Introduction to Scalable Neuroscience: Part 2
 |
I'm going to start this presentation by talking about biological brains. Please bear with me for a few minutes while I explain what we expect to learn from biology that is relevant to the primary topic of this course, namely designing artificial neural networks to implement the next generation of digital assistants that will help to accelerate the progress of scientific discovery.
The human brain is a highly evolved survival machine. Its purpose is to enable us to survive long enough to reproduce and pass on our genes. Given that it is a product of natural selection forced to rely on its existing design in order to live long enough to improve upon that design under selective pressure, it's not surprising it is quite unlike the engineered products that humans manufacture.
It's also not surprising that human beings have been curious about the brain for as long as we knew we had one and that the language we use to describe the structure and function of the brain reflects the long history of its study. Even the very basic anatomy of the brain is still described using a vocabulary that goes back centuries. For the next couple of minutes, focus on the left side of the next slide.
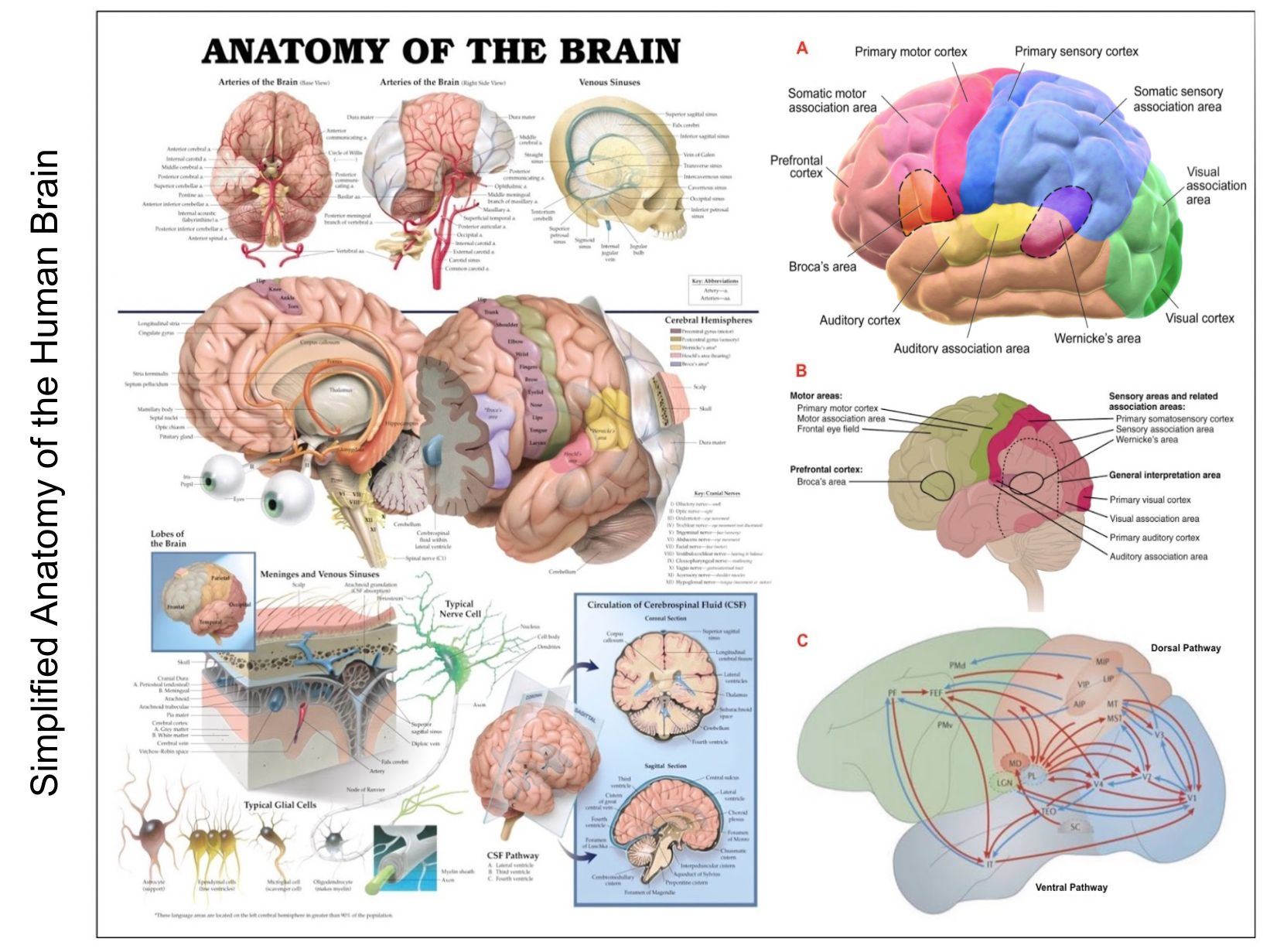 |
On the one hand, anterior, posterior, superior and inferior are used to identify the front, back, top and bottom of the brain for some purposes. Whereas rostral, caudal, dorsal and ventral are employed to specify the same coordinates for other purposes. Medial can be used to refine location within the brain as a whole or within a specified subcomponent. Terms like telencephalon, diencephalon, etc. describe subdivisions of the embryonic vertebrate brain and can be used to refer collectively to the adult regions they mature into, e.g., the telencephalon develops into the two cerebral hemispheres, including the cerebral cortex and a number of smaller subcortical structures.
We'll spend a good deal of our time talking about structures in the cerebral cortex including the so-called neocortex in the mammalian brain which is regarded as the most recently evolved part of the cortex. We'll also spend some time talking about the cerebellar cortex generally referred to as the cerebellum, especially with respect to its recently-evolved circuitry complementing that found in the neocortex.
In our discussions, we'll largely ignore the fact that the much of the brain and the cortex in particular is divided into two hemispheres with similar structure though somewhat different function. In talking about the cortex, we will often refer to the lobes that comprise each hemisphere, including the occipital lobe near the back of the brain encompassing the early visual system, the temporal lobe near the temple that is responsible for hearing and implicated in language, the parietal lobe including the somatosensory cortex, and the frontal lobe including the primary motor and premotor cortex as well as circuits involved in executive control, problem solving and consciousness.
Of course, the brain is two-dimensional and highly structured. The cortex can be thought of as a sheet of neural tissue consisting of several layers such that each layer plays a different role and often involves different types of neurons in different patterns of connectivity. If you stretched it out flat on a table, the cortex would be about the size of a large dinner napkin, but when folded up to fit within the human cranium it is divided into ridges referred to as gyri — singular gyrus — separated by fissures called sulci — singular sulcus — so that areas that appear near to one another on the surface may be at some distance from one another.
All of this can be enormously confusing to the uninitiated. Fortunately, you can ignore almost all the detail shown on the left hand side of this slide for the purposes of this class. Our objective is to design artificial neural network architectures that emulate parts of the brain that humans employ in solving practical problems, and combine these component architectures to design end-to-end systems to assist human engineers and scientists in their research. We aren't interested in slavishly simulating human behavior with all its idiosyncrasies, but rather exploit what we know about the brain in designing these assistants and re-engineer human capabilities when reasonable to do so.
Most of the diagrams you encounter will be no more complicated than those shown in the A, B and C insets on the right of this slide. The three insets provide summaries of how information and computation relating to vision and language propagate through the cortex. The external speakers participating in the first half of this class will provide the necessary background for you to understand how to interpret their analyses of what's going on in the brain. I hope some of you will want to drill down a little deeper to gain additional insight, e.g., you may find it useful to understand the differences between primary and secondary sensory-and-motor areas and between the unimodal sensory cortical areas and related multimodal association areas.
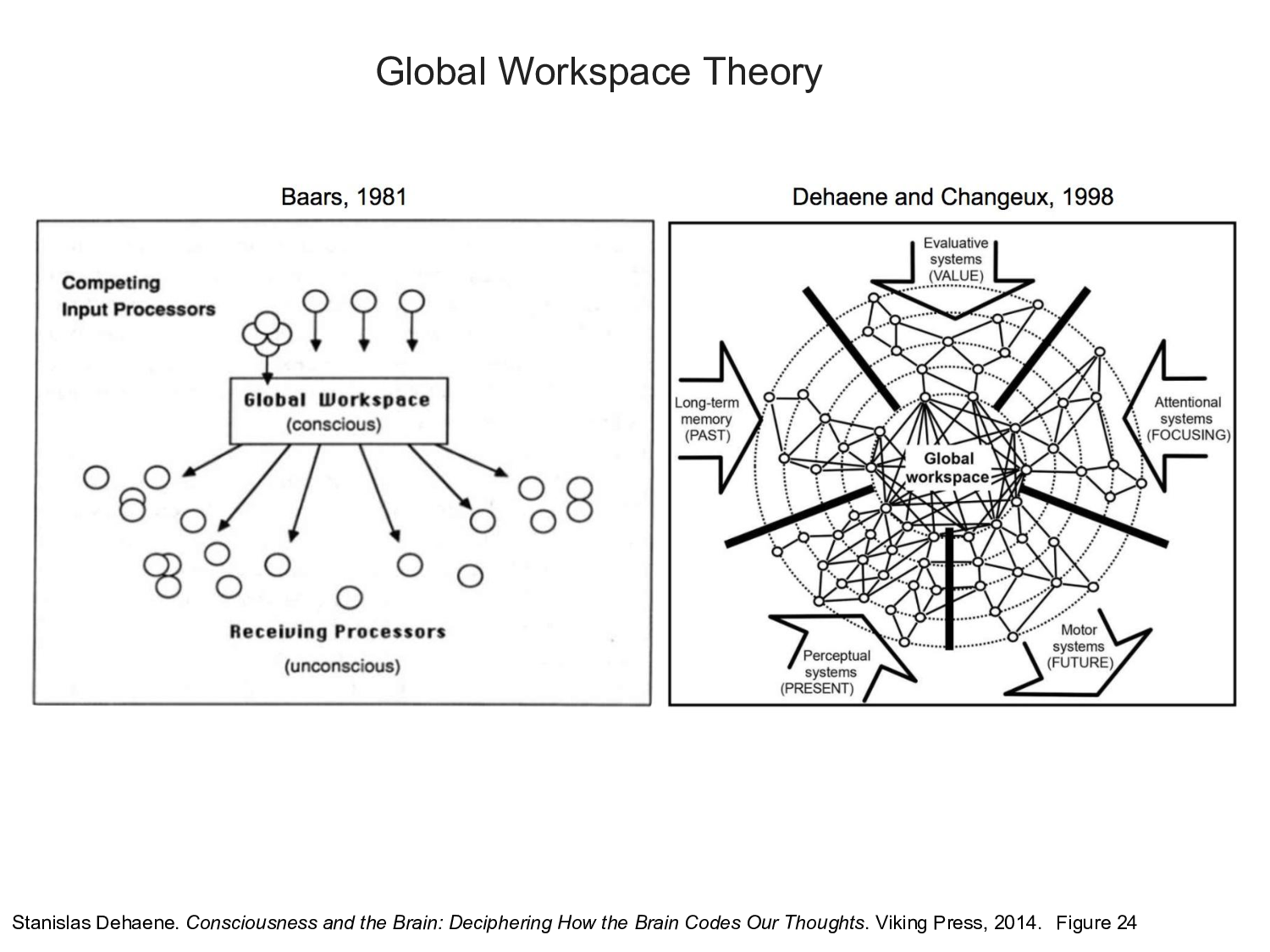 |
Over the last few decades. Stanislas Dehaene at the Collège de France in Paris and Michael Graziano at Princeton University and their respective students and collaborators have developed computational models of consciousness that have made considerable progress in demystifying the confused thinking that characterizes much of the past philosophical discourse on consciousness. At the very least, I think it is fair to say that they provide a framework for thinking about consciousness that is satisfactory for almost anything an engineer might care about in designing digital assistants.
Michael will be joining us next Tuesday to talk about his concept of an attention schema that facilitates human social interaction and addresses some of the issues that we will see later in building so-called theory-of-mind models that account for what other agents know. Several entries in the class discussion list summarize what you need to know about Dehaene's theory, including excerpts from his 2014 book, a succinct twenty-minute summary and a longer more-detailed lecture given by Dehaene. The twenty-minute summary here might be enough.
Central to Dehaene's model of consciousness is the idea of maintaining a global workspace inspired by the work of Bernard Baars. The basic idea is that information is acquired and processed through our primary and secondary sensory systems, combined in increasingly abstract features in association areas to activate portions of episodic memory, and these activations feed into evaluative systems in the frontal cortex where attentional networks select memories in order to to construct complex representations in short-term memory.
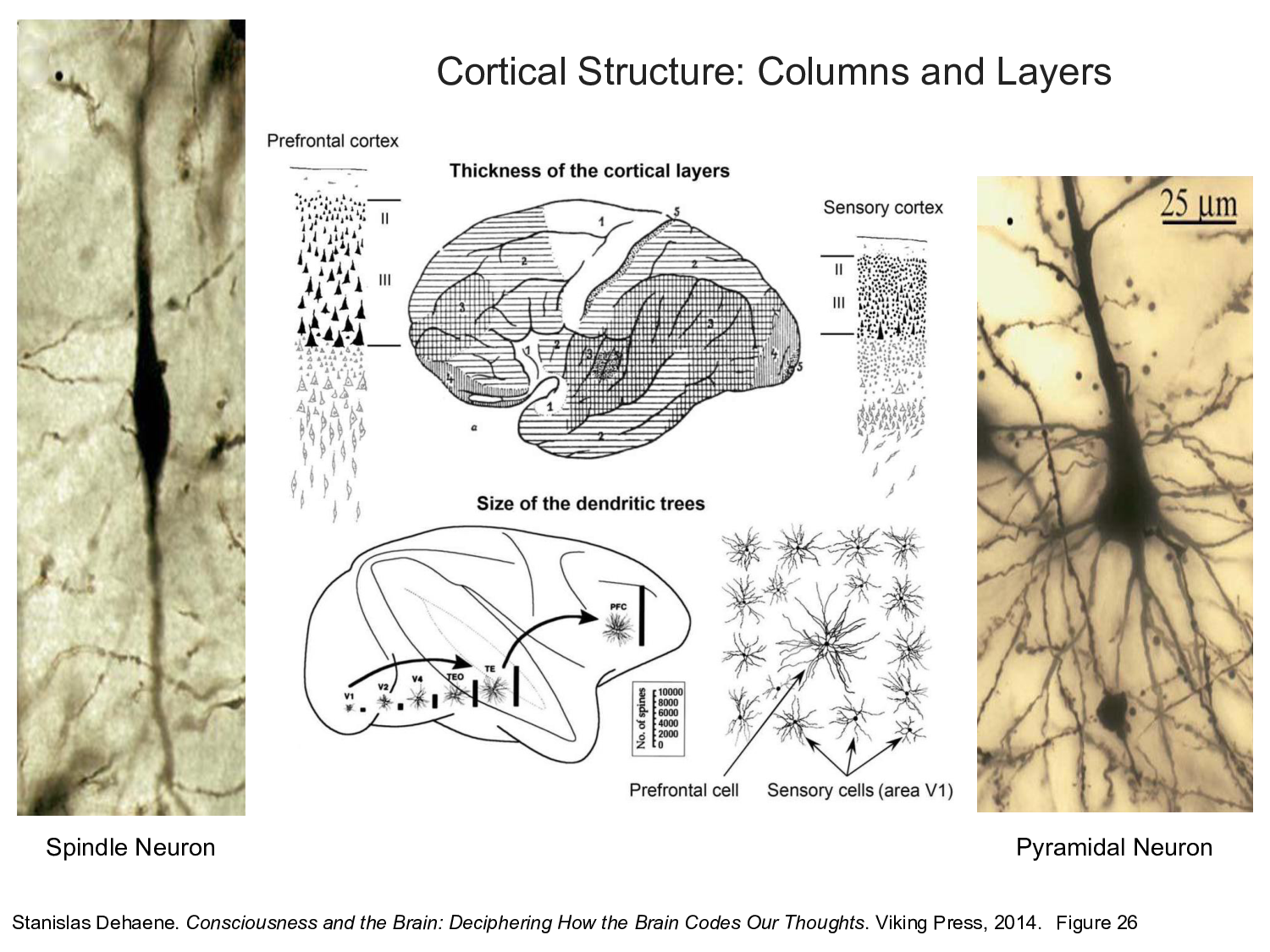 |
The cortical sheet, in addition to its layered structure, appears to be tiled with columnar structures referred to as cortical columns. Some neuroscientists believe that all of these columns compute the same basic function. However, there is considerable variation in cell type, thickness of the cortical layers, and the size of the dendritic arbors to question this hypothesis. The prefrontal cortex is populated with a type of neuron, called a spindle neuron, similar in some respects to the pyramidal cells found throughout the cortex, that allow rapid communication across the large brains of great apes, elephants, and cetaceans. Although rare in comparison to other neurons, spindle neurons are abundant and quite large in humans and apparently play an important role in consciousness and attentional networks.
These attentional networks are connected to regions throughout the cortex and are trained via reinforcement learning to recognize events worth attending to according to the learned value function. Using extensive networks of connections — both incoming and outgoing, attentional networks are able to create a composite representation of the current situation that can serve a wide range of executive cognitive functions, including decision making and imagining possible futures. The basic idea of a neural network trained to attend to relevant parts of the input is key to a number of the systems that we'll be looking at.
To understand attentional networks, think about an encoder-decoder network for machine translation. As the encoder digests each word in the sequence of words that constitute the input sentence, it produces a representation — Geoff Hinton refers to these as thought clouds in analogy to the iconic clouds that you see in comic strips — of the sentence fragment or prefix that it has seen so far. Because the sentence is ingested one word at a time — generally proceeding from left to right — the resulting thought cloud will tend to emphasize the meaning of the most recently ingested words in each prefix.
You could encode the entire input sentence and then pass the resulting representation on to the decoder, but earlier words in the sentence will receive less attention that later words. Alternatively, you could introduce a new network layer that takes as input all of the encodings of the sentence prefixes seen so far and trains the new layer — thereby taking advantage of the power of gradient descent — to produce a composite representation that emphasizes those parts of the input that are most relevant in decoding / generating the next word in the output. Check out this tutorial for more detail.
 |
In Dehaene's theory, information about the external world enters the cortex through the thalamus and, with input from subcortical structures responsible for arousal and sleep, generates a signal marking the information available for examination. The raw sensory input is propagated to higher-level processing systems eventually reaching the prefrontal cortex where it is evaluated and selectively made available in short-term memory. The computations required for evaluation and selection can be modeled by attentional networks initialized with a prior that selects for suitably abstract features that maximize executive performance.
The global workspace enables us to construct and maintain a complex composite representation in a serial fashion guided by attention. This can be accomplished using a form of persistent memory enabled by fast weights — originally referred to as dynamic links in the work of Christoph von der Malsburg — to manage a working memory in which information can be added, modified and removed, that supports associative retrieval and is implemented as a fully differentiable model and so can be trained end-to-end by gradient descent. Fast weights are used to store temporary memories of the recent past and provide a neurally plausible method of implementing the type of attention to the past that has recently proved helpful in sequence-to-sequence models.
 |
The basic artificial neural network architecture consists of a hierarchy of specialized networks with a relatively dense collection of feedforward and feedback connections that enable recurrent state, attentional focus and the management of specialized memory systems that persists across different temporal scales. Individual networks are specialized to serve different types of representation, employing convolutional networks, gated-feedback recurrent networks and specialized embedding models.
All of these networks are distributed representations of one sort or another, many of which were developed by the early pioneers in the nascent field of connectionism and featured in the PDP — Parallel Distributed Processing — books that we discussed in the previous class. Typically, they encode information in high-dimensional vector spaces such that different dimensions can be trained to represent different features allowing attentional mechanisms to emphasize or modify encodings so as to alter their meaning in a manner analogous to variable substitution in traditional symbolic systems.
Long Short-Term Memory (LSTM) models were one of the first really practical recurrent neural-network architectures. Now there are quite a few variations including Gated-Feedback Recurrent Networks (GF-RNN) and convolutional neural networks have been shown to work as well as recurrent models for some problems. There have been several important extensions to RNN models that have considerably extended their range. Here we mention three extensions that are applicable to the programmer's apprentice. All three of these extensions exploit attention in some manner, and they can be combined to design even more capable architectures.
The basic Attentional Interface that we've already encountered allows an RNN model to selectively focus on parts of its input. Neural Turing Machine (NTM) — also called Differentiable Neural Computer (DNC) — models employ external dynamic memory that can be read from and written to under attentional control. Finally, Neural Programmer models learn how to write programs as a means of accomplishing a target task. These programs need not be conventional computer programs and learning to program doesn't require examples of correct programs since the objective function depends on the target task and gradient descent does the rest.
 |
The original programmer's apprentice was the name of project initiated at MIT by Chuck Rich and Dick Waters and Howie Shrobe to build an intelligent assistant that would help a programmer to write, debug and evolve software. Our version of the programmer's apprentice is implemented as an instance of an hierarchical neural network architecture. It has a variety of conventional inputs that include speech and vision, as well as output modalities including speech and text. In these respects, it operates like most existing commercial personal assistants.
It differs substantially, however, in terms of the way in which the apprentice interacts with the programmer. It is useful to think of the programmer and apprentice as pair programming, with the caveat that the programmer is in charge, knows more than the apprentice does — at least initially, and is invested in training the apprentice to become a competent software engineer. One aspect of their joint attention is manifest in the fact that they share a browser window. The programmer interacts with the browser in a conventional manner while the apprentice interacts with it as though it is part of its body directly reading and manipulating the HTML using the browser API. The browser serves both programmer and apprentice as and encyclopedic source of useful knowledge as well as another mode of interaction and teaching.
There is a very real sense in which the apprentice is embodied in the same sense the Deep Recurrent Attentive Writer neural network architecture — the acronym is DRAW — developed by researchers at DeepMind embodies a digital slate and drawing program. DRAW networks employ a spatial attention mechanism that mimics foveation of the human eye, allowing it to iteratively construct complex images. The browser interface serves as a special type of prostheses enabling the assistant to interface more directly with the programmer by directly apprehending every key stroke and mouse movement initiated by the programmer.
 |
The most efficient mode of interaction between the apprentice and programmer is likely to be through the use of natural language. Existing personal assistants are not particularly talented at continuous dialogue. The job of the apprentice is simplified somewhat by the relatively narrow scope of the task of programming. That said, verbal communication is complicated by the inherent ambiguity of natural language, the importance of reading another person's body language and facial cues, the subtlety required to notice when our conversational partner is confused and then easily recover from misunderstanding, and, finally, the fact that human beings share a great deal of basic knowledge and common sense.
This is not the place for a lecture on dialogue management, but I'll make just a few comments about how we might finesse the problem either by brute force approaches or by resorting to a highly structured subset of natural language sufficient for most of the communication that goes on between two programmers focused intently in working on a specific problem.
The CMU RavenClaw Dialogue Management Architecture recast dialogue management as hierarchical task-based planning, demonstrating how error recovery, new topic introduction, recursive structure, and other characteristics of conversational dialogue could be handled within this framework. We've experimented with this approach and it might be a good fit for a prototype version of the programmer's apprentice. A more ambitious approach might leverage the idea of value iteration networks to create a dialogue management system trained on real dialog. A hybrid alternative would be to combine the two approaches.
In 2013 we created a dialogue dataset from the logs of chat sessions between software engineers and technical support staff. We borrowed the idea that dialogue management as a specialized form of language translation in which both speakers use the same basic language but employ different word choices, and created a sequence-to-sequence encoder-decoder translation model. The dataset was relative small compared with most of our language translation datasets, but the performance was better than we had any right to expect. More sophisticated hierarchical architectures using various attentional mechanisms would no doubt outperform our earlier models.
 |
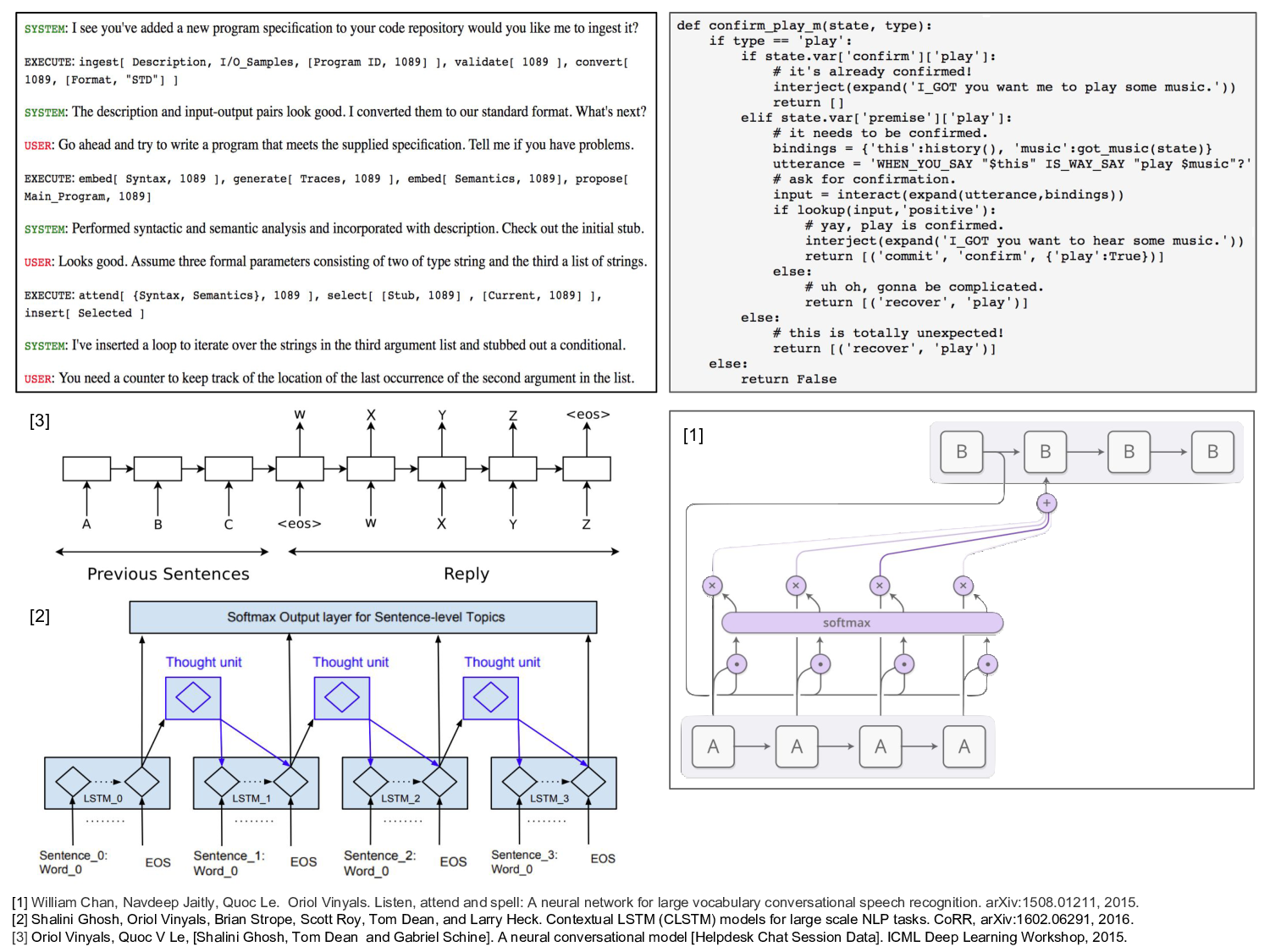
In the second half of the course, we will have a number of speakers discuss their different approaches to automated program synthesis. Most of them rely upon program embeddings of one sort or another in their neural network architectures. Here we briefly discuss one approach to code synthesis by way of illustrating the potential value of encoding a large repository of programs in an embedding space and using nearest-neighbor search to find similar programs.
Whether they admit it, many programmers begin work on a new project by searching the web for a program with a description or input-output behavior that matches their target specification. They might search a large repository like GitHub or consult a forum like Stack Overflow or Code Project to find a suitable starting program. Having identified a promising candidate, they iteratively transform the program by changing arguments, adding conditionals, modifying the body of recursive procedures, etc. In practice this method is most effective in modifying the behavior of an existing program, rather than starting an entirely new project.
If you do this frequently, rather than repeatedly searching the same repositories and forums, it makes sense to ingest all of the data at once and train an embedding model to improve search. Researchers often distinguish between syntactic and semantic program embeddings. This can give rise to some confusion and so hold your questions for now, and, as an exercise for later on, compare the two programs A and B shown here and list how they differ from one another semantically and syntactically. In the meantime, consider two basic strategies that illustrate the difference in practice.
The first strategy is based on NLP methods for machine translation. The idea is simple. Use standard compiler tools to convert the program into an equivalent abstract syntax tree (AST) and then proceed using your favorite machine translation method of embedding. The second strategy embeds code traces produced by running the program on sample input-output pairs. In this case, the embedding techniques tend to be more complicated, e.g. graph embeddings and multi-stage methods that first embed variable-assignment vectors and then embed sequences of such vectors in such a way as to account for the dependencies between variables.
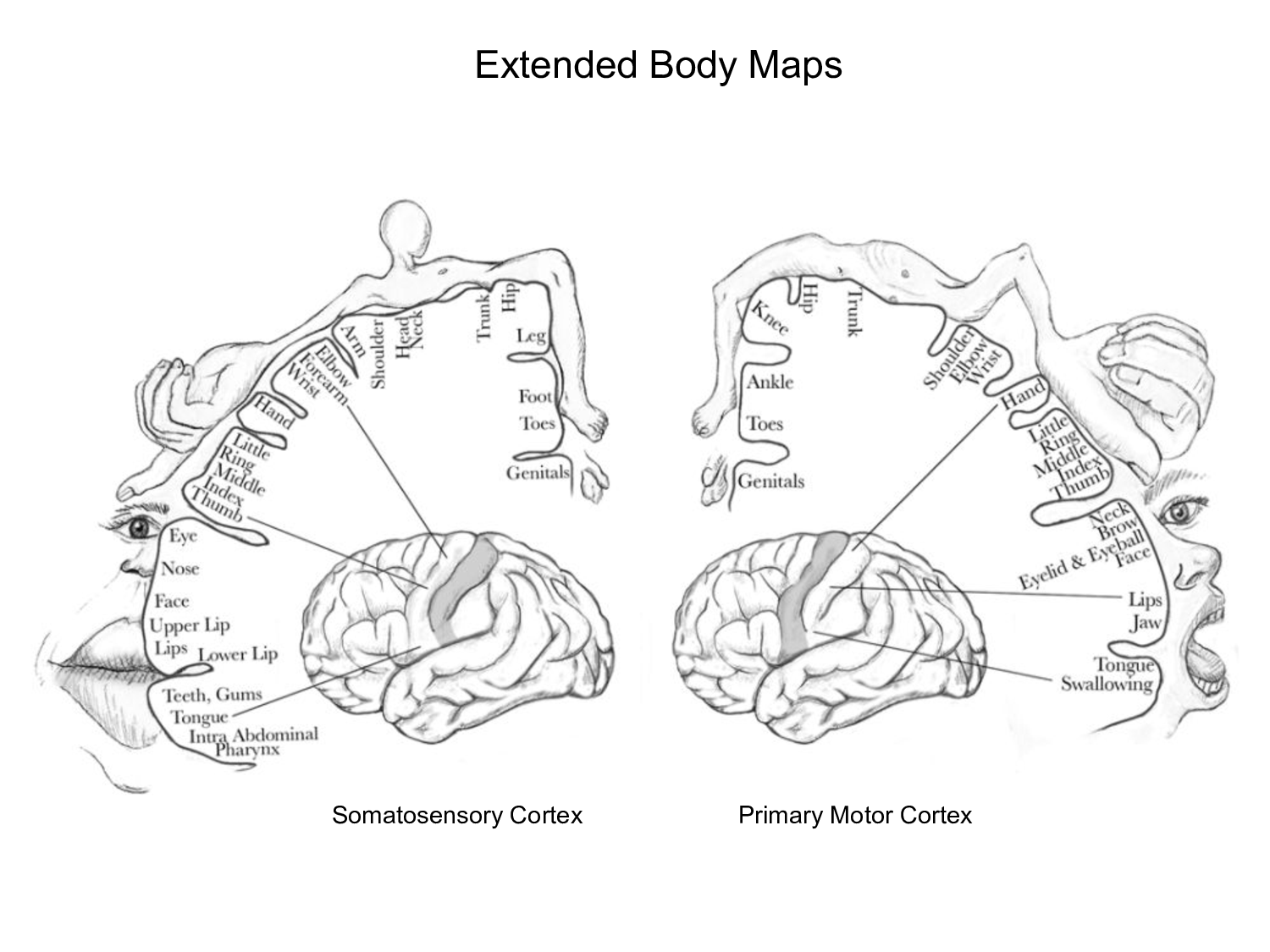 |
The spatial relationships among the ganglion cells in the retina are preserved in the activity of neurons found in the primary visual — or striate — cortex. Most sensory and motor areas maintain similar modality-specific topographic relationships. Shown here, for example, are Wilder Penfield's famous motor and somatosensory homunculi depicting the areas and proportions of the human brain dedicated to processing motor and sensory functions. Scientists have observed that the area devoted to the hands tend to be larger among pianists, while the relevant areas in the brains of amputees typically become significantly smaller.
 |
We imagine the programmer's apprentice with a body part consisting of an instrumented integrated development environment (IDE). Alternatively you might think of it as a prosthetic device. It is not, however, something that you can simply remove or replace with an alternative device outfitted with a different interface or supporting different functions. Like the legs you were born with or the prosthesis replacing an amputee's severed arm, you have to learn how to use these devices.
Architecturally, the apprentice's prosthetic IDE is an instance of a differentiable neural computer (DNC) introduced by Alex Graves and his colleagues at DeepMind. The assistant combined with its prosthetic IDE is neural network that can read from and write to an external memory matrix, combining the characteristics of a random-access memory and set of memory-mapped device drivers and programmable interrupt controllers. The interface supports a fixed number of commands and channels that provide feedback. You can think of it as roughly similar to an Atari game console.
 |
Cognitive and systems neuroscience provide a wide range of insights into how to design better algorithms and better artificial neural network architectures. From our study of the fly olfactory system we have learned new algorithms for locality sensitive hashing, one of the most important algorithms used for scalable nearest-neighbor search. The mammalian visual system is the most well studied area of the brain. Early on we discovered that the architecture of the visual system involved two separate pathways referred to as the dorsal and the ventral pathways and roughly characterized as being responsible for the "where" and "what" dimensions of visual stimuli.
Subsequently it was argued that other sensory modalities employed dual pathways and that the production and understanding of language were organized as such with Broca's and Wernicke's areas playing key roles in this architecture. The engineering insights we have gained studying the brain are cashed out in the technical language of different disciplines. For example, the dual loop language model as it's called is often presented as a block diagram consisting of conceptually separate neural networks. The Hodgkin-Huxley model of action potential propagation in the giant squid axon was described both as a system of differential equations and as an electrical circuit diagram.
The control system involving the cerebellar cortex or cerebellum, the cerebral cortex and number of subcortical areas including the basal ganglia is one of the most interesting and neglected systems in the mammalian brain and primates in particular. It is often described in terms of a control theoretic block diagram consisting of separate transfer functions as shown here. Contrary to our original understanding of the cerebellum as primarily involved in orchestrating the motor activity controlling fine movement, we now know that the primate neocortex in concert with recently-evolved augmentation of the cerebellum enable human beings to transfer abstract thinking such as that involved in solving algebraic equations from the cerebral to the cerebellar cortex allowing us to carry out such calculations with significantly greater speed and accuracy. Imagine how an experienced software engineer might take advantage of this capability to facilitate thinking about programs, and then think about how we might develop an architecture for the programmer's apprentice that employs a similar strategy.
 |
Human episodic memory is one of the most important elements in determining who we are and how we relate to others. It is critical in reasoning about what's going on in other minds and plays a central role in our social interactions. Not surprisingly episodic memory engages many cortical and sub cortical regions of the primate brain. If one were to pick out a single locus of activity relating to episodic memory it would probably be the entorhinal area corresponding to Brodmann areas 28 and 34 shown here highlighted in yellow. The entorhinal cortex is located in the temporal lobe in close proximity to the hippocampus, but this area is merely the hub of a great deal of activity spread throughout the brain.
 |
The hippocampus is perhaps best known for its role in supporting spatial reasoning. A type of pyramidal neuron called a place cell has been shown to become active when an experimental animal enters an area of a maze that it has visited before. However, the hippocampus plays a much larger role in memory by representing not just the "where" of experience but also the "when". The manner in which we employ short- and long-term memory is very different. We might construct a representation of our current situation in short-term memory, drawing upon our long-term memory to provide detail.
The two memory systems are said to be complementary in that they serve different purposes, one provides an archival record of the past while the other serves as a scratchpad for planning purposes. In retrieving a memory there is a danger that we corrupt the long-term memory in the process of subsequent planning. This isn't simply an academic question, it is at the heart of how we learn from the past and employ what we've learned to think about the future. Our subtle memory systems enable us to imagine solutions to problems that humans have never faced, and account for a good deal of our incredible adaptivity. In several lectures, we will explore architectures that support such flexibility.
 |
The phrase "Theory of Mind" refers to the idea that humans and possibly other organisms construct models of how other agents reason in order to understand and anticipate the behavior of such agents. Developmental psychologists have conducted fascinating research about how and when children learn such models, and what goes wrong when children fail to learn such models during a crucial developmental window.
Theory of Mind Reasoning refers to the mental processing required to employ such models in various collaborative and strategic circumstances. Here we consider what it would mean for a machine to learn such a theory and employ it in practical applications such as the programmer's apprentice. I've left this topic for last for a number of reasons. It might seem presumptive to suppose that machines could learn such models. It might not at first blush appear to be useful, but on reflection I hope you will agree that when two programmers collaborate in designing or debugging a computer program, it helps a lot to have some idea of what the other programmer knows or might be mistaken about.
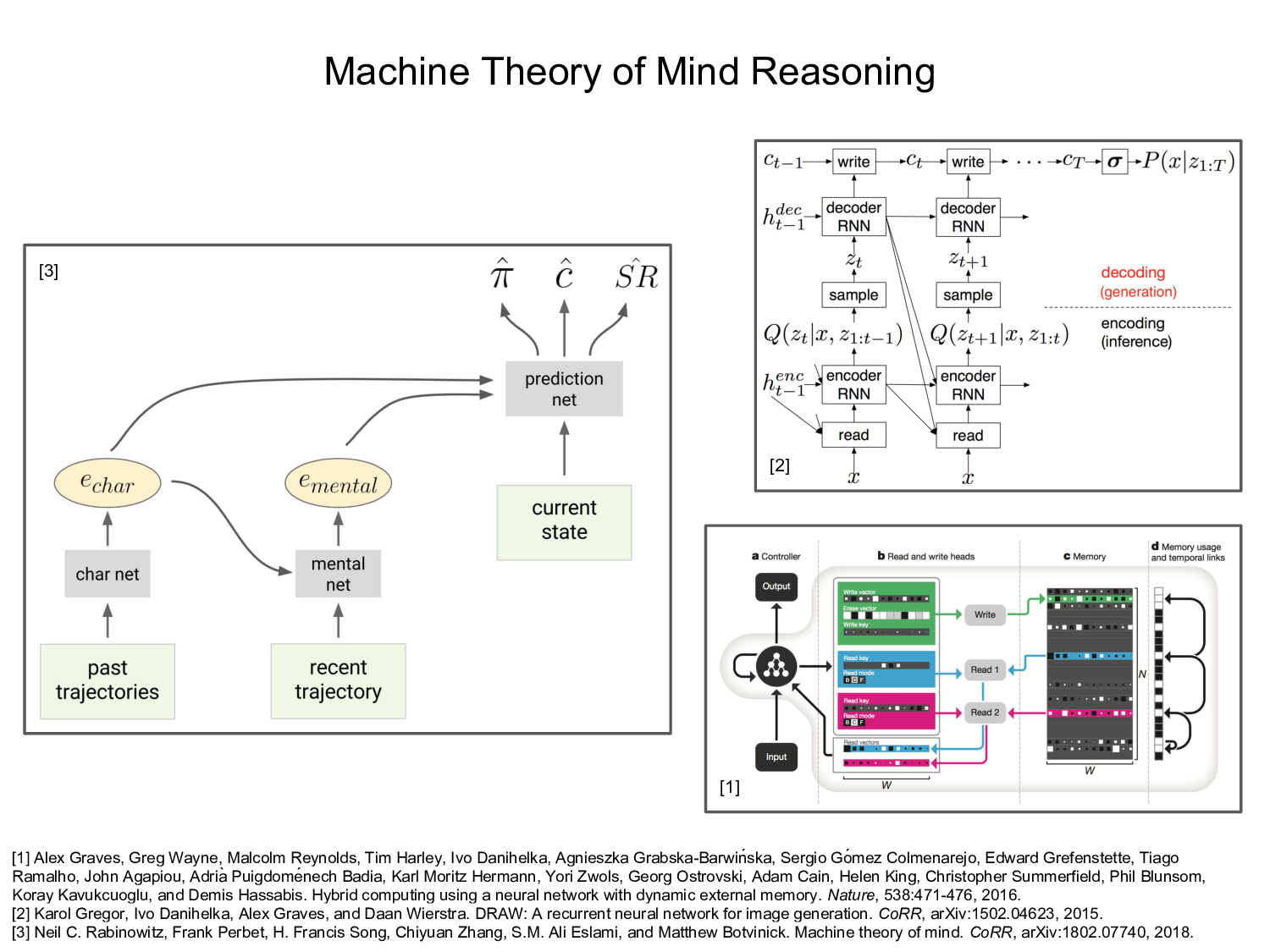
Michael Graziano will be discussing his attention schema theory of consciousness — or subjective awareness — its evolutionary and neurobiological basis, practical implementation, and critical role in facilitating social behavior. Here's a short video of Graziano explaining basic attention schema theory. Neil Rabinowitz will present an elegantly simple formulation and implementation of theory-of-mind reasoning that he and his colleagues at DeepMind have developed. This a good example of how our understanding of cognitive science, psychology and computational neuroscience can produce practical insights that inspire engineers and lead to powerful new technologies.