Below are the distributions of reviews in some corpora in which each text has associated with it a star rating, 1-5 stars (1 negative, 5 positive).
Your tasks:
(This problem concerns sentiment analysis, but the underlying issues are common wherever one is dealing with naturalistic corpora.)
| English product reviews | ||||||
|---|---|---|---|---|---|---|
| 1-star | 2-star | 3-star | 4-star | 5-star | total | |
| reviews | 39,383 | 48,455 | 90,528 | 148,260 | 237,839 | 564,465 |
| words | 3,419,923 | 3,912,625 | 6,011,388 | 10,187,257 | 16,202,230 | 39,733,423 |
| vocabulary | 61,138 | 63,632 | 82,868 | 109,130 | 139,922 | 239,362 |
| Japanese Amazon | ||||||
|---|---|---|---|---|---|---|
| 1-star | 2-star | 3-star | 4-star | 5-star | total | |
| reviews | 3,973 | 4,166 | 8,708 | 18,960 | 43,331 | 79,138 |
| words | 1,612,942 | 1,744,004 | 11,649,647 | 8,477,758 | 17,385,216 | 33,128,120 |
| vocabulary | 26,778 | 29,089 | 43,105 | 63,938 | 90,998 | 117,993 |
It's common for features in a model to have a kind of split personality due to sources of variation that have not been isolated. Very often, identifying these hidden factors can lead to better performance and increased interpretability of the model.
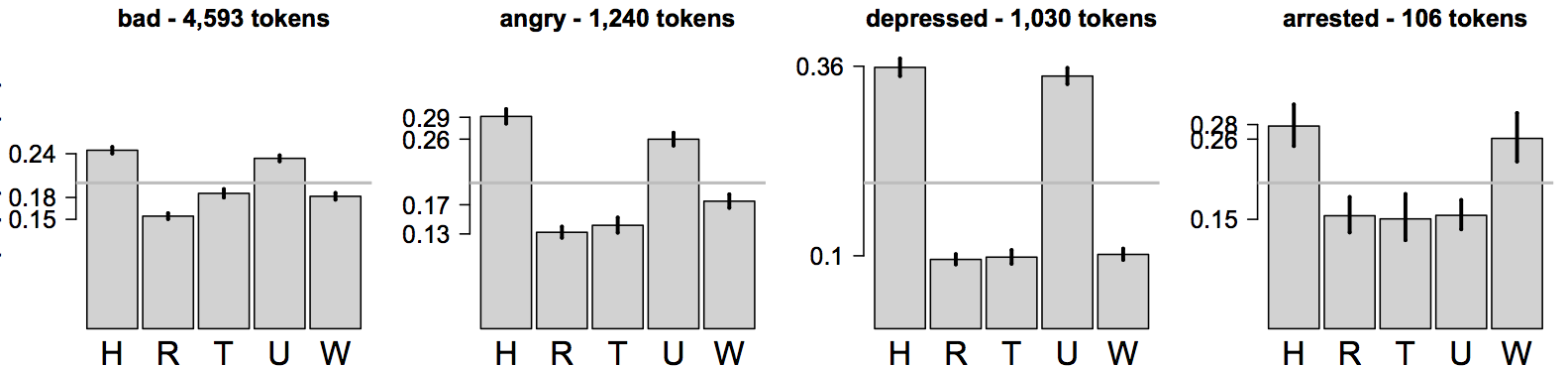
The following plots are derived from data at the Experience Project website. At the site, community members can post confessional texts, and others can react to them by clicking on a set of reaction categories: 'Sorry hugs' (sympathy), 'You rock' (positive enthusiasm), 'Teehee' (amusement), 'I understand' (solidarity), and 'Wow, just wow' (disapproval and shock). The plots depict probability distributions over these categories for four words: bad, angry, depressed, and arrested. You can think of the distributions as P(reaction | word): the probability of each kind of reaction given that the text contains the word in question.
Your task: focus on the rightmost plot, for arrested. The others plots are there to help you contextualize this one. The fact that the two most probable categories are 'Sorry, hugs' and 'Wow, just wow' is unusual. What might be causing the split between sympathetic and shocked reactions? (2-3 sentence response.)
Turney and Littman (2003) propose the semantic orientation method and apply it to developing a positive/negative sentiment lexicon. However, they suggest that the method could be extended to a much wider array of semantic oppositions. This makes it potentially useful to any project depending on lexical resources.
The R code you downloaded for the VSM lecture on Jan 17 includes an implementation of the semantic orientation method. Here's a direct link to the code and sample matrices. If you don't have that code and data already, download it now and then get set up by running the following commands in R, while inside the directory containing the data and code:
The code and word × word matrix are now loaded. Recall that you can reweight the matrix with TF-IDF, PMI, and other methods. You can also reduce its dimensionality with LSA. For details on how to do this to the matrix imdb, see pages 31 and 36 of the VSM slideshow.
Once you have the matrix in the format you like, you can use the semantic orientation method as follows:
Your tasks