CS 106B: Programming Abstractions, Autumn 2018
 Stanford C++ Lib
Stanford C++ LibLecture Preview: Hashing
(Suggested book reading: Programming Abstractions in C++, section 15.3)
Today we will discuss a fascinating approach to implementing sets and maps, called hashing. Hashing is where you come up with a function (let's call it H) that translates between a piece of data and a 0-based index. The idea is that you make an array and then you store each piece of data e at index H(e) in the array. Later if you need to check to see if your array contains e, you just go back to H(e) and look for it.
If the function H is fast, this means your collection can store and look up values very quickly.
We call the array a hash table if you use it in this way.
You can use a hash table to efficiently implement a set; that's what is inside of the HashSet collection in the Stanford C++ library.
It raises the question of what exactly the hash function H is, and how it translates elements of data into indexes. If the data are integers, a simple hash function is just to mod (%) the data by the array size. The following example shows the idea applied to an array of length 10, so that each element e you add will be stored at index e % 10:
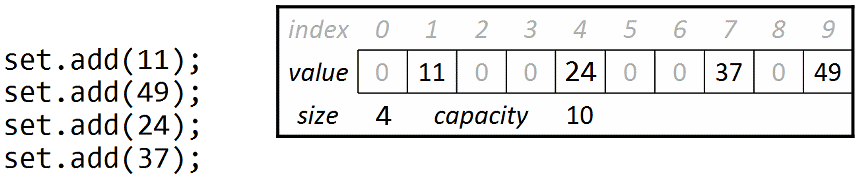
This idea encounters several problems, such as: What if two values map to the same index? And, how can you use this algorithm for data other than integers? We will discuss these issues in detail in lecture.