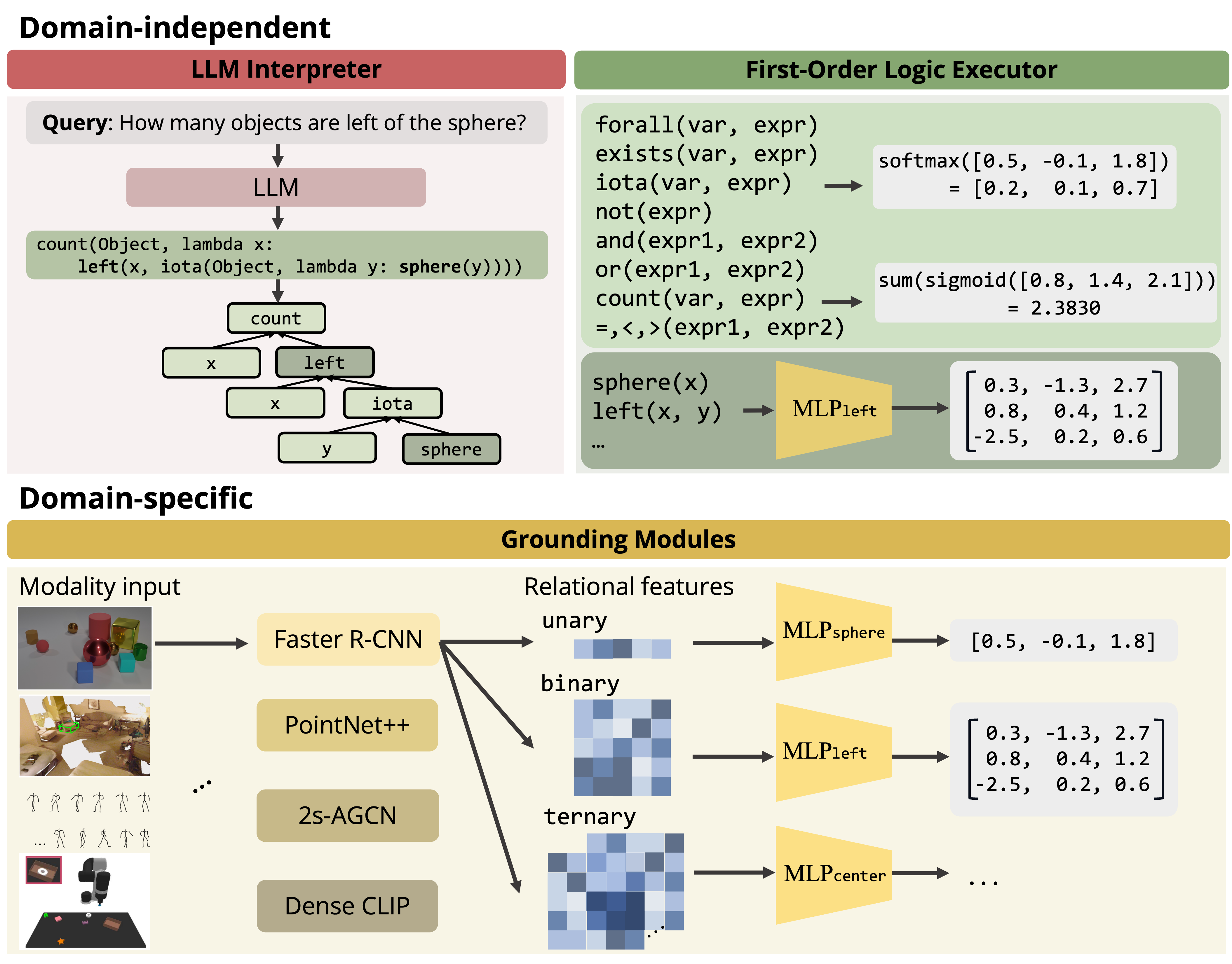
LEFT is the Logic-Enhanced Foundation Model, a unified
framework that conducts concept learning and reasoning across
different domains and tasks. It integrates LLMs with
differentiable logic modules, and modular neural networks for
grounding concepts in each modality. Importantly, LEFT requires
no predefined domain-specific language, and instead
leverages LLMs to propose both reasoning trace and the visual
grounding modules to automatically initialize from the input
language query.
Below, we show execution traces of LEFT in the 2D, 3D, temporal,
and robotic manipulation domains. LEFT executes each program,
generated by LLMs, with domain-independent first-order logic
modules and learnable domain-specific grounding modules (in
colored text). The LEFT framework can be trained on different
domains with the
same general decomposition. Concepts in language serve as
abstractions that enable such generalization.
Reasoning across tasks
LEFT can zero-shot transfer to novel visual reasoning tasks with LLM generated first-order logic, and effectively reuse learned concept embeddings, enabling flexible generalization. Our model performs well on challenging tasks which require the LLM interpreter to reason about patterns described by language. While the prompts given to the LLM are simple, the LLM interpreter can generalize to more complex tasks.