EE368B Final Project Report
Affine Motion-compensated Prediction
Dragomir Anguelov
Abstract
Traditional motion-compensated coders use only translational motion estimates for motion-compensated prediction. The goal of this project is to compare the traditional motion-compensated hybrid coder, with its counterpart, where we have an affine motion model instead of the translational one. We explore the tradeoff between the added quality that the increased expressivity of the affine model allows with the larger number of parameters that we need to encode.
The Motion-compensated Hybrid Coder
Motion compensated prediction exploits the similarity of successive frames of a video sequence and underlies such successful and widely-used standards as MPEG, H.261 and H.263[1]. It assumes brightness constancy - that the pixel intensities changes from frame to frame are due only to motion of objects in the scene. While there are a number of cases in real life when this assumption gets violated, for the most part systems based on it have performed very well.
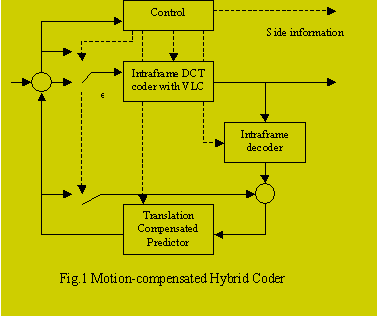
The Motion-compensated hybrid coder (MCHC) combines motion compensation and spatial 2D coding, the latter of which is usually used to transmit the prediction error and the first frame of the sequence. There are many techniques which improve the performance of the motion-compensated hybrid coder such as the use of loop filter and sub-pixel accuracy of motion compensation, and sophisticated features used in standard H.263 that we will not concern ourselves with in this project due to limited implementation time. Again, a number of spatial 2D coding methods can be used, but we have chosen to employ an intraframe DCT coder, which uses variable word length encoding. Also, we would be concerned with grayscale images only, because otherwise there are additional techniques we would employ to reduce the bitrate by using the mutual information between the components of the colorspace. The above is a general description of the testbed we will use for comparing the performance of translation and affine motion prediction.
Motion Models
Pure translation is widely used as a motion model for image compression. Let I(t) and I(t+1) be the frames at time t and t+1 and let I(t+1) be the frame we are trying to predict. Traditional motion-compensated coders split the image into blocks and use translation to describe the changes between them:
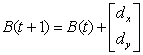
where B(t) is any point within a particular block in I(t) and B(t+1) is the corresponding point in I(t+1), and dx and dy are the translation of the block's center. The reason why translation works well in practice is that motion between frames is rather small, and the translation component is the most significant one (cameras and objects in general don't rotate or shear as much). Also, the translation model has only 2 parameters per block, which we need to encode.
The affine motion model is considerably more expressive, because it incorporates transformations such as rotation and shear. It allows higher adaptability to the underlying image and in general, we expect that it will yield better results. The transformation can be described as:
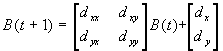
where
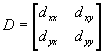 is
a deformation matrix accounting for rotation and shear. The image
coordinates in B(t) are measured with respect to the window's
center. For more details on the affine transformation, please refer to
[2]. In general, it should be explored whether the better rates from this
more expressive transformation offset the need to encode the additional
parameters and the need to perform more complicated motion estimation.
is
a deformation matrix accounting for rotation and shear. The image
coordinates in B(t) are measured with respect to the window's
center. For more details on the affine transformation, please refer to
[2]. In general, it should be explored whether the better rates from this
more expressive transformation offset the need to encode the additional
parameters and the need to perform more complicated motion estimation.
The "Hybrid" Motion-Compensated Hybrid Coder
Very often the motion in parts of the video sequence is so small, that it does not warrant the complicated affine model (and sometimes even translational motion is an overkill). Instead, we can combine the power of both translation and affine motion estimation selectively to encode a whole image. This is the main algorithm that we are readying for face off with the simple translation motion estimation. At the expense of 1 bit/block we get the choice to encode an affine or a translation transformation for every block in the video frame. The Hybrid MCHC computes the rates for both the affine and the translation models, and for each image block it picks the encoding which has lower rate.
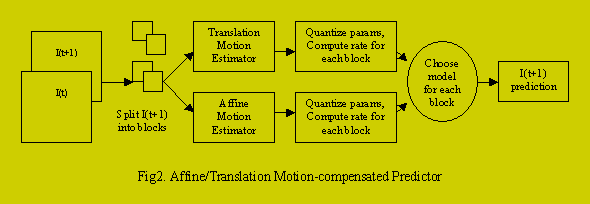
The "Hybrid" MCHC can be expected to perform better than its counterpart as the frame rate decreases (since then the assumption of small motion at which translation models perform well gets violated) as well as in sequences where objects display rotation and shear. More complex motion model also should do better if we use larger blocksizes. One should note, however, that in case of large intraframe motions the problem of affine motion estimation becomes rather difficult without full search.
Affine Motion Estimation
There are usually two main methods of motion estimation used in practice - blockmatching and differential methods. Blockmatching is usually the method of choice, because of its robustness in the face of large changes between images. This is important, because to really bring the rate down we can predict only a fraction of the frames and interpolate the rest. Usually blockmatching is implemented as full search over a window of possible displacements, but there are algorithms which speed it up [3][4]. The drawbacks of blockmatching are that it is computationally expensive (but parallelizable), especially if subpixel accuracy needs to be obtained.
Differential methods are an alternative which relies on iterative procedure minimizing the dissimilarity between the predicted block values and the actual ones. The algorithms perform Newton-Raphson minimization, by differentiating the dissimilarity with respect to the motion parameters, setting the derivatives to zero and solving a linear system for a better fit to the parameters [5][6]. The main weakness of the differential methods is that they assume very small motion for the derivatives to be meaningful. This is often not desirable for image compression purposes, because as stated above, we would often like to encode the motion vectors as seldom as possible. Hierarchical approaches are available to mitigate this problem. Also, we would like to perform well even when the distortion of the transmitted signal is large. Errors introduced as part of the compression are hard to deal with in this framework.
Exhaustive blockmatching is clearly not appropriate for estimating affine parameters. The number of block comparisons one needs to perform grows exponentially with the number of parameters. While estimating the values of 2 parameters does not seem prohibitive, estimating the values of 6 is. The best method probably is again a hybrid method: use blockmatching to estimate the value of the translation parameters, and then for each possible translation value, use differential method to compute the rest of the parameters, choosing the best set of parameters of all examined.
However, implementation and execution time limitations have forced me to go for a complete differential approach, as outlined in [6]. We are minimizing the dissimilarity over a block (or window) w as defined below:
![]()
where D is the dissimilarity matrix as described in the previous section and d is the vector containing the translation parameters. Larger intraframe displacements in this approach can be handled by using a hierarchical motion estimator and larger block sizes.
Experimental Results
We ran the algorithms on a couple of video sequences of length 4. We split the image into blocks of size 16. The algorithm pads the image so that regions near the borders can be tracked. Then, we estimate the translation and the affine motions that best seem to predict the next frame in the sequence using a hierarchical Kanade-Lucas-Tomasi tracker. The motion parameters are quantized as follows: the translation parameters are quantized to a 1-pixel accuracy, and the deformation parameters are quantized uniformly with a step 0.1. The block matches that result from the quantized parameters form the prediction image. The error of the prediction is quantized by a DCT coder with uniform quantization of step 1 and VLC coding of the coefficients(each coefficient is encoded separately). The rates of both translation and affine schemes are compared for each block and the better encoding is picked.
The first sequence we experimented with has very little motion. Below you can see the reconstructed images AFTER compression and transmission.




In this sequence the affine/translation algorithm performs slightly, but almost negligibly better than its translation counterpart. The reason that affine might perform better than translation in this case is due to the fact that in the distortion parameters allow the affine part of the algorithm to perform de facto subpixel-accurate motion estimation, which is known to usually further reduce the bit rate. This improvement can reasonably be expected to be good enough to offset the encoding of 4 more parameters.
| Frame | 1 | 2 | 3 | 4 | |
| Translation MCHC | Rate |
3.5100
|
2.2787 | 2.5618 | 2.9316 |
| Dist | 0.0830
|
0.0833 | 0.0834 | 0.0832 | |
| PSNR | 58.9392
|
58.9250 | 58.9182 | 58.9298 | |
| Hybrid MCHC | Rate | 3.5100
|
2.2226 | 2.4539 | 2.7922 |
| Dist | 0.0830
|
0.0834 | 0.0832 | 0.0835 | |
| PSNR | 58.9392 | 58.9202 | 58.9279 | 58.9141 |
Below is a diagram showing the motion model each block picked: black for translation and white for affine (there is no diagram for the first frame, because we transmit it directly, for it there is no motion estimation, you can also notice that for the first frame the rate is significantly higher).
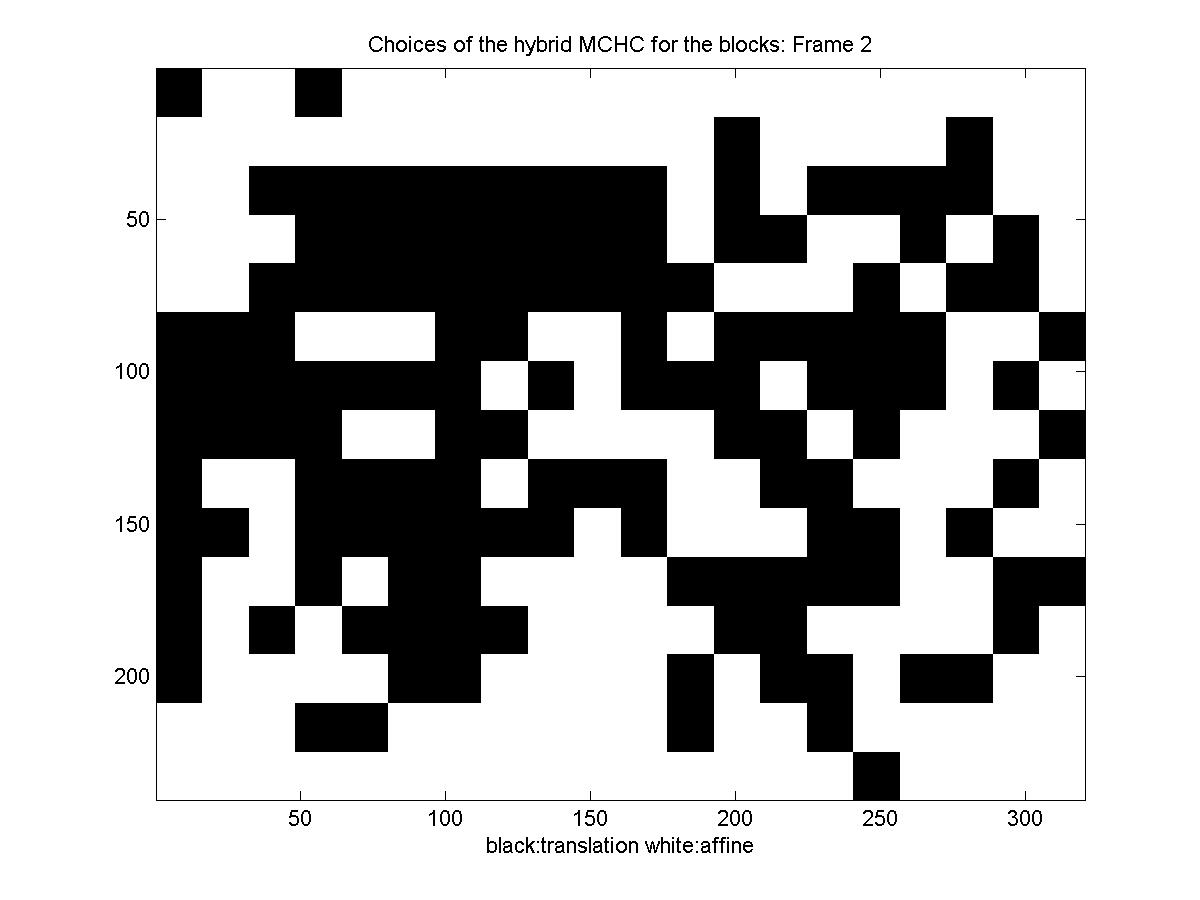
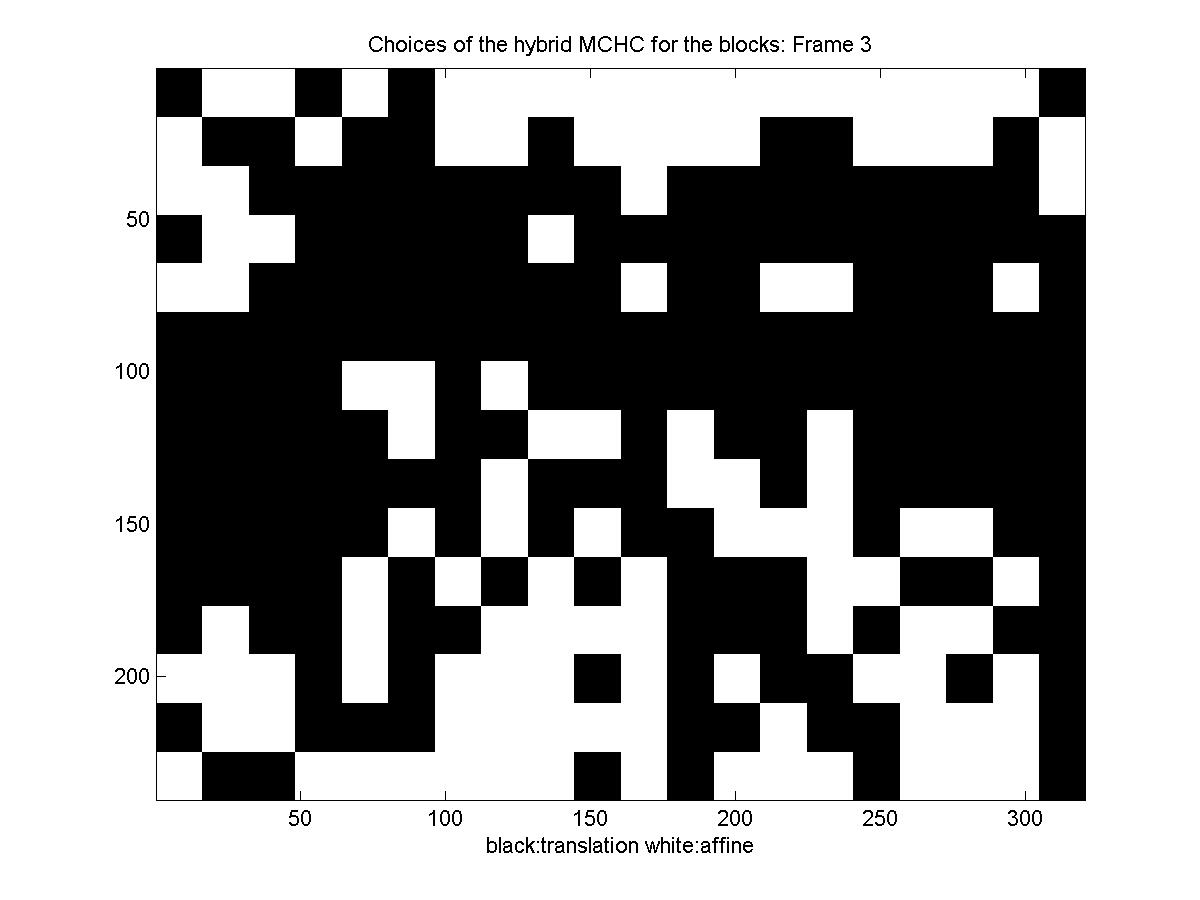
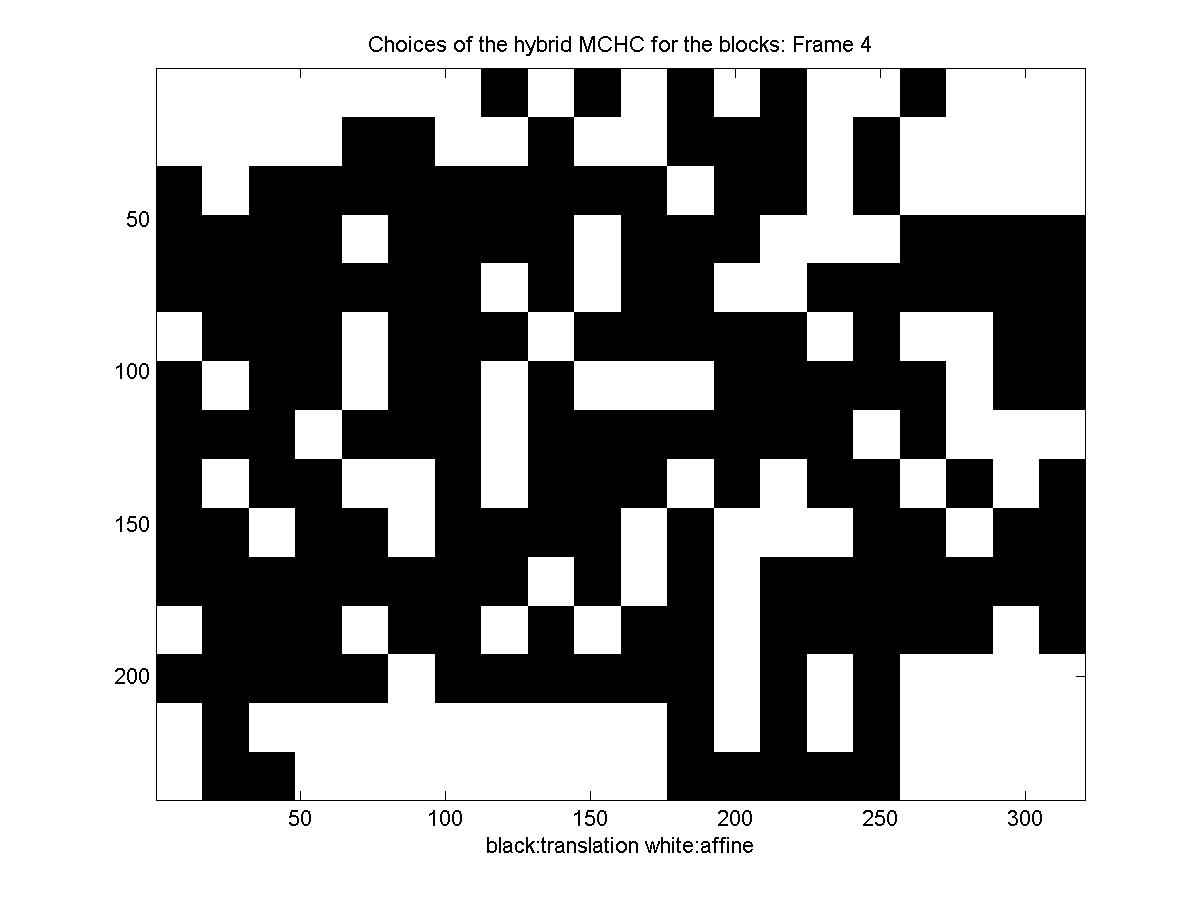
The other sequence we explored has significant image rotation. We also used prediction once every 6 frames. This time because of the rotation, new matter comes into the image from the borders, and the differential motion estimator sometimes cannot find a good match. We treat these few cases by setting the intraframe motion to zero in both the affine and the translational cases to avoid this having a major influence on the results. Below you can see the reconstructed sequence and the results.





| Frame | 1 | 2 | 3 | 4 | 5 | |
| Translation MCHC | Rate | 5.6845 | 4.2707 | 4.2568 | 4.2383 | 4.2342 |
| Dist | 0.0830 | 0.0835 | 0.0834 | 0.0833 | 0.0829 | |
| PSNR | 58.9377 | 58.9161 | 58.9199 | 58.9235 | 58.9433 | |
| Hybrid MCHC | Rate | 5.6845 | 4.2377 | 4.2045 | 4.2032 | 4.1900 |
| Dist | 0.0830 | 0.0830 | 0.0829 | 0.0833 | 0.0832 | |
| PSNR | 58.9377 | 58.9381 | 58.9464 | 58.9223 | 58.9292 |
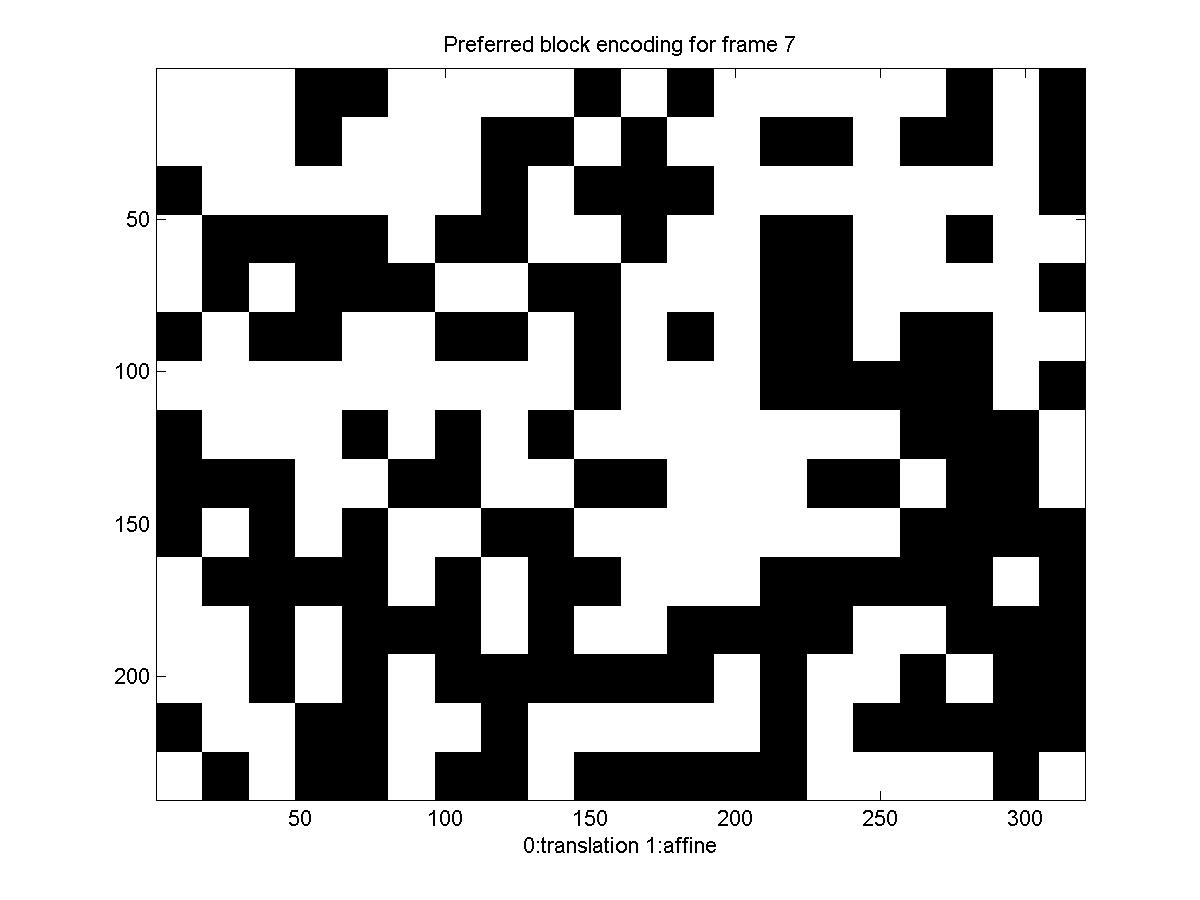
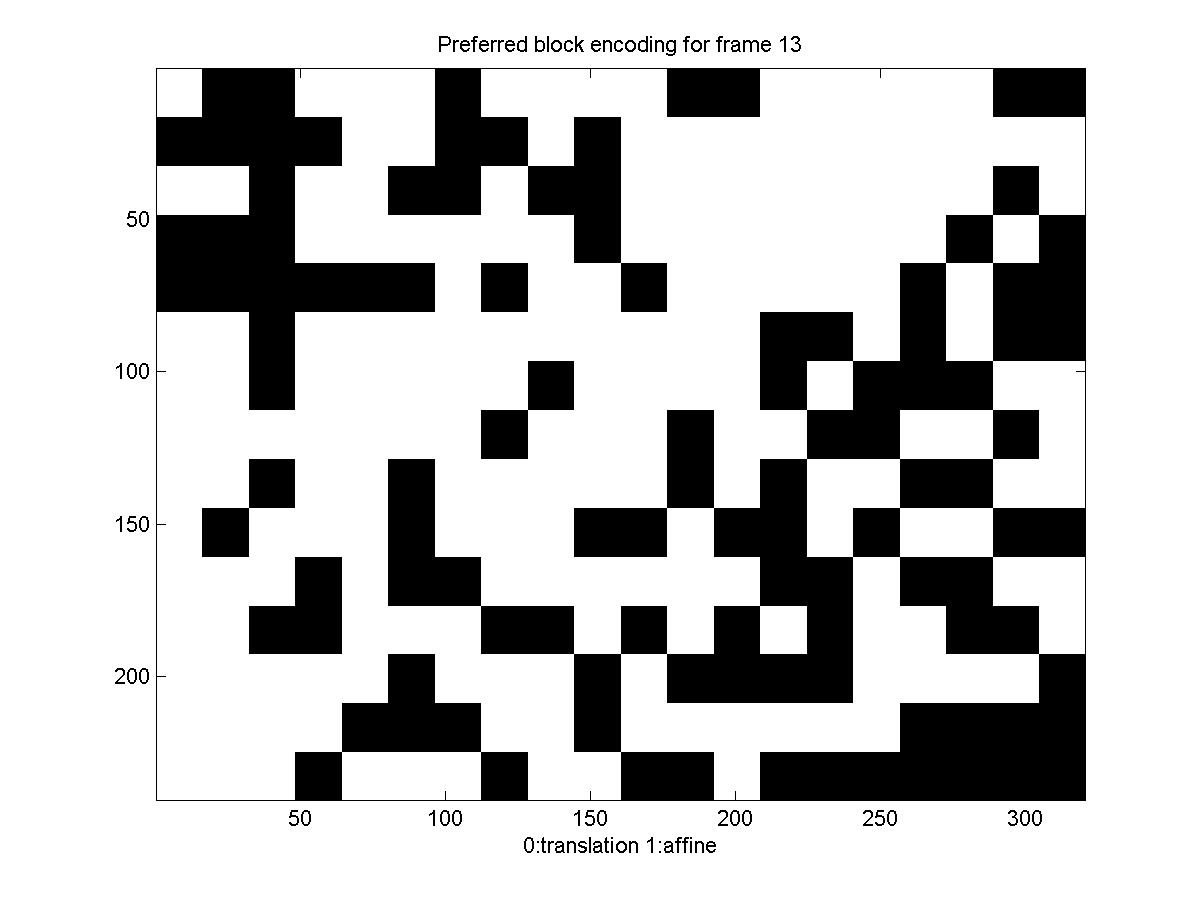
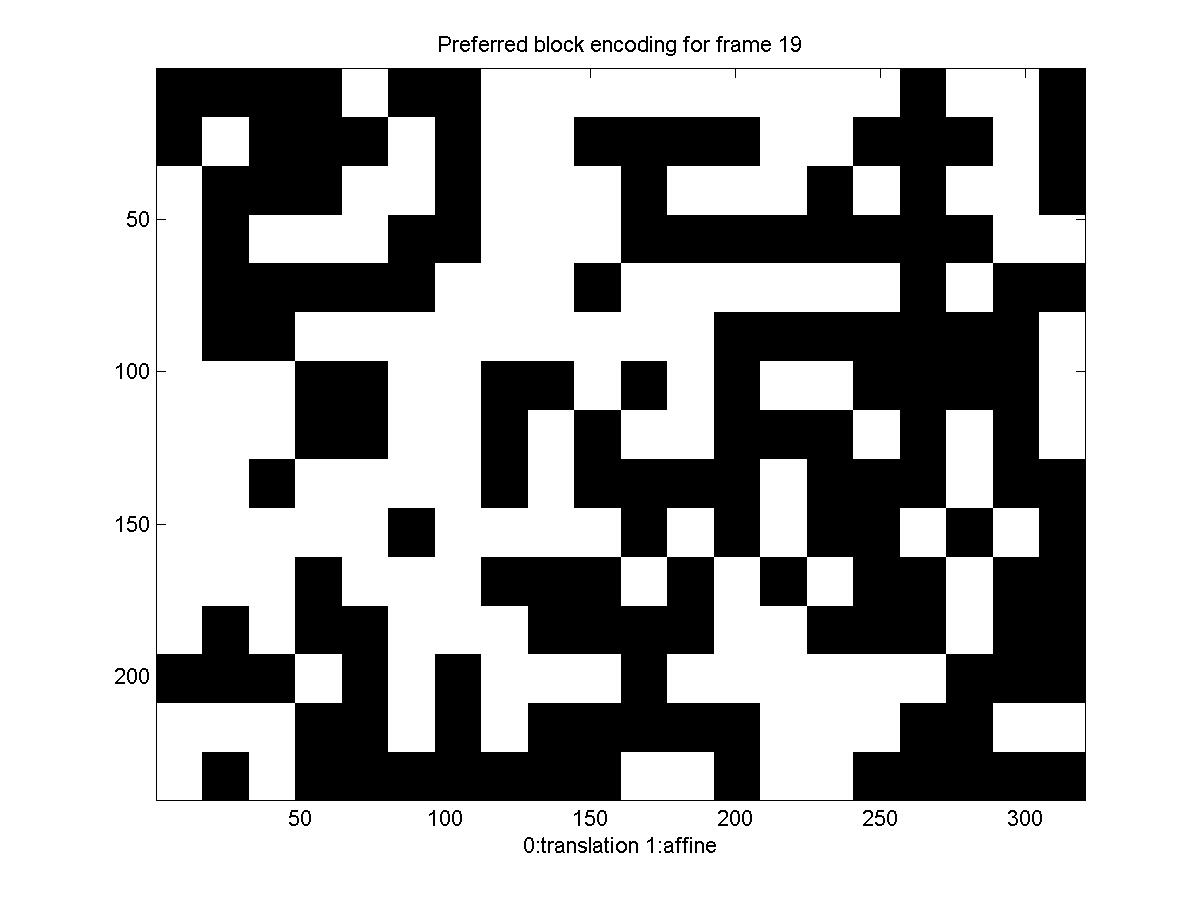
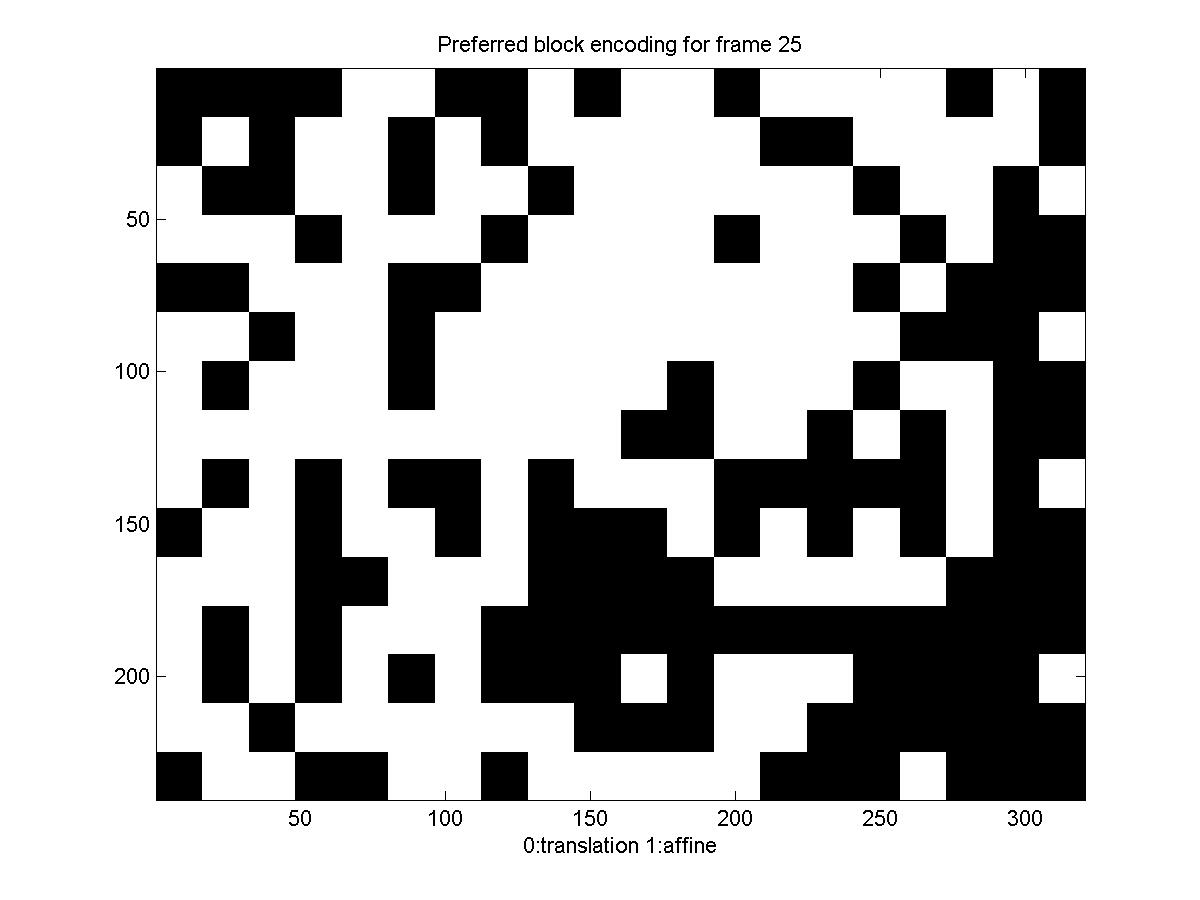
Again the translation/affine algorithm provides some improvement in the rate of transmission. We can see that the rate for this sequence is considerably higher than what we needed before. This can be explained by the high variability of the scene, the influx of new "unseen" pixels (and the way it's treated), the violations of the brightness constancy assumption, and the fact that this time we are skipping over 5 frames in our encoding.
Conclusions
Despite the fact that the hybrid algorithm shows an improvement for the kinds of sequences we have examined, and its use seems to save rate of about 0.05-0.15 bits per pixel on average. However, this improvement seems quite negligible to what we can get with simple approaches such as encoding only a fraction of the frames and interpolating the rest (notice that rate drops to about 0.8 bits per pixel if we encode once every 6 frames in the second sequence). The attempt to do affine motion estimation with differential methods presents significant restrictions both on the quality of the transmitted images (it must be good) and on the amount of motion that one can handle (it must be not too large). These restrictions interfere with the needs of simpler and more effective schemes such as the selective encoding mentioned above. In addition, we are presented with a double time overhead for encoding.
In contrast, if we really need to squeeze any extra bits for an encoding, applying the hybrid MCHC can only help us. However, we would recommend the mixed blockmatching/differential scheme for motion estimation: use full search blockmatching for the translation parameters, and then perform differential minimization to get the values of the distortion matrix D. Thus the requirement that the amount of translational motion is rendered unnecessary, and the requirement regarding the image quality is mitigated.
Acknowledgements
I would like to thank Salih-Burak Gokturk of Stanford University and Jean-Yves Bouguet of Intel Corporation for letting me apply the code in their motion-tracking routine to my project.
References
[1] Moving Picture Experts Group Web Page. http://www.cselt.it/mpeg/.
[2] J. Foley, A. van Dam et al. Computer Graphics, Principles and practice. Addison-Wesley, 1990.
[3] H Yeo, Y. Hu. A modular high-throughput architecture for logarithmic search block-matching motion estimation. Circuits and Systems for Video Technology, IEEE Transactions, 1998.
[4] T. Wiegand; , B. Lincoln.; B. Girod, Fast Search for long-term memory motion-compensated prediction. In Proceedings ICIP, 1998.
[5] B. Lucas, T.Kanade. An iterative image registration technique with an application to stereo vision. Proc. 7th Int. Conf. on AI, 1981.
[6] J. Shi and C. Tomasi. Good features to track. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, June 1994.