
Exhibit 3: Fundbox data loop
Leveraging machine learning to gain deep customer insights.
With a secure pipeline of data in place, Fuloria and the Fundbox team set out to define processes to help ensure they could learn as much as possible from their customers, as he explained: “How do you resist the temptation to come up with a bunch of business rules that overly constrain you from the very beginning? For example, if we had a traditional underwriter working at Fundbox from the very beginning, they would put a bunch of filters on our lending practices and box us in to lending to a particular type of customer. Whereas, by keeping a bigger aperture, we were able to figure out which parts of the market provided the most untapped value.”
Fuloria hoped to design a system in which guard rails could be established that kept the process working smoothly, but would not stifle the learning process, as he explained:
“The analogy I like to give is that as a parent with children, you try to keep them out of trouble, so you say things like, ‘Don’t do this, don’t do that, and don’t do that.’ Well, over time their learning becomes constrained, so there is always a tradeoff between how much risk you let them take and how much they can learn.”
Fuloria and his team also considered buying data:
“It’s ok to buy data to increase the number of columns (attributes) you have on each user. ‘Tell me more about them in terms of their size, previous bankruptcies, etc.,’ but the observations need to be your own. The problem with buying somebody else’s data is that, for example when it comes to bankruptcies, you may know that a particular business failed to repay a loan at a certain point in time, but you won’t know all of the other attributes of the business at that point in time.”
So the Fundbox team committed to learning through their own observations, which were the rows in the matrix. The data loop they committed to focused on lending small amounts of money at a high frequency, and as customers continued to use the product, the more Fundbox would learn about their lending needs (See Exhibit 3 below for a description of this data loop).
In addition to the data loop, Fuloria wondered whether it would be helpful to purchase additional data on Fundbox customers from third-party providers to increase the number of columns (attributes) for each user.
Exhibit 3: Fundbox data loop
Fundbox's data availability was markedly different from other consumer technology companies, like search engines. In the search engine model, a user could perform multiple searches a day, thus creating numerous attempts to gather data on the user and his or her queries. These data allowed the search engine to tailor advertisement results for every possible combination of user and search query. Additionally, each search improved the ability to match users with relevant advertisements during subsequent searches. (See Exhibit 4 below for an example of the search engine data loop.).
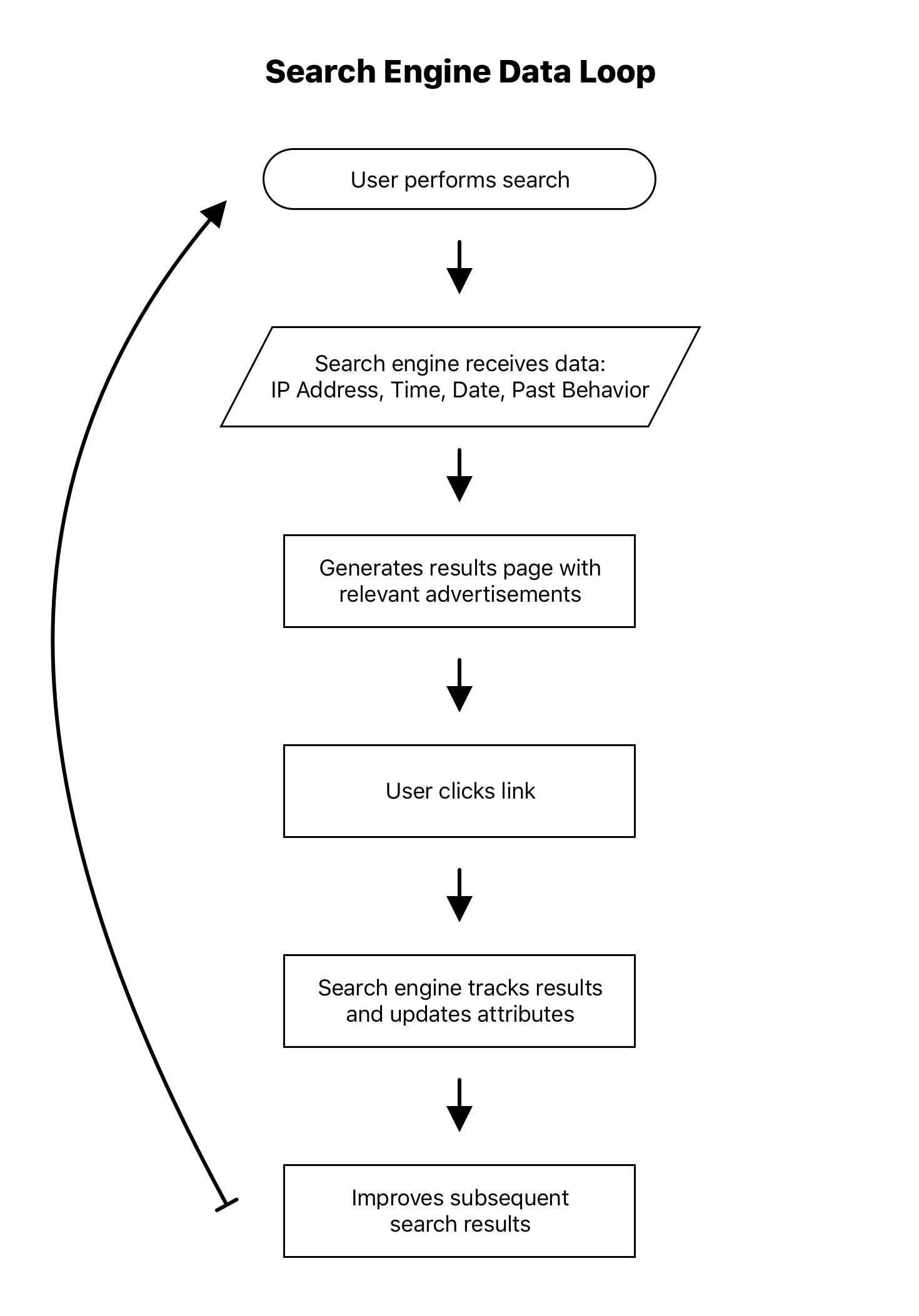
Exhibit 4: Search engine data loop